 夜雨聆风
夜雨聆风今日关键词:本地 AI、AI Agent、垂直落地
今天这期的主线很清楚:AI 正在从“云端大模型竞赛”往三个方向下沉——本地推理、垂直行业、真实工作流。
这不是一个特别热闹的模型发布日,但更像一个“应用层补课日”:开发者开始担心浏览器插件安全,企业开始把 Codex、Claude 放进工程流程,家电厂商开始把 AI 做进冰箱,内容出海公司则把 AI 译制当成刚需。说白了,AI 不再只是发布会上那个漂亮词,它开始进入成本、权限、安全和业务结果里。
📌今日头条
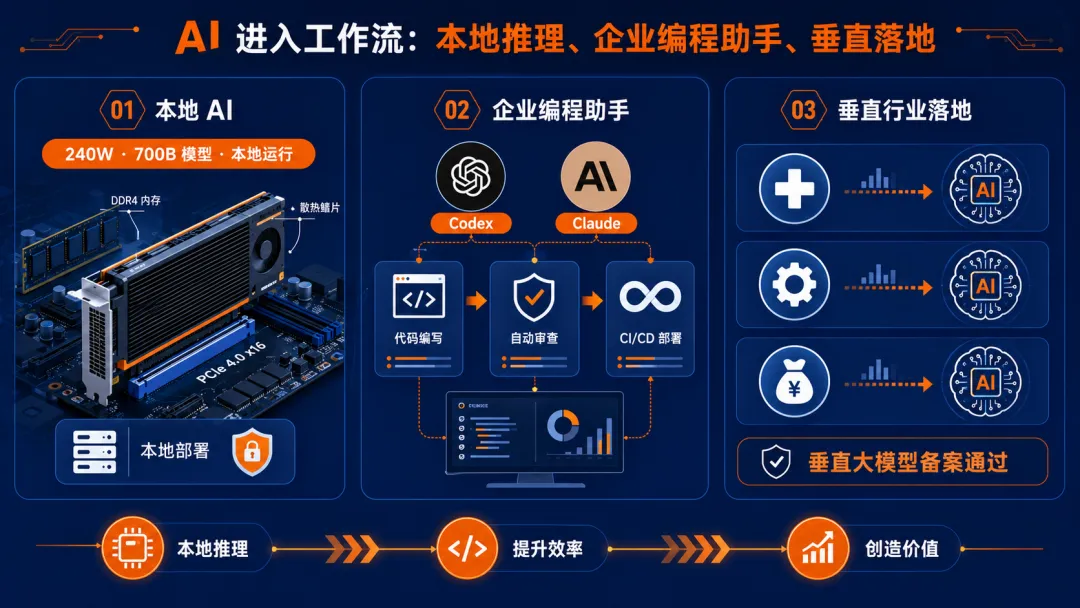
1. Amazon 放开开发者使用 Codex 和 Claude:企业 AI 编程进入“默认工具”阶段
据 Slashdot 报道,Amazon 已允许程序员使用 OpenAI Codex 和 Anthropic Claude。这个动作不只是“又一家大公司用了 AI 编程工具”,真正值得看的是:大型工程组织正在把 AI 编程助手从个人尝鲜,推向团队级、流程级使用。
核心信息:
相关工具:OpenAI Codex、Anthropic Claude 场景:企业程序员的日常开发流程 变化:AI 编程从个人效率工具,进入组织级采用阶段
从商业角度看,这会带来一个很现实的问题:AI 写代码不难,难的是谁来审、怎么审、出了问题谁负责。企业不是缺“生成代码”的按钮,而是缺一整套审计、权限、质量和安全边界。
看明白了吗?AI Coding 的下一轮竞争,不一定是“谁补全更快”,而是谁更适合进公司流程。
2. 垂直大模型持续备案:行业 AI 开始从“演示”走向“可上生产”
国内多地垂直大模型通过备案的消息继续出现。对普通读者来说,“备案”听起来有点行政化,但对企业应用来说,它背后的信号很直接:大模型应用正在从通用聊天,进入行业场景。
核心信息:
方向:垂直领域大模型 场景:医疗、制造、教育、金融等行业应用 意义:企业部署 AI 时,更重视合规、安全和场景适配
这类新闻的价值不在于“又多了几个模型”,而在于产业重心变了。过去大家比参数、比榜单;现在更关键的是:能不能接入业务系统?能不能处理行业数据?出了错有没有边界?
