 夜雨聆风
夜雨聆风前言
这篇文章的诞生,源于近2个月看到的一些前沿的资讯与现象,它们的演进与变革都是我从未设想到的一些点,所以借助这个平台来记录一下,同时也能与各位读者分享下这些洞见。
由于这次撰写是临时起意的一件事,也没花太多心思构思文章结构,权且简单地分为标题的两个维度——AI对百姓生活与产业链的影响。
ps∶本文正文内容均为原创,纯手工码字,引用源均已注明,如对你有帮助,幸甚。
Agenda
1.AI对百姓生活的影响
·1.1 老百姓额外的收入——每个人的车与家都将作为分布式算力
·1.2 使用的计算机或将迎来变革——Neural Computer
2.AI对产业链的影响
·2.1 员工被蒸馏为SKILL的趋势或进一步扩大——Meta强制监控员工
·2.2 工业界其它领域公司纷纷入局AI——著名马桶品牌TOTO、化妆品品牌花王等进军AI下游产业
·2.3 新型职业——机器人数据采集类工作
AI对生活的影响
这里提到的两件事未来都大概率会走入寻常百姓家,甚至能改变大家生活方式。
1.1老百姓额外的收入——每个人的车与家都将作为分布式算力
———————车———————
早在今年1月的一次xAI的个人采访中,名为苏曼的老哥就透露了一个轰动全球的"秘密",即特斯拉不仅是车,而是分布式小型算力。他当时提到的内容源自于特斯拉内部名为“Tesla Compute”的一项计划,即xAI打算付费给特斯拉车主,在车主在未来OTA中同意接受相关条款后,他们车辆在充电或闲置时的算力就会被用于共同训练大模型。这么一来北美的400万辆特斯拉就能通过协作成为庞大的分布式算力网络。
这么一来对有两个突出的优势∶
-第一,节约了巨量时间成本。像OpenAI、Google等公司需要耗时数年才能建成一个超算中心。但xAI的模式省去了基建过程和层层机构审批的行政流程,不管车在街上还是车库都能将闲置的车辆互联,从而聚少成多。
-第二,节约了巨额资金。参考OpenAI的星空之门计划可知,超算中心的成本量级都是百亿美元级别。在那次采访后,就有分析师测算,即使每月给一半车主50美元,年度成本也仅为12亿美元,与竞争对手的百亿级投入相比,成本低了近十倍,且无需等待,这么做无疑对其它玩家是降维打击。

不出所料,苏曼第二天就被解雇了,并且马斯克在社媒否认了其的所有观点。即使这样,在人们心目中的疑团也没完全被扫清,毕竟这种宏伟蓝图确实像是Elon会构想出的。
