 夜雨聆风
夜雨聆风
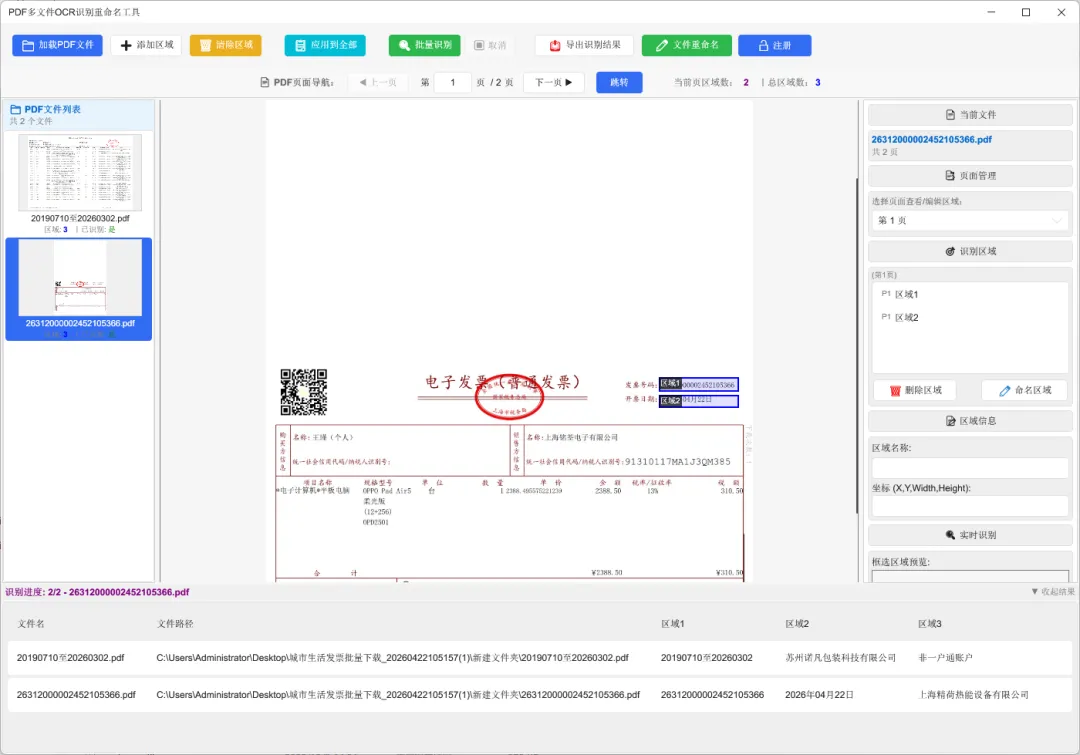
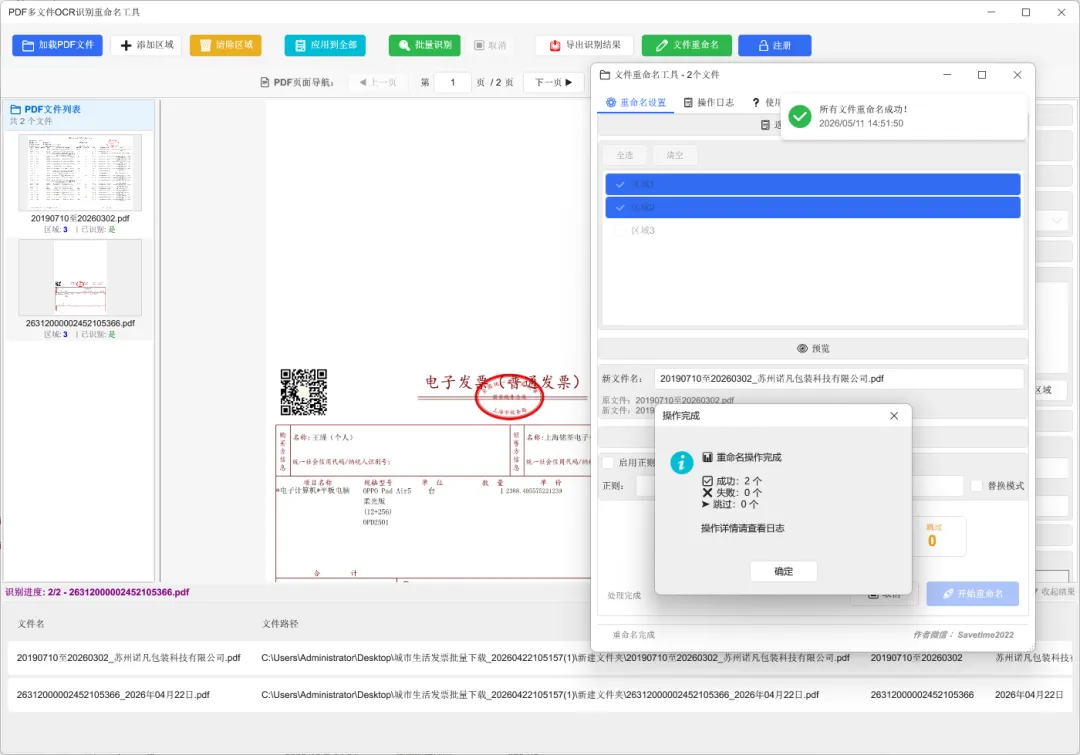
还在为多页PDF的识别而烦恼吗?面对结构各异的文件,手动重命名不仅耗时耗力,还容易出错。现在,一款全新的PDF批量识别与重命名工具,将彻底改变你的工作方式,让复杂文件的处理变得简单高效。
核心优势:智能区域设置功能
- 可视化框选识别区域
:你可以像使用画图工具一样,轻松指定需要识别的内容。 - 逐页灵活配置
:无论是单页还是多页PDF,都能逐页灵活配置识别区域,确保每一个关键信息都不被遗漏。 - 独立配置互不干扰
:每个文件的配置都是独立的,互不干扰。即使面对成百上千个结构完全不同的PDF文件,也能为它们一一量身定制识别方案,精准提取所需信息。
批量识别:灵活应对不同结构
- 结构相同的PDF文件
:比如统一格式的发票或合同,只需设置好第一个文件的识别区域,然后点击“应用到全部”,即可一键同步参数,实现批量快速识别。 - 结构不同的PDF文件
:比如来自不同公司的协议或不同格式的试卷,可以逐个文件进行独立设置,确保识别的准确性。无论文件结构如何变化,只要保证区域名称一致,批量识别后就能统一进行智能重命名。
