 夜雨聆风
夜雨聆风【导读】Google DeepMind 18 人团队发布论文《AI Co-Mathematician》,推出面向数学家的智能体研究工作台。该系统在 FrontierMath Tier 4 基准测试上拿下 48% 得分,刷新所有已评估 AI 系统的最高纪录。更值得关注的是,这套系统覆盖从构思、文献检索到定理证明的完整研究流程,早期测试中已帮助研究者攻克开放问题、发现新研究方向。
48%:一个安静登场的新纪录
5 月 7 日,一篇 22 页的论文出现在 arXiv 上。
标题:《AI Co-Mathematician: Accelerating Mathematicians with Agentic AI》。作者 18 人,全部来自 Google DeepMind。
论文摘要里藏着一个关键数字:FrontierMath Tier 4 得分 48%,所有已评估 AI 系统中的最高分。
原文表述:
"the AI co-mathematician also achieves state of the art results on hard problem-solving benchmarks, including scoring 48% on FrontierMath Tier 4, a new high score among all AI systems evaluated"
「AI 协作数学家在高难度问题求解基准上取得了最先进成绩,包括在 FrontierMath Tier 4 上得分 48%,刷新了所有已评估 AI 系统的最高纪录。」
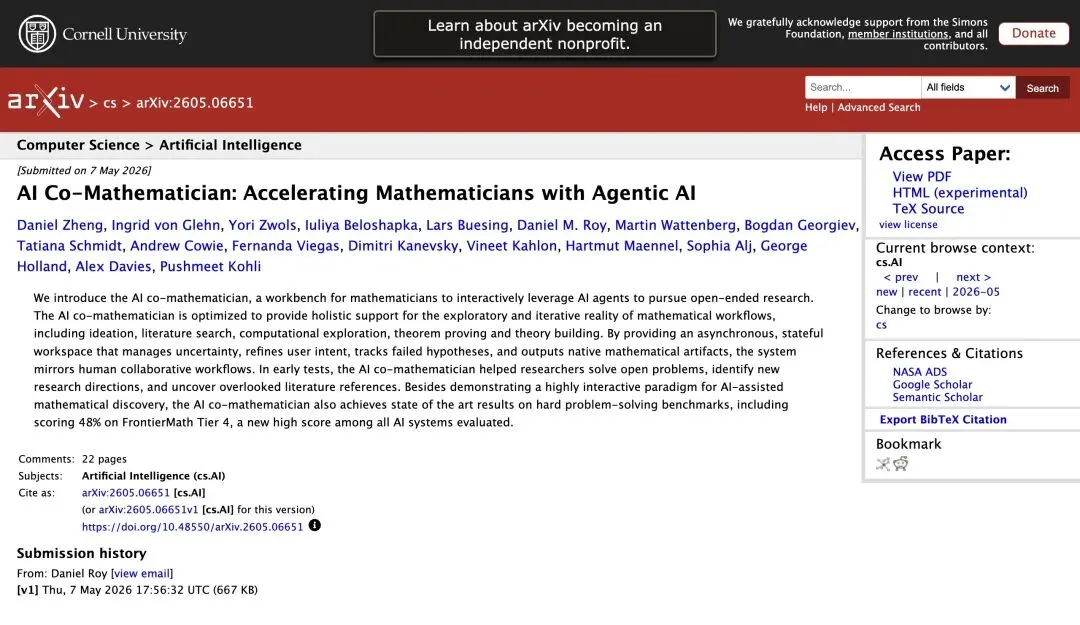
▲ arXiv 上的论文摘要页,18 位作者均来自 Google DeepMind
有一点需要交代:FrontierMath 作为基准测试目前仍处于早期阶段。其官网 FrontierMath.org 至今仍显示"Launching Soon"。Tier 4 的具体题目数量、难度定义和其他系统的对比分数,在公开资料中尚不可查。
但论文声称的"所有已评估 AI 系统最高分",已经足够让技术社区坐不住了。
五个模块,覆盖数学研究全流程
让这篇论文引起广泛讨论的,远不止一个得分数字。
过去几年,AI 在数学领域的主要突破集中在"解题"——给定问题,输出答案或证明。AlphaProof 刷 IMO 竞赛题,各家大模型卷 MATH benchmark,都属于"单点突破"模式。
AI Co-Mathematician 选了另一条路。
它把自己定位成数学家的全流程研究搭档,覆盖五个核心模块:
1.Ideation(构思)——帮助数学家产生新的研究想法 2.Literature search(文献搜索)——自动检索和整理相关文献 3.Computational exploration(计算探索)——进行数值实验和计算验证 4.Theorem proving(定理证明)——协助形式化和证明定理 5.Theory building(理论构建)——辅助搭建数学理论框架
论文摘要提到的早期测试成果相当具体:
"the AI co-mathematician helped researchers solve open problems, identify new research directions, and uncover overlooked literature references"
「AI 协作数学家帮助研究者解决了开放问题,发现了新研究方向,并挖掘出被忽视的文献引用。」
注意用词——"helped researchers solve",帮助研究者解决。人始终在环内,AI 担任的角色是 Co-Mathematician(协作数学家),不是替代者。
真正的亮点在架构:异步、有状态、记住走过的弯路
五个模块只是功能列表。这套系统真正让人眼前一亮的地方,在底层架构。
论文描述了一个异步(asynchronous)、有状态(stateful)的工作空间,具体特征包括:
- 管理不确定性
——面对模糊的研究方向,系统能同时追踪多条路径 - 精炼用户意图
——通过交互迭代,逐步理解数学家真正想探索什么 - 跟踪失败假设
——记录哪些路径走不通,避免重复犯错 - 输出原生数学产物
——生成可直接使用的数学公式和证明
原文的完整描述:
"an asynchronous, stateful workspace that manages uncertainty, refines user intent, tracks failed hypotheses, and outputs native mathematical artifacts"
「一个异步的、有状态的工作空间,能管理不确定性、精炼用户意图、跟踪失败假设,并输出原生数学产物。」
这套设计的核心理念是模拟人类协作工作流。
数学研究从来不是线性推进的——它充满了走弯路、推翻假设、偶然发现。一个"记得住你试过什么、走错过哪里"的 AI 搭档,和一个"每次对话都从零开始"的聊天机器人之间,差距是质的。
DAIR.AI 在推文中也特别强调了这一点:
"The asynchronous stateful workbench design is interesting to adopt if you are building agents for any expert workflow."
「如果你正在为任何专家工作流构建 agent,这种异步有状态的工作台设计值得借鉴。」
社区反应:兴奋、追问、质疑,全都来了
DAIR.AI 在推特上发布了这篇论文的介绍,评论区迅速分化成了几个阵营。
DAIR.AI 原帖的评价给得很高:
"This is one of the cleanest demonstrations that agentic AI moves the frontier on genuinely hard mathematical research, not just problem-solving but discovery support."
「这是 agentic AI 在高难度数学研究上推动前沿的最有说服力的演示之一——不止于解题,更延伸到了发现过程的支持。」