接下来两段纯粹是个人观点∶ 车成为超小型分布式算力极有可能在不久的将来实现,尤其是在最近xAI已经宣布原地解散,且准备要和SpaceX合并为SpaceXAi的势头下。SpaceXAi属于是创建了一条新赛道——太空轨道数据中心(Orbital Data Center System),这样的叙事实际上并没有摒弃"数据中心"这一概念,我认为它并不仅仅是为了IPO所设计的名词,单纯用于炒作,而是公司确确实实想围绕数据中心做文章,但又不能那么现眼,所以用了这种虚实结合、真真假假的障眼法。就如同当年xAI被创立的时候附带公益组织的性质,后来被悄然撤掉一般,Elon他可太懂"障眼法"了。他不可能不懂这个时代算力中心的重要性,而他又不是那种走寻常路的男人,所以苏曼提出的观点当时就深深震撼了我,并且到现在我都依旧认为这会成真,毕竟没有人能保证特斯拉上不会被部署星链。
这么一来,大胆畅想下未来一辆特斯拉的几大特点,或者说未来所有的车会具备的几大特点∶(1)成熟度极高的FSD。这就意味着不需要司机,且车把车主送到目的地后自己会自动去当滴滴帮车主赚钱;(2)充电或熄火时会与其它车互联,共同形成一套巨型算力系统,赋能AI预训练与后训练。出租的算力也会为车主赚钱;(3)内置星链或同类技术,在信号薄弱的户外也能实现高速上网。这就意味着在这种极端环境依旧能通过物联构筑巨型算力系统;(4)内置Gemma或同类技术,具备端侧离线大模型推断能力。关于这一点,如果有星链等技术的支持,其优势可能只停留在端测低延时推理上了。
———————家———————
4月13日前后,SPAN公司宣布推出 XFRA,这是一种分布式数据中心解决方案,旨在应对当前日益增长的电力基础设施限制,提供千兆瓦的新计算能力。 https://longbridge.com/zh-CN/news/282582576

这个项目除了英伟达和Span以外,还涉及PulteGroup这家大型房地产公司和住宅房主。Span的独特模式强调电网闲置容量利用+智能电板调度+零业主前期成本+固定月费分成,与PulteGroup合作预装到新房,目标客户是hyperscalers(如AWS、Google)。项目首期会在年内推行100户规模来做概念验证,这些住宅大多是新建的。
下面分点说明其模式∶
(1)电网闲置容量利用。即社区最大可达到的用电容量减去住户正在使用的容量。这里会顺便回答两个问题,即为什么该项目是需要住宅房而非商业房,又为什么不再统一划地建造超算中心。
