 夜雨聆风
夜雨聆风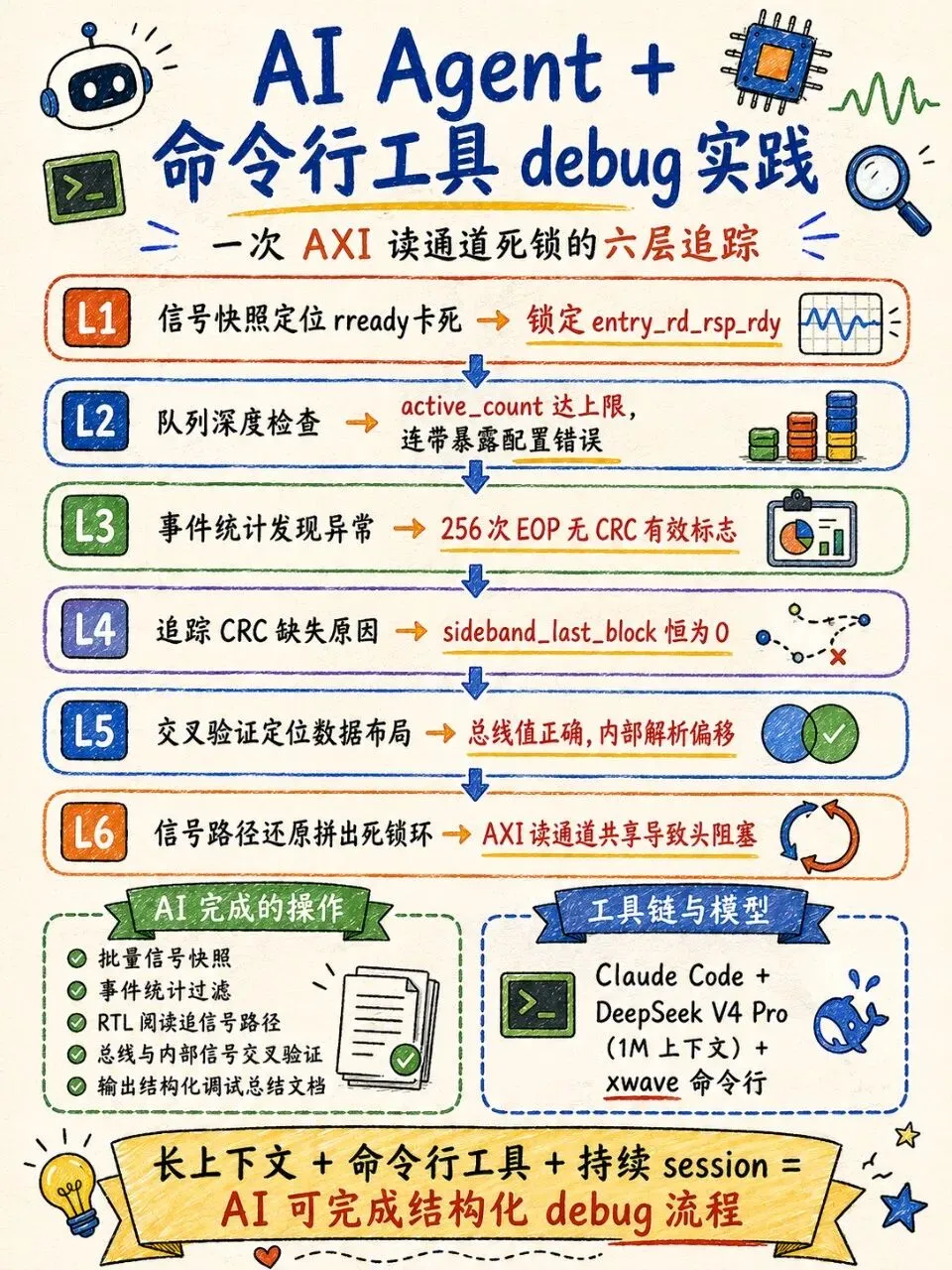
先交代背景。这次被 debug 的模块并不是正式项目里的东西,而是一个专门用来探索 AI 调试能力边界的虚拟模块。我在上面反复尝试,就是想搞清楚现在的 AI Agent 拿着命令行工具到底能把 RTL 调试做到什么程度。
Agent 是 Claude Code + DeepSeek V4 Pro,命令行波形工具是 xwave。死锁问题本身是个常见设计缺陷,但整个排查过程里 AI 展现出来的工具使用方式和推理链长度,比问题本身更有记录价值。调试结束后 Agent 输出了一份结构完整的总结文档,我把过程整理如下。
问题现象
仿真跑到 doorbell 下发之后 pipeline 停了。几个关键信号的状态很明确:dsram_wr_en 和 ds_vld 不再拉高,da_vld 仅跳了 16 次,pkt_fetch 模块里 active_count 停在 8 不再下降。是个典型的队列满导致的反压停滞,但根因埋得比表象深。
AI 怎么追的:逐层深入与工具调用
AI 拿到任务后没有一次性把所有信号都抓出来,而是按逻辑逐层下探。每深入一层,都是它自己决定下一步该查什么、该调哪个 xwave 命令。
第一层——定位表面卡点
AI 的第一反应不是让我去波形里手动加信号,而是直接开始敲 xwave 命令。它创建一个信号列表,把 rready、rvalid、entry_rd_rsp_rdy、pkt_ptr_rdy 四个嫌疑信号绑在一起,然后在几个关键时间点做批量快照。下面是它实际执行的命令序列:
xwave list new debug_rreadyxwave list add "xring_tb_top.u_dut.u_axi_master.rready" -l debug_rreadyxwave list add "xring_tb_top.u_dut.u_ring_manager.entry_rd_rsp_rdy" -l debug_rreadyxwave list add "xring_tb_top.u_dut.u_ring_manager.pkt_ptr_rdy" -l debug_rreadyxwave list add "xring_tb_top.u_dut.u_axi_master.rvalid" -l debug_rreadyfor t in 10560500 10570000 10600000 10700000 11000000 11563000; do xwave list value "${t}ps" -l debug_rreadydone几秒后结果出来:rready 在 10.57us 附近从 1 掉到 0 后再没恢复。直接原因是 entry_rd_rsp_rdy=0,再往下是 pkt_ptr_rdy=0。入口卡点当场定位。
第二层——追查背压为什么不解
接着它又建了一个列表把 active_count 和 cfg_max_concurrent 放进去。快照显示 active_count 达到上限后不再下降。附带还揪出一个配置问题:cfg_max_concurrent 的值是 4 而非规格约束的 8,根因是一处 APB 寄存器写入的位域写错。这与死锁无直接关系,但让队列更容易满,属于连带暴露。
第三层——检查数据通路
AI 开始怀疑数据链路本身有异常。它用 xwave 的 event 功能导出了时间窗内 da_vld、da_eop、da_sop 的事件统计。命令是写一个 JSON 配置文件,然后:
xwave event eop.json -n eopxwave event export -n eop -expr "da_vld" -b 11000ns -e 20000ns统计结果很明确:发出了 256 次 EOP,但没有一次携带 CRC 有效标志。也就是说 data_align 模块把所有数据当成错误丢弃了,dsram_wr_en 恒为 0 的直接原因就在这里。
