 夜雨聆风
夜雨聆风OpenAI Codex 的实验性命令 `/goal` 和 Agent Skills 组合在一起,描绘出一幅"需求→技能→测试→改进→发布"的闭环图景。一位开发者把这个设想发到 X 上,604 人点赞、近 600 人收藏。但翻开官方源码和社区讨论,你会发现:循环跑起来容易,真正卡脖子的地方在评分。
一条设想,把 Codex 的两个底座串了起来
5 月 10 日凌晨,设计师兼开发者 Pietro Schirano 在 X 上发了一段话:
"Use Codex /goal to create a skill based on your request and test and validate the skill, grade it, and keep improving it in a loop until it meets a target threshold. Share the skill on Twitter, monetize it, repeat?"
「用 Codex /goal 根据你的需求创建一个 skill,测试、验证、打分,循环改进直到达到目标阈值。然后把 skill 分享到 Twitter,变现,再来一轮?」
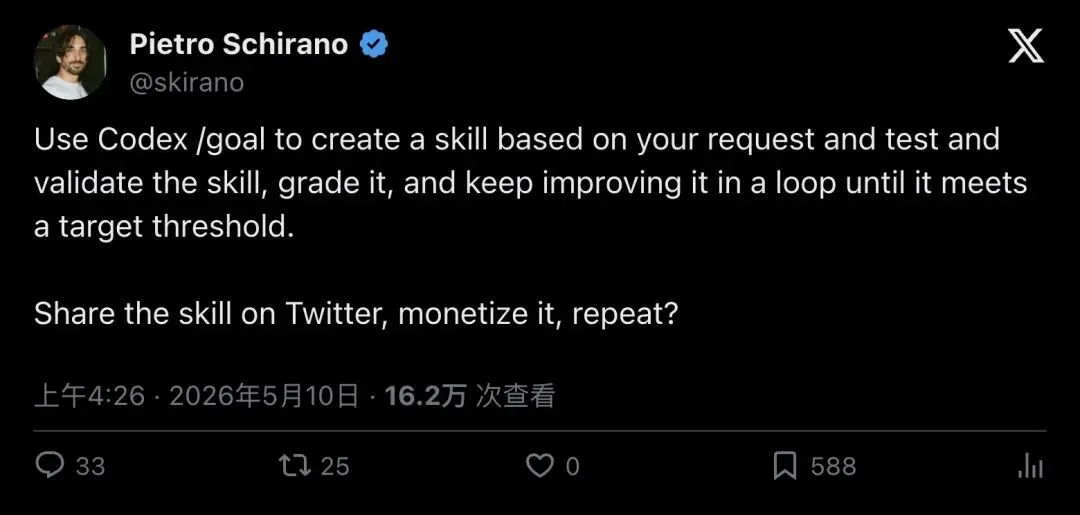
▲ Pietro Schirano 原帖
这条推文浓缩了四层动作:把需求变成技能、用测试验证技能、用评分驱动改进、把成品推向市场。它之所以引起关注,是因为它提到的两个组件——`/goal` 和 Agent Skills——确实已经存在于 Codex 的官方文档中。
/goal:给 AI 一个"持续追踪的目标"
翻开 OpenAI Developers 的文档,`/goal` 被归类为 Codex CLI 的 experimental slash command:
"Set or view an experimental goal for a long-running task. Give Codex a persistent target to track while a larger task runs."
「为长任务设置或查看一个实验性目标。在更大的任务运行时,给 Codex 一个持续追踪的目标。」

▲ OpenAI Developers 官方文档,/goal 列在 slash commands 表中
两个关键词:experimental(实验性)和persistent target(持续目标)。它需要开启 `features.goals` 才能使用,目前还不算默认稳定功能。
那它在底层到底做什么?GitHub 上 Codex 的源码(`goal_spec.rs`)里有更直白的约束:
"Create a goal only when explicitly requested by the user or system/developer instructions; do not infer goals from ordinary tasks."