这里得先厘清一个概念,即每个社区或商圈都会有一个最大用电容量,这个值和铺设电缆以及电缆的型号有关,如果所有电缆都以百分百功率工作,那就会达到峰值,这时候想额外调电也不可能,美丽国现在的情况就是很多商业用房(写字楼之类的)已经做好了这些基建,不太可能做大改,这些房间平时就容易达到最大用电容量。而住宅房就不一样,即使一家几口都在家猛猛用电时可能还会有容量冗余,这种情况下这些容量不用白不用,所以XFRA就是瞄准这部分冗余,调用它们为外挂机箱供电,让它们作为算力分发出去。讲到这里,实际上也自然回答了第二个问题,超算中心的从零建设是能重新铺线,但其成本消耗巨大,XFRA通过直接外挂在现有住宅外墙就能实现零基建成本工作。
相关资料显示,美国独栋住宅存量超过 8,000 万套,新建住宅普遍标配 200 安培电力服务等级,有独立电表和大量未用满的电网接入容量。 https://www.mittrchina.com/news/detail/16345
(2)智能电板调度。这里就需要提下Span这家公司的长板——智能电板技术。它可以实时测算每户的瞬时负载,动态调度计算节点的功率使用。这种技术能使用户正常用电的同时感知不到剩余容量被调度,做到有效但不打扰。
(3)零业主前期成本。Span与PulteGroup承诺装备该外挂机箱不产生费用。且对于新建住宅更加有利,因为可以从零部署管线和电力,相关硬件就可以被预装到建筑工序里,以实现开发商端做分发,而不需要后期调度后再统一分发。
(4)固定月费分成。这一点就需要谈一下该模式的运转了,总的来说是畅想的四方共赢模式。Span提供了自家技术和产品获利,英伟达能获得预期的算力供给给hyperscalers,PulteGroup以外墙挂机箱为宣传点出售新宅,住户零成本装机加盈利,盈利的多少取决于机箱供应的算力。
———————总———————
个人看法,不管是苏曼采访提到的车作为小型算力还是XFRA主打的住宅小型算力都让AI算力的战场走向了寻常百姓家中,对百姓来说多了项收入来源。可这些算力会被用于训什么,对百姓来说却是未知的,或许在不久的将来,待这两件事真的开始变成我们新的生活方式时,就会有相关的法案来对其做约束,比如算力执行知情权等。
1.2使用的计算机或将迎来变革——Neural Computer
这个词如果直译成中文会有点出戏,神经计算机。它是诸葛鸣晨与LSTM之父Jürgen Schmidhuber一起提出的一个新范式。
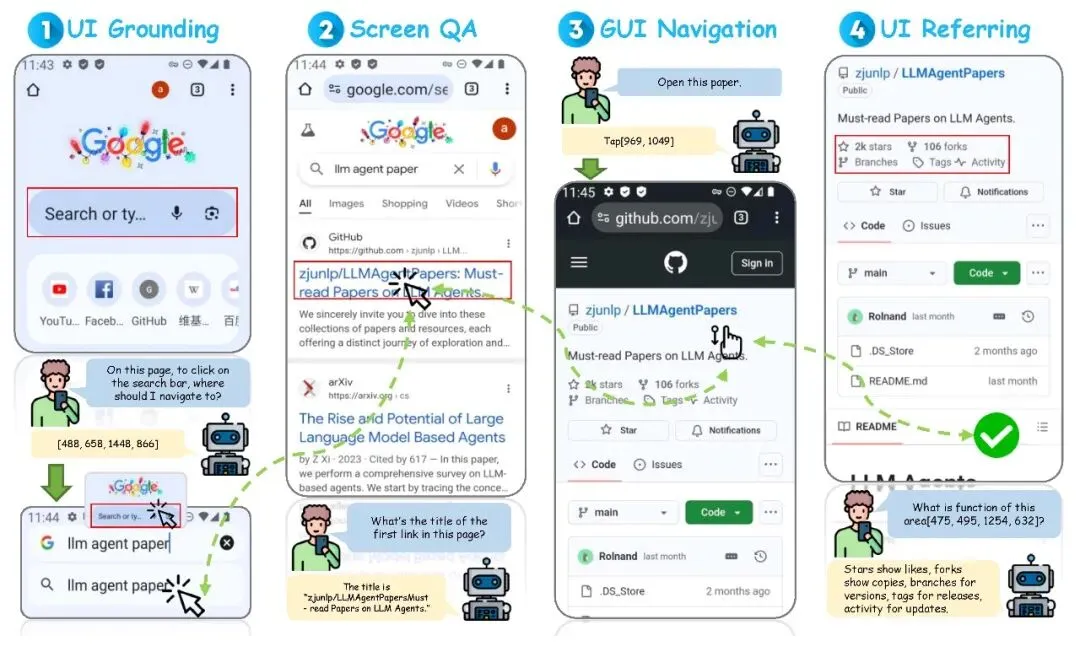
简单来说,目前的所有AI智能体的操作还是基于GUI,这是训它们时用的数据集决定的(如下图,源自Liu et.al. LLM-Powered GUI Agents in Phone Automation: Surveying Progress and Prospects. Preprints 2025, 2025010413),所以它们对界面的所有感知与响应都还是基于既定的软件界面。