第四层——追 CRC 为什么不返回
AI 查了 crc_calc 模块的 sideband_vld 和 sideband_last_block。用 xwave value 单点取值发现:前者为 1,后者恒为 0。而 crc_result_vld 是二者的逻辑与,所以永远不会拉高。sideband_last_block 又来自 pkt_fetch 对 preload header 的解析——hdr_is_last_block 字段,它取决于 hdr_next_ptr 是否等于全 1。
第五层——定位 header 字节布局的偏差
AI 自己读了 pkt_fetch 的 RTL,对照 preload 模块写入的 header 字节排布,发现失配。第一次布局把 next_ptr 放错了位置,第二次 block_size 又错位。每次改完,它都用 xwave 同时在 AXI 总线和 pkt_fetch 内部信号上取值做交叉验证:
xwave value "xring_tb_top.rdata[143:128]" 10438nsxwave value "...axi_pf_rd_data[137:128]" 10439nsxwave value "...hdr_block_size" 10439ns总线上的数据是对的,内部解析出的字段却不对。这步把问题精确限定在 RTL 对数据的解释方式上。
第六层——拼出完整的死锁环
preload 修好后 CRC 正常返回了,但 pipeline 还没活。AI 回头梳理了 rready 的完整赋值链路,结合之前各层的信号状态,拼出了死锁闭环。它没有让我自己画图,而是直接输出了一幅 ASCII 框图来描述这个头阻塞死锁:
┌─────────────────────────────────────────────────────────────┐│ 8 个 pkt_fetch 队列全满 (max_concurrent=8) ││ ↓ ││ pf_rm_rdy = 0 (不接受新 entry) ││ ↓ ││ entry_rd_rsp_rdy = pkt_ptr_rdy = 0 ││ ↓ ││ axi_master rready = entry_rd_rsp_rdy = 0 ││ ↓ ││ AXI R-channel 上 ring entry 读等待 rready ←────┐ ││ ↓ │ ││ 同一 R-channel 上 block 读响应也被阻塞 ←────────┘ ││ ↓ ││ 活跃队列等不到 block 数据 → 永远卡在 S_READ_DATA ││ ↓ ││ 队列永不完成 → active_count 永不下降 │└─────────────────────────────────────────────────────────────┘标准的头阻塞死锁——rready 在 axi_master.v 里按响应来源做选择,当来源是 ring entry 读时,rready 等于 entry_rd_rsp_rdy,而这个信号直连 pkt_ptr_rdy。pkt_fetch 队列全满时 pkt_ptr_rdy=0,ring entry 读响应收不走,同一通道上 block 数据的读响应也被堵在后面。队列等 block,block 等 entry,死锁形成。
AI 最后输出了什么
排查结束后,AI 直接给出一份结构化的调试总结文档,涵盖现象描述、六层追踪详细过程、上面这幅死锁链条图、出问题的 RTL 逻辑行、修复建议,以及关键信号路径列表和 xwave 命令模式。上面每一步推断、每一个关键信号值、每一次交叉比对都被整理进去,不需要人手再翻聊天记录重新组织。
