 夜雨聆风
夜雨聆风在人工智能大模型(LLM)狂飙突进的今天,行业内流传着一个共识:“数据是 AI 的燃料。然而,对于大多数企业而言,面临的现实并非燃料充足,而是堆积如山的“原油”——未经处理、标准不一、甚至连文档都缺失的碎片化数据。
如果数据治理不力,AI 就像是一个建立在流沙之上的摩天大楼。数据治理,这门原本被视为 IT 后台“苦活累活”的传统手艺,正在成为决定企业 AI 转型成败的生死之战。本文将抽丝剥茧,深度探讨数据治理的本质逻辑以及 AI 如何改变这一传统领域。
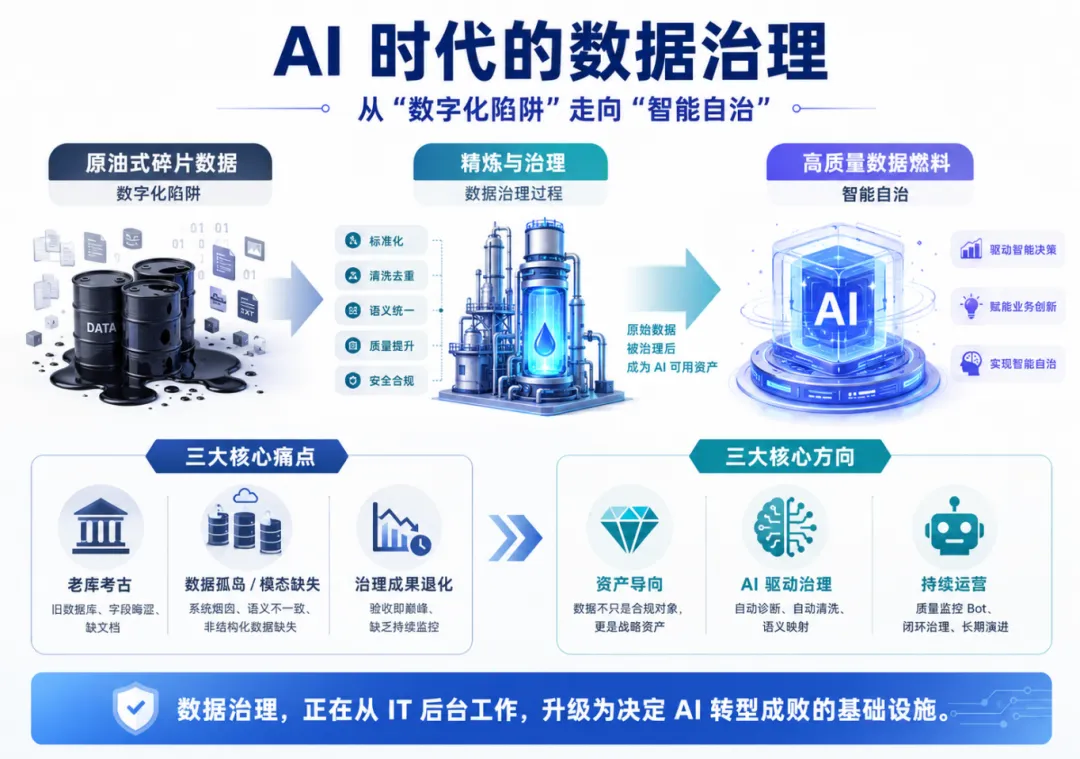
一、数字化转型的“隐形天花板”
许多企业在推进数字化时,往往会遭遇三个典型的“治理泥潭”:
1.“老库”考古学:许多企业的核心业务数据沉淀在十年甚至二十年前的旧数据库,例如Oracle、SQL Server 甚至早期的 DB2。这些系统往往缺乏文档注释,字段名全是类似proj_m_code的晦涩缩写。对这些数据的挖掘,往往变成了一场耗时数月的“考古”行动 。
2.数据孤岛与模态缺失的双重泥潭:企业系统“烟囱”林立导致数据语义互斥,对账如同各执一词的“罗生门”;同时,传统治理过度聚焦结构化数据,致使大模型亟需的非结构化资产严重流失。若将这些逻辑冲突且模态单一的数据直接投喂,不仅无法驱动业务,反而会成倍放大AI“幻觉”,得出荒谬的决策建议。
3.治理成果退化:许多项目面临“验收即巅峰”的窘境。交付时数据虽焕然一新,但因缺乏覆盖全生命周期的常态化监测,静态的清理动作无法应对动态流转的业务洪流 。不出三个月,若无“免疫系统”般的持续拦截机制,治理成果便会迅速退化,系统再次被新产生的垃圾数据蚕食,导致前期的巨大投入沦为沉没成本 。
二、趋势演进:从“IT 管理”到“数据资产化”
面对上述泥潭,2026 年的数据治理逻辑正在发生底层蜕变。当前,行业的一个显著趋势是数据治理正从“管理导向”全面转向“资产导向”。
数据治理不再仅仅是为了满足合规性而设立的打勾清单,而是维持企业竞争力和建立信任的战略必然要求。治理平台不仅要承担清洗整合的基础工作,更要成为数据价值发现和资产登记入表的核心载体。不仅如此,随着生成式AI 的发展,预计到 2027 年,将有超过 60% 的组织因底层数据治理不足而无法真正兑现 AI 的商业价值,以更好地交付 GenAI 应用并提升企业决策质量。