Neural Computer要解决的问题是如何把软件本身也放入模型内部供模型学习,而非只是让它学怎么用现有软件。换句话说,网络需要通过屏幕像素和用户操作直接学习计算机的运行方式。这就要给网络看大量的交互视频,让网络记住点击某个位置后会有什么响应、界面会如何变化,有点像是屏幕中的世界模型。为了实现原型,作者团队探索了 6 种数据收集方式,收集了超过 80 万条命令行操作片段,总时长大约 1,100 小时,还收集了大约 1,500 小时的图形桌面操作记录。但目前的实验结果显示还是会有较大局限,比如在命令行场景中,模型已可以准确生成光标位置、文字纹理,但逻辑运算的结果依然会出错。这表示模型能生成逼真的终端界面,却无法给出算术运算的正确答案。(下图来自论文Neural Computer)
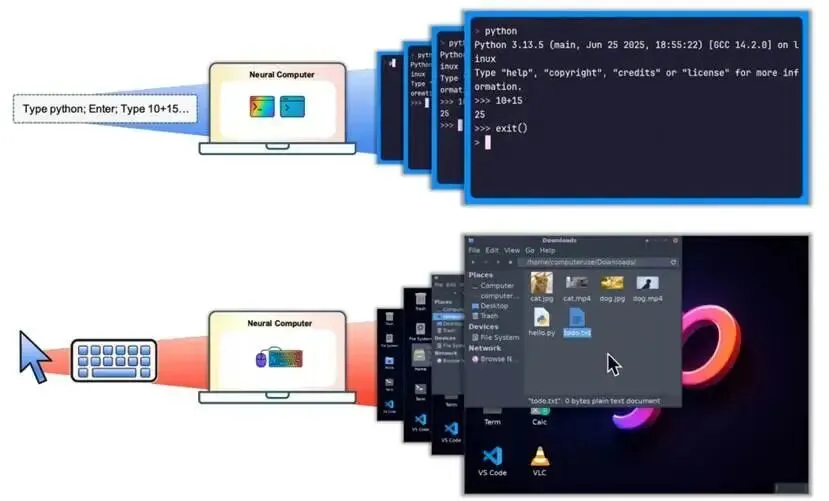
个人观点,这篇论文给出了一个非常有趣的创想,即把计算机的底层运算直接丢到网络里让它学习,这样的话学出来的东西是一个端到端的映射,它免去了传统计算机的真实处理过程中的cpu调度、内存缓存分配等一系列任务,而是直接基于current action以及current screen shoot这两个输入推断出next screen shoot,这个next screen shoot中包含了图形和逻辑两部分内容。但作者目前给出的方法有点像Sora这种视频生成式的世界模型,它是靠反复观看海量视频来学会模仿界面的演变,缺乏了内部"物理"约束,后续研究应该会深入到计算机底层的运算并且提炼相关内容来正则整个训练,从而获得更好的效果。
这么一来,未来的计算机或许也会变成我们要完成什么任务时,就通过文本提示或语音提示作为输入,计算机接受到指令后自动生成对应的画面,以此改变人机交互方式。
AI对产业的影响
这里分享下两件有趣的事情和与之伴随的个人看法加一个社会趋势。
2.1员工被蒸馏为SKILL的趋势或进一步扩大——Meta强制监控员工
上个月写了篇聊聊最近比较火的skills,然后4月22日路透社就报道了Meta正在员工工作电脑上部署名为"模型能力计划(Model Capability Initiative,MCI)的追踪软件。该软件可以实时采集员工鼠标移动轨迹、点击位置以及键盘输入内容,并定期做屏幕快照,这些采集的数据会被用于训练Agent。