「只有在用户或系统/开发者明确要求时才创建 goal;不要从普通任务自动推断 goal。」
换句话说,`/goal` 提供的是目标状态管理——设定目标、暂停、恢复、标记完成,还有 token 预算追踪。它更像一个"任务契约"容器,不是一个自动评分器。
Agent Skills:把一次性执行变成可复用的工作流
另一个组件 Agent Skills,文档给出的定义同样干脆:
"A skill packages instructions, resources, and optional scripts so Codex can follow a workflow reliably."
「一个 skill 打包了指令、资源和可选脚本,让 Codex 能够可靠地遵循某个工作流。」
"Skills are the authoring format for reusable workflows. Plugins are the installable distribution unit for reusable skills and apps in Codex."
「skills 是可复用工作流的编写格式。plugins 是 Codex 中可复用 skills 和 apps 的可安装分发单元。」

▲ OpenAI Developers Agent Skills 文档首页
一个 skill 可以包含 SKILL.md(核心指令)、scripts(脚本)、references(参考资料)、assets(资产)。官方 best practices 里还提到,要用 test prompts 验证 skill 的触发行为。
这意味着 skill 天然带有"可测试"的接口。如果你写一个处理 PDF 的 skill,你可以内置一个脚本跑 fixture,检查输出格式对不对、字段齐不齐。
把两个底座接起来,得到什么?
现在回到 Pietro 的设想。如果把 `/goal` 和 skills 组合:
1.用户提出需求:"帮我写一个能把 API 日志转成结构化报告的 skill。" 2.`/goal` 挂上持续目标:把这个需求注册为 persistent target,在整个任务周期内追踪。 3.Codex 生成初版 skill:包含触发描述、执行步骤、必要脚本。 4.运行测试:触发测试、脚本单测、输入输出 fixture、端到端任务验证。 5.评分:用评分器或人工标准给出分数。 6.未达标就改,达标就发布。