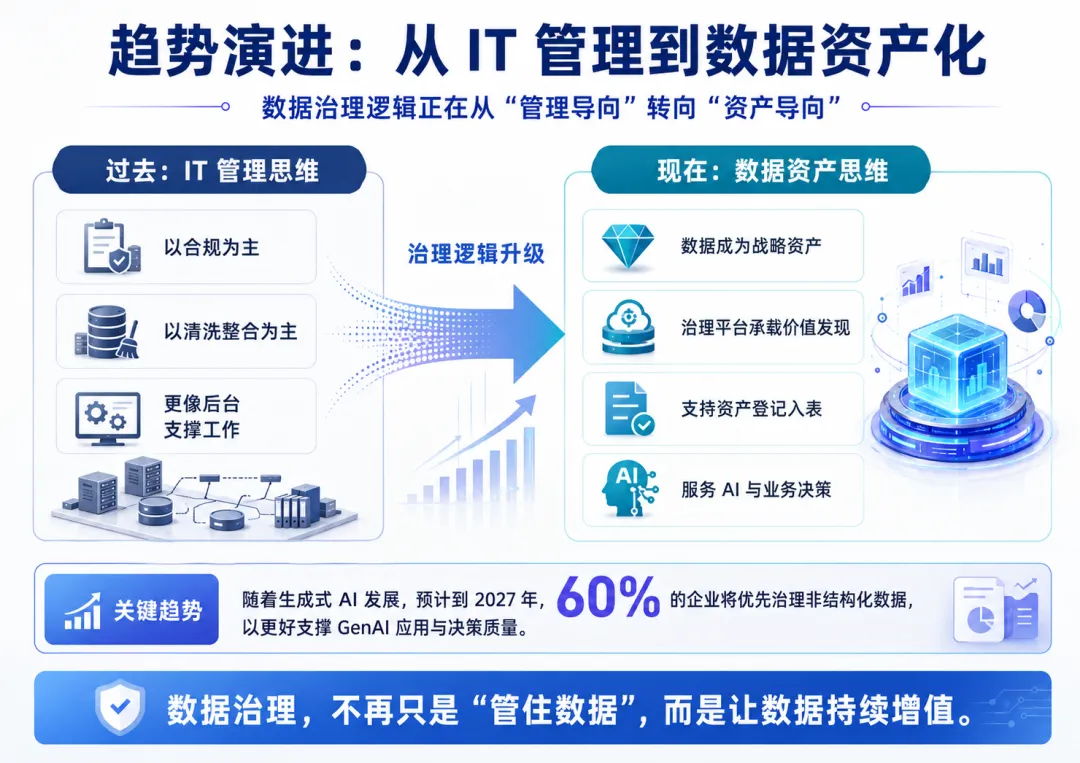
三、数据治理AI Agent的“五步法”逻辑
真正产生价值的数据治理,并非一次性的技术补丁,而是一个闭环的系统工程。行业主流的科学路径通常分为五个阶段:
诊断与规划:不仅是看数据库,更要深入一线理解业务流向。通过逆向工程自动绘制数据血缘图,识别哪些是“源头表”,哪些是“冗余表” 。
标准与建模:参照DAMA 框架或国家标准,制定统一的《数据标准化手册》 。关键在于实现跨系统字段的语义映射,如通过向量相似度自动匹配不同系统间的同义字段 。
清洗与整合:这是治理中工作量最大的环节。传统的规则清洗已难以应对模糊数据,现在的趋势是利用AI 自动填补空值、纠正格式异常,并识别诸如“某某集团”与“某某有限公司”其实是同一实体的语义消重问题 。
应用与赋能:治理后的数据应通过Text-to-SQL 等技术,让管理者能用自然语言直接提问(如:“上月毛利率最高的十个项目是谁?”)并获得可视化分析 。
持续运营:部署质量监控Bot,当数据质量分数下降时自动触发告警,确保治理成果不退化 。
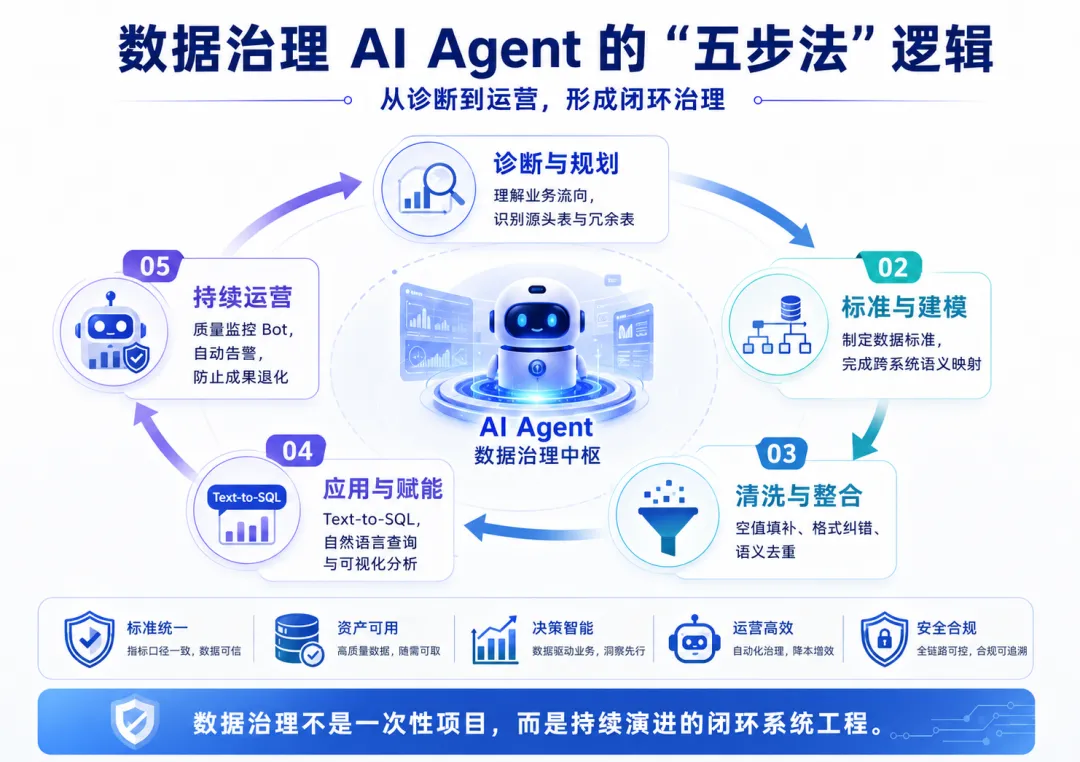
四、行业实践的破局之道:从“人工主导”到“智能自治”
传统的数据治理极度依赖顾问的个人经验,成本高且周期长。随着AI Agent(智能体)技术的成熟,数据治理正发生革命性的升级:
1.非结构化数据的“救活”:过去,合同PDF、往来邮件等非结构化数据是无法治理的。现在,通过向量数据库(如 Milvus、Chroma)进行 Embedding 存储,可以实现语义检索,将“死数据”变为“活资产” 。
2.智能诊断Agent:AI 可以自动连接数据库,通过数据样本推断字段含义,生成自然语言的表结构说明文档,将诊断周期从数月缩短至数周 。
3.主动治理与数据合约:在数据进入系统前建立“数据合约”,由 Agent 自动监控格式和质量,从源头上杜绝脏数据的产生 。
