 夜雨聆风
夜雨聆风

📚 AI算力网络专题系列 · 持续更新中
第①篇:配过 OSPF做过 QoS但 AI 集群的网络为什么让你看不懂?
第③篇:为什么 AI 集群宁可网络变慢,也不能让 PFC 频繁触发?
第④篇:AI 集群网络调优:ECN 水位线没配好,你知道会发生什么吗?
番外篇①:InfiniBand 完整体系拆解:从 RDMA 原理到 Rail 拓扑设计
番外篇②:AI 集群负载均衡:为什么 ECMP 在 AI 训练场景下会失效?
第⑥篇:Incast 流量为什么是 RoCEv2 集群最难解决的问题?(本篇)
前情回顾
前五篇建立了以下认知框架:
AllReduce 要求所有 GPU 全员同步, 最慢的节点决定整个集群的训练效率。
RDMA / RoCEv2 实现亚微秒级零拷贝传输, 但对丢包零容忍——一个包丢失,QP 报错, 恢复代价是正常延迟的 10 万倍。
PFC / ECN / DCQCN 三层机制协同保障无损传输, ECN 提前感知拥塞,DCQCN 主动降速, PFC 作为最后一道防线兜底。
负载均衡(NSLB / Adaptive Routing)解决 ECMP 哈希冲突导致的链路不均问题。
然而,即便以上机制全部就位、配置正确, RoCEv2 集群仍然存在一个几乎无法完全消除的场景——
Incast
什么是 Incast?
Incast,直译为"内向流量聚合", 描述的是这样一种流量模式:
多个发送方在同一时刻, 向同一个接收方发送大量数据, 流量在接收方的上联交换机端口瞬间汇聚。
在 AI 训练场景中,Incast 几乎是必然发生的:
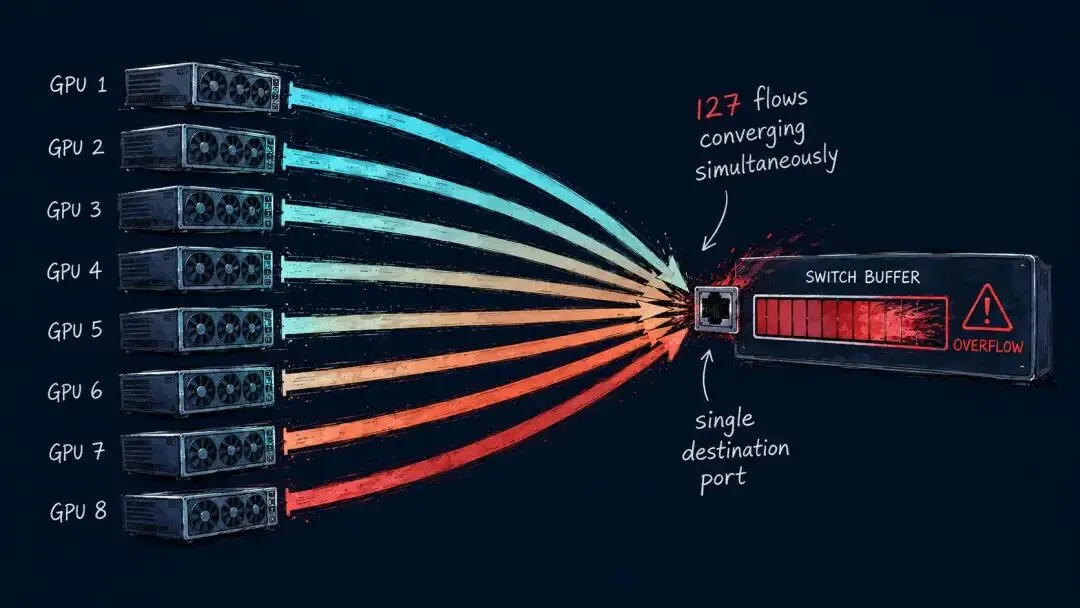
AllReduce 的 Reduce 阶段, 所有 GPU 需要将各自的梯度数据 汇聚到同一个节点或同一组节点进行聚合。
假设集群有 128 块 GPU, 在 AllReduce 的某个时间窗口内, 127 块 GPU 同时向 1 块 GPU 发送数据——
127 条流量在同一时刻涌向同一个交换机端口。
这就是 Incast
Incast 对 RoCEv2 如此危险?