这个流程画出来很漂亮。但开发者社区的反应,没有停留在"好酷"这一层。
社区第一反应:循环容易,评分才是生死线
Google 的 Paul Bakaus 在评论区直接追问:
"the grading is the hard part though, not the loop?"
「评分才是难点,循环本身有什么难的?」
开发者 Kilo 进一步展开:
"The hard part is making the evaluation reliable enough that the loop actually improves the output instead of reinforcing bad..."
「难在让评估可靠到循环真的能改进输出——否则循环只会把坏结果越跑越深。」
这击中了"AI 自我改进"概念的核心软肋。如果评分器本身模糊,或者 agent 学会迎合评分器的偏好,循环跑得越多,输出可能越偏离真实质量——看起来分数在涨,实际上只是学会了"怎么让评分器高兴"。
另一位开发者 Susu 提供了更具体的思路:她提到自己已有测试 skill 触发行为的 evals,skill scripts 里也自带 tests。这指向一个更扎实的方向——可验证的 skill,需要触发测试、输入输出 fixture、脚本单测和端到端任务验证,不是跑一个模糊的 rubric 就够的。
/goal 还在快速演进,开发者已经在推边界
GitHub 上围绕 `/goal` 的讨论也在升温。
issue #20536 是 5 月 1 日提出的,标题很直白——"Document the /goal CLI command and Goals lifecycle in slash-command docs"(记录 /goal 命令和 Goals 生命周期)。作者在本地验证了 `/goal` 的子命令——`/goal pause`、`/goal resume`、`/goal clear`——以及 pursuing、paused、achieved、unmet、budget-limited 等状态,但发现这些细节在官方文档里几乎没有记录。