不太好听地说,很多通用大模型演示很漂亮,但真到企业生产环境,才发现到处都是坑。
3. 短剧出海带火 AI 译制:内容全球化进入低成本复制阶段
36 氪报道提到,短剧出海爆发式增长,AI 译制服务成为行业刚需。短剧这种内容形态,本来就追求快速生产、快速测试、快速投放,AI 译制刚好卡在了它的成本结构里。
核心信息:
场景:短剧出海、多语种内容分发 需求:翻译、配音、本地化表达 影响:内容团队可以更快测试海外市场
这件事的关键不是“AI 会翻译”,而是“AI 让试错成本下降”。以前一个内容团队要做多语种发行,需要较高的人力和时间投入;现在先用 AI 跑一版市场反馈,已经变得可行。
但问题也在这里:低成本会带来更多内容,也会带来更多同质化。海外用户不是只需要“听得懂”,还需要“像本地内容”。AI 译制解决了第一步,第二步仍然考验团队的审美和本地理解。
参考链接:
Slashdot[https://developers.slashdot.org/story/26/05/10/0618225/amazon-relents-lets-its-programmers-use-openais-codex-and-anthropics-claude] 新浪财经[https://finance.sina.com.cn/jjxw/2026-05-11/doc-inhxnfpz0812942.shtml] 36氪[https://36kr.com/newsflashes/3804084482268932?f=rss]
🔥 AI 新动态
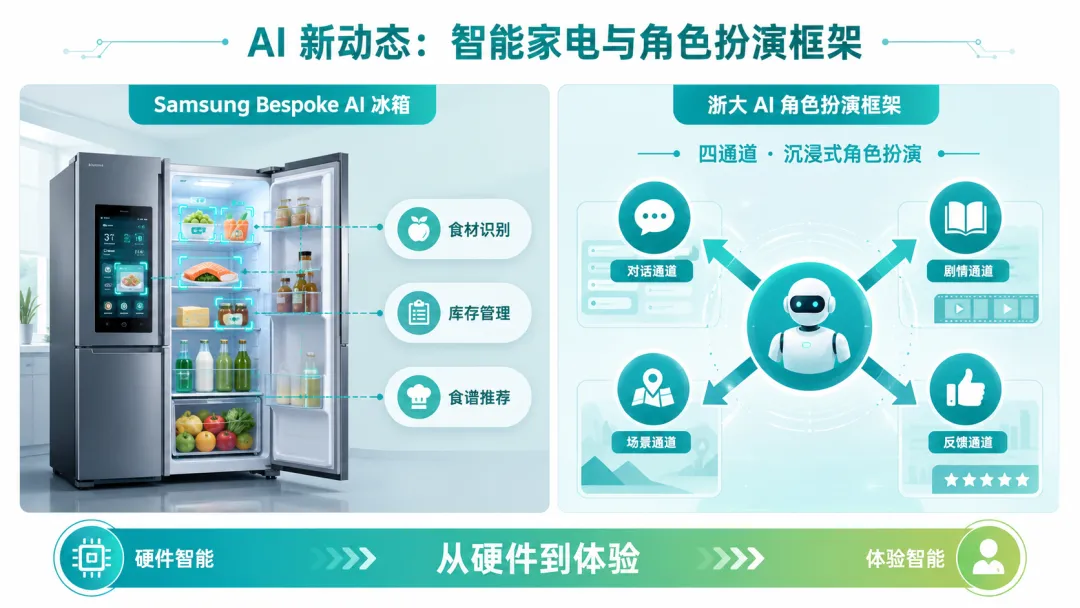
1. Samsung Bespoke 更新:AI 家电开始从“噱头”变成“生活管理入口”
Engadget 报道称,Samsung 的 Bespoke 系列更新正在让冰箱里的 AI 更接近实用功能:识别食材、管理库存、辅助推荐食谱。这类功能过去经常被吐槽“为了 AI 而 AI”,但现在它开始触碰一个真实场景——家庭日常决策。
核心信息:
产品:Samsung Bespoke 智能家电 功能方向:食材识别、库存管理、食谱建议 用户价值:减少家庭管理中的重复记忆和临时决策
这个方向值得关注,因为它代表 AI 应用的一种新路径:不是让用户打开一个聊天框,而是把 AI 塞进原本就高频存在的设备里。
当然,坏消息也很明显。家电 AI 如果做不好,很容易变成昂贵的提醒器。用户真正愿意买单的,不是“冰箱会说话”,而是它能不能真的少浪费食材、少做无效决策。
2. 浙大角色扮演框架:AI 不只会聊天,还要学会“导演场景”
量子位报道,浙江大学推出了让 AI 会“导演”的角色扮演框架,通过四通道消息实现更沉浸的交互。这类研究说明,AI 角色扮演正在从简单人格设定,走向更复杂的场景控制。
核心信息:
方向:AI 角色扮演与多通道交互 目标:提升沉浸感、角色一致性和剧情推进能力 潜在场景:游戏、虚拟陪伴、教育训练、交互式内容
这背后其实有一个更大的变化:AI 内容交互正在从“问答”变成“叙事”。
问答是工具逻辑,叙事是体验逻辑。未来很多 AI 应用,可能不再像办公软件,而更像一个能持续推进情境的“互动系统”。但这也意味着更高的内容安全、边界控制和用户心理依赖风险。别只看热闹,这块并不轻。
参考链接:
Engadget[https://www.engadget.com/2167892/samsungs-bespoke-update-is-big-step-towards-a-useful-ai-for-your-fridge] 量子位[https://www.qbitai.com/2026/05/415048.html]
🚀 技术突破

1. 旧工艺 AI 加速卡挑战本地推理:700B 模型、本地运行、240W 功耗
TechRadar 报道,一家小型公司推出的 PCIe AI 加速器,使用相对传统的 DDR4 和 28nm 芯片,却宣称可在本地运行 700B 级别大模型,功耗约 240W。
性能数据:
形态:PCIe AI 加速器 宣称能力:本地运行 700B 级别大模型 功耗:约 240W 技术路线:DDR4、28nm 等较成熟工艺组合
如果这些数据能够在真实环境中稳定复现,它的意义很大:本地 AI 不一定只能靠最先进制程和昂贵 GPU 堆出来。
但这里也要泼一点冷水。硬件新闻最容易出现“参数很好看,落地很骨感”的问题。真正要看的是吞吐、延迟、模型兼容性、软件栈成熟度,以及开发者能不能用得起来。没有软件生态的硬件,很容易变成一块漂亮板卡。
2. 用 Swift 训练 LLM:从矩阵乘法性能优化开始补底层课
Cocoa with Love 发布了“使用 Swift 训练大型语言模型”的系列文章,第一部分聚焦矩阵乘法性能优化,从 GFLOP/s 提升到 TFLOP/s 级别。
技术信息:
主题:用 Swift 训练 LLM 切入点:矩阵乘法性能优化 性能目标:从 GFLOP/s 向 TFLOP/s 提升 价值:探索非传统深度学习技术栈的可行性
这类内容看起来不如模型发布热闹,但对开发者更有价值。因为 AI 工程正在进入“底层能力再分配”阶段:不是所有人都只能在 Python、CUDA、主流框架里工作。
说白了,AI 应用越普及,底层优化就越值钱。大家都在调用模型的时候,能理解算子、内存、矩阵乘法的人,反而更稀缺。
参考链接:
TechRadar[https://www.techradar.com/pro/tiny-company-steals-amds-thunder-and-challenges-nvidia-with-old-tech-pcie-ai-accelerator-that-runs-700b-llms-locally-sipping-just-240w-thanks-to-decade-old-ddr4-and-28nm-chips] Cocoa with Love[https://www.cocoawithlove.com/blog/matrix-multiplications-swift.html]
💡 AI 行业观察
1. AI Agent 的下一道门槛不是“更聪明”,而是“更可信”
今天的新闻里,ClaudeBleed 浏览器扩展漏洞、企业引入 AI 编程工具、Agent 可以观察屏幕的项目,放在一起看,其实指向同一个问题:AI Agent 的权限越来越大,但信任机制还没跟上。
过去,AI 工具主要帮你写一段文案、补一段代码;现在,它要看你的屏幕、读你的仓库、操作你的浏览器、进入你的工作流。
这就麻烦了。
