 夜雨聆风
夜雨聆风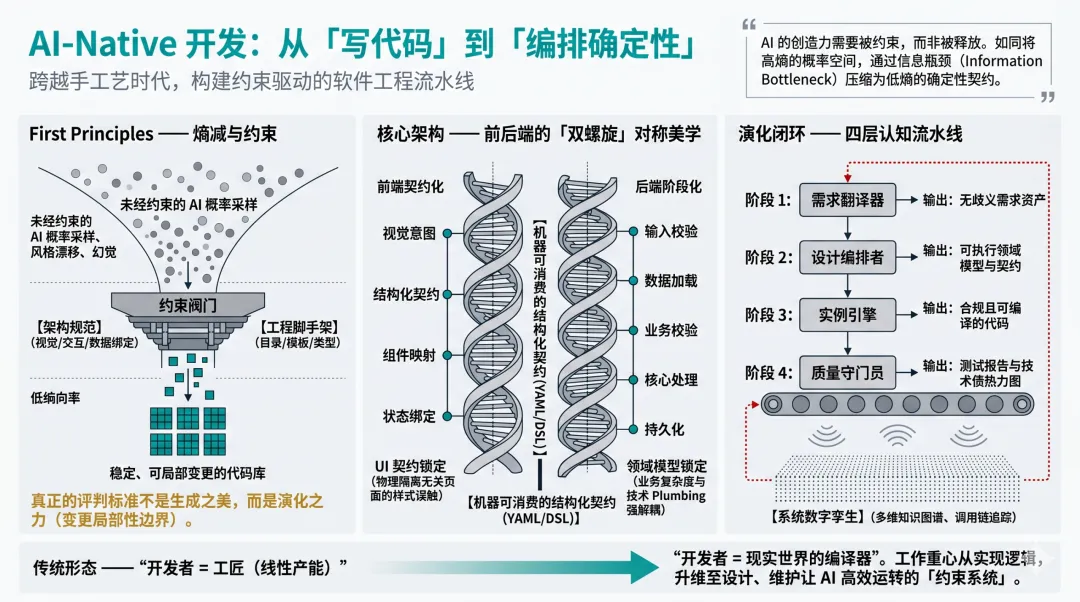
不是让 AI 取代创造力,而是让架构智慧为 AI 划定轨道
技术思考 · 架构演进 · 范式跃迁
过去三十年,软件工程的核心命题是「如何让人更高效地写代码」。但今天,这个命题本身正在失效。
当一位技术负责人在上午提出业务需求,傍晚前便完成了前后端架构搭建、数据模型设计和可运行原型时,我们面对的不再是效率提升百分之几十的渐进改良,而是生产关系的根本重构。
AI-Native 开发不是「用 AI 辅助写代码」——那是旧思维在新工具上的投影。真正的 AI-Native,是将软件工程从「手工艺时代」推进到「工业化编排时代」。
核心洞察
AI 的创造力需要被约束,而非被释放。给 AI 的自由度越多,它的输出越平庸;给 AI 的约束越清晰,它的产出越卓越。
🎯真正的标尺:演化之力,而非生成之美
衡量 AI-Native 成败的标尺,从来不是「AI 一次生成的代码有多漂亮」。一个能写出优雅排序算法的 AI,在真实业务场景中价值有限。
真正的分水岭在于:当需求发生变更时,AI 生成的代码架构能否支持极小范围、稳定且可预测的局部修改,而不是触发不可控的整体重构。
这是区分「AI 编程玩具」与「AI-Native 工程体系」的试金石:
- 前者
追求一次性炫技——看,AI 十分钟写了一个完整的 CRM 系统! - 后者
追求持续演化能力——三个月后业务规则调整,AI 能在十五分钟内精准定位到两个领域方法和一个前端组件完成修改,其余代码纹丝不动。
传统 AI 辅助编程难以进入生产核心,正是因为它缺乏这种「变更隔离机制」。生成的代码耦合度、内聚性、边界清晰度完全不可控,一旦需求微调,AI 往往倾向于「推倒重来」或「补丁叠加」,架构在数次迭代后迅速腐化。
工程底气
规范和脚手架的本质作用,是为 AI 建立「变更的局部性边界」。当目录结构、组件职责、数据流向、领域分层都被架构契约锁定时,AI 的修改被物理隔离在可控范围内。
⚡熵减工程:把 AI 锁进低熵容器
未经约束的软件系统必然经历熵增:代码风格漂移、架构边界侵蚀、业务规则散落各处。传统工程用 Code Review 对抗,本质是用更高成本的人类注意力抵消自然退化。
而大语言模型基于概率采样,天然是高熵的。给它模糊需求,它会在全网知识里天马行空——引入不存在的组件库,采用冲突的状态管理,生成违背业务规则的逻辑。
AI-Native 的第一性原理,是「将 AI 锁定在一个极低熵的生成空间内」。这需要两个基础设施:
📐 架构规范
将视觉风格、布局模式、交互约定、数据绑定规则结构化为机器可消费的「知识资产」。AI 不再是自由创作,而是「在既定轨道上开车」。
🏗️ 工程脚手架
将目录划分、代码模板、类型定义、错误处理固化成不可违背的「物理边界」。AI 的生成行为从「概率采样」转化为「约束满足」。
🧬对称美学:前后端的「双螺旋」
真正成熟的 AI-Native 体系,前后端呈现惊人的对称性。而这种对称性的终极目的,正是实现「变更局部性」。
后端:六段式骨架
将业务操作强制拆解为确定性阶段:输入校验 → 数据加载 → 业务校验 → 业务处理 → 持久化 → 异步通知。技术 plumbing 由框架统一处理,AI 只在 sandbox 内填充规则。
但 sandbox 并非万能保险箱。领域模型定义了聚合根、实体与不变量,这些才是嵌在业务层内部的「微型轨道」。骨架负责横向阶段隔离,领域模型负责纵向边界锁定,两者交织成三维约束网格。