理解 Incast 的危险性, 需要从交换机缓冲区的物理特性说起。
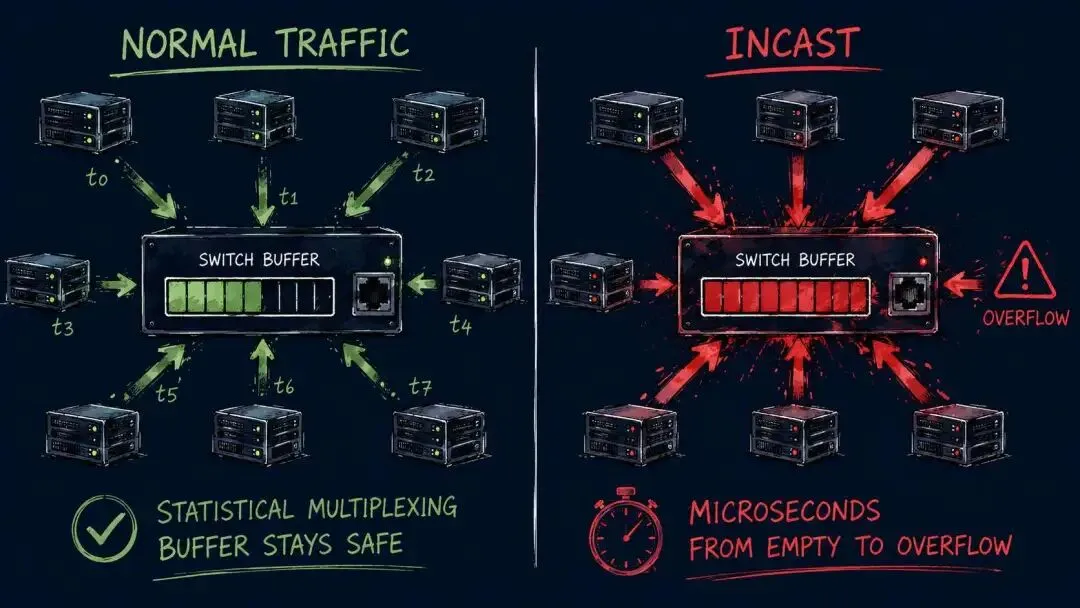
现代数据中心交换机的缓冲区设计, 基于的是统计复用的假设—— 不同来源的流量在时间上随机分布, 缓冲区只需要应对短时的突发, 不需要容纳所有端口的满速流量。
Incast 完全打破了这个假设:
多条流量精确同步地到达同一个端口, 不存在任何统计复用效应, 缓冲区在极短时间内从空到满。
填满的速度取决于入端口数量和链路速率。
以 400G 网络为例: 32 个发送方同时以满速发送, 汇聚到一个 400G 出端口, 等效入流量达到 12.8 Tbps, 而出端口只有 400G 的转发能力。
缓冲区填满的时间:微秒级。
Incast 为什么能绕过 ECN 和 DCQCN?
前几篇讲过,ECN 和 DCQCN 的工作流程是:
交换机队列超过 Kmin→ ECN 标记数据包→ 接收方生成 CNP→ CNP 经过网络传回发送方→ 发送方 DCQCN 降速这个流程有一个隐含的时间成本:
CNP 从接收方传回发送方,需要一个完整的往返时延(RTT)。
在 400G 网络的典型集群内, 单跳 RTT 约为 1-5 微秒。
