 夜雨聆风
夜雨聆风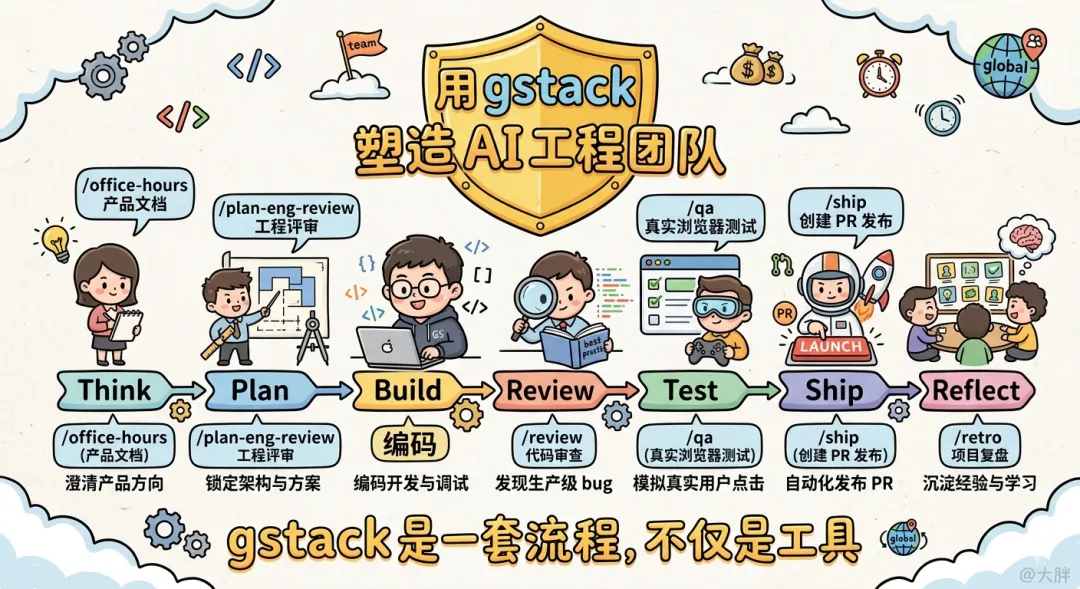
一句话理解:gstack 不是又一个 Prompt 合集,而是一套把 AI 编程组织成 Think→Plan→Build→Review→Test→Ship→Reflect 标准工序的工程操作系统。
🎯 本文产出
• 完整的 gstack 工程工作流实操指南(从产品定义到发布复盘) • gstack + OpenSpec 对比决策矩阵(一张表帮你选型) • gstack 常用命令速查表(可直接收藏备用) • 三类真实失败模式 + gstack 如何规避的对照分析
💰 商业价值
用 gstack 驱动 AI 完成完整工程闭环,单兵开发效率提升 20-50x,将"写代码的 AI"升级为"做工程的虚拟团队"——可接全栈项目外包,单价 3-10 万/单。
一、一个让人不舒服的问题
Garry Tan(YC 现任 CEO)在 2026 年的一次分享中提到,他用 gstack 驱动 AI 编程,每天产出逻辑代码量达到 11,417 行——这是 2013 年顶级工程师人均日产出(约 14 行)的 810 倍。
先不管这个数字是否夸张,它揭示了一个更让人不舒服的问题:你用 AI 编程,到底在加速什么?
