 夜雨聆风
夜雨聆风一、前言:我的笔记管理混乱
作为一个 .NET 后端工程师,我每天都会遇到这样的情况——
刷到一篇好文章,看完觉得「太有用了」,然后……就没有然后了。几天后再想找回这篇文章,浏览器书签翻了半天找不到,有道云笔记用了好多年,但是整理花时间,久而久之就乱了,搜索出来也需要一个个去确定信息,更别提把文章里的知识真正用起来。
就这样,大量有价值的信息在收藏夹和云笔记中吃灰,当想用的时候,却不记得放在哪个收藏夹或云笔记里,白白浪费时间去搜索。
直到最近,我摸索出了一套本地知识库 + AI Agent 的方案,才真正把「日常阅读」变成了「知识积累」。今天把这套流程分享给你。
先看效果——我现在每天的工作流是这样的:
浏览器看到好文章 → 一键采集到 Obsidian → AI Agent 自动帮我整理摘要、关联历史笔记 → 需要使用时,可以使用传统的搜索,也可以让 AI 直接从我的知识库里找
全程数据在本地,不依赖任何云笔记服务。下面展开说怎么做。
二、为什么选 Obsidian?
市面上笔记工具很多,飞书、ima、有道云笔记、语雀……为什么我偏偏选了 Obsidian?
核心就两个字:开放。
Obsidian 有几个特性让我无法拒绝:
1. 数据完全本地化。 所有笔记以 Markdown 文件存在本地磁盘上,不是某个云服务的私有格式。这意味着我拥有数据的完全控制权——哪天想换了,换个编辑器就能继续用,不存在迁移成本。
2. 同步方式极其灵活。 Obsidian 官方提供了 Obsidian Sync 云同步服务(付费),但更重要的是——因为数据就是普通文件,你可以用任何方式同步,甚至 U 盘拷贝,爱怎么同步怎么同步。
3. 插件生态足够开放。 Obsidian 的社区插件库非常丰富,也可以像浏览器插件直接使用本地目录中的插件,本次我为了同步,专门写了一个支持 SVN 的同步插件。
简单来说:Obsidian 像积木,你可以往上拼任何东西,而不会固定于某个模式。
三、选一个 AI Agent:Claude Code、Cursor、Trae、Lingma 怎么选?
有了知识库的「容器」,接下来需要一个「大脑」来帮你整理和检索。
这里的核心角色是 AI Agent——一种能直接读写文件的 AI 助手。它可以读取你的 Obsidian 笔记内容,理解后帮你整理、分类、关联,甚至在你写作时从知识库中调取素材。
目前市面上能胜任这个角色的 Agent 有好几款:
| Claude Code | |
| Cursor | |
| Trae | |
| Lingma(通义灵码) |
本质上,它们都具备「读取文件 → 理解内容 → 操作文件」的能力。你不需要纠结选哪个,选一个你觉得顺手的就行。
我个人用的是 Claude Code,原因是它能直接通过命令行在知识库目录中启动,操作文件的能力很强,而且可以通过 CLAUDE.md 深度自定义行为。
下面以 Claude Code 为例演示配置方式,其他 Agent 的配置思路完全一致。
四、配置 Agent:让 AI 读懂你的知识库
这是最关键的一步——如果不做配置,Agent 根本不了解你、不了解你的知识库结构,它就像一个刚入职的新员工,需要你交代清楚背景。
在知识库根目录创建一个配置文件,Claude Code 读取的是 CLAUDE.md,Cursor 和 Trae 也支持类似的规则文件(.cursorrules / .trae)。
以下是我实际使用的 CLAUDE.md 配置:
# CLAUDE.md — 个人知识库## 关于我- **角色**:.NET 后端工程师- **技术栈**:.NET(C#)、MySQL、Redis、Vue、FreeSql ORM## 知识库结构- Clippings/:Web Clipper 采集的原始文章(待整理)- 1、阅读笔记:阅读过的文章和笔记- 2、开源项目:感兴趣的开源项目- 3、部署维护:Linux 服务器运维相关- 4、工具库:工作中用到的工具和技巧- 6、创作库:自己写的文章- 9、内容摘要:AI 整理的问答和摘要存档## 工作偏好- 所有回复使用中文- 代码必须带中文注释- 文档使用中文标点符号- 回答问题时优先检索本地知识库中的相关笔记
你可以参考这个结构,根据自己的情况调整。核心要点:1. 告诉 Agent 你是谁。 角色、技术栈、偏好——这些信息会在每次对话时自动加载,Agent 会根据你的背景给出更有针对性的回答。
