 夜雨聆风
夜雨聆风当算力增长 90,000 倍、内存带宽只增长 30 倍——这不是商业竞争,这是物理学在说话。
做信号完整性的人都知道:通道的频宽决定了数据能跑多快。但 AI 产业花了十年才发现——算力堆到天上的时候,最慢的环节不是计算,是把数据搬到计算单元的通道。这个通道,恰好是 SI 工程师的老本行。
一、算力飞了,数据在爬——物理学从不说谎
先看三个数字。它们在一个工程师眼里,构成的不只是"趋势",是物理定律在工程现实上划出的红线。
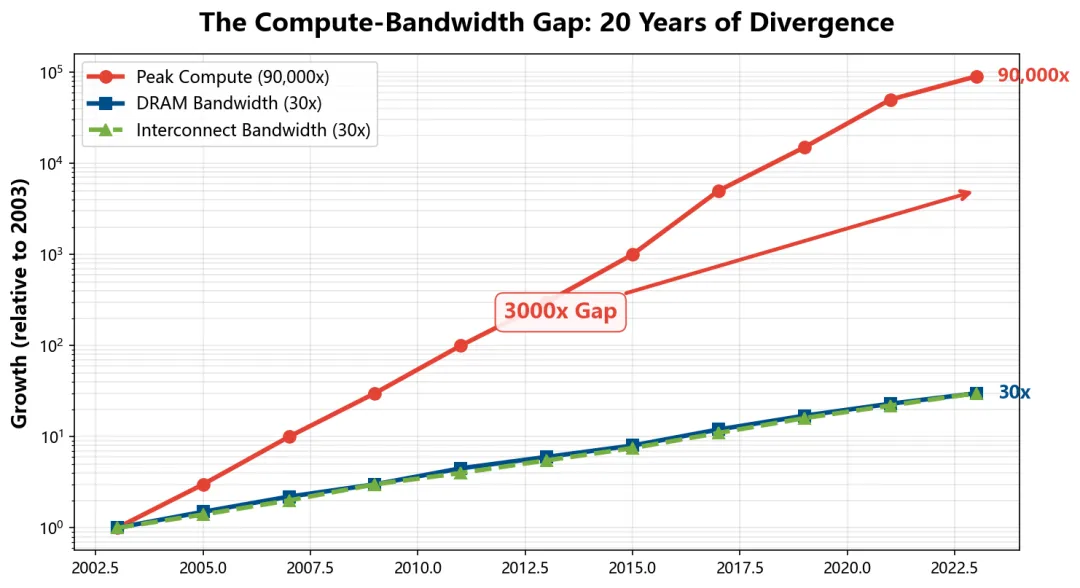
过去 20 年:峰值计算能力增长 90,000×,DRAM 带宽增长 30×,互连带宽增长 30×。差距 = 3,000 倍。
—— IEEE Emerging AI Accelerator Workshop,Manouchehr Rafie (HPE 首席架构师)
这个 3000 倍不是某个公司的管理问题。是物理学:
计算密度跟晶体管工艺走——摩尔定律的尾巴上,FinFET 还能往 3nm 挤。 内存带宽爬得慢——HBM 堆叠走 TSV,热密度和物理尺寸双天花板。 互连带宽更惨——PCB 上的铜皮损耗跟 tanδ 走,FR-4 在 28GHz 的超肤效应损耗不是优化布线能解决的。
这就是说:一块 H100 的 SM 单元算得再快,数据队排到芯片外面去了。90% 的时间不是在算——是在等。对于训练,可以用批量 (batching) 掩盖延迟。对于推理,每个请求等不了别人。上一个请求的 token 没算完,下一个用户的刷新键已经按了三遍。
再看 AI 模型参数的膨胀速度:
Transformer 参数每 2 年增长 750×,GPU 内存容量每 2 年仅增长 2×。
以 Llama 3 70B (FP16) 为例:权重 140GB。一张 H100 装不下——至少两张。一台双路 Xeon 服务器轻松插 512GB DDR5——价格不到 GPU 的 1/3。不是算力问题,是内存够不够的问题。