如果你今天的 AI 编程方式是"对话框里说需求,AI 生成代码,你审查复制"——那加速的是"代码的生成速度",而不是"软件工程的交付质量"。
这两件事的差距,就是生产 Bug 的温床,也是方向性浪费的来源。
gstack 解决的不是"怎么让 AI 写得更快",而是"怎么让 AI 在正确的工程阶段做正确的事"。
二、AI 编程的真正瓶颈:工程流程的缺失
过去两年,AI 编程工具的形态演进非常清晰:代码补全(Copilot)→ 对话式编程(Cursor)→ Agent 自主执行(Claude Code)。每个阶段都在提升代码生成速度,但一个尴尬的现实始终存在:
代码写得越快,工程问题暴露得越早。
你可能遇到过这些场景:
• AI 写完了整个功能,但产品方向就是错的——它根本不理解"为什么做" • 代码跑通了,放到生产就炸——没有安全审计,没有边界检查,没有性能测试 • 改了三轮需求,AI 的上下文悄悄漂移——之前的架构约束被静默推翻 • 每次新开会话,AI 就像一个失忆的工程师——所有背景要重新解释
这些问题的共同根源只有一个:AI 模型没有内建的工程阶段意识。
一个需求在真实的软件工程里要经过:产品思考 → 方案规划 → 编码实现 → 代码审查 → 测试验证 → 发布上线 → 复盘沉淀。每个阶段有明确的入口条件、产出物标准、质量门禁。
但当你对 AI 说"帮我写一个任务管理工具"时,它一次性跳过了全部前置阶段,直接进入编码——这相当于让一个工程师不看需求文档、不做架构设计、不写测试用例,直接开始写代码。
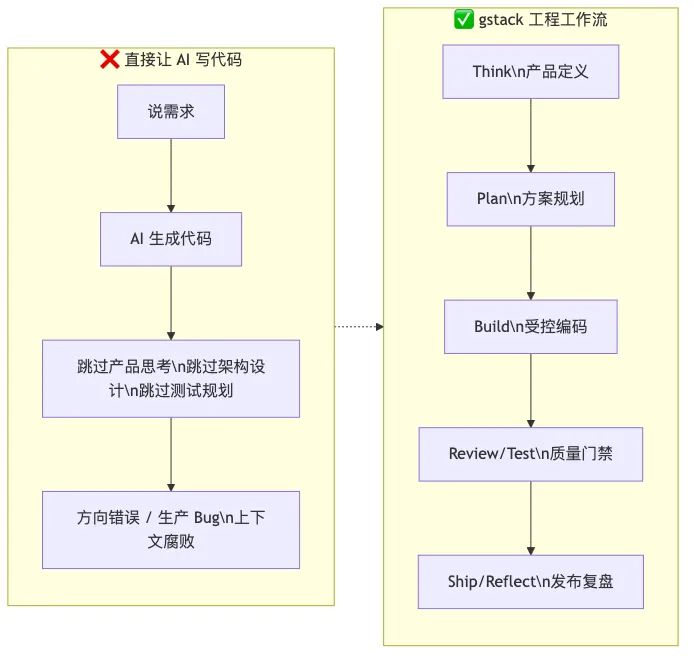
左侧是"直接写代码"的典型失败路径,右侧是 gstack 的阶段化工程流程。核心差异在于每个阶段有明确的产出物传递和质量门禁——这是软件工程的本质,而不是额外的流程负担。
三、认识 gstack:把 AI 变成一支虚拟工程团队
gstack 由 YC 首席执行官 Garry Tan 开源,是一套面向 Claude Code 的 AI 编程 skill 套件(同时支持 Codex、Cursor、OpenCode、Kiro 等 Agent)。
它的核心设计理念只有一句话:
gstack is a process, not a collection of tools.