2. 告诉 Agent 知识库的结构。 让 Agent 知道每个目录的用途,这样它就知道 Clippings 是素材库、阅读笔记是整理后的内容、创作库是你的输出区。
3. 告诉 Agent 你的行为偏好。 语言、风格、优先级——避免每次都重复交代。
配置完成后,每次在这个目录下启动 Agent,它会自动读取配置,像一个了解你工作习惯的助手一样工作。
五、采集与整理:Web Clipper + Agent 协作
第一步:浏览器一键采集
在 Chrome 或 Edge 浏览器中安装 Obsidian Web Clipper 插件。这是 Obsidian 官方出品的浏览器扩展。
安装后,在 Obsidian 中打开 Web Clipper 设置面板,创建一个采集模板:
- 保存路径
: Clippings/(所有网页采集统一放到这个待处理目录) - 文件名
: {title}(用文章原始标题) - 内容模板
:建议保留原文链接和采集时间
配置好之后,浏览网页时看到好文章,点一下浏览器工具栏的 Web Clipper 图标就行了。插件会自动提取页面正文、保留排版格式,保存到 Obsidian 的 Clippings 目录。
公众号文章、知乎、技术博客,大部分内容型页面都能采集得不错。
第二步:Agent 帮你整理
这是真正省力的环节。Clippings 里堆积了文章之后,打开 Agent,用自然语言下指令就行。
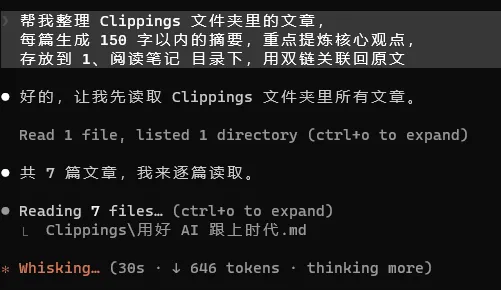
场景一:批量生成摘要
帮我整理 Clippings 文件夹里的文章,每篇生成 150 字以内的摘要,重点提炼核心观点,存放到 1、阅读笔记 目录下,用双链关联回原文Agent 会逐篇读取 Clippings 中的文章,理解内容后生成结构化的摘要笔记,并且用 Obsidian 的双链语法 [[原文标题]] 把摘要和原文关联起来。
场景二:按主题提取信息
我最近采集了好几篇关于 MES 系统选型的文章,帮我提取每篇文章中的关键观点、优缺点分析、价格信息,整理成一份对比表格放到 4、工具库 目录Agent 不会简单地复制粘贴——它会理解文章内容,把分散在多篇文章中的相关信息提取出来,结构化呈现。
场景三:发现知识关联
我刚采集了一篇关于 MySQL 索引优化的文章,帮我扫描整个知识库,找出与之相关的历史笔记,在新文章末尾加上相关阅读的链接这一步特别有价值。你单篇单篇地看文章时,很难意识到「这篇讲的 B+ 树原理」跟「半年前写的那篇查询优化笔记」有联系。Agent 能跨文件扫描,帮你在知识之间建立连接。
六、用知识库辅助创作
知识库建起来之后,最让我惊喜的用途是辅助写作。
做开发 10 多年,平时一些好用的工具、框架之类的,想和同事分享一下,结果发现卡壳了。现在有了 AI Agent 加持的知识库,它能够把我平时的项目经验或头脑风暴总结出来。这样知识就在不断地积累、复用。这样你的知识库就形成了一个闭环:采集 → 整理 → 创作 → 发表 → 关联。知识在其中不断积累、流动、复用。
七、多设备同步方案
最后说一下同步。因为 Obsidian 的数据就是普通的 Markdown 文件,同步方案的选择很多:
- 官方同步
(Obsidian Sync):付费,体验最好,端到端加密 - 第三方平台(S3)
:根据自己现有的资源选择 - Git
:适合技术人员,有版本控制 - SVN
:适合已有 SVN 服务器的场景
我个人用了 SVN 同步,因为工作环境已有 SVN 服务器,而且 SVN 的文件级版本控制很适合 Markdown 文档的管理。我自己写了一个 Obsidian 的 SVN Sync 插件(没有上传到官方插件市场,纯自用),实现了启动时自动同步、定时提交、冲突检测等功能。
你不需要照搬我的方案,适合自己的才是最好的。
八、总结
整套方案的搭建过程:
- Obsidian
作为知识库容器——本地存储、格式开放、插件丰富 - Web Clipper
负责采集——浏览器一键保存 - AI Agent
负责整理和创作辅助——读文件、理解内容、生成笔记、辅助写作 - 同步方案
按需选择——数据是普通文件,怎么同步你说了算
整套流程没有绑定任何云服务,数据完全掌握在自己手里。而且每个环节都是可替换的——Agent 可以换、编辑器可以换、同步方式可以换,你的知识不会因为某个工具停止维护而丢失。
最后想说一句:搭建知识库真正的价值不在于「存了多少」,而在于「用了多少」。 AI Agent 的作用,就是帮你把「存」变成「用」——让那些躺在文件夹里的文字,真正成为你的第二大脑。