这次实践里 AI 做得实在的几个点
按结果决定下一步,不是跑脚本。 每一层拿到快照或统计结果后,AI 会自行判断下一步该查哪个模块,不会机械执行预设脚本。“查一步、看一步、再查一步”的方式和工程师的 debug 习惯很接近。
长上下文让整个推理链条不断线。 这里必须提 DeepSeek V4 Pro 的 1M 上下文窗口和长上下文召回能力。整个 debug 过程中,AI 先后读了 axi_master.v、ring_manager.v、pkt_fetch.v、crc_calc.v、data_align.v 等好几个模块的 RTL,同时还要记忆 xwave 在不同时间点返回的信号快照和事件统计结果。普通上下文窗口容易在信息堆积到后半程时出现“遗忘”,但 1M 窗口保证了这些跨模块、跨时间点的信号关系始终在同一个注意力范围内。当它拼死锁环、回头引用第一步的 rready 快照和第四步的 sideband_last_block 状态时,不需要重新加载或反复提示,直接从对话历史里精准召回。
能读 RTL 并追踪信号路径。 从 rready 往上追到 entry_rd_rsp_rdy 再到 pkt_ptr_rdy,从 sideband_last_block 反推 hdr_is_last_block 再到 header 字段,这些信号链都是 AI 自己读 Verilog 抽出来的。
交叉验证替代猜测。 查 preload 问题时,AI 没有直接猜“数据没写进去”,而是先验证字节写入通路,再用 xwave 在总线和内部信号之间做比对,把问题收敛到“传输正确但解释错误”。
持久化上下文让工具侧没有冷启动。 xwave 的 daemon 一直在后台保持 FSDB 加载,AI 查过的信号、取过的时间点都在同一个 session 里,不需要反复加载波形。这和模型侧的长上下文形成了双重上下文保持——工具层热数据,模型层长记忆。
还不成熟的地方
RTL 修复环节没有像信号追踪那样顺畅。preload 字节布局 AI 前后改了三次才改对,中间还误判过一次信号的 bit 范围;测试用例和配置脚本也没有一次生成到直接可用的程度。这不一定是模型能力的绝对上限——更可能是在面对多文件关联修改和精确位域约束时,上下文工程和提示词策略还没有适配到位。如何更清晰地描述修改边界、如何在 prompt 中嵌入“修改后需满足什么验证条件”这类强制检查,目前还是开放问题,也是下一步可以重点迭代的方向。
这个实验到底在试什么
这个模块本身就是为探索 AI 能力边界搭的虚拟模块。用它来 debug,目的不是修掉某个具体 bug,而是想知道:当 AI 手边有命令行级的波形工具、有一个足够大的上下文窗口时,它到底能自主完成多深的信号追踪,在哪个环节会掉链子,哪里需要通过更好的工程手段来补强。
这次跑下来,从现象到根因的六层追踪,AI 做到了全程不依赖人给方向。它中间犯过几次错,但通过交叉验证自己纠正了。在 RTL 修改这类需要高精确性的环节上,表现出了明显的不稳定,也正是从这个缺口里,可以看到上下文工程和提示策略的优化空间还很大。
可以带走的一点
这次排查跟下来,最直接的感受是:AI 参与 debug 的瓶颈不在模型能力,而在它手边有没有趁手的命令行工具。 xwave 把波形查询变成了 list、event、value 这种一行一条的原子操作,AI 就能像调 Linux 命令一样编排它们。而背后支撑这种多步编排不跑偏的,是 DeepSeek V4 Pro 那样的长上下文能力——能一口气装下整个调试过程的所有数据之后,仍然准确地定位 RTL 里的一个 bit 段偏移。工具链越贴合机器的调用习惯,上下文窗口越能撑住长链推理,AI 能干的活就越多。而那些尚未做好的地方,恰恰标出了下一轮工程优化的起点。