3.1 虚拟工程团队的角色矩阵
gstack 通过 23 个 slash command,将软件工程拆解为不同角色的专业职责:

gstack 的角色覆盖了软件工程的五个核心层,每层之间有明确的产出物传递关系——上层输出是下层的输入。这些角色不是"人格设定",而是限定了 AI 在当前阶段的视角和职责边界。当 AI 处于
/review模式时,它只做代码审查,不会去改产品方向。
3.2 核心流程总览
| Think | /office-hours | ||
| Plan | /plan-ceo-review/plan-eng-review/plan-design-review | ||
| Build | /guard | ||
| Review | /review/investigate | ||
| Test | /qa/cso/benchmark | ||
| Ship | /ship/land-and-deploy | ||
| Reflect | /document-release/retro |
关键机制:阶段间上下文传递
每个阶段的产出物(设计文档、技术方案、测试报告等)以 Markdown 文件形式保存,成为下一阶段的输入。这解决了 AI 编程中最头疼的"上下文腐败"问题——当你在 Build 阶段新开一个 Claude Code 会话时,它可以直接读取 Plan 阶段生成的架构文档,无需重新解释需求背景。
四、gstack vs OpenSpec:两张图厘清适用边界
gstack vs OpenSpec:两张图厘清适用边界
很多开发者在了解 gstack 的同时也会接触到 OpenSpec。这里用一张决策树厘清两者的核心差异与协同场景,避免选型时的困惑。
4.1 核心定位对比
| 核心定位 | ||
| 核心理念 | ||
| 覆盖链路 | ||
| 约束类型 | ||
| 上手门槛 | ||
| 适配场景 |
4.2 决策流程
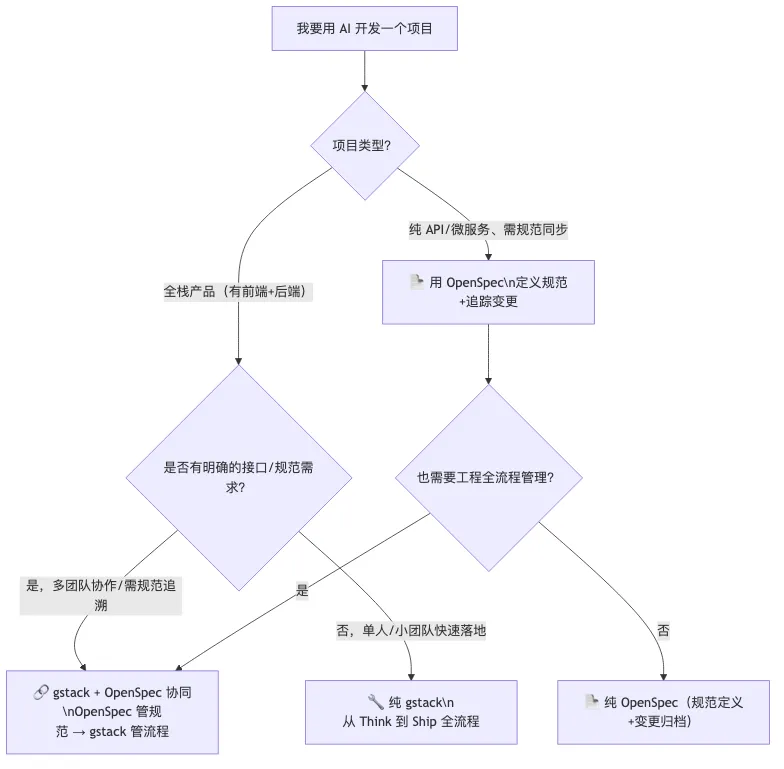
gstack 和 OpenSpec 不是竞品,而是不同维度的互补工具。gstack 的流程约束解决"在正确阶段做正确的事",保障工程落地效率;OpenSpec 的规范约束解决"规范的一致性和可追溯性",避免需求偏差——大型项目或跨团队协作时,两者协同效果最佳。
五、真实失败模式:为什么不用 gstack 会出问题
在进入实战演示之前,先看三类最常见的 AI 编程失败模式,以及 gstack 如何在机制层面规避它们。这不是理论推导,而是实际踩坑的提炼。
失败模式 1:方向性浪费(跳过 Think 阶段)
典型场景:开发者直接说"帮我做一个任务管理工具",AI 三分钟生成完整代码,但实现的是通用任务管理,而用户真正需要的是"小团队每日站会同步工具"。
根因:AI 接到模糊需求时,会用训练数据里最常见的实现填充——而不是追问"你为什么要做这个"。
gstack 的规避机制:/office-hours 强制用 6 个产品逼问重新定义问题,输出带有假设清单的产品设计文档,作为所有后续工作的约束。
失败模式 2:生产 Bug 频发(跳过 Review/Test 阶段)
典型场景:AI 生成的 API 在本地跑通,上线后被发现没有做用户权限隔离——任意用户都能读取他人数据。
根因:AI 写功能代码时的视角是"让代码跑通",而不是"让代码在生产环境安全运行"——这是两个完全不同的思维框架。
gstack 的规避机制:/review 以 Staff Engineer 视角审查代码,专门寻找"生产环境真正会出问题的 Bug"而非风格问题;/cso 基于 OWASP Top 10 做安全审计,权限模型是必查项。
失败模式 3:上下文腐败(无标准化传递机制)
典型场景:第一个会话里确定了"用 MongoDB",第三个会话里 AI 悄悄换成了 PostgreSQL;第一个会话定义了"任务状态用下划线命名(in_progress)",第四个会话生成的代码用了连字符(in-progress),导致查询永远不匹配。
根因:AI 没有跨会话记忆,每次对话都是全新的——而开发者在新会话里往往只告诉 AI"接着上次的做",并不重述所有约束。
