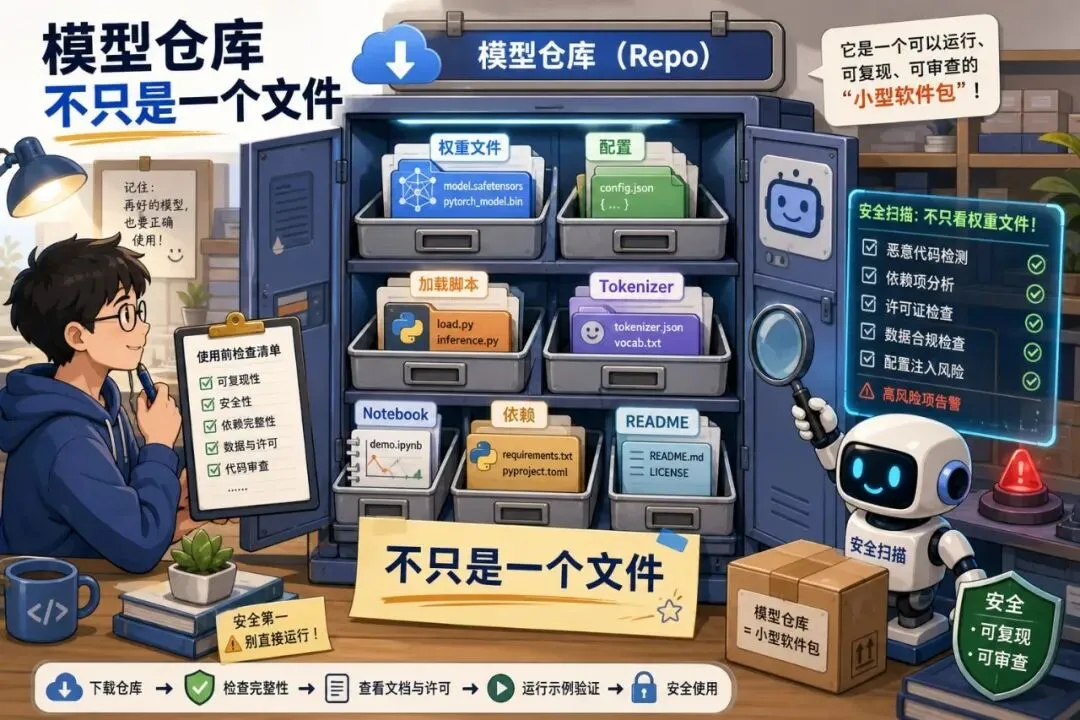
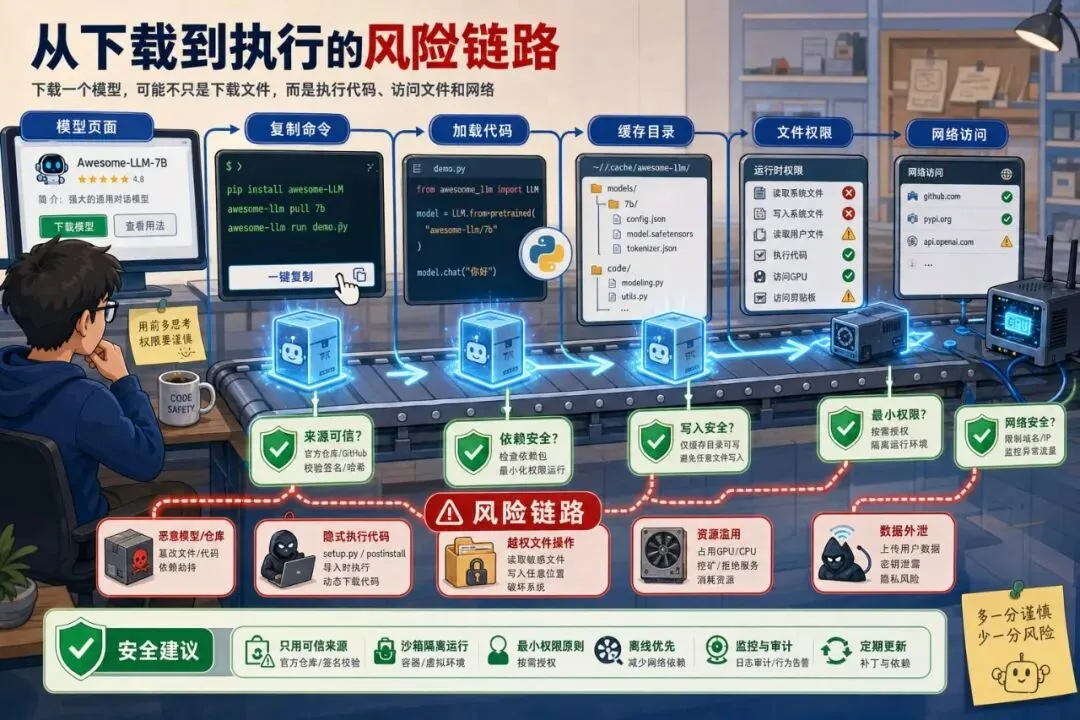
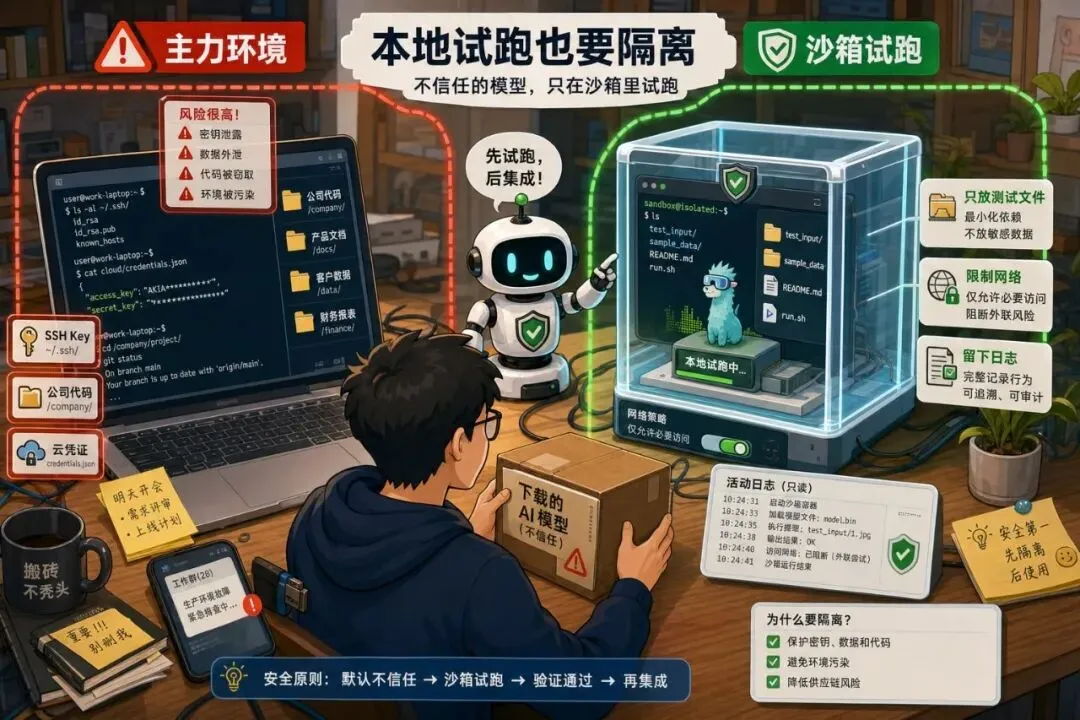
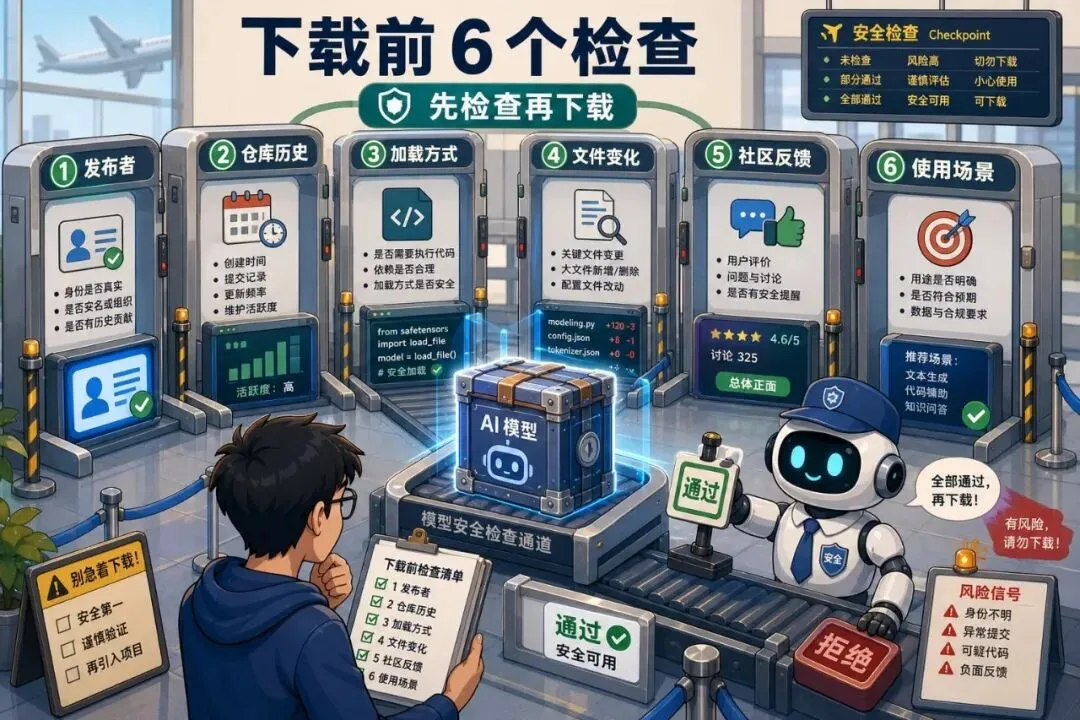
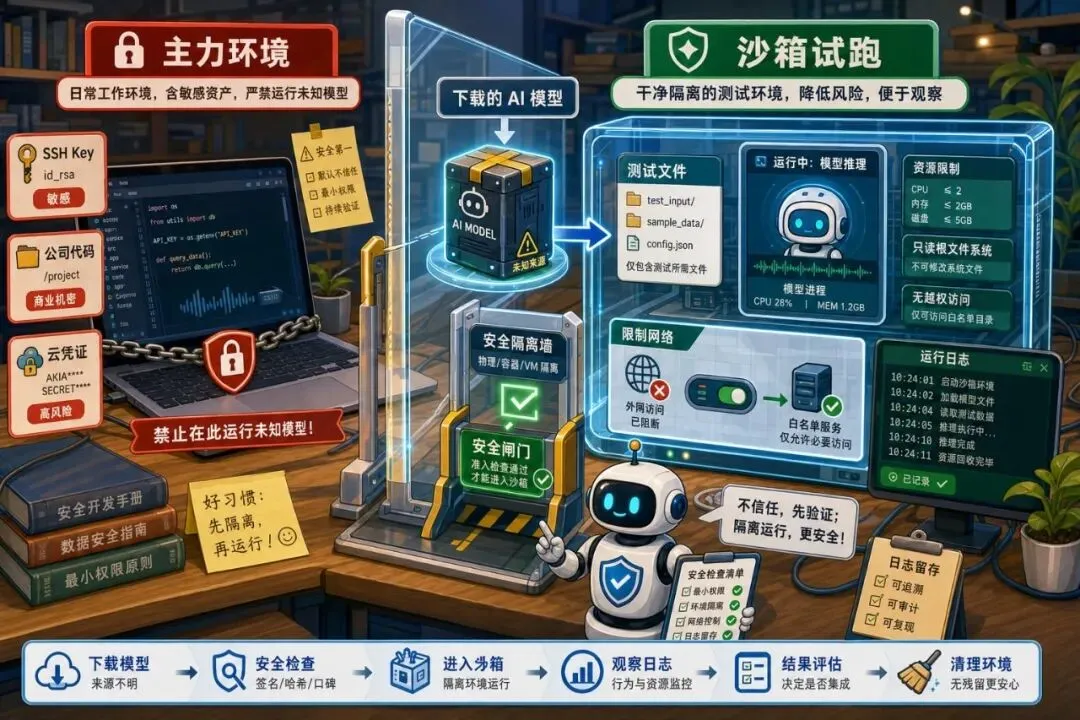
别再随手下载热门模型了:AI 时代的软件供应链风险变了以前我们提醒开发者:不要随便复制一段来路不明的命令。后来变成:不要随便安装 npm 包、pip 包、浏览器插件。现在,这句话还要再加一条:不要随便下载一个热门 AI 模型就跑。这听起来有点反直觉。模型不就是一堆权重文件吗?下载下来推理一下,最多输出胡话,怎么会变成安全问题?问题在于,今天的“模型”早就不只是一个静态文件。一个模型仓库里可能有 README、配置文件、加载脚本、推理代码、依赖声明、示例 notebook、量化文件、tokenizer、工具调用说明,甚至还有让你一键运行的命令。它越来越像一个小型软件包。而只要它像软件包,就会有供应链风险。最近,一个伪装成 OpenAI 发布的 Hugging Face 恶意模型仓库冲上趋势榜,并在下架前获得了大量下载。