 夜雨聆风
夜雨聆风
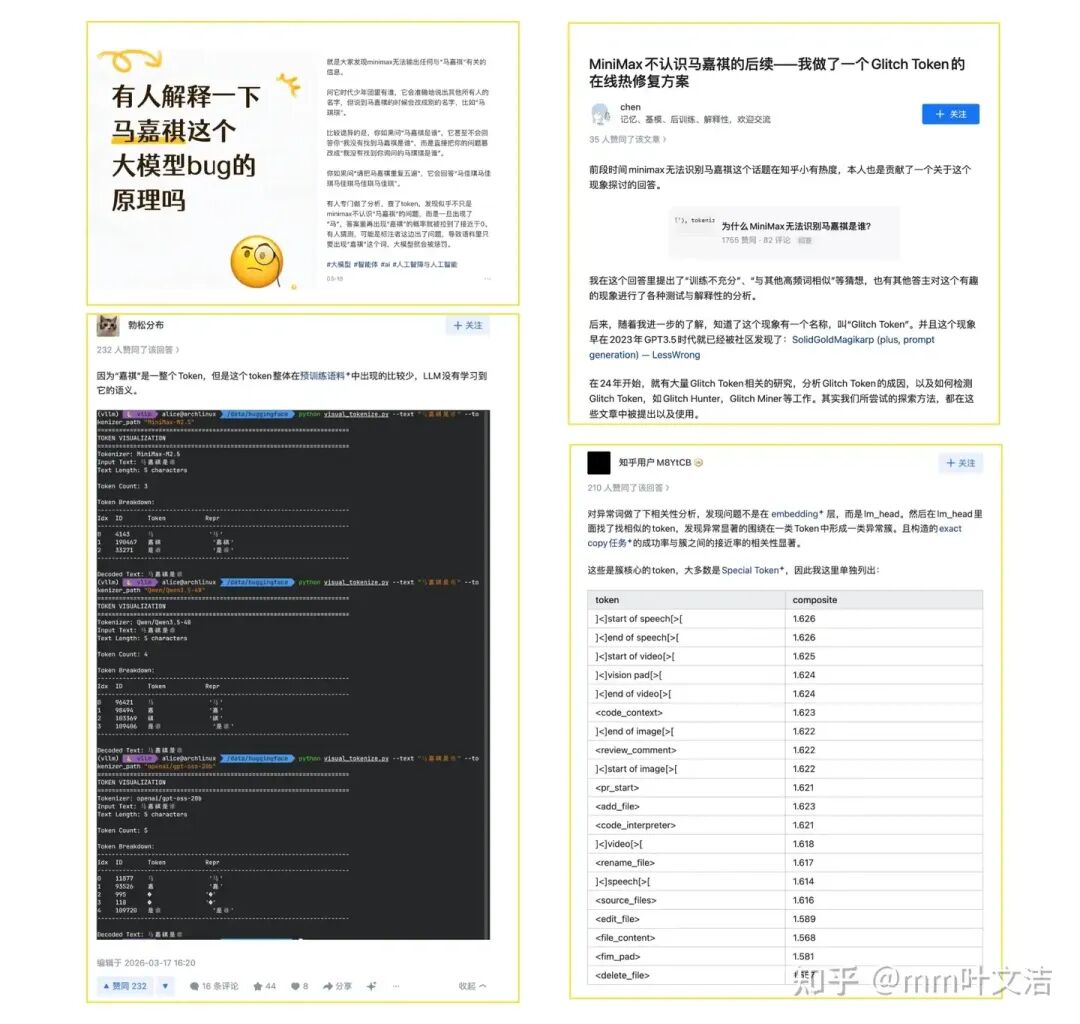
前阵子到处都在讨论一件怪事:MiniMax 的 M2 模型,说不出「马嘉祺」这三个字。
问它时代少年团的队长是谁,它能讲出「马嘉祺」的生日、所在院校等基本信息,但「嘉祺」这俩字,就是说不出来。要么绕开不写,要么只写出「马嘉」两个字。为什么会出现这种「话到嘴边说不出口」的现象?事情最开始很像一个粉圈与 AI 圈交叉的小插曲,但MiniMax 技术团队没有把它当成一个简单的幽默事件,而顺着模型生成链路,发现了一个后训练阶段的 token 漂移问题。
问题究竟出在哪? MiniMax 官方发布了一篇技术博客,公开了整个排查过程。
文末有「划重点」总结👇
为什么 MiniMax 大模型无法识别马嘉祺是谁?