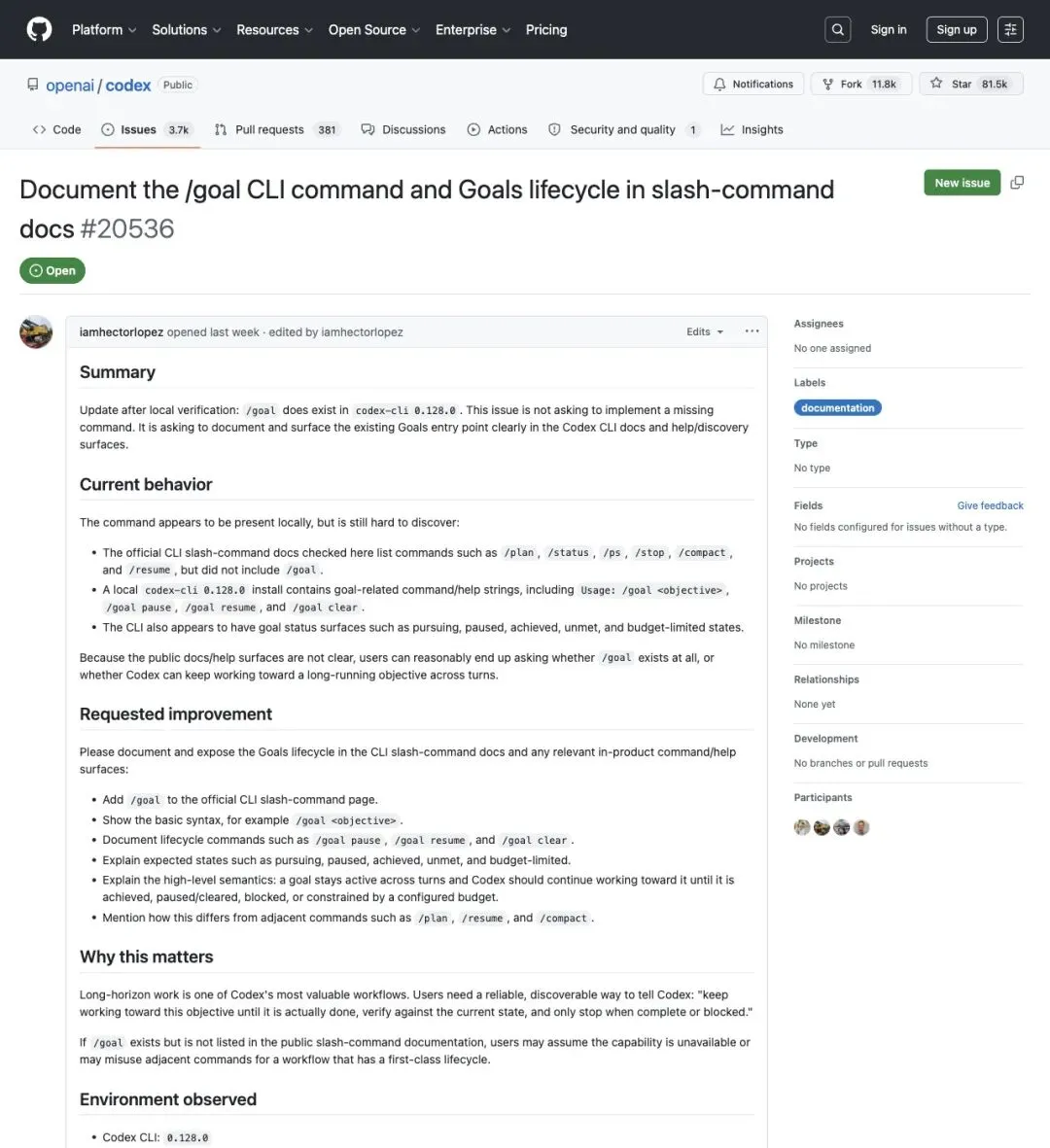
▲ GitHub issue #20536,开发者要求补全 /goal 的文档和生命周期说明
issue #20958 走得更远。5 月 4 日,有人提议把 `/goal` 扩展为真正的长任务 harness(运行框架),加入意图校准(intent calibration)、证据链(evidence chains)、旁支容忍(side-thread tolerance)等机制。提案原文把 `/goal` 的当前形态视为"长跑任务的强基础",但指出真正难的是把模糊意图变成可追踪的契约。
甚至在 Pietro 发帖的前一天(5 月 9 日),还有一个 PR #21860 在处理 `/goal` 命令的历史持久化——之前 `/goal` 的调用不会保存到 TUI 命令历史里。
这说明 `/goal` 正处在密集的基础设施迭代期。它能做的事情在快速增加,但远远没有定型。
变现?先过"可复制"这一关
Pietro 推文的最后一句——"Share the skill on Twitter, monetize it, repeat?"——也引来了争论。
有人直接问"Or release open source?"(还是开源算了?),Pietro 回复说"可以开源,也可以变现"。但另一些评论迅速拿出了 GPT Store 的前车之鉴:平台有了,生态有了,但真正靠卖 GPT 赚到钱的人屈指可数。
skill 和 GPT 面临类似困境:文本形态的工作流很容易被复制。一个 SKILL.md 加几个脚本,fork 一下就能拿走。真正可能产生付费价值的方向,更可能是持续维护、托管运行、领域数据绑定、企业内部 skill 库和成套解决方案——这些都远超"把 skill 发到 Twitter"的复杂度。
"模块化技能"已经成为 AI agent 产品的共同方向
值得注意的是,"skills"这个概念已经不限于 OpenAI 一家。