Incast 场景下, 缓冲区从空到满的时间可能只有 几微秒——
CNP 还没有发出去,缓冲区已经溢出; DCQCN 的降速指令还没有到达发送方,丢包已经发生。
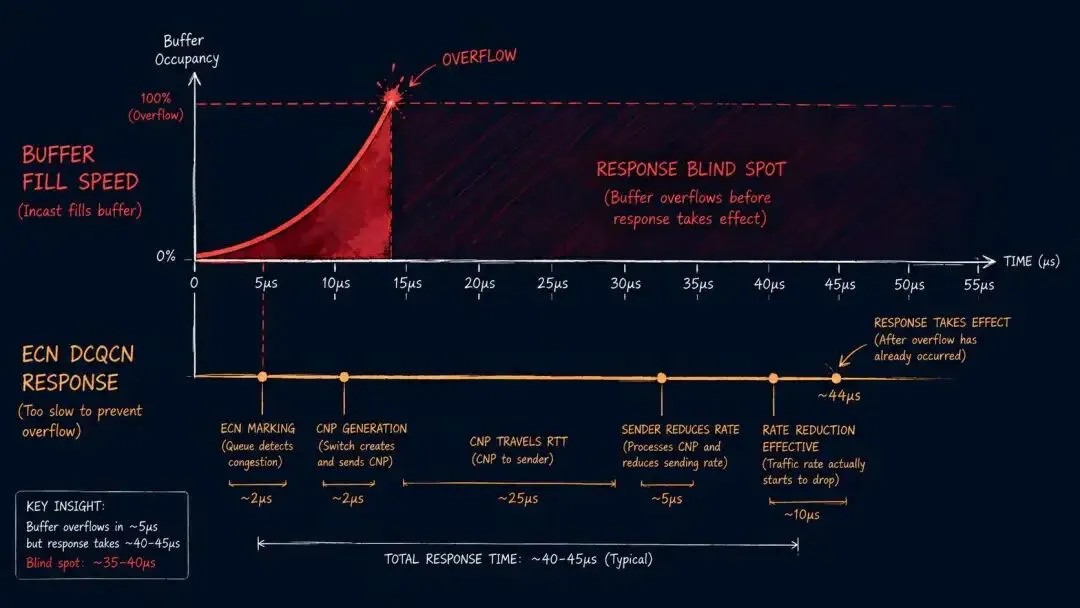
ECN 和 DCQCN 的响应速度, 在 Incast 面前根本来不及介入。
PFC 能救 Incast 吗?
按照前几篇的逻辑, ECN 来不及响应时,PFC 应当作为最后一道防线介入。
但 Incast 场景下,PFC 同样面临时序问题:
PFC 的触发条件是缓冲区水位到达阈值, 触发之后 PAUSE 帧需要经过网络传达上游, 上游收到 PAUSE 帧才能停止发送。
这个过程同样需要时间—— 而 Incast 的缓冲区填充速度, 可能快过 PAUSE 帧的传播速度。
更严重的问题在于:
Incast 的流量来自多个方向, PFC 的 PAUSE 帧需要同时向所有上游发送方传播。
PAUSE 帧传播期间, 所有发送方仍在以满速注入流量, 缓冲区继续积累。
结果是: PFC 触发了,但丢包也发生了。
Incast 造成的连锁反应
Incast 引发丢包后, RoCEv2 集群的反应是灾难性的:
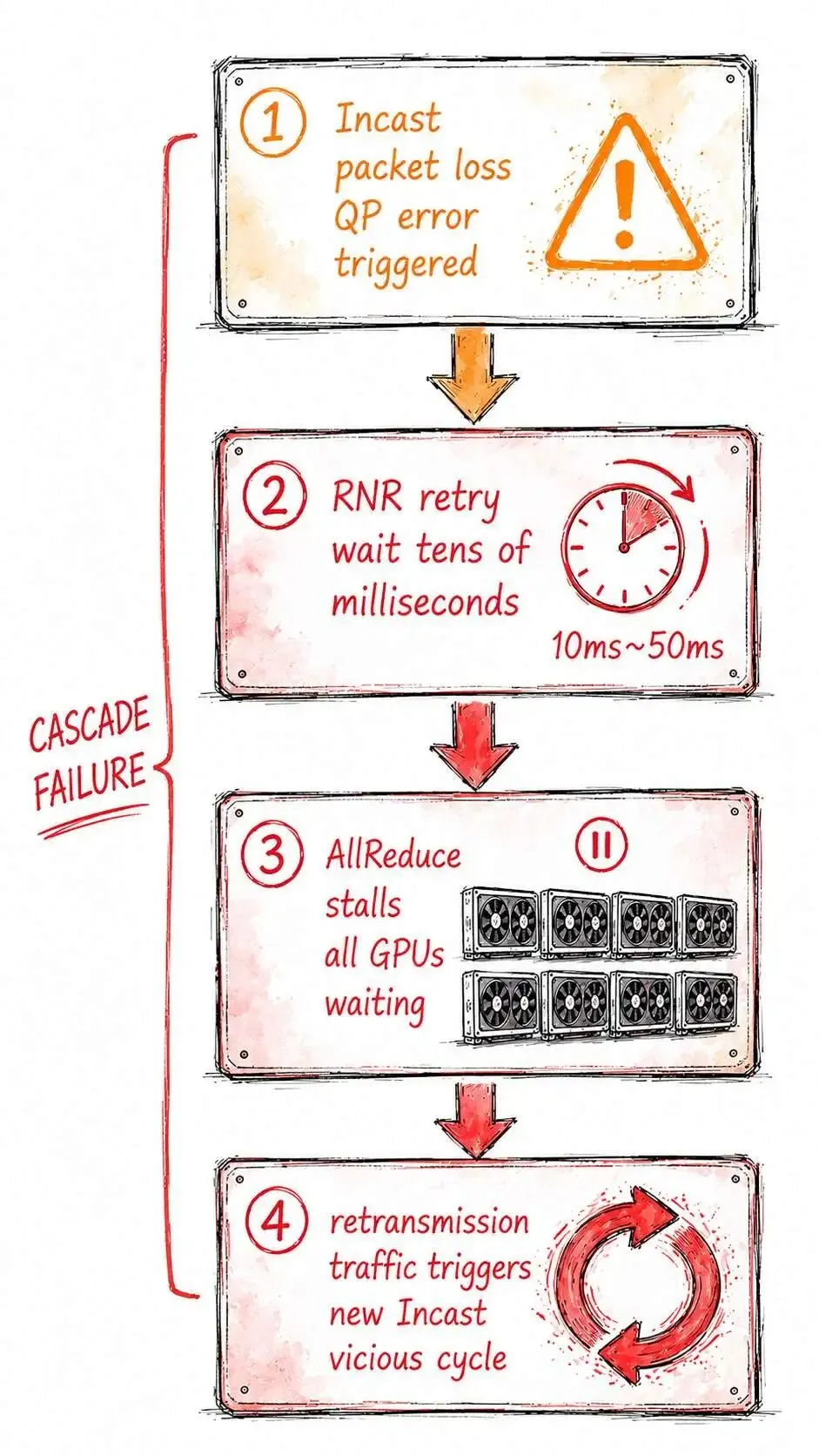
第一步:QP 报错丢包导致接收方 QP 队列序号不连续, 对应 QP 进入错误状态。
第二步:RNR 重试等待发送方收到错误通知, 进入 RNR(Receiver Not Ready)重试流程, 等待时间默认为数十毫秒。
第三步:AllReduce 停滞参与 AllReduce 的所有 GPU 等待报错的 QP 恢复, 训练迭代无法推进。
第四步:PFC 风暴风险大量 QP 同时报错, 重传流量叠加正常训练流量, 再次触发 Incast,形成恶性循环。
一次 Incast 引发的丢包, 可能导致整个训练任务停滞数百毫秒甚至数秒—— 在高频迭代的大模型训练中, 这是不可接受的代价。
如何缓解 Incast?
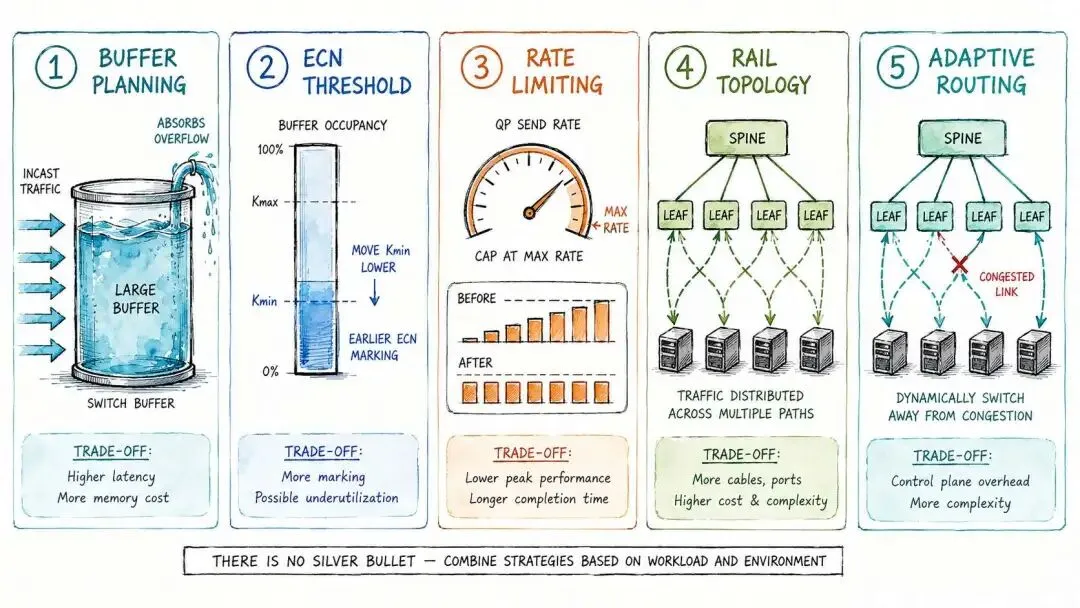
Incast 无法被彻底消除, 但可以通过多层手段将其影响降至可接受范围:
手段一:交换机缓冲区规划
增大交换机的共享缓冲区(Shared Buffer), 为 Incast 流量的瞬间汇聚提供更大的吸收空间。
400G 时代,AI 集群交换机的缓冲区规划 已从普通数据中心的 MB 级提升至 数百 MB 级。