答主丨mm 叶文洁(3130+赞同)
大家好,我是 MiniMax Forge 的 zhongyu。MiniMax M2 系列受到了开发者社区的广泛关注,不少用户在深度使用中发现了一些 corner case——其中「模型无法说出马嘉祺」这个问题在各平台上引发了较多讨论。我们也注意到,社区中有不少开发者对这个现象进行了相当严谨的分析和论证,包括 tokenizer 对比、采样参数测试等。
在内部复现后,我们发现这不是一个孤立的 case——除了「马嘉祺」之外,还有一些其他低频词汇(如「王郸」等)也存在类似现象。社区开发者已经给出了很有价值的分析,但受限于资源,较难进一步深入到模型训练层面进行实验验证。作为模型的开发者,我们认为这个问题背后的原因和机制值得做一次系统的研究,而我们也有条件对比 pretrain 与 SFT 各层参数的变化、分析 lm_head 的退化模式、量化稀疏 token 的遗忘机制,并通过训练实验验证修复方案。
目前此问题已经在内部排查完成,并且在后续模型中更新解决,这条排查线索还帮助我们定位并解决了另一个诟病已久的小语种语言混杂问题。
这里将内部的排查过程和实验结果整理出来,希望能为社区的讨论提供更多参考。
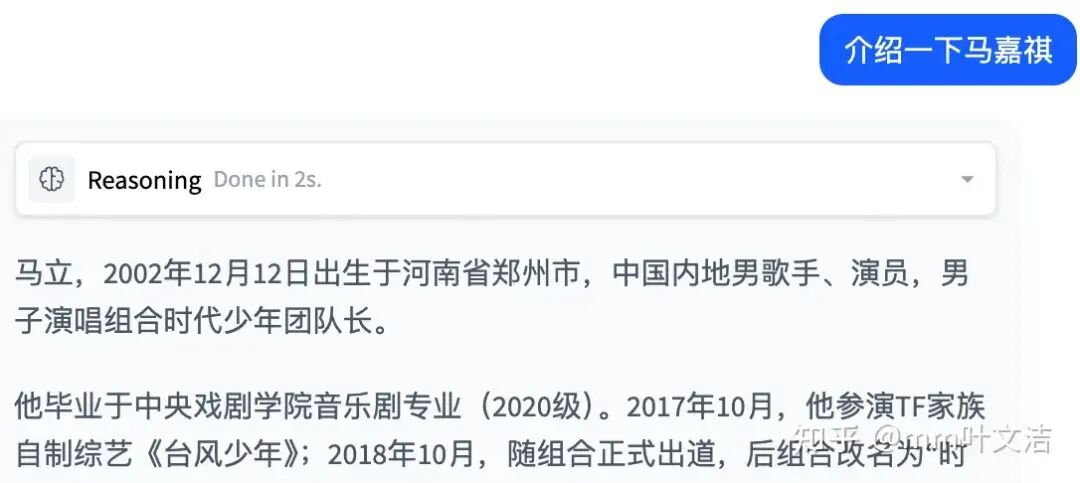
从这个 case 来看,模型依然具备相关的知识——能回答马嘉祺的基本信息(如所属团体、出道时间等),说明对应的语义表征并未丢失,只是在生成阶段无法将「嘉祺」这个 token 输出出来。
因此首先排查 tokenizer 层面:检查模型输入和期望输出的 token id,确认文本与 token 互转过程是否存在不匹配。
使用后训练的 tokenizer encode:马嘉祺,结果如下:
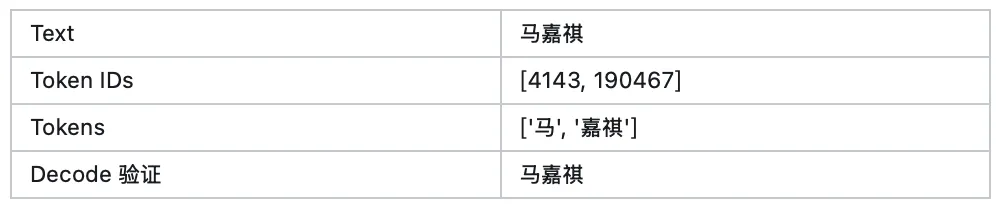
encode 和 decode 过程均正常,但一个值得注意的细节是:「嘉祺」被分词为一个独立的 token(id=190467)。
这两个字在日常语料中共现频率较低,作为单一 token 存在略显意外。由此产生一个假设:是否是因为预训练和后训练+serving 阶段使用了不同的 tokenizer 策略,在预训练预料中「嘉祺」实际被切分为两个 token [『嘉』, 『祺』],导致「嘉祺」这个 token 没有得到充分训练。而后训练和 serving 阶段使用合并后的 token ,其生成概率会很低(小于 5%),那么在 top-p = 0.95 的采样策略下就会被 mask,从而无法生成。