在羽山数据的深度治理实践中,我们发现引入“以 Agent 为核心、人工兜底”的模式,已经可以替代约 80% 的重复性治理工作。在处理海量核心档案时,关键维度信息的补全率可基本达到95%。
五、结语:风暴才刚刚开始,敬请期待系列拆解
以上探讨的“五步法”与初步的 AI 实践,仅仅揭开了这场数智化变革的冰山一角。数据治理是一场长期的马拉松,而非百米冲刺。
站在2026 年的拐点上,行业权威机构曾发出严厉警告:未来将有超过半数的组织,会因为底层数据治理不力而无法真正兑现 AI 的商业价值。面对快速演进的监管要求、日趋复杂的业务架构以及大模型带来的惊人潜力,数据治理已经到了必须被“重新定义”的关键时刻。
毫无疑问,真正的“深水区”还有更多硬核命题等待我们去抽丝剥茧。比如,大模型时代究竟放大了哪些传统治理的痛点?企业该如何应对从数据投毒到合规冲突的连环“地雷”?从“人治”向“智治”跨越的这几年,行业将迎来哪些决定性的技术趋势?面对市面上令人眼花缭乱的云原生治理工具与 AI 平台,企业又该如何避坑选型?更重要的是,如何彻底抛弃“治理即成本”的旧思维,让底层数据真正蜕变为可增值、可变现的战略资产?
在这个AI 狂飙的时代,建立坚实的自动化治理流水线,是持续输出高质量“燃料”的唯一路径。作为新一代智能数据治理的探索者与实践者,羽山数据深知企业从“人工治理”走向“智能自治”所必经的阵痛与挑战。关于数据资产重塑的战役才刚刚打响。在接下来的系列分享中,我们将结合羽山数据在大量政企服务一线的真实落地方案与技术洞察,继续和大家逐步深挖这些隐藏在冰山之下的底层逻辑。
带着敬畏与好奇,让我们一起探索数据智能基础设施的星辰大海!
========== END ==========
本文由羽山数据产品团队分享,旨在探讨AI 驱动下的数据治理新思路。
如果您正处于数字化转型的深水区,或对文章探讨的AI 驱动治理模式感兴趣,欢迎添加下方微信(或邮件)沟通交流,免费获取完整内部参考资料。
【联系我们】
AI数据治理顾问:周经理
Email:zhoumengli@yushanshuju.com
公司官网:https://www.usendata.com
地址:上海市虹口区飞虹路118号瑞虹企业天地T2-1719