缓冲区越大,能够吸收的 Incast 突发越多, 但同时也会增加尾延迟和 PFC 触发后的恢复时间。
手段二:ECN 水位线前置
将 Kmin 设置得更低, 让 ECN 在队列水位尚低时就开始标记, 尽量在缓冲区填满之前触发发送方降速。
代价是正常流量也可能频繁触发 ECN 标记, 带宽利用率有所下降。
手段三:速率限制(Rate Limiting)
在发送方 RNIC 层面, 对每个 QP 设置最大发送速率上限, 防止多个 QP 同时以满速注入流量。
这是一种主动的预防手段, 代价是单流带宽受到限制。
手段四:拓扑层面的流量分散
通过 Rail-Optimized 组网, 让同一个 AllReduce 任务的流量 尽量分散到不同的 Spine 交换机路径, 避免流量在单一节点汇聚。
手段五:自适应路由(AR / NSLB)
实时感知链路负载, 在 Incast 形成之前将流量引导至空闲路径。
番外篇②已经详细介绍了 华为 NSLB 和英伟达 Adaptive Routing 的机制, 两者都将 Incast 缓解作为核心设计目标之一。
Incast 是 RoCEv2 集群最难解决的问题?
总结一下 Incast 的特殊性:
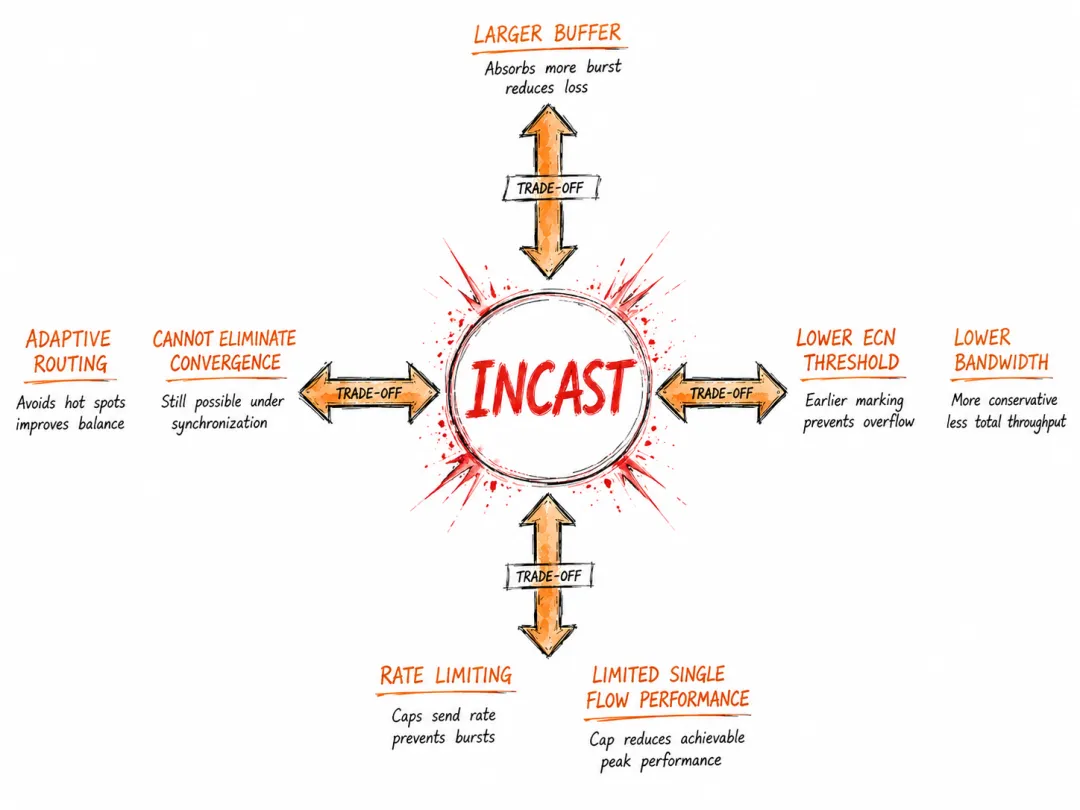
① 物理层面无法避免AllReduce 的通信模式决定了流量汇聚的必然性, 这是算法层面的约束,网络无法改变。
② 现有机制的响应速度不足ECN/DCQCN 依赖 RTT 传递信号, PFC 依赖 PAUSE 帧传播, 两者的响应时间均长于 Incast 的缓冲区填充时间。
③ 后果严重且连锁一次丢包触发 QP 报错, QP 报错导致 AllReduce 停滞, 停滞期间的重传流量叠加再次触发 Incast, 形成难以自愈的恶性循环。
④ 缓解手段之间存在矛盾增大缓冲区会增加尾延迟; 降低 ECN 水位线会降低带宽利用率; 速率限制会限制单流性能; 自适应路由无法完全消除流量汇聚。
没有任何单一手段能够完全解决 Incast, 工程实践中需要根据集群规模、训练任务特征、 硬件条件,在多种手段之间寻找平衡。
这也是为什么 Incast 的处理, 是 AI 集群网络调优中最考验工程经验的环节之一。
小结
Incast 是多个发送方在同一时刻向同一接收方汇聚流量的场景, 在 AllReduce 的通信模式下几乎不可避免。