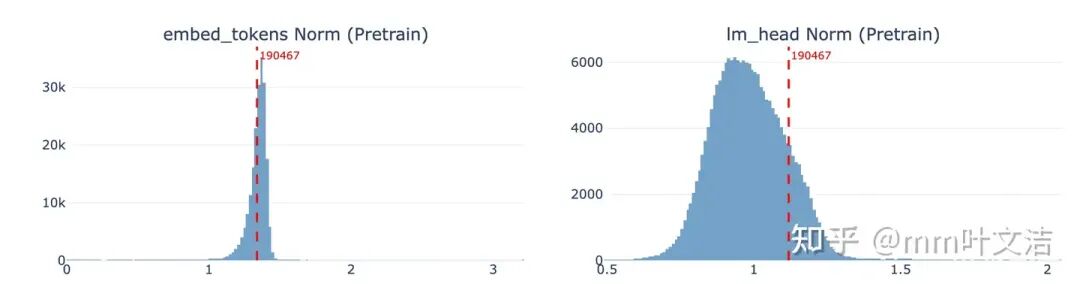
为验证这一假设,检查预训练模型的 vocab embedding,从统计分布和语义近邻两个角度确认 token 190467(「嘉祺」)是否在预训练阶段经过了充分训练。
统计分布检查:对比全词表的 embed_tokens norm 分布,token 190467(「嘉祺」)的向量范数落在正常分布范围内,未出现未训练 token 常见的异常小值的现象,表明该 token 在预训练阶段已被充分学习。
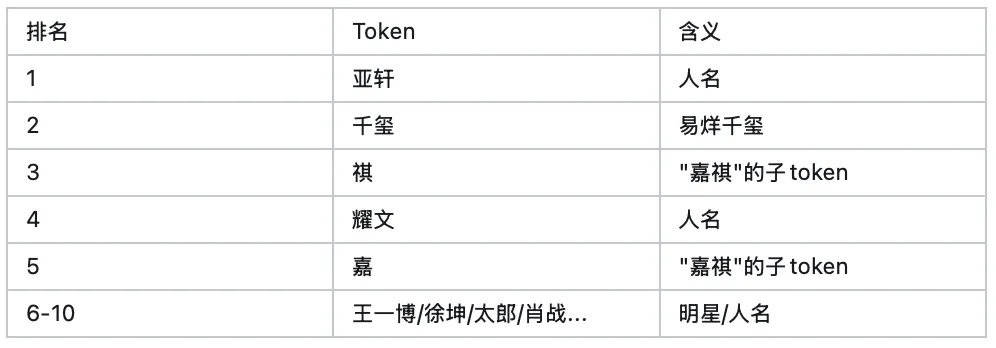
语义近邻验证: 对「嘉祺」的 embedding 进行最近邻检索,召回结果包括「千玺」、「亚轩」等语义高度相关的中文人名 token,说明预训练模型已经为该 token 建立了合理的语义聚类,tokenizer 与模型参数在预训练阶段是对齐的。
跟「嘉祺」的 token embedding 最接近的 Top-10 tokens:
预训练与后训练模型 few-shot 对比实验:为进一步确认问题出现的阶段,分别在预训练 base 模型和后训练模型上进行 few-shot 测试。通过其他人名作为示例,引导模型回答包含「马嘉祺」的问题:
Q: TFBOYS 的队长是谁?
A: TFBOYS 的队长是王俊凯。
Q: 飞儿乐团的主唱叫什么?
A: 飞儿乐团的主唱叫詹雯婷(Faye)。
Q: 时代少年团的队长是谁?
A:
预训练 base 模型:能够正常续写出「时代少年团的队长是马嘉祺」,「嘉祺」 token 可以正常生成。
后训练模型:模型仍倾向于回避该 token,依然无法正常输出 token。
综合以上三项验证,可以排除 tokenizer 不对齐的假设:token 190467(「嘉祺」)在预训练阶段经过了充分训练,具备正确的语义表征。问题的根源应当在后训练阶段。
既然问题出在后训练阶段,一个自然的猜测是:后训练数据中「嘉祺」这一 token 的出现频率过低,导致模型在 SFT 过程中逐渐「遗忘」了对该 token 的生成能力。
对后训练数据进行统计,发现包含「嘉祺」的样本不足 5 条,基本印证了这一假设。
当然,最直接的修复方式是在后训练数据中补充相应样本。但我们更关心的是:模型内部究竟发生了怎样的变化?是否存在某些中间指标,能够更精确地刻画这种稀疏 token 的遗忘机制?
另一个有趣的问题是,模型为什么依然认识「嘉祺」这个 token,为什么后训练数据缺失仅仅让它丢失了生成能力而仍然保留理解能力?