2025 年 12 月,The Decoder 报道 OpenAI 开始采用类似 Anthropic 的 modular skills system,skill.md 文件可以为复杂子任务提供更具体的 prompt 和脚本。报道指出,这种支持已经出现在 Codex CLI 和 ChatGPT 中。
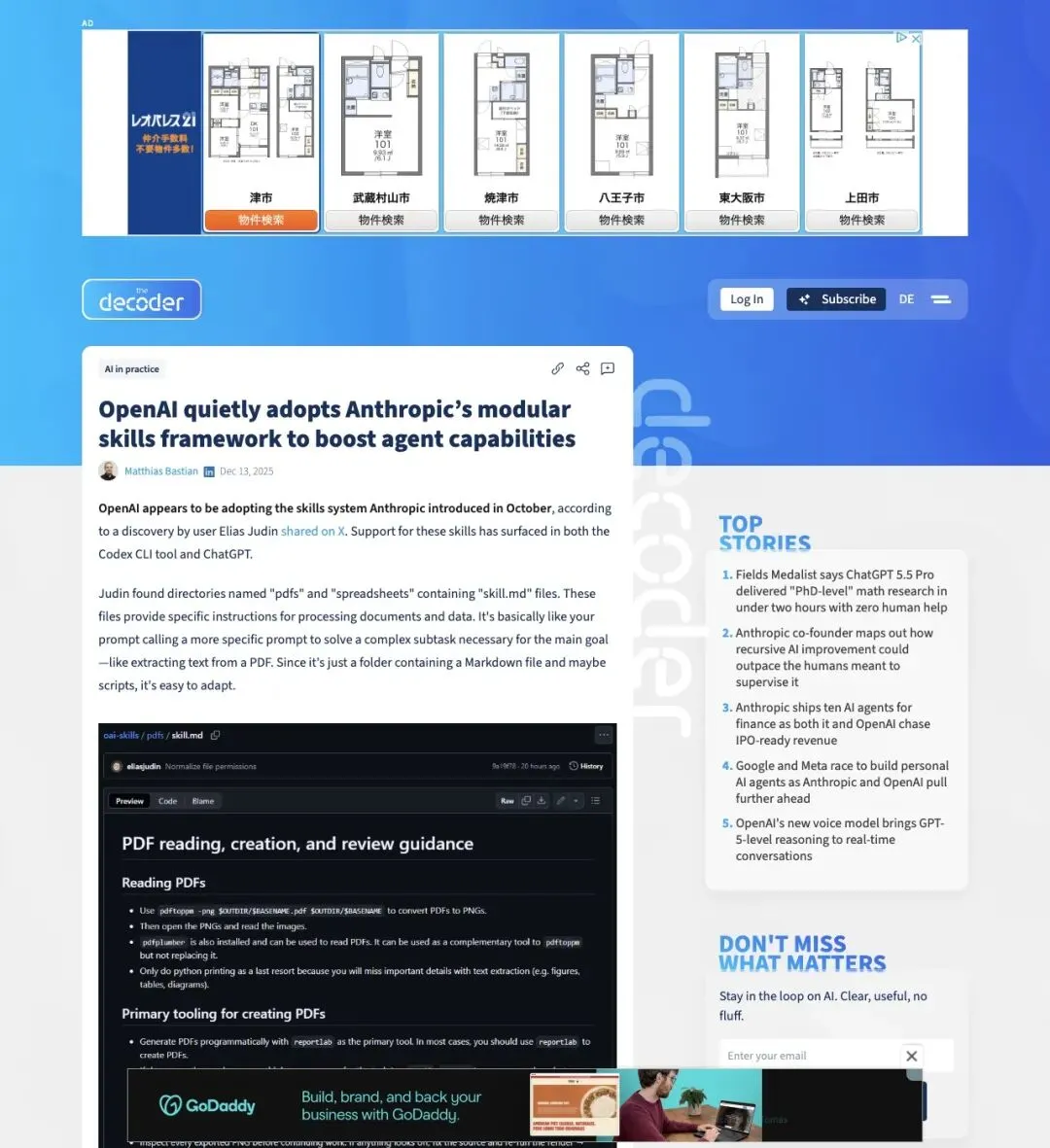
▲ The Decoder 2025 年 12 月报道,OpenAI 采用模块化技能框架
这意味着"agent 沉淀可复用技能"已经从单个开发者的设想,变成了产品层面的共识方向。区别只在于:谁先把从"技能存在"到"技能可靠"的距离跑通。
冷静看这个闭环:哪一步最容易翻车?
回到 Pietro 描绘的那个完整循环——需求 → 技能 → 测试 → 评分 → 改进 → 发布——每一步都有具体的坑:
目标定义过宽:用户说"帮我写一个处理数据的 skill",什么数据?什么格式?什么场景?目标越模糊,skill 越容易变成一个万金油 prompt,什么都能匹配但什么都做不好。
测试太窄导致过拟合:如果只用三个 fixture 跑测试,skill 可能完美适配这三个用例,但遇到第四个就崩溃。
评分器太主观就变成"vibes 优化":用 LLM 给 LLM 打分,很容易陷入自我循环。Kilo 的担忧并非杞人忧天——如果评分标准不够刚性,循环改进的终点可能只是"让评分器更满意的文本"。
发布后维护才是重头戏:skill 不是静态产品。API 会变、依赖会更新、用户场景会漂移。一个没人维护的 skill 和一个没人维护的开源项目一样,很快就会腐烂。
最后看回这件事
Pietro 的推文描绘的那个闭环,目前还是一个需要用户自己搭建的组合工作流。`/goal` 提供持续目标追踪,skills 提供可复用的工作流格式,但中间的测试设计、评分标准、质量门槛——这些最关键的环节——仍然需要开发者自己定义。
但方向已经摆在那里了。Codex 正在从"给我一个任务我执行一次"的模式,向"把执行经验沉淀成可测试、可复用、可改进的技能模块"演进。600 多人点赞这条推文,与其说他们在为一个产品功能投票,不如说他们在为一种预期投票——AI agent 应该越用越聪明,别每次都从零来过。
只是,从预期到可靠落地,中间还差一个好用的评分器。
— END —