能力越强,风险越不只是“回答错了”。它会变成数据泄露、权限滥用、供应链安全、审计缺失。AI Agent 真正商业化之前,必须先补安全这一课。否则越自动化,越像把钥匙交给一个还没完全体检过的助手。
2. 本地 AI 的热度上来,本质是大家开始重新计算“云端依赖成本”
“Local AI needs to be the norm”、本地 AI 加速器、Chrome AI 功能占用本地存储,这些看似分散的讨论,实际都围绕一个核心:AI 到底应该跑在云端,还是更多跑在本地?
云端强,弹性好,升级快。但代价也明显:成本、隐私、延迟、网络依赖,以及越来越复杂的数据合规问题。
本地 AI 不是复古,而是一种反向平衡。尤其是企业、开发者和高隐私场景,会越来越在意“模型在哪里运行”。这不会取代云端大模型,但会把 AI 架构从单一云端,推向云、本地、边缘混合。
参考链接:
LayerX Security[https://layerxsecurity.com/blog/a-flaw-in-claudes-browser-extension-allows-any-extension-to-hijack-it] Hacker News[https://news.ycombinator.com/item?id=48085821] Hacker News[https://news.ycombinator.com/item?id=48084710]
🛠️ 工具推荐
1. Gawk Dev:追踪 AI 工具动态的实时看板
类型: AI 工具追踪平台核心功能: 聚合并展示各类 AI 工具的更新动态,适合快速了解新产品、新功能和生态变化。适合人群: AI 产品经理、内容创作者、创业者、工具研究者。获取方式: Gawk Dev[https://gawk.dev]
推荐它的原因很简单:现在 AI 工具太多了,真正的问题不是“没有工具”,而是“根本跟不过来”。这类追踪工具的价值,就是帮你把信息噪音先压一层。
2. PerceptAI:让 AI Agent 观察屏幕,而不只局限在浏览器里
类型: AI Agent 感知工具 / 屏幕观察项目核心功能: 让 AI Agent 能够观察任意屏幕环境,而不是只在浏览器网页中工作。适合人群: Agent 开发者、自动化工作流设计者、AI 产品实验团队。获取方式: Hacker News 讨论页[https://news.ycombinator.com/item?id=48085738]
这个项目值得关注,但不建议普通用户马上冲。屏幕观察能力很强,也很敏感。它一旦进入办公环境,权限边界、隐私保护和误操作风险都必须重新设计。
参考链接:
Gawk Dev[https://gawk.dev] Hacker News[https://news.ycombinator.com/item?id=48085738]
结语:AI 真正进入工作流,问题才刚开始
这一期最值得记住的不是某一个模型,也不是某一个工具,而是一个趋势:AI 正在从“会聊天”进入“能做事”。
能做事,当然更有价值。
但也更麻烦。它需要权限,需要数据,需要审计,需要责任边界。过去我们讨论 AI,常问“它聪不聪明”;接下来更该问的是:它拿到了什么权限?它能影响什么结果?出了错怎么回滚?
这才是 AI 应用进入深水区的标志。
本文所有信息均来自公开报道,文中已标注原始链接供进一步阅读