由于模型的大部分能力(如知识问答、指令遵循等)在后训练后并未出现退化,可以推断 Transformer 中间层的表征变化不太可能是问题的主因。更合理的排查方向是模型的首尾两端——输入侧的 vocab embedding 和输出侧的 lm_head,这两层直接参与 token 级别的映射,对稀疏 token 的影响最为敏感。
对比预训练与 SFT 后的 vocab embedding,发现两者几乎没有差异。
这与预期一致:一方面反向传播过程中梯度范数逐层衰减,另一方面,对于出现频率极低的 token,embedding 层几乎不会收到来自 loss 的有效梯度更新,仅有 weight decay 施加微弱的正则化作用,因此 vocab embedding 在后训练前后保持稳定是合理的。
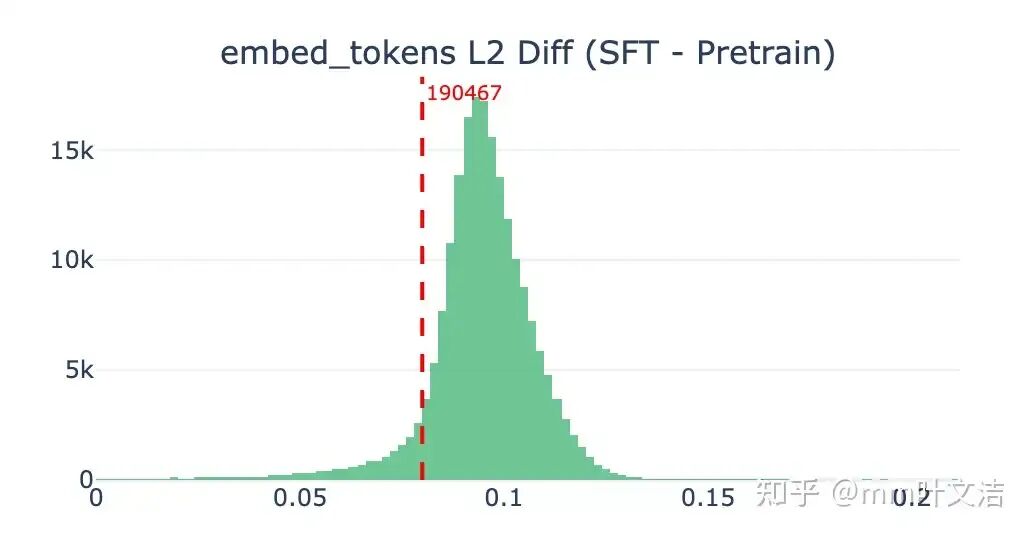
Embed_tokens L2 Diff (SFT - Pretrain)直方图,token 190467 标注在正常分布范围内]lm_head:变化显著转而检查输出侧的 lm_head,发现「嘉祺」对应的权重向量在后训练过程中发生了显著偏移,主要体现在两个方面:
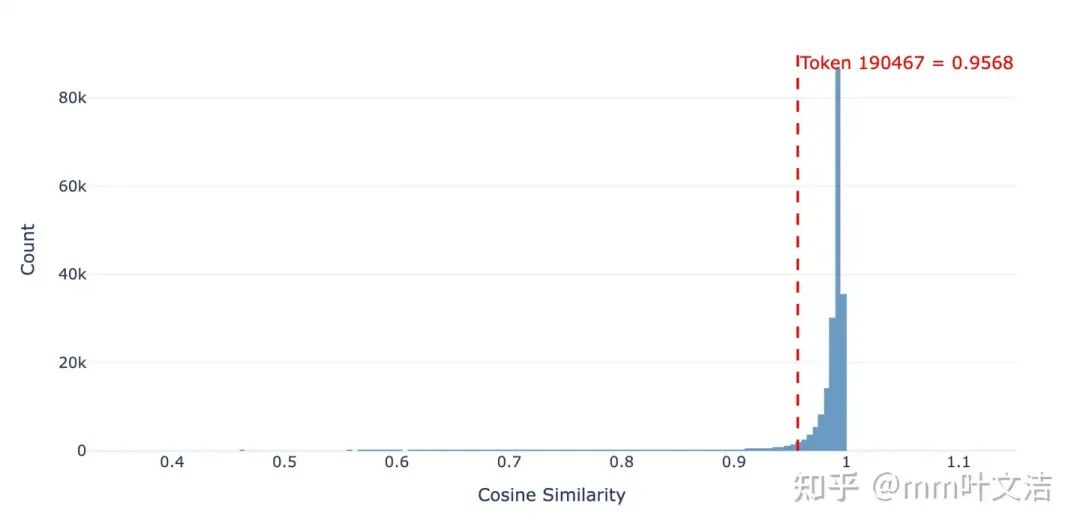
余弦相似度大幅下降且 Norm 变化很大:计算 SFT 前后 lm_head 中每个 token 向量的cosine similarity,token 190467(「嘉祺」)的变化幅度在整个词表中排名靠前,表明其输出表征已被大幅改写,同时 L2 Diff 也发生了显著变化。
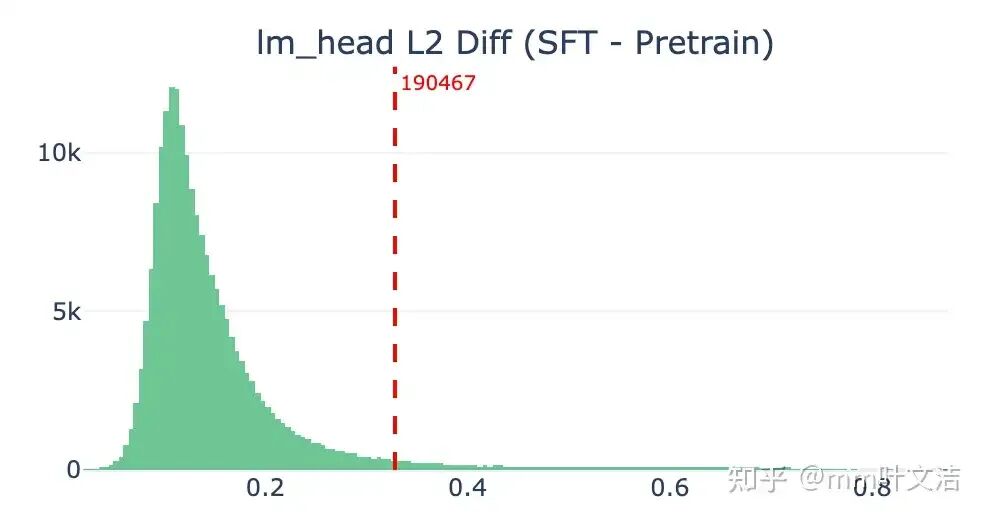
最近邻语义结构发生剧变: 对 lm_head 中「嘉祺」向量的最近邻进行对比,可以更直观地看到这种退化。
预训练阶段,其近邻以语义相关的中文人名为主——亚轩、祺、肖战、子怡、霆锋、杰伦等,虽然也混入了少量噪声 token,但整体聚类结构合理。
SFT 之后,近邻结构发生了明显恶化:尽管排名靠前的仍保留部分人名(亚轩、柏芝、无崖、千玺),但大量特殊 token 和噪声 token 涌入——
包括 </minimax:tool_call>、<edit_file>、<file_content>、<delete_file> 等 tool call 相关标记,以及 LENBQUMs、EFCFFF、flagathlete 等编码噪声。这些 id 在 200000 以上的特殊 token 与「嘉祺」的 lm_head 向量变得异常接近,说明后训练过程中该区域的向量空间已被挤压和污染。