gstack 的规避机制:每个阶段的产出物保存为 Markdown 文件,作为下一阶段会话的输入。技术栈、枚举值、权限模型、接口约定都在文档里,而不是在对话历史里。
六、实战:用 gstack 从 0 开发轻量级 Web 任务管理工具
以下按照 Think → Plan → Build → Review/Test → Ship/Deploy → Reflect 六个阶段,完整演示用 gstack 开发一个 Web 版任务管理工具的全过程。
初始需求:"我想做一个轻量级的 Web 任务管理工具,支持任务创建、优先级划分、状态跟踪。"
技术栈:Vue 3(Composition API)+ Node.js(Express)+ MongoDB
阶段 1:Think —— 先定产品,再写代码
为什么不能直接写代码?
如果直接对 AI 说"帮我写一个任务管理工具",它会在 30 秒内开始生成 index.html、app.js、server.js。但以下关键问题完全没有被回答:
• 目标用户是谁?个人使用还是小团队协作? • 核心场景是什么?每日任务追踪还是项目任务拆解? • 和 Todoist、Microsoft To Do、Trello 的差异化在哪里? • MVP 必须验证什么假设? • 如果只做一个功能,哪个功能能让用户明天就用?
直接写代码的代价:不是代码质量差,而是方向可能完全错误——而方向错误在写完所有代码之后才会被发现。
用 /office-hours 重构产品定义
/office-hours 我想做一个轻量级Web任务管理工具/office-hours 模拟 YC 的 Office Hours 模式——它不是顺着你的需求做,而是用一系列逼问来重新理解问题:
1. 用户现在怎么管理任务?微信聊天记录?纸笔?备忘录? 2. 现有方案最大的痛点是什么?忘记跟进?优先级混乱?信息分散? 3. 如果只做一个功能来验证需求,是什么? 4. 为什么用户不用 Todoist 或 Microsoft To Do? 5. 第一版要验证什么核心假设?
实测效果(基于 gstack v1.0 + Claude Code,2026年4月):
经过 /office-hours 的逼问,产品定位从模糊的"通用任务管理"收敛为:
小团队极简任务追踪工具:支持任务创建/编辑/删除、优先级划分(高/中/低)、截止日期、状态切换(待处理/进行中/已完成)、简单筛选——专注"每天打开就知道该做什么",不做项目管理,不做协作审批。
产出物:design/2026-05-11-tasktool-design.md,包含用户画像、核心场景、MVP 范围假设、待验证问题清单。
阶段 2:Plan —— 多维度规划,锁定范围与方案
/plan-ceo-review:砍掉不重要的一切
/plan-ceo-review/plan-ceo-review 支持四种审查模式:
| Scope Reduction | ||
| Hold Scope | ||
| Selective Expansion | ||
| Expansion |
对于任务管理工具 MVP,选择 Scope Reduction 模式。
必砍功能:团队协作与任务分配、复杂报表与数据看板、多项目管理/工作区、AI 任务优先级建议、日历视图/甘特图。
必留功能:任务 CRUD、优先级划分(高/中/低)、截止日期设置、状态切换(待处理/进行中/已完成)、按优先级/状态筛选。
产出物:ceo-plans/2026-05-11-tasktool-mvp.md
/plan-design-review:Web 端体验审查
/plan-design-reviewSenior Designer 视角会审查:信息架构(任务列表→任务详情的层级是否合理)、操作便捷性(创建任务步骤是否 ≤ 2 步)、状态反馈(操作后是否有明确的视觉反馈)、空状态设计(首次使用无任务时的引导)、响应式适配(PC/移动端 Web 的布局策略)。
💡 踩坑记录 #1:AI 生成的表单往往缺少实时校验提示——用户提交后才看到错误。正确做法是输入框失焦即校验,提交前已完成所有格式检查。这个问题在
/plan-design-review阶段就会被提出,而不是等到 QA 才发现。
/plan-eng-review:锁定技术方案
