当前时间: 2026-06-20 16:05:01
分类:办公文件
评论(0)
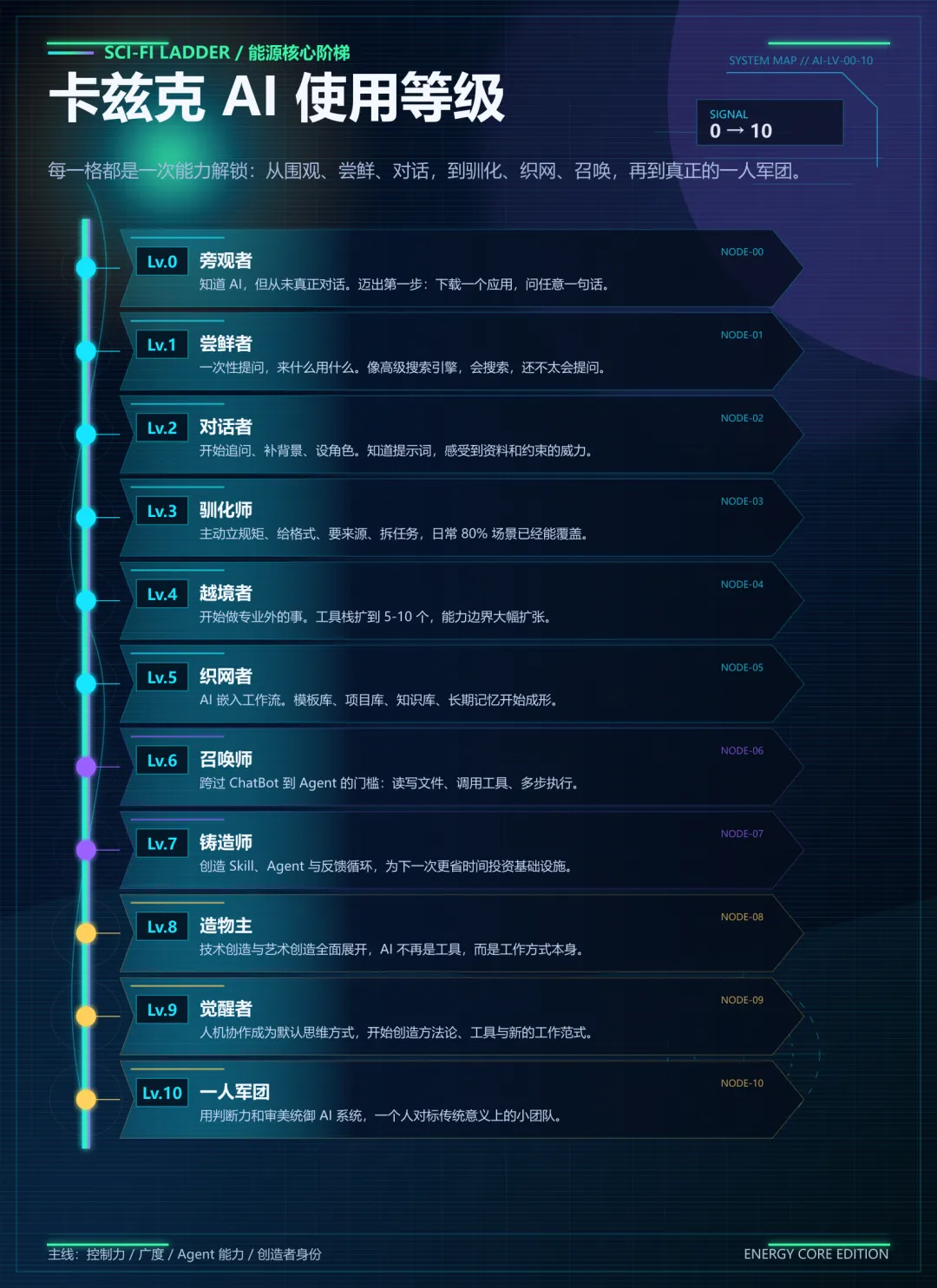
你在AI使用水平等级的哪一级?最近看到卡兹克整理了一套AI使用水平等级,挺有意思的。从可控性、广度、形态、角色四个维度,把不同阶段的AI使用者分了个层,从Lv.0到Lv.10。我看完之后自己评估了下,目前应该在lv4~lv5这个阶段,偶尔会做一些lv6和lv7的任务,比如创建skill,用agent来调用工具等。当然,这套等级不是什么权威标准,卡兹克是根据他长期观察大量AI使用者之后主观整理出来的框架。我先快速过一遍这套等级,你可以边看边想想自己在哪一层。- Lv.0 旁观者。知道AI,但从来没跟任何大模型对过话。
- Lv.1 尝鲜者。开始用了,但基本是「帮我写个XX」然后等结果。AI给什么就用什么,好不好全靠运气。
- Lv.2 对话者。开始意识到「怎么问」比「问什么」重要。会追问,会补背景,会让AI扮演某个角色。
- Lv.3 驯化师。开始给AI立规矩了。「不知道就说不知道」「按这个格式输出」「不确定的标注推测」。会拆任务,会上传文件,会用记忆,会自定义指令。
到这一层,大量觉得自己AI用得不错的人,其实都在这里。- Lv.4 越境者。开始用AI做自己专业以外的事。市场人写Python脚本,程序员写商业方案,老师用AI做海报。能力边界第一次大幅扩张。
- Lv.5 织网者。AI不再是偶尔求助的对象,而是被嵌入日常工作流。有固定的Prompt、固定的模板、固定的项目规则,开始搭知识库、做长期记忆、设计自己和AI的协作方式。
再往上还有Lv.6到Lv.10,从Agent到自己造Skill,到一个人干一个团队的活。但今天不聊那么远。因为你已经会写Prompt了。你会上传文件,会让AI改几版,会让它按格式输出,会要求它给来源,会知道不同模型适合不同任务。Lv.3的人常问的是,「我该怎么问,AI才能答得更好?」Lv.5的人问的是,「这个任务应该被拆成几步?每一步输入什么,输出什么?验收标准是什么?哪些交给AI,哪些必须我自己判断?」很多人给AI的指令就是「帮我写一篇文章」「帮我做个方案」「帮我分析一下这个文件」。但他没有定义这篇文章写给谁看,多长,什么风格,什么算写好了。没有开工条件,没有完成标准,也没有收尾流程。AI是放大器。这句话卡兹克反复在讲,我自己用下来也觉得是这样。你有判断力,它放大判断力。你有一套流程,它放大流程。你只有一个模糊的愿望,它就放大模糊。如果你自己都不清楚做这件事的步骤是什么,AI也只能给你一个平均化的、模板化的、看起来正确的答案。如果你自己都说不清楚什么叫「好」,AI就只能给你一个它猜测的好。写文章,什么叫好?是标题点击欲望更强,还是逻辑更清楚,还是更像你本人的风格?你不说清楚,AI怎么知道?结果就是,你每次拿到AI的产出,靠感觉判断「还行吧」,然后就用了。上午让AI帮你做了一堆事,下午开一个新对话,AI完全不知道上午做到哪了。它只能重新探索,重新摸索,重新犯你上午已经帮它纠正过的错。每一次新对话都是一次记忆清零。你以为你在积累,其实你在反复重启。所以从Lv.3到Lv.5,跨越的不是从短Prompt到长Prompt。