既然问题的根源在于 lm_head 的变化,一个自然的延伸问题是:这种退化是否仅限于「嘉祺」?为此,我们对整个词表的 lm_head 向量计算了 SFT 前后的 L2 diff,并按变化幅度排序,系统性地检视了变化最大的 token 类别:
1. Special Tokens
2. 日文口语/网页模板(最大类别,约占 40%+)
がスタート、かもしれません、に息、を満喫、きちんと、そういった、ですと、などなど、といいでしょう、にチャレンジ、参考にしてみてください、気を付けて……
大量日文 SEO/博客常见表达,在预训练语料中有一定频率,但在 SFT 对话数据中占比极低,导致 lm_head 表征发生显著漂移。
3. LaTeX/网页元数据
makebox, mathbbm, boldmath, mathring, medskip, mathds, \footnotetext, {multiline}, {corollary}, {defn}
学术论文格式标记,SFT 对话数据中极少使用。
Weblinks, DEFAULTSORT, accessdate, commonscat, Commonscat, Reflist, Webarchive, Listaref, Collegamenti, interprogetto
维基百科源码模板标记,同样属于预训练特有的格式化 token。
4. 中文 SEO/垃圾文本
其中,special tokens 和 LaTeX/网页元数据的变化是合理的——这些 token 在预训练和后训练的阶段本身分布变化就会很大。但日文口语类 token 占据了变化最大类别的 40% 以上,这引起了我们的注意。
回顾此前收到的用户反馈,M2.5 在处理日文对话时偶尔会混入其他语言,这一现象曾被归类为「小语种语言混杂」问题,但一直未能明确根因。结合此次的分析,我们发现两个问题可能共享同一机制:后训练数据中日文 token 的覆盖严重不足,导致这些 token 的 lm_head 表征在 SFT 过程中发生漂移,与其他语言的 token 在向量空间中发生混淆——既可能导致日文 token 在不该出现时被错误激活(语言混杂),也可能导致与之空间相邻的低频中文 token(如「嘉祺」)被挤出正常的生成概率范围(token 遗忘)。这一发现将原本看似独立的两个问题统一到了同一个框架下,也为后续的修复方案提供了更清晰的方向。
基于上述分析,稀疏 token 遗忘的核心原因已较为明确:后训练数据对词表的覆盖不均匀,导致低频 token 的 lm_head 表征在 SFT 过程中发生漂移。而 input embedding 层的更新稀疏特性,让它仅仅丢失了生成能力而仍然保留理解能力。
针对这一问题,我们设计了一组以提升词表覆盖度为核心思路的修复实验。
