 夜雨聆风
夜雨聆风引言:AI 时代,数据存储的“新旧之争”
在人工智能浪潮席卷全球的今天,数据已成为驱动 AI 发展的核心燃料。然而,海量、多模态的 AI 数据对底层存储系统提出了前所未有的挑战:传统文件系统力不从心,对象存储虽具弹性却缺乏 POSIX 语义,性能也难以满足 GPU 饥渴的 I/O 需求。
近期,AWS 推出了 S3 Files,声称能让 S3 桶像文件系统一样被访问,似乎为 AI 开发者带来了福音。本文将深入剖析 S3 Files 的技术本质,将其与专为高性能 AI 场景设计的分布式缓存系统 Curvine 对比。
一、S3 Files 的架构:基于 EFS 的文件语义
S3 Files 的核心思想是为 S3 提供文件语义兼容性,但其实现方式会对性能有所影响。它并非原生构建,而是通过在 S3 前端“联合”了 Amazon EFS(Elastic File System)来实现的。这意味着,您的数据访问路径是:
客户端 → NFS 协议 → Amazon EFS (作为缓存/网关) → 后台异步同步 → S3 Bucket
这种多层间接的架构,从一开始就埋下了性能和复杂性的隐患。
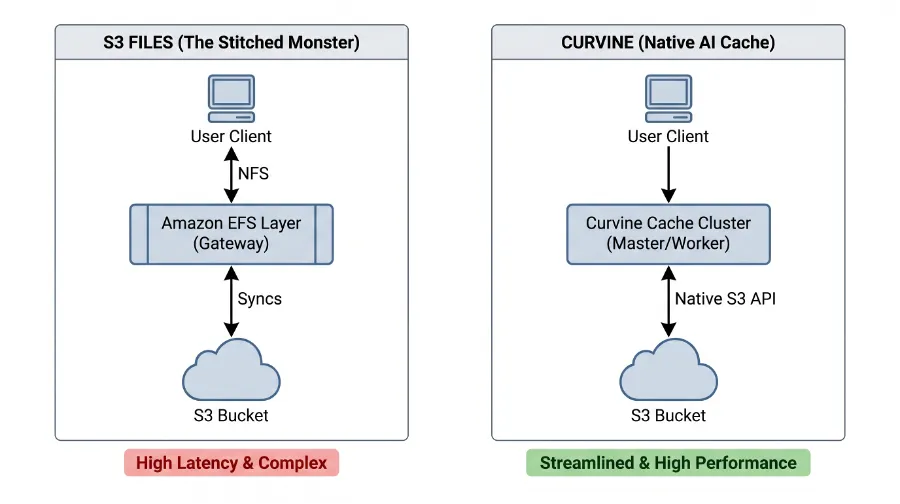
技术解读:
• NFS 协议的限制:NFS 本身是为传统文件系统设计,其单连接吞吐量有限,且元数据操作通常需要经过中心化服务器。当大量 AI 训练任务并发访问时,NFS 协议的瓶颈会迅速显现。 • EFS 的中间层开销:EFS 作为中间缓存层,虽然提供了一定的性能缓冲,但其自身的延迟和管理开销依然存在。数据需要先写入 EFS,再异步同步到 S3,这引入了额外的一致性延迟和数据路径复杂性。 • S3 的最终一致性:S3 本身是最终一致性模型,而 EFS 试图在其上提供强一致性。这种“强行兼容”往往意味着复杂的内部机制和潜在的性能折衷。
相比之下,Curvine 采用全分布式客户端架构,直接通过原生 S3 API 与对象存储交互,链路更短,性能更优,且避免了中间层的复杂性。
二、写放大:大文件随机写
AI 训练中,对大型模型文件或数据集进行随机写入(如模型参数更新、Checkpoint 保存)是常见操作。然而,S3 Files 在此场景下表现堪忧,其根源在于 S3 对象存储的特性。
S3 对象是不可变的。当您修改 S3 Files 中的一个大文件时,即使只修改了其中一小部分,S3 Files 也可能需要将整个文件作为一个新对象重新上传到 S3。这就是所谓的“写放大”(Write Amplification)。
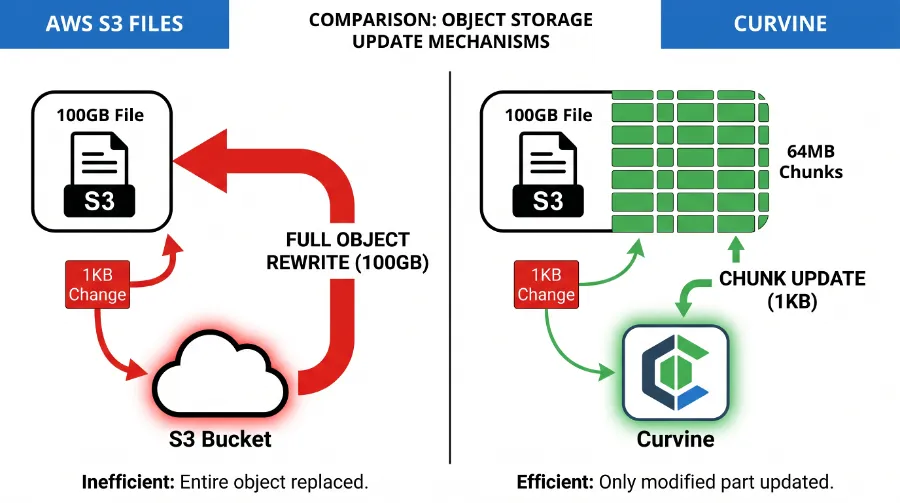
