 夜雨聆风
夜雨聆风前三期我们一直在讲OpenAI和Anthropic的互搏,但硅谷这么多大公司,他们都在干嘛?今天先讲谷歌。之所以先讲它,是因为在这轮AI浪潮里,谷歌的处境最特殊。
苹果卖硬件,Meta卖社交和广告,亚马逊卖货也卖云。AI对它们要赢,但输了没有灭顶之灾。谷歌不一样。AI如果输了,搜索就没了。大家自己体感一下,现在日常用AI之后,打开搜索的频率是不是大幅下降?所以谷歌来说,AI是一场不能输的战争。
那谷歌现在的AI到底怎么样?我总结了三个词:全力以赴、迎头赶上、前途未卜。
· · ·
为什么说谷歌"全力以赴"
ChatGPT横空出世的时候,谷歌是真的慌了。当时谷歌做AI的有DeepMind、Google Brain好几个团队,各搞各的,力量分散。创始人谢尔盖·布林后来回忆说,那段时间他看到的是"一团混乱",于是就放弃了退休生活直接回到公司。
布林就住在帕拉奥图,现在几乎天天去谷歌加班,一周干60个小时,直接领导AI编程方向的突击团队。一家两万亿美元市值的公司,创始人亲自下场写代码、带队打仗,这在科技巨头里极其罕见。

组织层面更是大刀阔斧。谷歌把分散的AI团队全部统一到了DeepMind旗下——Brain合并过来,模型研发团队合并过来,负责任AI团队合并过来,连Gemini App的产品团队都并进来了。
为什么要以DeepMind为核心?因为研发负责人哈萨比斯本身就是诺贝尔奖得主,DeepMind被收购后一直保留着创业公司的文化,战斗力最强。谷歌这是把全部筹码押在一个有创业基因的组织上。Pichai和哈萨比斯也亲自下场,整个公司进入战时状态。
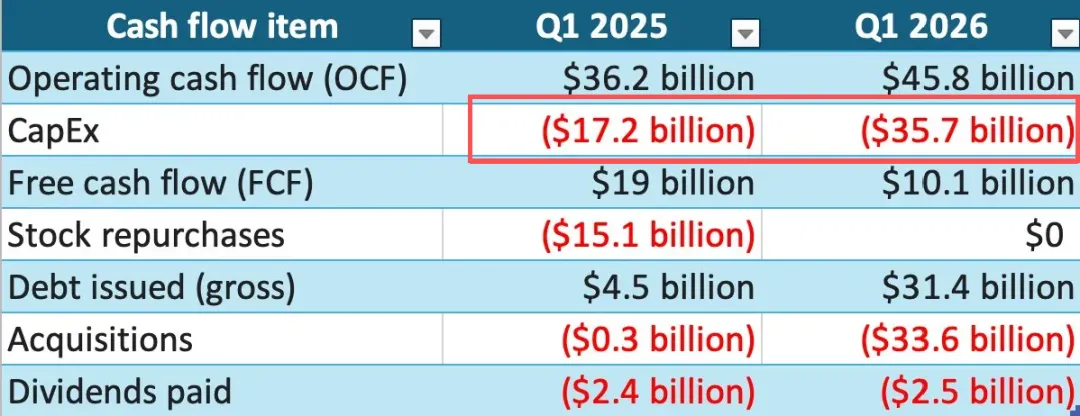
资源上就更不用说了。谷歌2026年Q1的资本支出高达357亿美元,全部砸向AI模型和算力设施,比去年同期翻了一倍。