在对照组(标准 SFT 数据)的基础上,额外混入一份覆盖全词表的合成重复数据,确保每个 token 在后训练阶段都能作为生成目标被充分训练。合成数据的构造方式如下:
将全量词表(200,064 tokens)随机划分为若干份,每份包含约 8,000 个 token
对每份 token 列表进行随机打乱(shuffle),构造一条对话样本:query 为打乱后的词列表加上指令「请重复以上内容」,answer 为原样复制(copy)
总计生成约 500 条对话,确保每个 token 至少作为 target 出现 20 次
这一设计的核心思想是:通过简单的复读任务,以极低的数据构造成本为全词表建立一个生成频率的「下限保障」,防止任何 token 在后训练过程中因完全缺失而发生 lm_head 退化。
为全面评估词表覆盖数据的效果,我们设计了以下几类测试,以实验组(+全词表覆盖数据)与 baseline 模型进行对比:
1. 小语种混淆率测试(核心指标,100 次采样,temperature=1.0):分别使用韩语和日语 prompt,统计输出中非目标语言字符的出现率。
2. 马嘉祺 case 定性验证(temperature=0):包括直接询问和引导性询问。
3. 群聊对比 case:复现此前在内部群聊中发现的 baseline 已知 failure case(如「无痛人流→人流」、「据介绍→介绍」、「地税→地利」等稀疏 token 替代现象),验证实验组是否修复。
4. lm_head 高退化 token 专项测试:选取 baseline 中 lm_head cosine similarity 变化最大的 token(cos_sim < 0.65),构造 prompt 引导模型生成包含该 token 的回答,检验是否能正确输出。
小语种混淆率测试
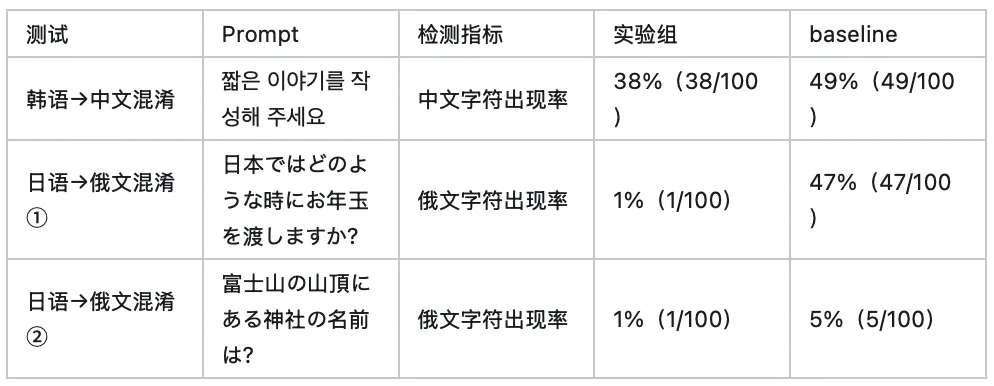
日语→俄文混淆从 baseline 的 47%/5% 大幅降至 1%,效果显著。韩语混淆率(38%)与对照组基线(30%)持平,说明韩语混淆的主因可能并非 token embedding 退化,而更多涉及训练数据中的中韩混杂样本,需要通过数据清洗等其他手段解决。
定性验证(temperature=0)
马嘉祺 case:

已知 failure case:
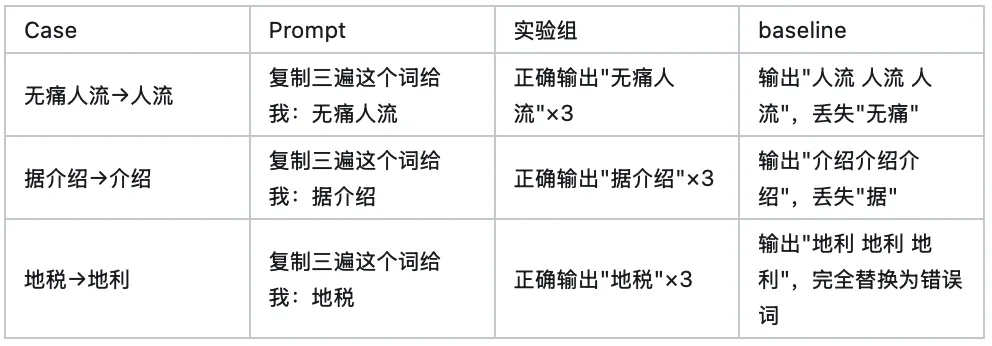
这三个 case 完美展示了 lm_head embedding 退化的生成端效果:模型能理解 prompt 的语义(知道要「复制三遍」),但由于对应 token 的 lm_head 向量已发生方向漂移,生成时被近义或近邻的错误 token 替代。实验组通过全词表覆盖数据完全修复了这些问题。