工程价值:当业务规则变更时,AI 的修改范围被严格锁定在第 3 或第 4 步的特定方法内,不会波及数据访问层,更不会穿透到前端契约。
前端:结构化契约
革命性转变是从「视觉意图」到「结构化契约」。AI-Native 的前端输入是机器可读的 UI 契约:字段类型、校验规则、组件映射、显隐条件、API 绑定。
变更隔离:当 UI 契约明确规定了组件树与数据流向,AI 响应「第三步增加一个字段」时,修改范围被自动限制在契约声明、组件映射和校验规则内。它不会重写整个 Wizard 流程,不会误触无关页面样式。
| 架构容器 | ||
| AI 自由度 | ||
| 变更响应 |
🤖四层智能体流水线
AI-Native 不是「一个超级 AI 包办一切」,而是多个专业化智能体组成的「认知流水线」。四层之间流转的不是自然语言,而是结构化的架构契约(YAML/JSON/DSL 形式的约束规则集)。
① 需求翻译器
接收业务输入,识别目标、拆解故事、拒绝违背原则的需求,输出无歧义的结构化需求资产。
② 设计编排者
执行实体识别、状态机建模、接口契约设计,输出可执行的领域模型与数据契约。
③ 代码实例化引擎
基于设计资产与架构容器,生成可编译、可运行的代码——用设计资产实例化架构容器。
④ 质量守门员
基于需求资产自动生成测试用例,执行回归测试,输出质量报告。
本质区别:AI-Native 是「契约驱动的精确演化」——AI 接收契约的 diff,在既定轨道内完成最小范围的代码 diff;传统 AI 辅助编程是「提示词驱动的模糊重写」。
👥组织重构:从工匠到编排者
传统团队中,开发者是工匠:掌握手艺,通过个人技艺将需求转化为代码,团队规模与产能线性相关。
AI-Native 团队中,开发者是「架构编排者」:核心工作是设计并维护「让 AI 高效运转的约束系统」——骨架演进、规范迭代、契约模板化、智能体指令调优。
审批疲劳是真实挑战。当 AI 在分钟级内产生大量变更时,人类认知带宽成为新瓶颈。应对策略是「分层自治」:
- L0 自治
补全测试、格式化代码 —— AI 自主合入 - L1 审批
新增业务规则 —— 快速扫描 - L2 审批
核心领域逻辑、分布式事务 —— 架构师深度审查
从工程实践看,AI-Native 呈现「团队规模收敛」曲线:第一年基础设施投资期;第二年 AI 生成采纳率超 70%,进入高杠杆期;第三年 22 人团队可收敛为 10 人「编排者团队」,直接写代码比例低于 20%。
🔧被忽视的战场:维护与演化
软件工程 80% 的成本发生在首次上线之后。遗产系统充斥着没有文档却运行良好的暗逻辑。AI 如何获取这些上下文?
数字孪生:通过静态分析、运行时追踪、变更历史挖掘,将既有系统的结构、行为、经验提取为多维知识图谱。当 AI 修改既有代码时,在数字孪生的指引下导航,遵循最小破坏原则。
变更影响分析:智能体追踪调用链、识别关联聚合根、标记破坏性变更,输出《变更影响报告》供人类审批参考。
技术债 AI-可识别化:将代码坏味道的定义结构化,嵌入质量守门员,使其主动扫描(包括 AI 自己过去生成的代码)中的技术债,生成热力图。让技术治理从「年终大扫除」变为「日常保洁」。
衡量 AI-Native 成熟度的标尺,不是看它一次性能生成多漂亮的代码,而是看它在需求变更时,能否以极小范围、稳定且可预测的方式完成演化。
一次性的代码生成是表演,面向变更的架构才是工程。
现实世界的编译器,正在诞生。