说实话,我写这篇文章的底气不是「我已经到了Lv.5」,而是「我正在从Lv.3往Lv.5走,我能感受到这中间的差距到底在哪」。我运营这个公众号,用AI帮我做内容。最开始的时候,我的用法跟大多数人一样。每次开一个新对话,跟AI说「帮我写一篇关于XX的文章」,然后等它给我一版,我看看觉得还行就自己润色下,觉得不行就自己重新弄。效果很不稳定。有时候出来的东西还可以,有时候AI味重得我自己都读不下去。我当时以为问题出在Prompt上,花了不少时间研究怎么写更好的提示词。问题在于我每次都在从零开始。AI不知道我之前写过什么,不知道我的读者是谁,不知道我的风格是什么,不知道哪些坑我已经踩过了。每次对话都像是跟一个新来的实习生重新交代一遍所有背景。我做的第一件事,是给AI写了一个核心记忆文件。每次新对话开始,AI先读这个文件,就能立刻知道这个项目是什么、我是谁、当前进展到哪了、接下来该做什么。然后我在下面建了几个专项记忆,追踪每篇文章走到了哪个阶段的流水线状态,定义了标题怎么写、正文什么节奏的写作风格手册,记录每次踩坑教训的决策日志。效果是明显的。AI不再每次从零开始猜了。它知道我要什么风格,知道哪些词不要用,知道上一篇文章卡在哪个环节。我省掉了大量重复交代背景的时间,质量的稳定性也上来了。- 最大的缺口是验证。文章写完之后,我没有一个结构化的检查流程。没有一个清单告诉我,这篇文章的标题是否符合风格手册的标准,正文有没有「只有我能说」的内容,字数是不是在合理区间。现在的验证全靠我自己看一遍的感觉,而感觉这个东西,时好时坏。
- 另一个缺口是任务规范。每篇文章开工之前,我没有一个标准化的定义来明确这篇文章到底要达成什么目标、完成标准是什么。这导致写到一半经常会偏,或者写完了不确定到底算不算好。
- 还有一个缺口是状态驱动。我的流水线状态文件确实在追踪每篇文章的进度,但说实话有些任务挂在「进行中」已经两周了,状态文件只记录了带完成状态,但其实我已经自己改完了,但是AI不知道,没有及时拉通。
它是一层一层补齐的过程。先把记忆搭起来,让AI不用每次从零开始。再把规则定好,让AI知道什么叫「好」。然后补验证,让「完成」不再靠感觉。最后让状态真正驱动行动,而不只是被记录。我现在大概在这条路的中间。记忆和规则搭了,验证和驱动还在补。卡兹克在讲这套等级的时候说了一句话,我觉得直接说出了不同人使用AI效果大相径庭的原因。「真正的AI高手,不是更会聊天,而是更会给AI留工作痕迹。」聊天记录会消失,但你写下来的规则、标准、状态、流程不会。它们是你和AI之间真正的积累。大多数人用AI,是每次开一个新对话,问一个问题,拿一个答案,然后关掉。而从Lv.3往上走的人,开始把每一次跟AI的协作,变成可以被下一次继续的东西。这个转变听起来不性感,但它可能是普通人在AI时代能做的最有杠杆的一件事。我自己还在路上,下一篇打算写写怎么从零开始搭自己的AI工作系统。如果你也在想这件事,可以关注一下,我们一起走。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
基本
文件
流程
错误
SQL
调试
