 夜雨聆风
夜雨聆风一、背景
现在越来越多公司给员工发放了tokens,行业里一般会有统一的 LLM 接入网关,所有团队的大模型调用流量都走他;包括 研发、测试、数据、AI 平台等多个组都从同一个入口出去。统一网关带的好处是可以集中鉴权、集中计费、集中模型路由、集中限流。
但所有人共享的高成本入口,本质上就是一个新的攻击面与合规盲区,具体到我们这边,问题在以下三个维度同时显现:
- 成本维度
:某个月账单同比上涨近 40%,但定位不到具体责任人。我们能看到 user_id、model、token 数,却回答不了一个最关键的问题 —— 这些花费是否合理。 - 安全维度
:LLM 调用的提示词里可能裹挟着 SSH 私钥、AWS Secret、数据库密码、内网拓扑、 /etc/shadow内容。每一条 prompt 都是一次潜在的数据外泄通道。 - 合规维度
:员工是否在用公司 key 处理副业?已离职员工的 key 是否还在被使用?远程办公时的源 IP 是否合规?这些都没有抓手。
传统 SIEM 体系面对 LLM 流量是盲区,所以我们决定自建一套面向 LLM 流量的安全分析平台,目标是让"每一次调用都可解释、可追责、可处置"。
二、违规案例
平台灰度的当天下午到次日凌晨,告警面板触发了几十条事件。挑两个最能说明问题的样本(已脱敏)。
2.1 非业务用途
某测试组同学,过去两周日均调用量平稳,最近三天突然飙升至基线的 6 倍以上,叠加 ark-code 高成本模型占比异常。下钻到原始 prompt 后发现规律性的关键词分布:
帮我润色个人博客文章毕业设计要做的微信小程序方案副业接的电商后台原型私活客户要的预约系统
平台基于"个人用途关键词词典"在单日命中阈值以上,自动打上 SIDE_PROJECT_KEYWORDS 标签,并与 VOLUME_SPIKE、HIGH_COST_MODEL 三条告警形成关联画像。整条证据链 —— 从 prompt 原文到 IP、UA、时间分布、成本曲线 —— 都可以在控制台一键调出。
我们没有走声讨流程,而是把告警同步给了对应 leader。员工本人在第二天主动认领并整改。整个处置过程不需要任何人工对账。
2.2 横向移动尝试
凌晨 02:13 至 02:18,平台连续推送三条 critical 级告警,全部聚合到同一个用户账号下:
RULE_CREDENTIAL_HARVEST | cat /etc/shadowAWS_ACCESS_KEY_ID=AKIA...、.env DATABASE_PASSWORD=... | |
RULE_K8S_PROBE | kubectl get pods -Akube-system namespace 里 etcd secret 怎么导出 | |