/plan-eng-reviewEng Manager 视角帮助锁定:
• 技术栈:Vue 3 + Express + MongoDB • 数据库模型:任务表(title, priority, status, due_date, created_at, updated_at)、用户表(username, password_hash, created_at) • API 设计:RESTful, GET/POST /api/tasks、PUT/DELETE /api/tasks/:id、GET /api/tasks?priority=high&status=pending• 测试矩阵:
为什么要在 Plan 阶段定义测试矩阵? 测试矩阵一旦定义,/review 和 /qa 阶段就有了明确的检查依据。如果等到 Build 之后再想"测什么",AI 生成的测试往往只覆盖 happy path,而边界情况完全空白。
产出物:eng-plans/2026-05-11-tasktool-eng.md,含架构图、数据流、API 文档、测试矩阵。
阶段 3:Build —— 分 Sprint 编码,安全可控
Sprint 1:项目初始化(/guard 安全模式)
/guard 初始化一个 Vue3 + Express + MongoDB 的任务管理工具项目/guard 等价于 /careful + /freeze 的组合——它锁定无关目录,避免 AI 误删配置文件、误改依赖包。
为什么需要 ? AI Agent 在项目初始化时会执行大量文件操作(npm init、vue create、目录创建)。如果不加约束,可能在错误的目录执行、覆盖已有配置、或安装不必要的依赖。/guard 将这些操作限定在安全的边界内。
产出物:tasktool-frontend/(Vue 3 脚手架 + 路由配置 + API 封装)、tasktool-backend/(Express 项目 + MongoDB 连接 + 目录结构)。
Sprint 2:核心 CRUD 实现 + /review 审查
实现任务创建、列表读取、编辑、删除、状态切换。完成后立即运行:
/review/review 的角色是 Staff Engineer——它不是在找代码风格问题,而是在找生产环境真正会出问题的 Bug。
userId 校验 | ||
skip/limit |
实测数据:/review 对 200 行 API 代码的审查自动发现 4 个问题(2 严重/2 中等),自动修复 2 个(分页 + 日期校验),需要人工决策 2 个(权限模型设计 + 日志粒度)。
Sprint 3:筛选与交互优化 + /investigate 排障
/investigate 筛选"进行中"状态任务时,已完成的也出现在结果里/investigate 的核心原则是:no fixes without investigation(先定位根因,再修复)。它会系统化追踪数据流:
1. 前端发送请求: GET /api/tasks?status=in_progress2. 后端接收参数: req.query.status = "in_progress"3. MongoDB 查询: Task.find({ status: req.query.status })4. 发现根因:MongoDB 中存储的状态值是 "in-progress"(连字符),而前端传的是"in_progress"(下划线),查询永远不匹配5. 修复:统一枚举值为 "in_progress",全局替换存量数据
这正是前面提到的"上下文腐败"失败模式——枚举值在不同会话里被不同方式定义。/investigate 的价值不只是找到这个 Bug,而是系统化地追踪它是怎么发生的,避免类似问题在其他地方复现。
对比数据:不使用 /investigate 时,AI 的典型行为是猜测式修复——可能改前端、改后端、改数据库,来回试 3-4 轮才定位根因。使用 /investigate 后,1 轮定位 + 1 轮修复,Token 消耗减少约 60%。
阶段 4:Review/Test —— 质量门禁
这个阶段有三个独立的质量检查,覆盖不同维度。每个检查都有明确的通过/失败标准,不是"检查了就行",而是"通过了才能进入下一步"。