就该计划而言,员工无权拒绝部署。Meta官方称MCI数据仅用于训练AI,不涉及KPI考核且附带敏感内容机制,但并没明确说明哪些内容被视作敏感内容并会被加以豁免。 https://www.businessinsider.com/meta-new-ai-tool-tracks-staff-activity-sparks-concern-2026-4
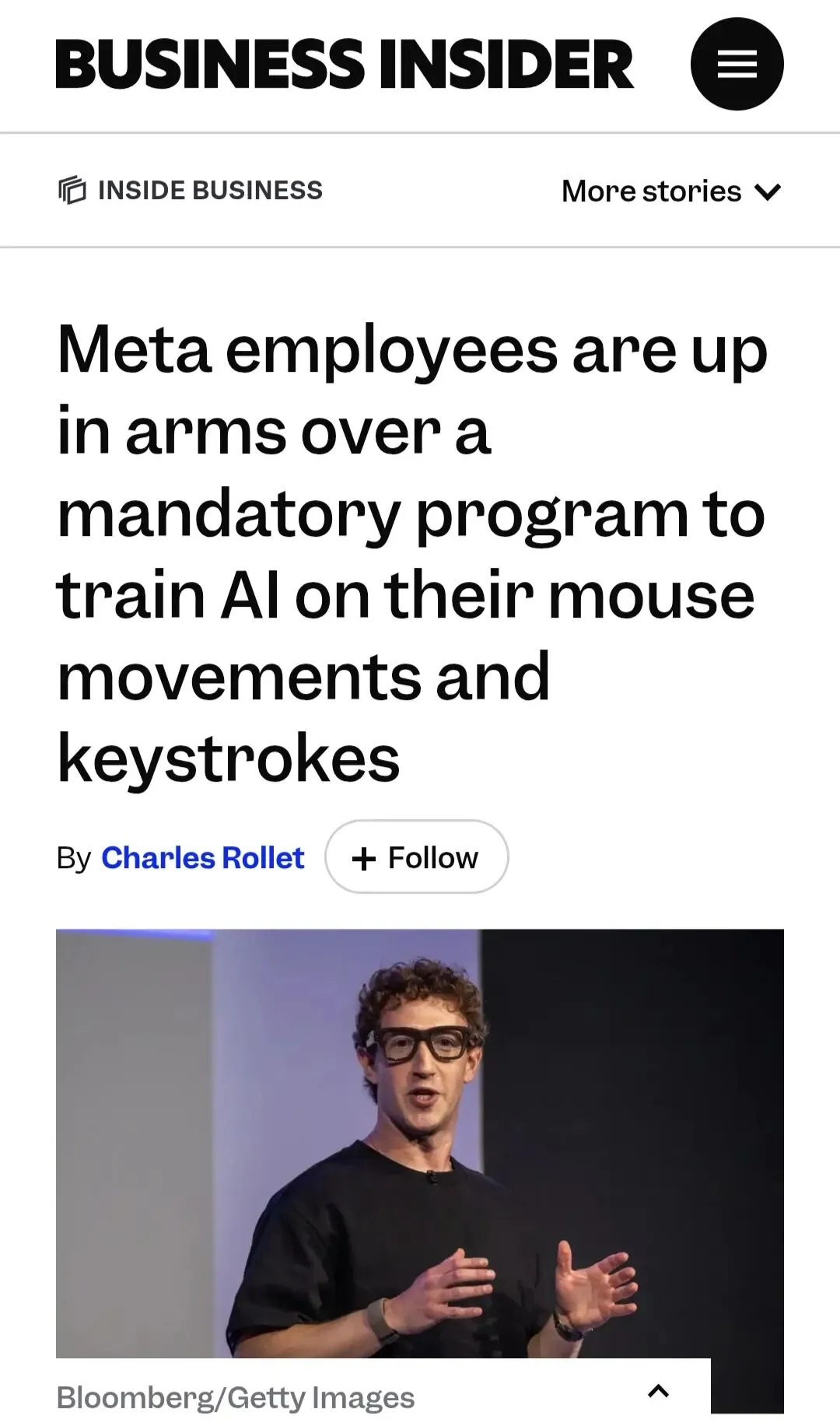
该举措的结果自然引来大量内部员工的抵触,但呻吟后依旧无果。与之伴随而来的是自3月起开始推进的Agent Transformation Accelerator计划,该计划的目的就是用Agent替代部分岗位。公司内部已通过内部邮件通知员工,自5月20日起会在全球裁10%的员工。
笔者认为,Meta该举措起到了个行业头炮的作用,媒体和其它企业一定都在关注其举措造成的结果,如果未来有信息表明该举措能取得正向结果,势必会有大量效仿接踵而至。毕竟今年到现在为止,Meta、Amazon、Google等公司纷纷都在为自己的员工设立了一到两周的AI训练营课程,旨在系统化培训员工动用AI工具的能力,且课程结束时还需要提供从零搭建的作品。也就是说,AI渗透到工作流中已成定势,且随着Agent的逐渐强大,非创造性的岗位一定会更多地被压榨。比较有趣的是,上文提到的Neural Computer实际上是和Meta联合发表的,所以Meta的MCI计划也是有孕育神经计算机的潜在可能性的。
作为牛马,遇到这种场景,也只能认命了。唯一能做的就是改变心态,再往前走一步,用黄仁勋去年受访的一句话来说∶聪明的人不是让AI去帮忙解决问题的,而是让AI帮助自己去学习的。确实今天对寻常百姓来说调用AI的门槛已经非常低了,但调用的目的是什么,是为了让自己能偷懒摸鱼呢,还是不断降低自己对新事物的学习成本?在国内订阅制即将到来的前夕,尽量让AI为自己作最后一舞。
下图为5月4日豆包推付费版的截图,往后国内问答大模型生态一定也会往国外那种订阅制发展

2.1工业界其它领域公司纷纷入局AI——著名马桶品牌TOTO、化妆品品牌花王等进军AI下游产业
该小节多数信息源于此文章。 https://www.mittrchina.com/news/detail/16344。
今年 4 月,潮鞋公司 Allbirds宣布停止运动鞋业务,转型为AI算力基础设施供应商,并在名字上加上AI两个字母,其股价在4月15日盘中暴涨,最高涨幅去到600%,最后收盘以582%的涨幅收于16.99dollar。这充分说明了只要在风口,猪都能起飞。