而且谷歌不光买英伟达的卡,自己还造TPU:钱、卡、人、组织,能押的全都押上了。
· · ·
打了两年,谷歌真追上来了
这么全力以赴当然有结果。今天谷歌的大模型能力,算是迎头赶上了。
2025年11月推出Gemini 3.0 Pro,2026年2月又出了3.1 Pro。评测数据一路走高。
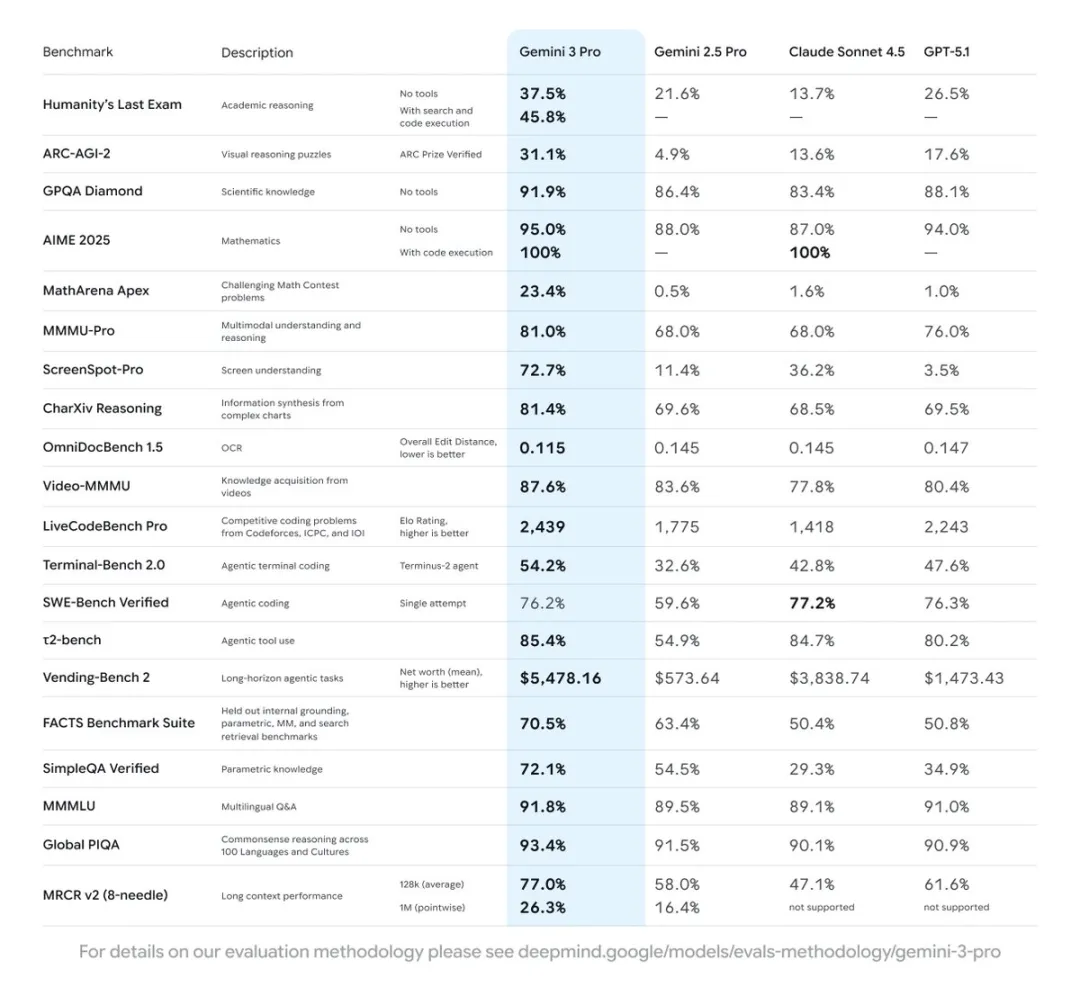
我自己用下来的感受也差不多——我现在日常遇到问题,绝大部分都问Gemini了,不用GPT了。现在你问个问题,Gemini的回答都不差,关键是它还免费。
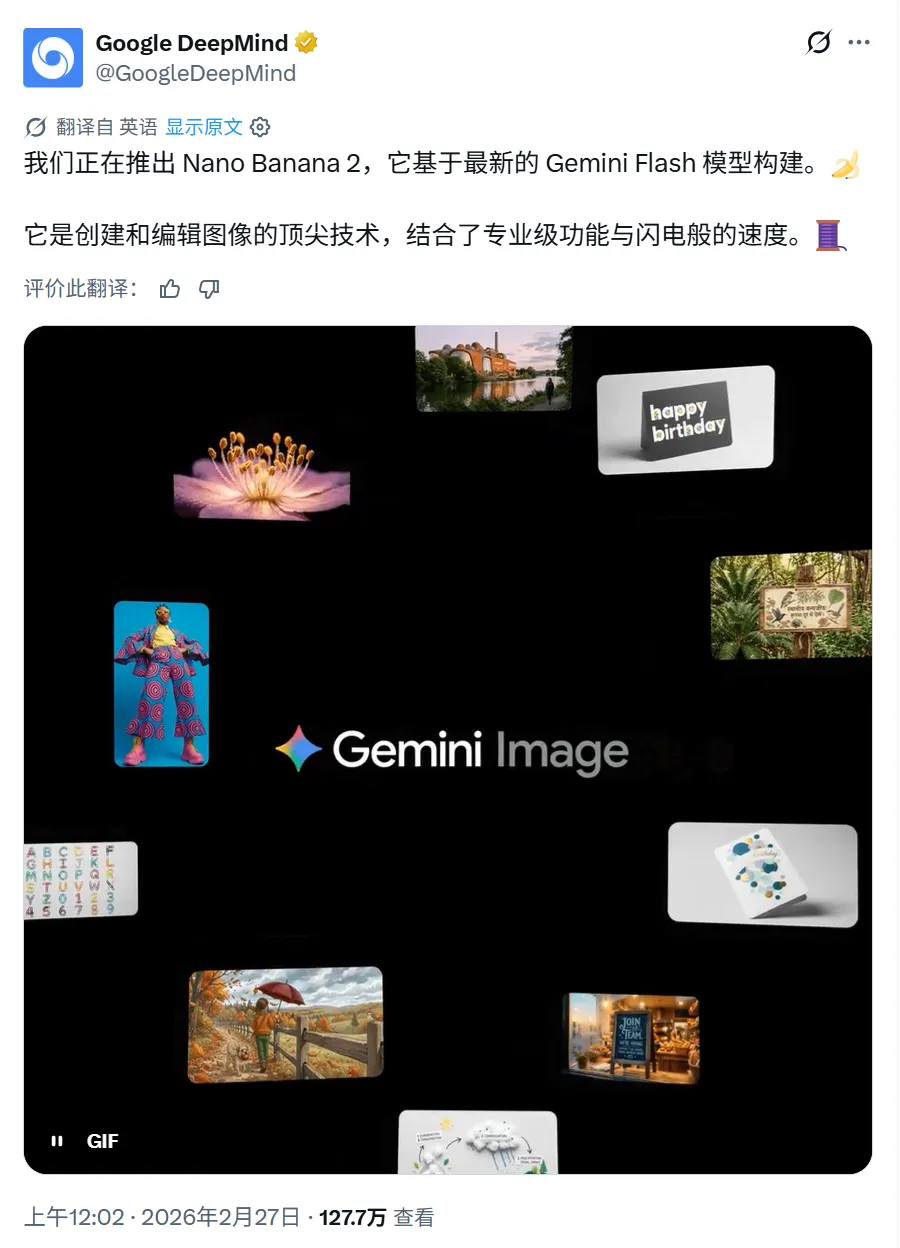
生图能力是另一个很直观的例子。去年11月,谷歌推出了Nano Banana Pro,全网好评,AI生图直接上了一个台阶。隔了三个月,Nano Banana 2发布,用Flash的速度做Pro的质量,2K图1到3秒出,成本还降了60%。生图这件事上,谷歌从追赶到领先,一步到位。