技术解读:
• S3 Files 的 1:1 对象映射:S3 Files 倾向于将文件直接映射为 S3 对象。当文件发生随机修改时,由于 S3 对象的不可变性,系统不得不读取整个旧对象,修改部分内容,然后作为一个新对象重新写入 S3。这导致了巨大的 I/O 浪费和延迟。 • Curvine 的分块写入与增量同步:Curvine 针对 AI 场景进行了优化。它将大文件智能地切分为更小的块进行管理。当文件发生随机修改时,Curvine 只需更新受影响的数据块,并进行增量同步,大大减少了实际写入 S3 的数据量,从而有效避免了写放大。
三、POSIX 兼容性:文件语义对比
对于习惯了本地文件系统语义的 AI 开发者而言,POSIX 兼容性至关重要。它确保了现有工具链、脚本和框架无需修改即可运行。然而,S3 Files 在 POSIX 兼容性上存在限制。

技术解读:
• S3 Files 的缺失:S3 Files 无法完全支持硬链接 (Hard Links)、原子级重命名 (Atomic Rename)、扩展属性 (xattrs) 等关键 POSIX 语义。这些缺失在复杂的 AI 工作流中可能导致意想不到的错误,甚至数据不一致。 ◦ 硬链接:在数据集管理中常用于版本控制或数据去重,S3 Files 不支持会增加数据冗余或管理复杂性。 ◦ 原子重命名:对于确保文件操作的原子性至关重要,尤其是在多进程并发写入场景下,S3 Files 的非原子重命名可能导致数据损坏或不一致。 ◦ 扩展属性:常用于存储文件的额外元数据,S3 Files 的不支持限制了其在某些高级应用中的灵活性。 • Curvine 的原生 POSIX:Curvine 从设计之初就致力于提供完整的 POSIX 兼容性。它通过精巧的元数据管理和数据组织方式,确保了所有标准 POSIX 语义的正确实现。这意味着,您的 AI 框架可以无缝迁移到 Curvine,无需担心兼容性问题。
四、性能天花板:被协议限制的 S3 Files
AI 训练对数据吞吐量和延迟有着极高的要求,尤其是大规模分布式训练场景。S3 Files 的架构决定了其性能存在难以逾越的天花板。
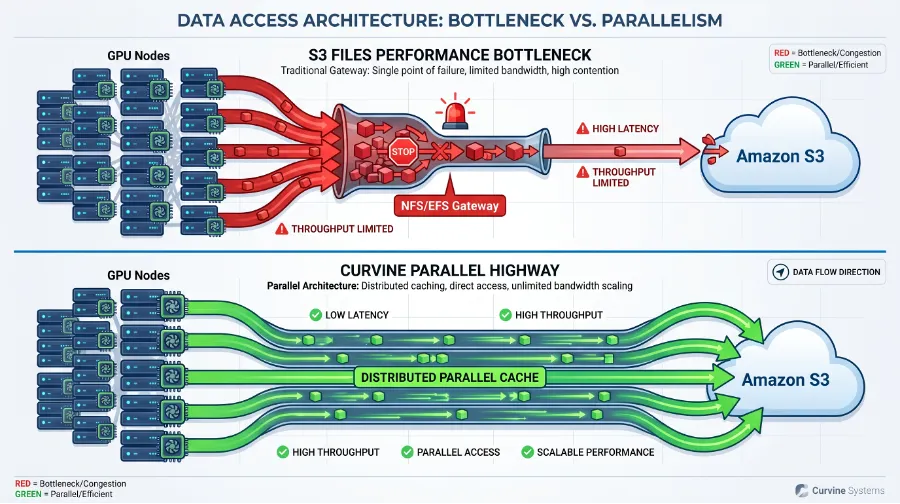
技术解读:
• NFS 协议的性能限制:S3 Files 依赖 NFS 协议进行客户端访问。NFS 协议的特性决定了其在处理大量并发小文件请求或高吞吐量需求时,容易出现瓶颈。所有的元数据操作和部分数据流都可能经过中心化的 EFS 网关,形成单点瓶颈。 • 中心化元数据瓶颈:EFS 作为 S3 Files 的元数据管理层,其自身的扩展性和性能会直接影响整个系统的表现。在大规模 AI 训练中,元数据操作(如文件查找、目录遍历)的频率极高,中心化元数据服务很容易成为性能瓶颈。 • Curvine 的全分布式并行架构:Curvine 采用完全去中心化的分布式架构。客户端直接与 Curvine 缓存集群交互,数据和元数据访问均可并行化。其元数据管理基于 Raft 协议,确保高可用和强一致性,同时避免了中心化瓶颈。性能可以随计算节点规模线性扩展,真正释放对象存储的吞吐潜力。
五、成本对比:复杂 vs 透明
云服务成本是企业关注的焦点。S3 Files 表面上利用了 S3 的低存储成本,但其隐藏的“管理溢价”和复杂的计费模式,可能让您的账单超出预期。
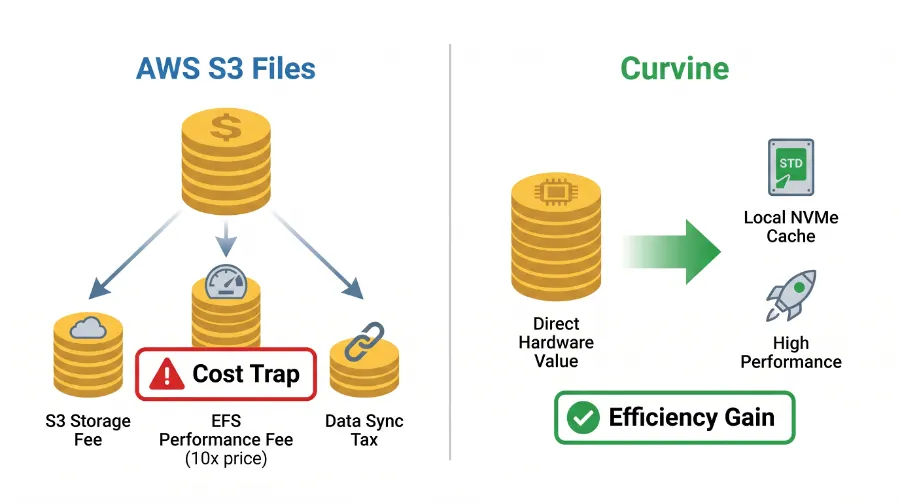
技术解读:
• S3 Files 的多重计费:使用 S3 Files,您需要为以下多项服务付费: 这种复杂的计费模式,使得成本预测困难,且容易产生高昂的“管理溢价”。
◦ EFS 存储费用:EFS 作为中间缓存层,其存储本身就需要付费。 ◦ EFS 吞吐量费用:EFS 的数据吞吐量是按量计费的。 ◦ S3 存储费用:底层 S3 存储的费用。 ◦ S3 请求费用:S3 的 GET/PUT/LIST 等请求是按次计费的。由于写放大等问题,S3 Files 可能会产生远超预期的 S3 请求量。 ◦ 数据传输费用:EFS 与 S3 之间的数据传输,以及 EFS 与计算实例之间的数据传输都可能产生费用。 • Curvine 的透明成本模型:Curvine 部署在您的计算集群内部或边缘,利用本地存储作为高性能缓存。它通过高效的缓存命中率和智能的数据管理,大幅减少了对 S3 的频繁访问和数据传输量。这意味着,您的主要成本将集中在计算资源和底层 S3 存储本身,成本模型更加透明和可控,每一分钱都真正花在了性能提升上。
总结:选择真正懂 AI 的存储
AWS S3 Files 试图通过结合现有服务来解决 S3 的文件系统访问问题,但其架构上的固有缺陷,导致了写放大、性能瓶颈、POSIX 兼容性残缺以及高昂的隐性成本。它更像是一个为通用文件访问场景设计的“妥协方案”,而非为 AI 时代高性能、大规模数据处理量身定制的解决方案。
Curvine 则从 AI 负载的真实需求出发,通过全分布式、原生 POSIX 兼容、智能缓存和优化的 I/O 路径,彻底释放了对象存储的潜力。它不仅提供了极致的性能,更带来了成本效益和架构的简洁性,是您构建下一代 AI 应用的理想选择。
立即行动
👉 了解更多 Curvine 技术细节:https://github.com/CurvineIO/curvine