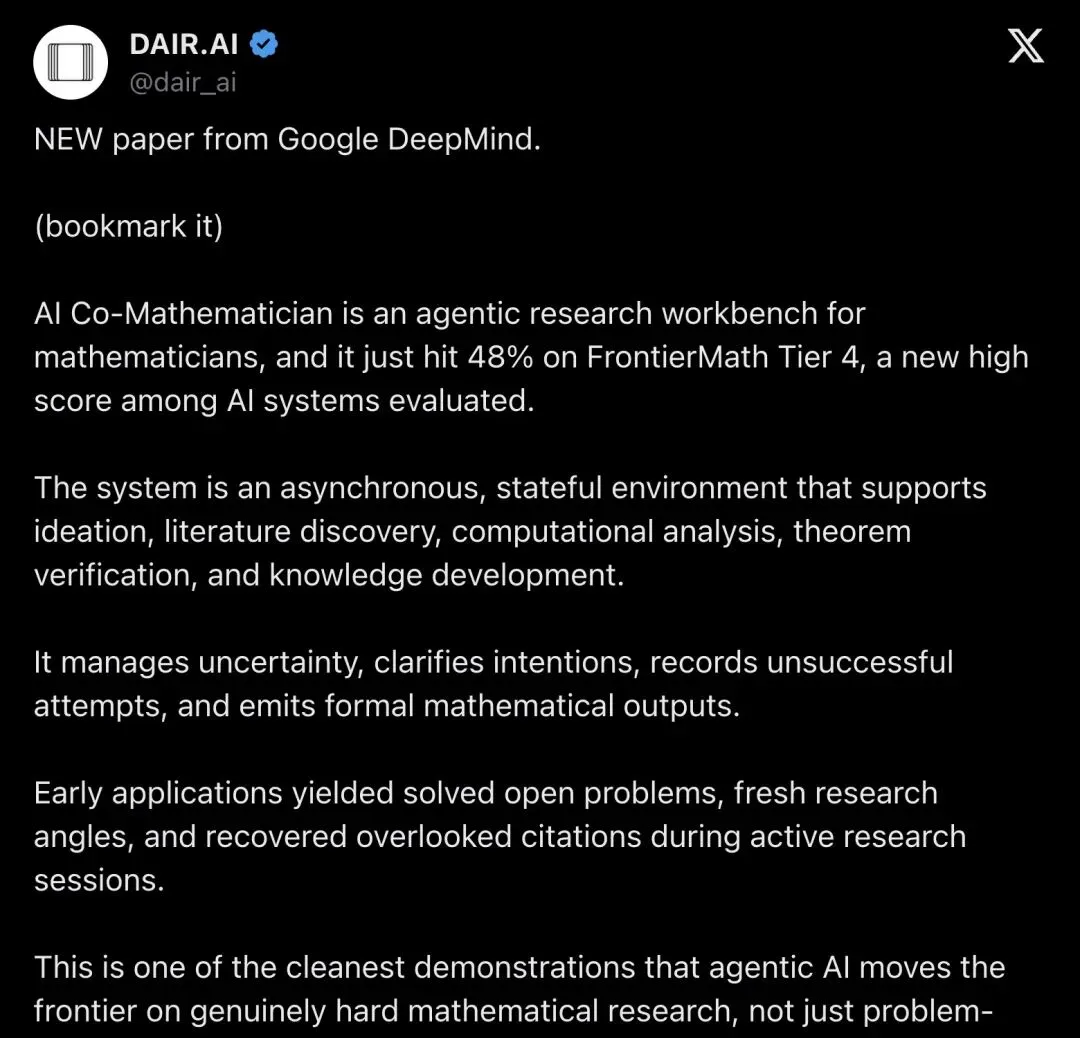


▲ DAIR.AI 在推特上介绍该论文,书签数接近点赞数,深度技术读者的收藏意愿很强
架构设计引发的讨论最热。
Scott Shapiro 直接下了判断:
"Stateful + asynchronous is the right architecture for any expert workflow. The 48% on FrontierMath Tier 4 is the proof."
「有状态 + 异步对于任何专家工作流都是正确的架构,FrontierMath Tier 4 上的 48% 就是证据。」
Andre Cunha 则追问能否迁移到其他领域:
"the stateful + tracks failed hypotheses design feels like the missing piece in most agent workflows I've seen. do you think this architecture pattern translates well to non-research domains like legal, finance, or consulting?"
「有状态 + 跟踪失败假设的设计,感觉就是大多数 agent 工作流里缺失的那块拼图。这种架构模式能迁移到法律、金融或咨询等非研究领域吗?」
不过需要指出——论文只在数学领域做了验证,向其他领域迁移目前完全是社区猜想。
但质疑同样尖锐。
@FiftyOne_50_ 提了一个让人停下来想想的问题:
"Once the agent can ideate, search, compute, prove, and remember failed attempts, the brake is no longer 'did it solve?' The brake is: who can prove it wrong?"
「一旦 agent 能构思、搜索、计算、证明,还能记住失败的尝试,刹车就不再是'它解出来了吗'。刹车变成了:谁能证明它错了?」
这指向了 AI 数学研究中一个根本性困境——当 AI 能力超过人类审核能力时,正确性靠什么保障?
Marcus 从另一个角度追问了协作中的分歧处理:
"Real question: how does this hold up when mathematicians disagree with the agent's proof strategy mid-session?"
「真正的问题是:当数学家在研究过程中对 agent 的证明策略产生分歧时,协作怎么继续?」
Gerard Sans 则给出了最冷的评价:
"If you look carefully, it's not really 'intelligence.' It's essentially a brute-force search across corpus distributions that can arrive at both right and wrong answers."