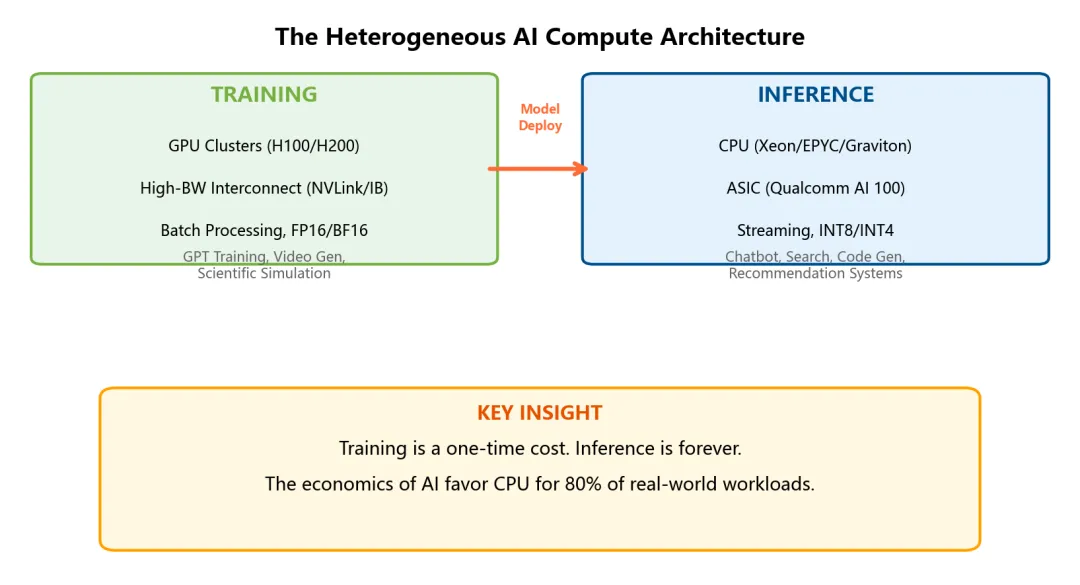
二、推理不是训练——当 AI 从"算一次"变成"算一辈子"
这是整个逻辑的转折点。训练和推理的硬件需求——是一个问题,两种答案。
训练要的是吞吐:一次喂进去几百万个 token,GPU 的数千核全跑满了,并行度越高越好。一次训练跑几周,电费是 FAANG 级别公司的预算。
推理要的是延迟和通量密度:每个请求独立,batch size = 1,来一个算一个,算完就回——等不起 batching。但每天的请求量是数十亿次。这时候,每 token 成本乘上请求量,就是天文数字。
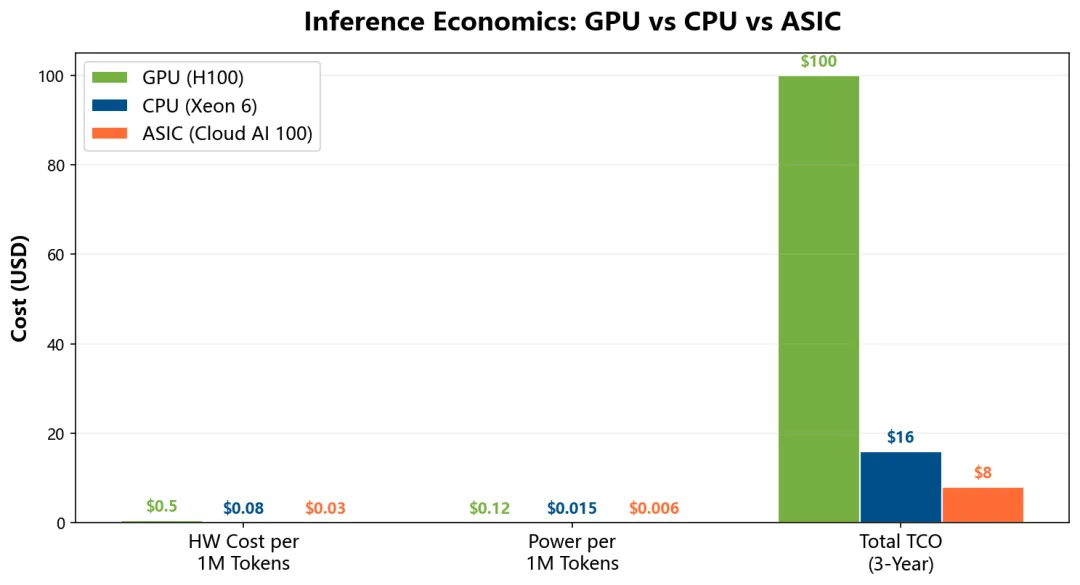
Qualcomm Cloud AI 100 实测:同等功耗下,推理性能是行业领先 GPU 的 2-4×。Perf/TCO 优势同样是 2-4×。
—— Evgeni Gousev, Qualcomm VP, IEEE Emerging AI Accelerator Workshop
为什么?因为 GPU 的并行架构是为训练优化的——矩阵乘法用 Tensor Core 并行,但推理的瓶颈不在矩阵乘法。
AI 推理的真正瓶颈是内存带宽,不是 FLOPS。
每个 token——自回归生成——读完整个模型权重,算一层,吐一个 token。70B 模型,每个 token 要把 140GB 权重从内存读到计算单元。GPU 用 HBM(高带宽但容量小),CPU 用 DDR5(容量大得多,每个内存通道独立)。当模型大到一张卡装不下时,卡间 NVLink 的开销吃掉所有 FLOPS 优势。
计算口诀:推理 token/s ≈ 内存带宽 / (模型参数量 × 2 bytes)。谁的带宽/容量比更匹配模型,谁就赢。这不是 GPU vs CPU 的争论——是物理定律对两种内存架构的裁决。
三、产业已经在动了——这不是预言,是正在进行