lm_head 高退化 token 专项(cos_sim < 0.65):
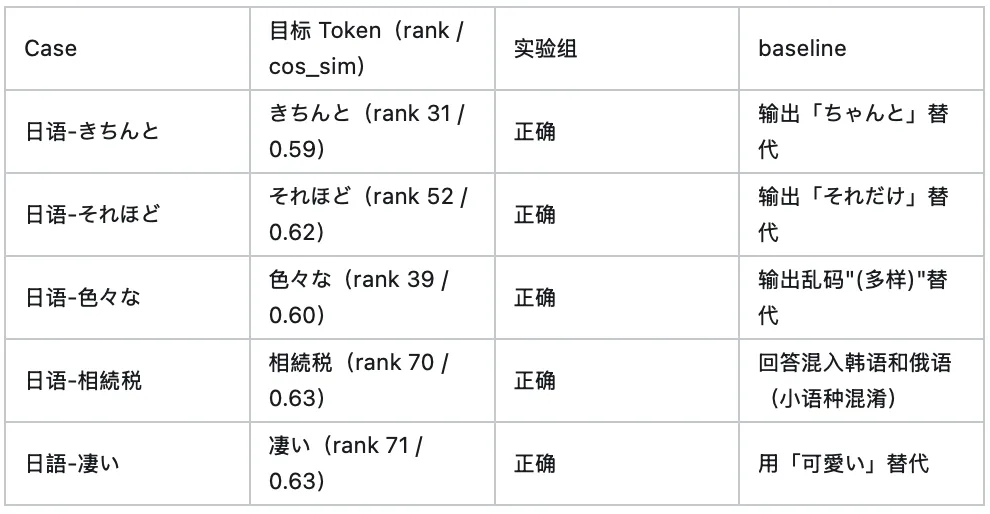
综合定性验证通过率:实验组 13/16,baseline 仅 4/16(排除 tokenizer 层面两边都失败的 case 后)。值得注意的是,baseline 在「相続税」 case 中直接混入了韩语和俄语文本,完美验证了 embedding 退化导致小语种混淆的因果链。
lm_head Cosine Similarity 定量分析
为量化验证全词表覆盖数据对 embedding 方向的保持效果,我们对比了实验组与 baseline 相对预训练 base 的 lm_head cosine similarity 变化:
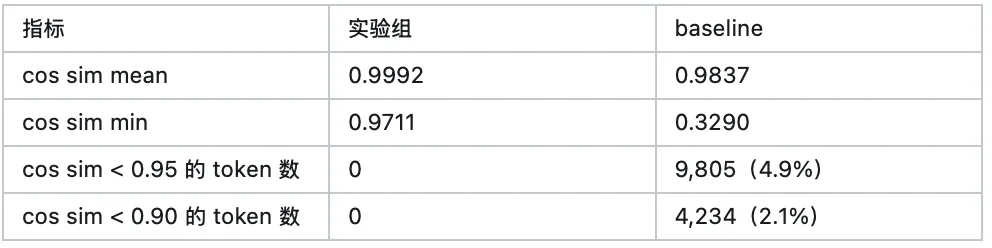
按语种进一步拆分:
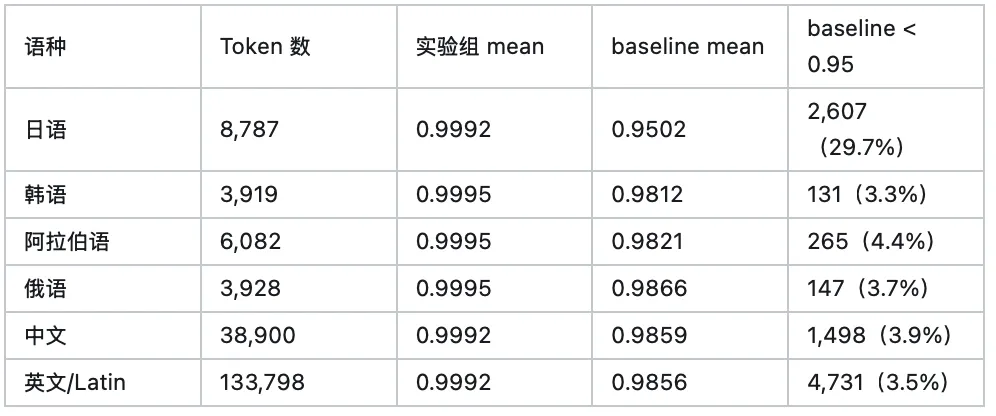
数据表明:实验组将所有语种的 lm_head mean cosine similarity 统一维持在 0.999 以上,全部 200K token 的 cos_sim 均高于 0.97,embedding 方向几乎完全保持。而 baseline 中日语 token 的退化尤其严重——mean cos_sim 仅为 0.9502,29.7% 的日语 token cos_sim 跌破 0.95,这与日语→俄文混淆率高达 47% 的现象高度吻合。
除词表覆盖合成数据外,还有几种值得进一步探索的策略:
混入预训练数据:在 SFT 数据中按一定比例混入预训练语料,利用预训练数据天然的词表覆盖广度来缓解稀疏 token 的退化。这一方法在已有研究中被证明对缓解灾难性遗忘有效,但需要仔细调控混入比例,避免影响 SFT 的对话能力。
针对低频 token 的定向合成:统计后训练数据中覆盖不足的 token,针对性地构造包含这些 token 的高质量对话样本。相较于全词表覆盖方案,这种方式数据量更小、更精准可以维持更精确的语义,但需要维护一套 token 覆盖度的监控机制。
词表裁剪 + CPT: 从根本上移除词表中在目标场景下极低频 token(如 SEO 垃圾词等),缩小词表规模后进行 CPT 以重新对齐 embedding 空间。这一方案改动较大,但能从源头消除稀疏 token 问题。
上述修复策略均作用于后训练阶段,本质上属于事后补救措施。若进一步追溯问题的根源,稀疏 token 退化现象实际上反映了 tokenizer 词表设计与下游使用场景之间的不匹配。