与该讲故事公司不同(纯笔者观点),TOTO是大家耳熟能详的做马桶盖的公司,其智能马桶垫中的半导体陶瓷部件静电吸盘成为了半导体和显示器供应中炙手可热的部件。静电吸盘(ESC,Electrostatic Chuck)在半导体制造过程中用于固定晶圆(wafer),其被广泛应用于 NAND 闪存等芯片生产环节,不仅能在极低温度下稳定刻蚀,同时还能最大限度降低颗粒污染。
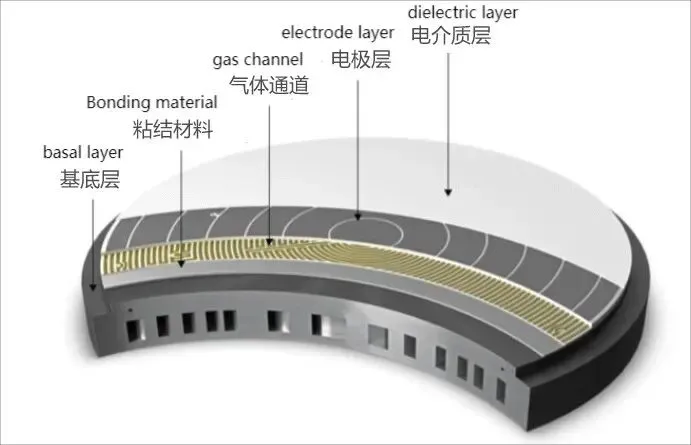
数据显示,这家卫浴公司是全球第二大静电吸盘生产商。在整个HBM/NAND的存储产线不断扩产的今天,它仿佛找到了企业的第二曲线。
与之境遇类似,花王起初是一家化妆品公司,之后其业务延伸到汽车和电视电子元件的清洁剂,到今天它将“去除污垢”的核心技术应用到了半导体领域。由于芯片越来越小,在其产程中不可避免地容易在每个阶段引入纳米级颗粒污染,最终导致晶圆良率下降,所以清洁技术扮演者举足轻重的角色。花王则提供了分子层面清除污垢的清洗剂,用于芯片清洗任务,在这个时代顺利地完成了转型。
笔者观点∶ 在AI浪潮之际,越来越多公司凭借卓越的战略眼光实现转型,搭上了这趟AI的快车。这里不由地感叹技术之间的相通性以及学科之间的交叉性。历史总是惊人地相似,回看十年乃至二十年,亚马逊通过开启AWS使其从电商转型到技术巨头;惠普通过开发仪器校正仪成为了开启pc时代的公司,完成了仪器公司到电脑公司的转型。在新时代的列车驶出时,每个人都手握车票,区别在于能不能找到站台以顺利搭乘上这班列车。
2.1新型职业——机器人数据采集类工作
这点就没啥好说的了,机器人时代来临之际,"搬砖任务"从机器学习的数据标注员到机器人数据采集,包括室内室外、teleops遥操、手套采集等各类工作。

笔者自己想到了一个可讨论的话题,即创建数据的价值有多少?实际上目前机器人行业是极度缺乏数据的,尤其是Real World的数据,且目前经星海图采访披露,真实机器人采集的一小时成本大约为200到250元人民币。但笔者搜索了下苏杭地区相关工作,发现提供的报酬是130到300左右的价格区间,其时薪取决于每天总采集时长。数据极度缺乏,但给出的区间又并非恒高于真实机器人采集的成本,这样的付出回报比真的合适吗?确实采集这类活相对来说并非是极度需要脑力,但毕竟这是在为机器人行业补齐整个行业稀缺能力的一环(AI能很好地做脑力任务,但反而做不好体力劳动任务,所以才需要捕获此类数据去训它们),其为未来缔造的价值是巨大的,那这个薪酬是否应该定高些?