DesignCon 2026 的 Track 7 论文(Reinventing the Backplane: Why AI Demands an Architecture Revolution)一针见血:当机柜内加速器从 72 个向 1024 个扩张,每条 SerDes 链路推 224Gbps 时,PCB 走线的插入损耗已经逼到了物理极限——必须在关键链路中插入 Retimer。
每一级 Retimer = 增加功耗 + 增加延迟。无脑堆 GPU 的边际成本在指数级上升。
代价落到账本上——明明白白:
DesignCon 2026 上有一个令人会心一笑的注脚——电源完整性(PI)专家组在专题讨论中坦白:
"GPU 功耗激增是下一代 PI 最大的挑战。我们正在用 AI(跑在 CPU 上)来优化 PI——讽刺的是,GPU 制造了问题,CPU 上的 AI 在解决它。"
—— DesignCon 2026 Panel: "Powering the Future: AI's Role in Next-Generation Power Integrity Solutions"

四、CPU 的回应不是"变快了",是懂了什么叫专用计算
回顾计算机架构史,有一个剧本反复上演:某个专用处理器在某项任务上远超通用 CPU → CPU 吸收专用处理器的设计思想 → 以通用形态反超。
1970 年代,小型机威胁大型机,IBM 推出 PC 反超。1990 年代,GPU 从图形卡独立,Intel 吸收 SIMD 指令集,CPU 吃掉了低端图形。2010 年代,TPU/NPU 威胁 CPU,Intel 推出 AMX,AMD 增强 AVX-512。
这一次也不例外。CPU 的 AI 矩阵运算能力已悄然换代:
| Intel | |||
| AMD | |||
| ARM | |||
| Apple |
这些能力随 CPU 免费附赠——不需要一张 $30,000 的加速卡。