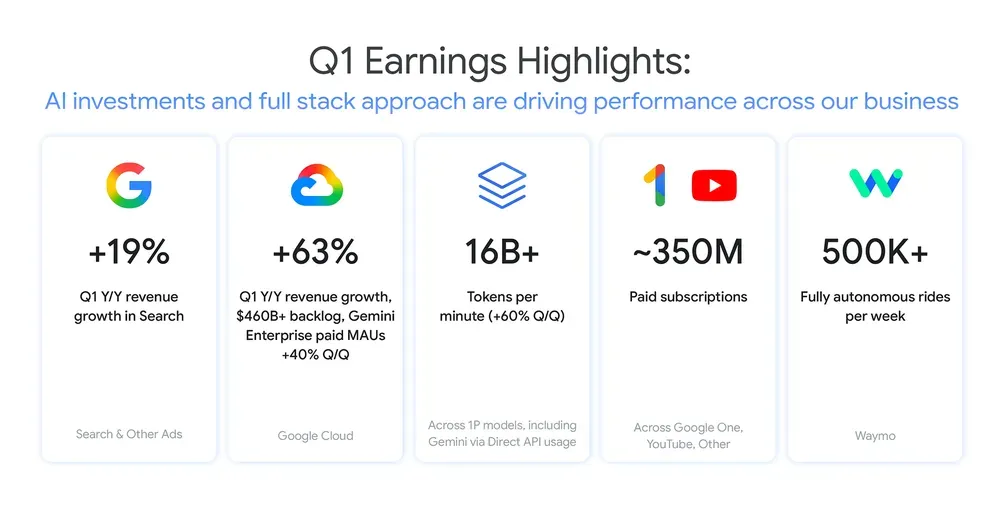
硬数据也在变好。谷歌2026年Q1财报,总营收1099亿美元,同比增长22%;Google Cloud首次突破200亿美元大关,达到200.3亿,同比增长63%。这里特别说一下云为什么涨这么猛,因为今天大家上云就是为了用AI。搜索业务604亿美元,同比涨了19%,AI Overviews功能推高了查询量。
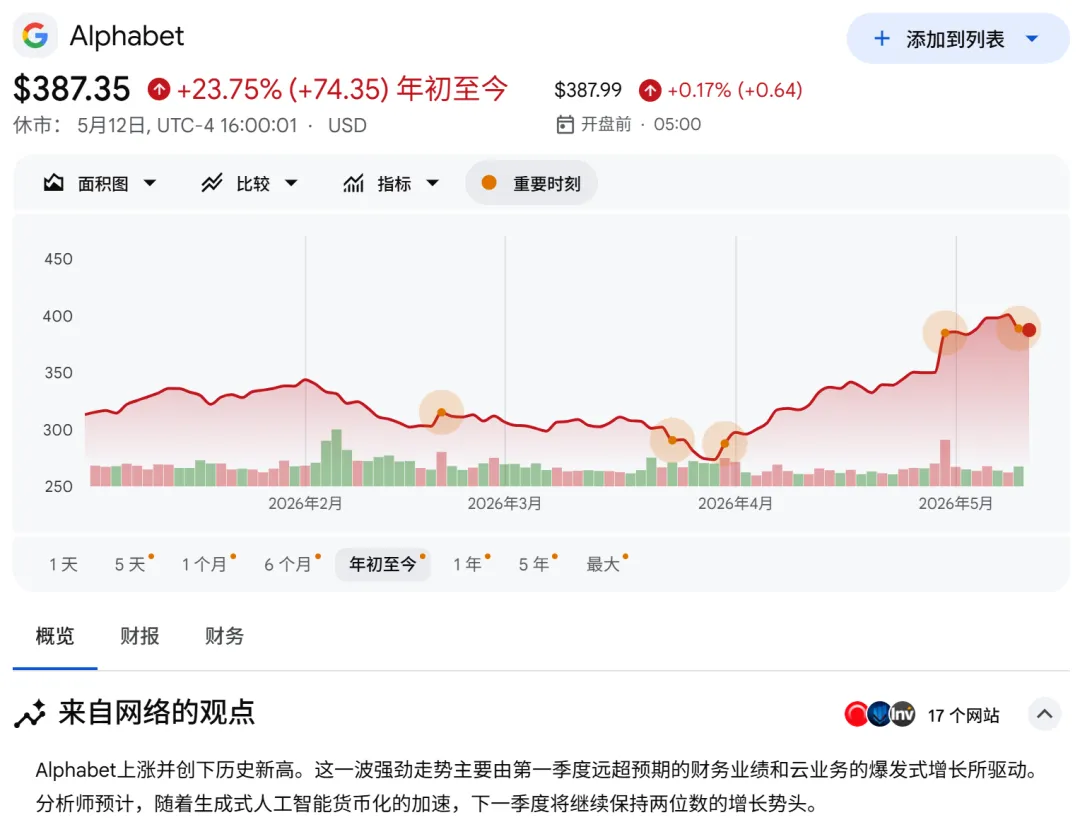
股价也跟着往上走。整个Q1的财报电话会上,Pichai和CFO几乎句句不离AI,因为增长确实就是AI拉动的。
打到这里,谷歌算是出了口恶气。模型强了,生图能打了,财务数字漂亮了。
但为什么我还要说它"前途未卜"?