当前大语言模型的 tokenizer 通常基于大规模预训练语料,通过 BPE 等算法构建。即便在语料筛选阶段已排除低质量文本,所得词表中仍不可避免地包含很多仅在特定领域或语种中出现的低频 token。这些 token 在预训练阶段虽有机会获得一定程度的表征学习,但进入后训练阶段后,由于 SFT 数据的分布与预训练数据存在显著差异,导致对应的稀疏 token 参数发生显著变化——这本质上是一种由分布偏移引发的灾难性遗忘。
在预训练阶段,tokenizer 的词表构建应当纳入对后训练数据分布的前瞻性考量,通过调整词表规模或合并策略,减少在下游场景中几乎不会被激活的稀疏 token,从而实现词表设计与实际部署模型之间的更好对齐。
在后训练阶段,训练数据覆盖策略需同时兼顾两个维度:其一,从业务角度确保不同任务类型和领域的充分覆盖;其二,从底层统计角度持续监控词表中低频 token 的生成概率是否出现异常衰减。
另外有趣的是,Anthropic 在发布 Opus 4.7 时也明确声明其 tokenizer 经过了调整,并且新的 tokenizer 只会增加 token 不会减少,这基本说明是从之前的词表中删除掉了部分 token,而不是全新的 tokenizer。尽管无法确认其动机是否与上述问题直接相关,当然也可能涉及 OPD 策略或其他技术层面的改进,但这一变化至少表明,tokenizer 的词表设计依然存在着比较大的优化空间。



1. MiniMax 其实「认识」马嘉祺,只是「说不出来」。模型知道他的团体、经历等信息,说明知识没丢,但生成「嘉祺」这个 token 的能力在后训练里退化了;
2. 问题核心是:低频词被模型「遗忘」了。后训练数据里「嘉祺」出现不到 5 次,导致输出层(lm_head)发生漂移——模型脑子里还记得这个人,但嘴已经不会准确念出这个名字;
3. 这不只是一个明星名字 bug,而是暴露了大模型的底层问题:如果后训练数据覆盖不均,AI 会逐渐忘记冷门 token,甚至出现日语夹俄语、小语种混乱等现象。MiniMax 凭借「全词表复习训练」把这些问题一起解决。
📢你还遇到过让 AI 当场「卡壳」的情况吗?比如常识性错误、死活不认某个词、或者自信满满地胡说八道?评论区说出你的故事。

知乎 2026 新知青年大会正式官宣!
📍 北京 798 艺术区
📅 5 月 16 日–17 日
🎟 20+ 场活动,全部免费
👇点击链接即刻报名!座位有限,先到先得!
20+场免费活动,2026 新知青年大会 5 月 16 日见!
👇 不能来现场的朋友请预约直播
查看精彩线上内容!
点击【阅读原文】,查看更多精彩回答
题图来源:答主@mm 叶文洁
🔥热门文章
本文内容来自「知乎」
点击上方卡片关注
转载请联系原作者