「仔细看的话,这并非真正的'智能'。本质上就是在语料库分布上做暴力搜索,既能得出正确答案也能得出错误答案。」
而 Bukenya Lukman 的批评直指 Google 的老问题:
"Google with its building of impressive tools and then keeping them to themselves. We would be testing this tool by now"
「Google 又是造出厉害的工具,然后自己藏着。如果开放了,大家现在就能上手测试了。」
截至目前,确实没有任何公开信息显示该系统会对外开放。
48% 到底有多重?要看更多信息才知道
回到那个核心数字。
48% 的分量取决于几个目前还无法完全确认的因素:Tier 4 到底有多难?包含多少道题?其他顶级系统的对比得分是多少?
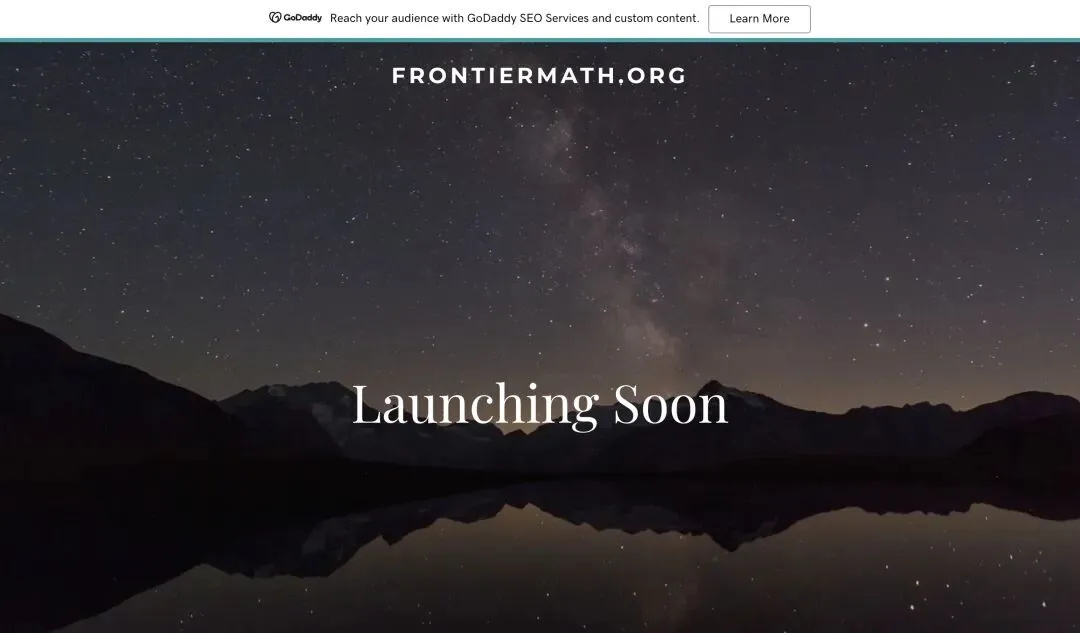
▲ FrontierMath.org 截至 2026 年 5 月仍显示"Launching Soon",基准详情尚未公开
FrontierMath 作为基准本身还没完全公开,这让 48% 暂时缺乏充分的对比参照。但论文白纸黑字写着"所有已评估 AI 系统中的最高分"——如果这一点得到第三方验证,分量不可忽视。
Marcus 在评论中给了一个更有启发性的视角:
"The interesting question isn't whether it beats human mathematicians on competition problems. It's whether the stateful environment pattern generalizes to research domains where 'correct' is harder to define than a proof."
「有趣的问题不在于它能否在竞赛题上胜过人类数学家,而在于这种有状态环境模式,能否延伸到'正确性'比证明更难界定的研究领域。」
这可能才是 AI Co-Mathematician 最值得关注的方向——它代表的范式转变,比单个得分数字更有意义。
当 AI 开始在完整的研究链条中扮演搭档角色,数学研究乃至更广泛的科学研究的工作方式,可能正站在一个转折点上。
18 人团队,22 页论文,一个声称刷新 FrontierMath 纪录的系统。Google DeepMind 这次画了一张很大的蓝图——但系统何时开放、架构能否迁移、验证困境怎么解决,每一个都是悬而未决的硬问题。
数学,或许是 AI agent 最好的试验场。而从"48% 的基准得分"到"真正改变数学研究的日常",中间隔着的距离,只有时间能回答。
— END —