这件事最值得警惕的地方,不是“又有人造假”。而是它提醒我们:AI 时代的供应链入口,已经从代码包扩展到了模型仓库。为什么模型仓库会变危险很多人对模型文件的想象还停留在“下载一个大文件”。但真实使用流程往往不是这样。你会打开一个模型页面,看介绍、看 star、看下载量、看评论。然后复制作者给的安装命令。接着运行一段 Python 代码。如果模型需要自定义结构,你可能还会开启 trust_remote_code。如果教程写得很顺,你甚至会把它放进自己的脚本、服务或内部工具里。这条链路里,任何一个环节都可能被利用。恶意方不一定要攻破你的服务器。它只要让你相信“这是一个热门模型”“这是官方发布”“这是别人都在用的工具”,你就可能自己把它请进来。以前攻击者投毒的是依赖包。现在他们也可以投毒模型仓库。“热门”不等于可信这次事件里最容易让人后背发凉的一点,是它利用了人们对热度的信任。下载量高。趋势榜靠前。名字像官方。页面包装完整。这些信号在日常使用里很有用,但它们不是安全证明。一个仓库可以靠标题、关键词、社交传播、自动化下载、蹭热点,把自己快速推到很多人眼前。当开发者看到“大家都在下”,警惕心很容易下降。这和过去 npm、pip、Docker 镜像的风险很像。名字相似、拼写相近、冒充官方、蹭热门项目,都是老套路。