 夜雨聆风
夜雨聆风谁说苏妈的软件栈不行?AMD这次真的在十四天内创造了奇迹。
就在刚刚,权威机构SemiAnalysis旗下的InferenceX平台抛出一枚重磅炸弹:自DeepSeek V4发布以来,AMD的ROCm软件栈在短短两周内,实现了惊人的75倍推理吞吐量提升!这不仅仅是一个数字,这是算力界的一场“闪电战”。
想象一下,你手中的硬件没有任何变动,仅仅通过软件层面的“基因改造”,性能就从绿皮车的速度直接飙升到了超音速客机。这次测试精准覆盖了FP4和FP8精度下的8K/1K上下文典型场景,截止到5月8日,AMD交出的这张成绩单让整个业界为之侧目。在交互性体验完全不降级的前提下,Token处理能力同步爆发,曾经令人头疼的大模型推理延迟被瞬间抹平。
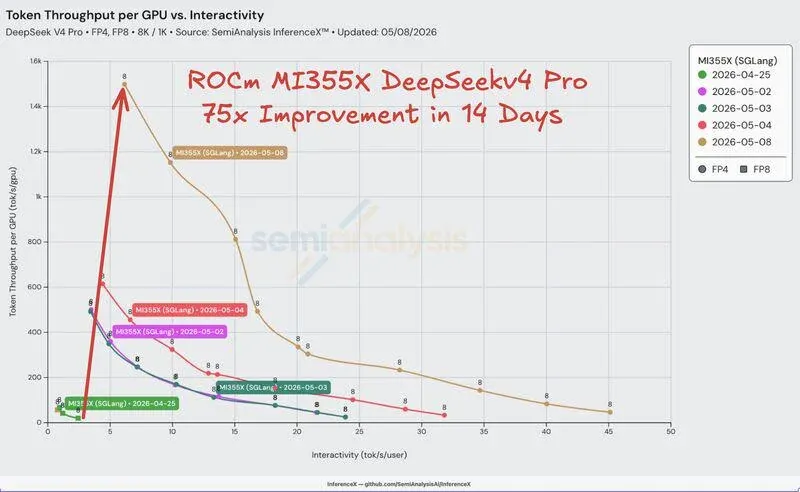
这种近乎“逆天改命”的性能飞跃,完全源自ROCm软件栈的极限压榨。AMD的工程团队精准切入了核心痛点,通过融合mHC操作与RoPE哈达玛变换,不仅极大地降低了CPU的额外开销,更让HBM内存的利用率达到了前所未有的高度。更绝的是,他们直接抛弃了繁琐的旧框架,索引器、键值缓存压缩器等核心计算内核全部采用TileLang和Triton语言重写。这种极简且高效的开发模式,正是AMD能够在这场算力竞赛中“快进”的关键。
最令人热血沸腾的细节是,这几乎是一场“盲打”。在DeepSeek V4发布之初,AMD团队并没有提前拿到模型权重,他们是在模型开源后的第一时间,凭借着极其敏锐的技术直觉启动了适配。仅用14天,就完成了从“起步”到“起飞”的全过程。这种快速迭代能力,正式宣告了AMD在AI软件领域已经拥有了与顶级对手正面硬刚的底气。
虽然目前的测试数据显示,ROCm在单节点聚合性能上与英伟达B200仍有5倍的差距,但在PD解耦版本下,这个差距已经缩小到了仅剩1.5倍。更重要的是,AMD的攻势还没有结束,预计在未来几周内,剩余的性能优化目标就将达成。这意味着,CUDA长期以来建立的“护城河”,正在被ROCm以一种不讲理的速度快速填平。
这场算力之巅的对决已经进入了下半场:硬件决定下限,而软件优化决定上限。AMD用这75倍的跃迁告诉全世界,大模型推理的战场上,没有谁是永远的霸主。苏妈的这份“两周大礼包”,或许正是全球开发者期待已久的那个转折点。