Incast 的缓冲区填充速度快于 ECN/DCQCN 和 PFC 的响应时间, 导致现有拥塞控制机制在 Incast 面前存在响应盲区。
通过缓冲区规划、ECN 水位前置、速率限制、 拓扑分散、自适应路由五种手段综合缓解 Incast 影响, 但无法彻底消除。
📌 想动手验证?
YESLAB《AI算力中心网络架构专家课》 模块8「无损网络与性能调优」包含Incast 拥塞实验
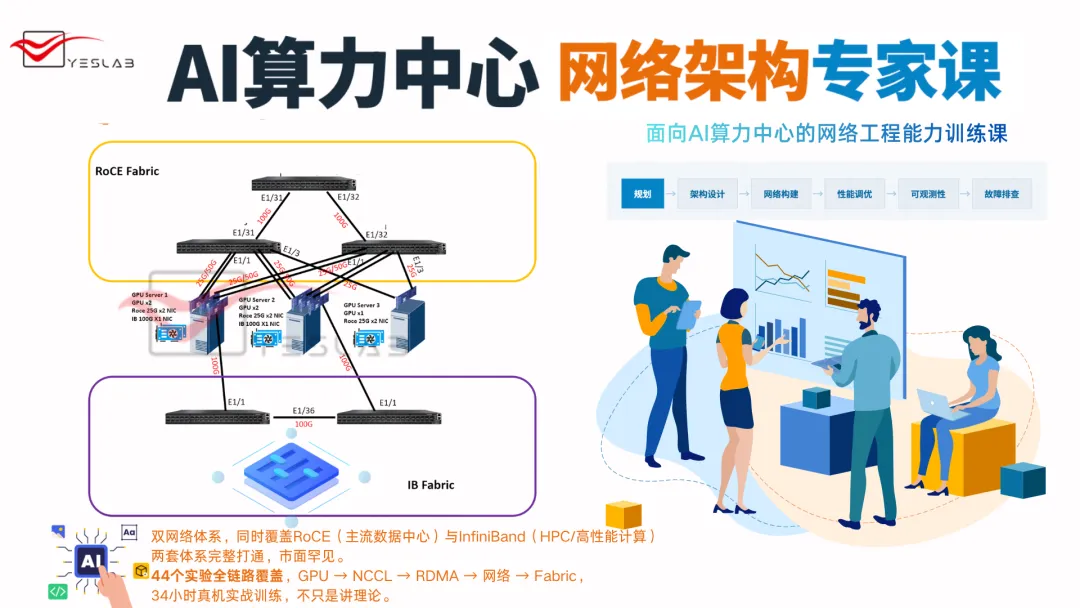
—— 在真实环境中构建 Incast 场景, 观察缓冲区水位、PFC 触发次数、 QP 报错频率的完整变化过程, 验证不同缓解手段的实际效果。
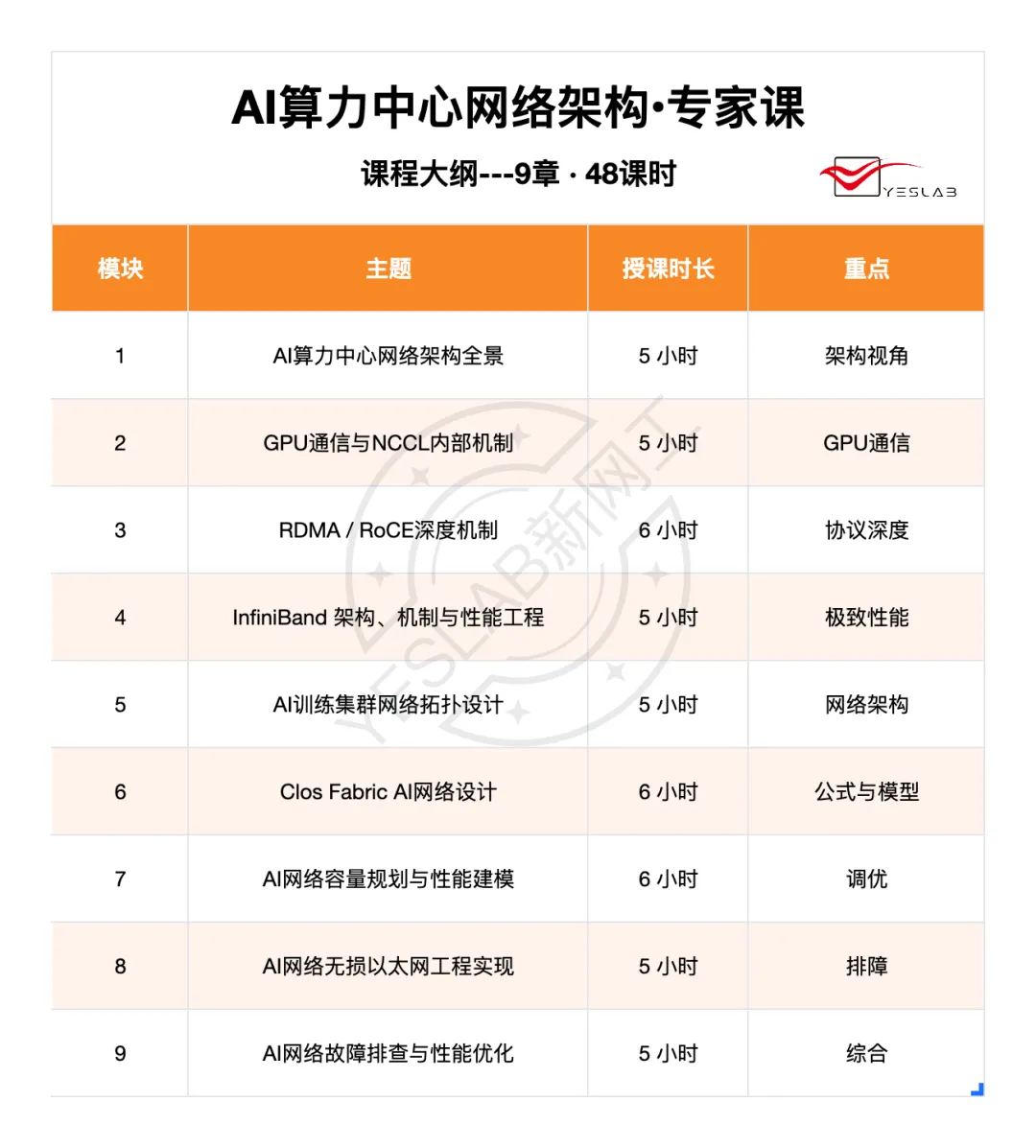
9章 · 48课时 · 44个高阶实验 · 34小时实操训练
覆盖架构建模、性能调优、故障排查三大能力体系



无论你是网络工程的初学者,还是希望提升技能的专业人士,YESLAB致力于提供系统化的技术学习资源。通过灵活的学习模式和实战案例解析,帮助你逐步构建专业知识体系,探索职业发展的可能性。加入YESLAB,与行业爱好者共同成长,如需了解更多学习资源,可联系课程顾问获取,开启你的技术进阶之旅!