RULE_SYSTEM_PERSISTENCE | bash -i >& /dev/tcp/.../4444authorized_keys |
排查之后发现这个账号持有人两周前已经离职,但 API key 未走完回收流程。源 IP 是公网地址,UA 是 curl/7.81.0,和这个员工历史画像不符。
值班同学在告警推送后约 35 分钟内完成 key 吊销 + 源 IP 封禁 + 横向访问审计。如果没有这套系统,这条 key 大概率要等到下个月对账时才会被人注意到。
三、技术方案
出于内部使用规避和最小化攻击者对抗信息的考虑,本节仅给出架构层面的描述,不展开具体规则参数与算法细节。
整套系统采用"采集 — 检测 — 分析"三层解耦架构:
3.1 采集层
在 LiteLLM 的 callback 机制上挂载自研的结构化日志采集器,将每一次请求的关键字段统一沉淀为事件流:
调用主体: user_id、user_email、team_id、key_alias调用上下文: model、endpoint、messages、response_text网络指纹: ip_address、user_agent资源消耗: input_tokens、output_tokens、cost_usd、latency_ms业务结果: status_code、error
对网关业务零侵入,单次调用引入的延迟开销在亚毫秒级。事件流支持 JSONL 落地与流式转发两种模式,便于后续对接公司既有的数据中台。
3.2 检测层
检测能力沿五个维度展开,覆盖企业 LLM 滥用的主要场景:
| 时间维度 | |
| 内容维度 | |
| 流量维度 | |
| 网络维度 | |
| 行为维度 |
每条规则都带有:
- 去重分桶策略
:按 (user, day)、(user, hour)、(user, minute)、(ip, hour)等粒度做幂等,避免同一行为反复轰炸告警通道 - 滚动基线
:流量类与成本类规则使用 14 天滚动窗口计算个体基线,横向对比(同事之间)与纵向对比(自身历史)双重确认,降低对新人/项目立项期的误报 - 严重级别分级
: critical / high / medium / low四档,对应不同的通知通路与响应 SLA - 可解释证据链
:每条告警都附带原始事件指针 + 结构化证据 JSON,下游可直接渲染、复盘、溯源
3.3 分析层
面向安全同学和 leader 的 Web 控制台提供了三个核心视图:
- 告警视图
:按规则、严重级别、时间窗、用户多维筛选,支持一键变更告警状态(待处理 / 已复核 / 已忽略) - 用户画像视图
:按人聚合的调用统计、模型偏好、IP/UA 分布、24 小时调用热力,以及该用户名下的全部历史告警 - 规则视图
:每条规则的命中次数、影响人数、典型样本,便于规则有效性回溯与持续调优