只是这次披上了模型外衣。所以以后看到热门模型,第一反应不应该是“赶紧试试”。而应该先问:发布者是谁?是不是官方账号?仓库创建多久?有没有异常的加载代码?有没有让你执行奇怪命令?有没有第三方安全讨论?最危险的是“试一下”很多安全事故不是从生产环境开始的。而是从一句“我先本地试一下”开始的。试模型的时候,开发者常常会降低警惕。本地电脑里有 SSH key、云服务凭证、浏览器登录态、公司代码、历史命令、配置文件、笔记和数据集。如果你在这个环境里直接运行不熟悉的模型加载代码,风险并不小。更麻烦的是,AI 模型经常需要访问 GPU、文件系统、缓存目录和网络。为了“跑通”,很多人会给它更大的权限。一旦仓库里夹带恶意脚本,它拿到的就不只是一次推理机会。它可能看到你的环境变量、读你的文件、下载额外组件,或者在缓存目录里留下后门式的东西。这里不需要把细节讲得太吓人。只要记住一句话:模型试跑环境,不应该等同于你的日常开发环境。下载模型前,先做 6 个检查如果你今天要从 Hugging Face、GitHub 或教程链接里下载模型,可以先做一个很小的检查。01|看发布者身份。官方模型尽量从官方账号、组织账号或项目主页跳转进入,不要只靠搜索结果。02|看仓库历史。新建仓库突然冲榜、提交记录很少、作者信息模糊,都要多留心。03|看加载方式。