- 请求信息 : 2026-06-27 06:43:25 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/617727.html
- 运行时间 : 0.310125s [ 吞吐率:3.22req/s ] 内存消耗:4,692.45kb 文件加载:145
- 缓存信息 : 0 reads,0 writes
- 会话信息 : SESSION_ID=7a82e3135500ecb5b6e1f05b0dac826b
- CONNECT:[ UseTime:0.000616s ] mysql:host=127.0.0.1;port=3306;dbname=wenku;charset=utf8mb4
- SHOW FULL COLUMNS FROM `fenlei` [ RunTime:0.000856s ]
- SELECT * FROM `fenlei` WHERE `fid` = 0 [ RunTime:0.030960s ]
- SELECT * FROM `fenlei` WHERE `fid` = 63 [ RunTime:0.003983s ]
- SHOW FULL COLUMNS FROM `set` [ RunTime:0.000779s ]
- SELECT * FROM `set` [ RunTime:0.000239s ]
- SHOW FULL COLUMNS FROM `article` [ RunTime:0.000689s ]
- SELECT * FROM `article` WHERE `id` = 617727 LIMIT 1 [ RunTime:0.000544s ]
- UPDATE `article` SET `lasttime` = 1782513805 WHERE `id` = 617727 [ RunTime:0.040747s ]
- SELECT * FROM `fenlei` WHERE `id` = 64 LIMIT 1 [ RunTime:0.006921s ]
- SELECT * FROM `article` WHERE `id` < 617727 ORDER BY `id` DESC LIMIT 1 [ RunTime:0.006231s ]
- SELECT * FROM `article` WHERE `id` > 617727 ORDER BY `id` ASC LIMIT 1 [ RunTime:0.001731s ]
- SELECT * FROM `article` WHERE `id` < 617727 ORDER BY `id` DESC LIMIT 10 [ RunTime:0.000870s ]
- SELECT * FROM `article` WHERE `id` < 617727 ORDER BY `id` DESC LIMIT 10,10 [ RunTime:0.039465s ]
- SELECT * FROM `article` WHERE `id` < 617727 ORDER BY `id` DESC LIMIT 20,10 [ RunTime:0.004474s ]

0.311870s

 夜雨聆风
夜雨聆风