/qa:真实浏览器测试
/qa http://localhost:8080/qa 不是跑单元测试,而是打开真实浏览器(基于 Playwright),模拟用户操作:点击按钮、填写表单、验证页面元素、截图记录。
测试流程:打开 Chrome,访问首页 → 创建"高优先级 + 明天截止"的任务 → 编辑任务优先级为"中" → 切换状态为"进行中" → 按"高优先级"筛选,验证结果 → 删除任务,验证列表刷新 → 截图每步结果,生成测试报告。
💡 踩坑记录 #2:AI 生成的页面在 Chrome 和 Firefox 下表现一致,但在移动端 Safari 中,
datetime-local输入框行为不一致——iOS Safari 对该类型的支持有限,需要使用text类型 + 自定义日期选择器,或使用flatpickr等第三方库。这类兼容性问题只在真实浏览器测试时才会暴露。
/cso:安全审计
/cso/cso 基于 OWASP Top 10 和 STRIDE 威胁模型进行审计。对于任务管理工具,重点检查:
实测发现的关键问题:GET /api/tasks 未强制按当前登录用户的 userId 过滤。虽然前端传了 userId 参数,但攻击者可直接调用 API 传入他人的 userId 查看数据。修复方案:后端从 JWT token 中提取 userId,忽略客户端传入的 userId 参数。
这个问题是 Sprint 2 里 /review 已经标记为严重级别的问题——/cso 在安全审计层面再次确认,确保没有被遗漏修复。
/benchmark:性能基准
/benchmark什么时候不该用 gstack 的完整流程?
如果你只是修改一个文案或调整一个 CSS 样式,走完整 Think→Ship 流程是严重的过度工程。gstack 的完整流程适用于功能级开发(≥1 个完整的 CRUD 模块)或从 0 到 1 的项目启动。对于单文件改动,直接用 Claude Code 的普通模式——流程的价值与任务的复杂度成正比。
阶段 5:Ship/Deploy —— 标准化发布
/ship:发布前检查
/ship/ship 的核心理念是:Test everything,以"可验证"作为发布前提。
执行流程:同步 main 分支 → 运行全量测试(单元 + 集成)→ 检查测试覆盖率(< 80% 阻止发布)→ 初始化缺失的测试框架 → 推送分支 + 创建 PR → 自动更新 CHANGELOG。
/land-and-deploy:上线部署
/land-and-deploy合并 PR → 等待 CI 通过 → 前端静态资源构建并部署到 Nginx → 后端服务通过 PM2 启动 → 数据库 migration 执行 → 生产环境健康检查(GET /api/health)。
首次部署需先用 /setup-deploy 配置服务器环境、部署脚本、环境变量。
阶段 6:Reflect —— 复盘与沉淀
/document-release:文档更新
/document-release自动更新:README(部署步骤、使用说明)、ARCHITECTURE(前后端交互流程、数据库设计)、发布说明(版本功能、已知问题)。
/retro:工程复盘
/retro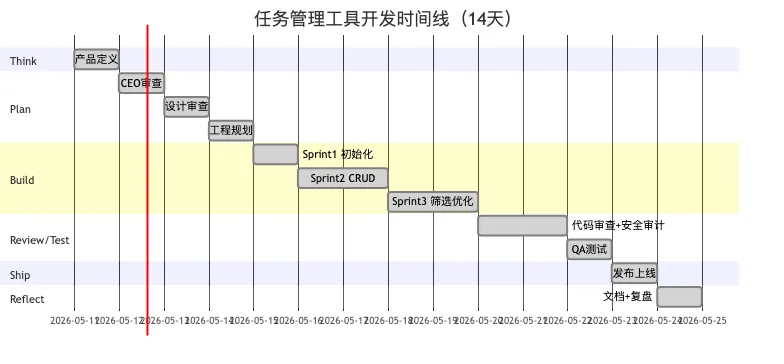
Think+Plan 占 4 天(29%),Build 占 5 天(36%),Review/Test 占 3 天(21%),Ship+Reflect 占 2 天(14%)。与传统单人开发相比,前期投入占比更高,但后期返工几乎为零——这是工程方法论对效率的最大贡献,不是靠"写得更快"实现的。
七、同一工作流,不同技术栈的决策差异
上面的实战案例以 Web 应用(Vue3 + Node.js + MongoDB)为技术栈。如果面对的是微信小程序场景,gstack 的流程结构不需要变,但每个阶段的决策内容会发生系统性变化:
| Think | |||
| Plan | |||
| Build | |||
| Review | |||
| Test | /qa http://localhost:8080 | ||