如果需要开启远程代码执行、自定义加载脚本、复制一长串 shell 命令,要提高风险等级。04|看文件变化。除了权重文件,还要看 Python、配置、依赖、notebook、脚本。真正会出事的常常不是权重本身。05|看社区反馈。搜索仓库名、作者名、模型名,看有没有安全提醒、下架记录、冒充争议。06|看你的使用场景。只是读论文复现,和准备接入内部数据、客户文件、生产服务,风险级别完全不同。试跑时要把它关进笼子检查不是为了让你永远不下载模型。开源模型生态本来就很重要。问题是,试跑要有边界。比较稳的做法是:先用干净环境。不要在装满公司凭证和私有代码的主力电脑里直接跑。可以用临时容器、虚拟机、一次性云主机,或者至少使用单独用户和干净目录。再限制网络。很多模型第一次下载依赖可以联网,但真正试跑时不一定需要随便访问外网。能断就断,不能断也要知道它访问了哪里。然后限制文件。不要把整个工作目录挂进去。只给它需要的测试文件,不给 SSH key、浏览器目录、云配置和生产数据。最后留下日志。运行了什么命令,下载了哪些文件,访问了哪些域名,生成了哪些缓存,最好能回头看。这听起来麻烦。但比事后怀疑“我电脑是不是被动过”要轻松得多。上线前再问三个问题如果一个模型只是本地玩玩,风险还在可控范围内。