Ansys 在 25 亿网格 CFD 仿真中的对比更震憾:NVIDIA Grace Hopper 平台比纯 CPU 快 110×——但同一张幻灯片上的小字写着,每次仿真的成本从 CPU 的 2.99 亿降至 460 万。对绝大多数 AI 应用来说,每天数十亿次推理请求,每 token 的成本乘数是决定性的。CPU 在这个战场上拥有 5-10× 的价格优势。
五、异构计算不是"折中方案",是物理定律的必然
总结:故事不是"CPU 打败 GPU"。故事是——
当计算增长 90,000×、数据传输仅增长 30×,系统的瓶颈已经从计算单元移到了数据通道。
这个改变不是某个公司选的战略——是物理学。摩尔定律驱动的算力爆炸创造了一个"头重脚轻"的系统——算得快,传得慢。AI 产业从训练时代进入推理时代的那一刻,"传得快"突然比"算得快"更重要。
| 战场转移 | 一句话 |
|---|---|
2023 年,HPE 的 Manouchehr Rafie 在 IEEE 研讨会上画了一张图:三条线——计算、内存、互连——从同一点出发,到 2023 年已分道扬镳,差距 3,000 倍。GPU 坐在这三条线的焦点上,吃了一波计算爆炸的红利。
但 AI 从少数巨头的"训练特权"变成每个人的"推理日常"时,决定胜负的是谁能用更低成本把数据送到计算单元。
在这个新的物理约束下,通用计算的王者从未离开。
四条判断,收工
➊ 内存带宽是第一原理推理 token/s ≈ 内存带宽 / (模型参数量 × 2 bytes)。匹配带宽 vs 容量的架构才赢。
➋ 算力≠价值训练要 FLOPS,推理要带宽。90% 的商业 AI 价值在推理——CPU 的带宽架构天然适配。
➌ 异构计算是物理必然,不是妥协计算/内存/互连三条曲线的 3,000× 差距——没有单一种类的硬件能同时覆盖。
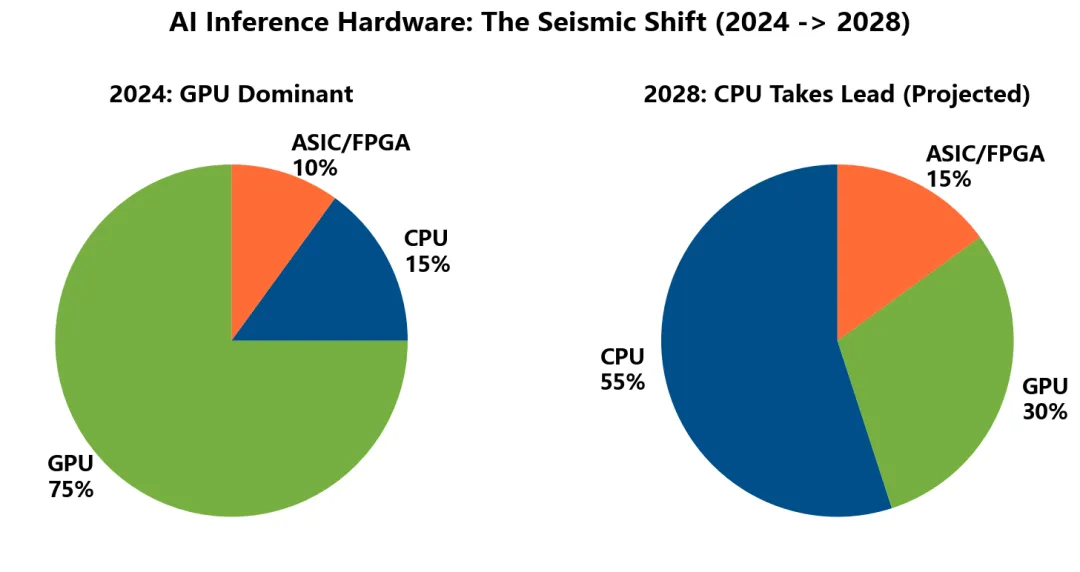
➍ 产业已在转向Meta 80%、Google 60% 的推理已回 CPU。不是趋势,是财务结算的结果。