自动命名:告别手动重命名
- OCR识别结果直接命名
:OCR识别的结果可以直接用于文件名,彻底告别了手动重命名的繁琐。 - 自定义命名规则
:你可以根据需要自定义命名规则,例如“{合同编号}{签约方}{日期}.pdf”,让文件命名变得规范有序。 - 支持正则表达式
:对于有更高需求的用户,工具还支持正则表达式,可以进行更复杂的高级处理,满足各种个性化命名需求。
适用行业:多场景高效解决方案
这款工具适用于财务、行政、教育、医疗、物流等多个行业。
| 财务 | |
| 行政 | |
| 教育 |
无论你的工作场景多么复杂,这款工具都能为你提供高效的解决方案。
操作简单:零代码门槛,人人可用
- 可视化操作界面
:无需任何编程知识,零代码门槛,人人都能轻松上手。 - 批量处理能力
:让效率提升10倍以上。 - 参数导入导出功能
:方便你复用配置,进一步节省时间。
之前可能需要一整天才能完成的手动重命名工作,现在只需10分钟就能搞定,识别准确率极高,基本无需二次校对。
拥抱智能高效新时代
告别手动重命名的痛苦,拥抱智能高效的PDF处理新时代。让这款工具成为你工作中的得力助手,释放你的时间和精力,专注于更有价值的工作。