证据链做了双向关联 —— 从告警可下钻到原始事件,从事件可反查所属告警,完全闭环。
四、效果数据
平台从立项到首版上线约一周时间,灰度运行两天后的关键指标:
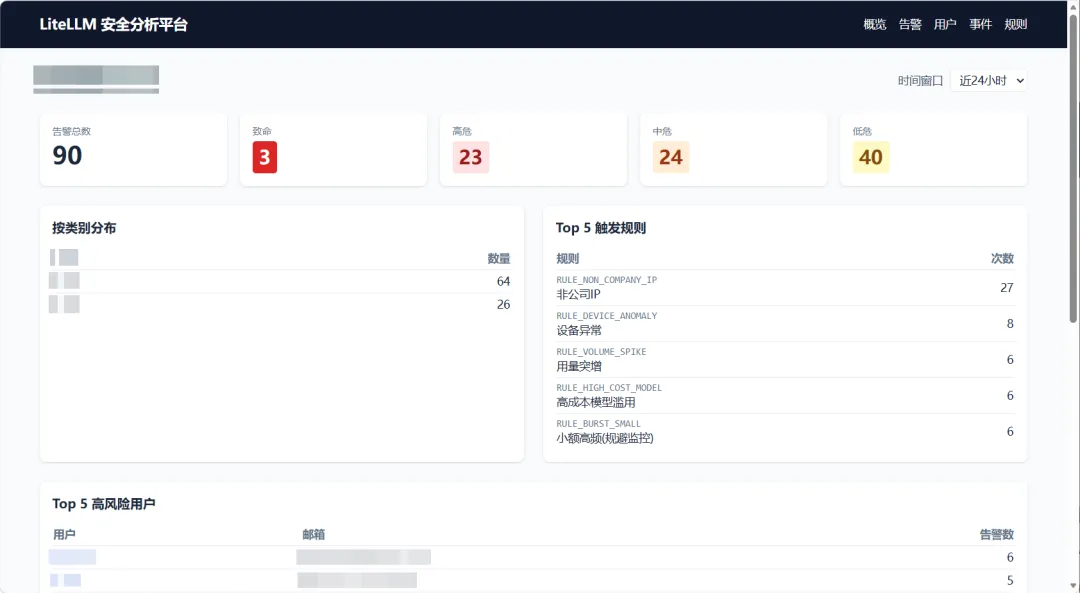
4.1 首页
下图中安全运营总览。左上为关键指标卡(24h 调用数、活跃用户、告警总量、待处理告警),中部为按规则维度的告警分布,下方为最近告警时间线。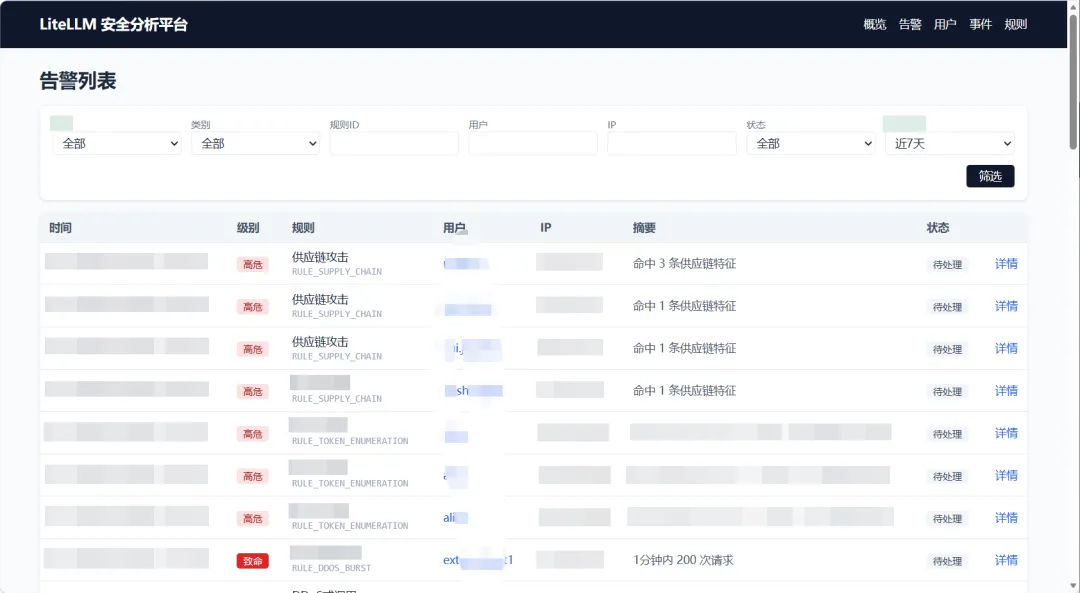
整个团队的 LLM 调用风险水位,一屏可见。日常巡检只需 30 秒。
4.2 告警列表
图 2 · 告警列表(Alerts)
告警工单视图。支持按严重级别、规则、时间窗、用户多维筛选,每条告警附带证据摘要与一键下钻入口;右侧状态列对应"待处理 / 已复核 / 已忽略"三态工单流转。
安全同学每天面对的不再是几十万行原始日志,而是结构化、可分派、可闭环的告警工单。
图 3 · 规则中心(Rules)
检测规则中心。覆盖时间、内容、流量、网络、行为五个维度共十余条规则,每条规则展示其严重级别、命中次数、影响用户数与最近一次触发时间。

规则即文档 —— 每条规则的有效性、覆盖率、误报率都在这里持续被度量和迭代。
| 100% | |
| 下降约 18% | |
最后一个数字尤其值得说一下 —— 没有发任何通知、没有开会、没有约谈,仅仅是"系统上线"这一个动作本身,就让非工时调用曲线主动回落了一半。可观测性本身就是治理力。
五、不足与改进
第一版本已经上线,不过现在的阶段还有短板:
- 规则驱动的天花板
:对"低速、慢节奏、分散化"的攻击模式(典型如分散在数百次小批量请求中的数据外泄)覆盖能力有限。下一阶段计划引入 UEBA(用户行为画像) 思路,基于历史行为做漂移检测。 - 语义检测仍偏粗粒度
:当前内容类规则以关键词与正则为主,对刻意改写、编码绕过、多轮拆分等手法识别率不够。计划引入轻量分类模型对 prompt 做语义分级,并探索 prompt-injection 的对抗检测。 - 告警降噪需要持续运营
:上线初期我们也被自己的告警刷屏过,后续依靠分桶 + 严重级别分级 + 状态机收敛才达到目前的可读性。规则阈值仍需要根据业务季节性持续调优。 - 响应链路尚未完全闭环
:目前止步于"通知到人",理想状态应当支持自动化处置 —— key 权限自动降级、源 IP 临时封禁、强制二次认证、调用链路熔断等。这部分需要与 IAM、网关限流模块深度联动。 - 可视化体验仍偏功能向
:作为内部工具尚可,对外演示和向非安全同学解释时还需更多叙事化的视图(如攻击者画像时间线、风险趋势热力等)。
请注意,本文章内容纯属虚构,请不要对号入座~
作者:汤青松微信:songboy8888日期:2026年5月11日