| Ship |
关键洞察:gstack 的阶段化流程是跨技术栈不变的常数。无论开发 Web 应用、小程序还是移动 App,Think→Plan→Build→Review→Test→Ship→Reflect 的流程结构不变。变化的是每个阶段内部的具体决策内容(技术选型、安全模型、测试方式、部署目标)。
这就是"流程即产品"的核心价值——你学会的不是一套命令,而是一套工程思维方式,它在任何技术栈上都适用。
八、安装与团队落地
快速安装(Claude Code)
git clone --single-branch --depth 1 https://github.com/garrytan/gstack.git \ ~/.claude/skills/gstack \ && cd ~/.claude/skills/gstack \ && ./setup团队项目配置
在项目根目录执行,团队成员进入项目时自动启用 gstack:
(cd ~/.claude/skills/gstack && ./setup --team) \ && ~/.claude/skills/gstack/bin/gstack-team-init required \ && git add .claude/ CLAUDE.md \ && git commit -m "require gstack for AI-assisted work"团队落地三原则
初级开发者从 /review/qa 开始(用 AI 审查自己的代码),建立对质量门禁的感知;高级开发者用 /office-hours/plan-eng-review(用 AI 辅助架构决策),解放产品和技术判断力。
统一使用 Think→Plan→Build→Review→Test→Ship→Reflect 流程,每个阶段的产出物放在约定目录;设计文档、技术方案、测试报告全部入 Git,形成可追溯的工程知识库——这才是 AI 编程真正的"长期资产"。
九、总结
gstack 的核心价值不是"让 AI 写得更快",而是让 AI 在正确的工程阶段做正确的事。
真正的工程效率来自两个地方:一是减少方向性浪费(Think 阶段),二是减少生产 Bug 的修复成本(Review/Test 阶段)——这两块加起来,往往是一个项目总成本的 60% 以上。
避坑三原则:
不要跳过 Think 阶段——方向错了,代码再优雅也是浪费。不要省略 /review——AI 写的代码在生产环境出问题的概率远超你的直觉。不要过度依赖 gstack——单文件改动直接用 Claude Code,完整流程只用于功能级开发。
从"写代码的 AI"到"做工程的虚拟团队",差的不是模型能力,而是工程流程的框架。gstack 提供的就是这个框架。
💬 加入讨论
你现在用的是什么 AI 编程方案?有没有遇到过 AI 跳过产品思考直接写代码的"方向性浪费"?欢迎评论区分享你的踩坑经历和解决方案。
📌 延伸资源
• 🔗 gstack GitHub:github.com/garrytan/gstack[1] • 📄 配套速查表:见下方附录
附录 A:gstack 常用命令速查表
/office-hours | |||
/plan-ceo-review | |||
/plan-design-review | |||
/plan-eng-review | |||
/guard | |||
/review | |||
/investigate | |||
/qa | |||
/cso | |||
/benchmark | |||
/ship | |||
/land-and-deploy | |||
/setup-deploy | |||
/document-release | |||
/retro |
附录 B:gstack vs OpenSpec 决策矩阵
| gstack | ||
| OpenSpec | ||
| OpenSpec + gstack | ||
| gstack | ||
| 不用任何工具 |
附录 C:三类失败模式快速索引
/office-hours | |||
/review/cso 安全审计 | |||
引用链接
[1] github.com/garrytan/gstack