但如果你准备把它接进产品、内部知识库、客服系统、代码助手或数据分析流程,就要再升级一次检查。第一,模型来源能不能被追溯?以后出了问题,团队要知道模型来自哪里、版本是多少、谁审核过、为什么选择它。第二,运行环境能不能被隔离?模型服务不要和核心数据库、密钥管理、内部办公系统混在一起。能读什么、能写什么、能访问什么,都要清楚。第三,更新机制能不能被控制?不要让生产服务自动拉取“最新模型”。最新不一定最安全。模型更新应该像依赖升级一样,有测试、有审批、有回滚。把模型当成依赖管理,听起来不酷。但这就是成熟工程和随手试玩的区别。最后AI 模型仓库变成供应链入口,并不意味着开源模型不可信。恰恰相反,开源模型会越来越重要。问题是,越重要的生态,越会吸引攻击者。过去几年,开发者已经学会了检查依赖包、锁版本、扫镜像、看许可证、做 CI 安全扫描。现在,这套习惯要扩展到模型世界。模型不是魔法文件。模型仓库也不是天然安全的下载站。它是代码、权重、配置、脚本、依赖和信任信号混在一起的新型软件包。以后看到一个很火的模型,不妨先慢半拍。别急着复制命令。先确认来源。先隔离环境。先看加载代码。先想清楚它能碰到哪些文件和数据。AI 时代会让我们下载更多模型、试更多工具、接更多自动化能力。速度会变快。但安全边界也要跟着变厚。能跑起来只是第一步。敢放心地跑,才是下一步。
 夜雨聆风
夜雨聆风