· · ·
全力以赴,但前途未卜
因为在谷歌埋头追赶OpenAI的时候,AI战场的主线悄悄换了。
以前OpenAI是带头大哥,大模型怎么定义,就看OpenAI。
谷歌的思路很自然:OpenAI搞多模态输入输出,那我也搞;OpenAI做生图做视频,那我也做。一切对着OpenAI打。结果这两年打下来,好不容易追上了,回头一看,半路杀出个Anthropic。
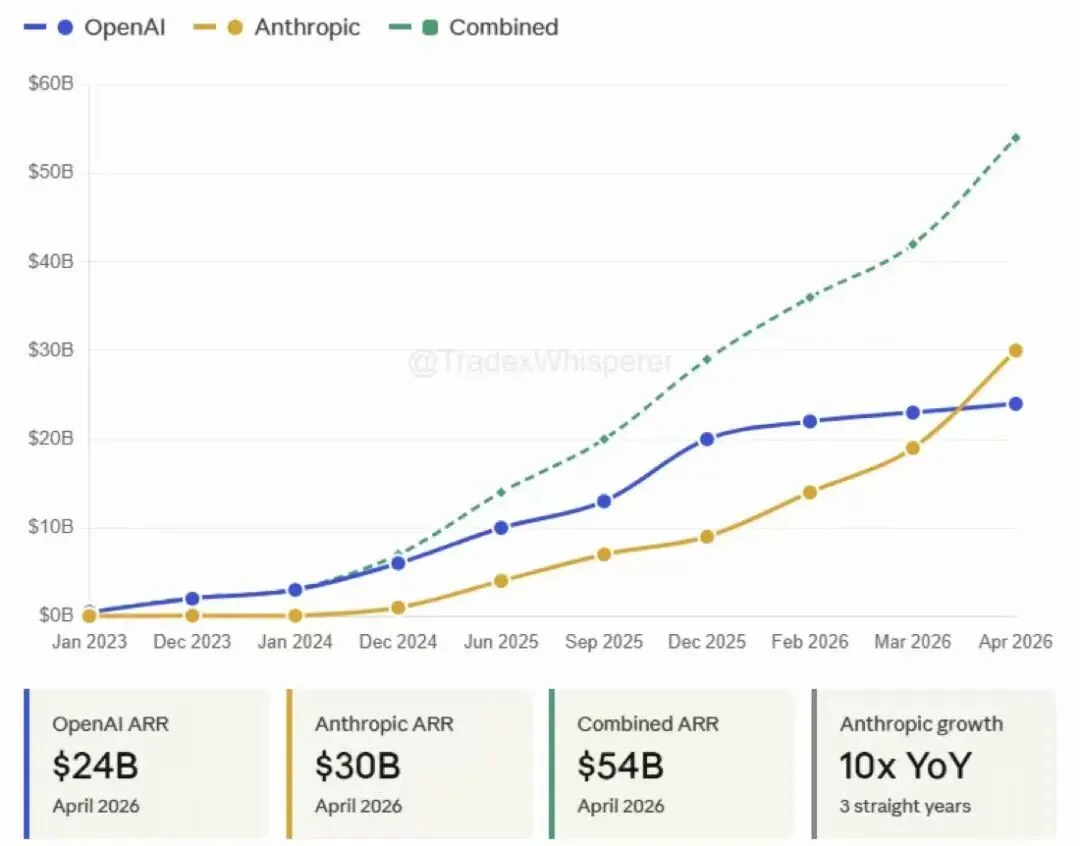
Anthropic的产品线跟OpenAI完全不一样。它不是以回答问题见长的,是以写代码、做长任务、自主规划见长的。
过去几个月,硅谷在AI这件事上达成了一个关键共识:一个模型如果能写好代码,它就能写代码去改进自己;代码质量越好,改进出的模型就更好,又能写出更好的代码继续改进——这是一条自我进化的循环。硅谷认为,这才是AGI真正的起点。
谢尔盖·布林是硅谷最早意识到这个转向的人之一。他亲自用了Anthropic最新的Mythos模型之后,在谷歌内部讲了三句话。
第一句:
Mythos就是一个纯粹的AGI。如果你用了Mythos还不觉得这是AGI,那我不知道什么叫AGI。
布林见过的大模型太多了,Gemini就是他自家的东西,但他给了竞争对手的模型这种评价,Mythos给他的冲击不是一星半点。
第二句:
我现在不要什么多模态大模型了。我要的是一个能写代码的模型。
注意这个转变。谷歌过去两年最大的投入方向就是多模态,Gemini的差异化卖点也一直是多模态,生图生视频。但布林现在说,别整那些花活了,单点极致,代码能力才是唯一的入口。
第三句:
我要我们谷歌的工程师,用我们自己写代码的模型写代码。
这句话藏着最深的焦虑。今天谷歌内部有个尴尬的局面:全公司原则上不让用竞争对手的产品,怕内部代码暴露给Anthropic。但Claude Code写代码就是好,效率就是高。于是DeepMind团队被特批可以用,其余团队不能。

谷歌内部直接分裂成两拨人:一拨用着Claude Code效率拉满,另一拨只能用自家工具。你不用,效率跟不上。你用了,代码暴露给对手。这才叫进退两难。
布林这三句话是三四月份说的。而大模型这行有个特点,行内管它叫"炼丹"——你把料放进炉子里,一练就是两三个月。布林意识到方向要转的时候,谷歌下一代主力模型已经在炉子里快出锅了,改不了了。
所以你现在看新闻,谷歌马上要在下周的Google I/O大会上发布Gemini Omni,主打视频生成,能输出各种高质量视频。外面肯定一片叫好。
但我可以告诉你,谷歌内部评价这件事已经不一样了,他们认为主战场不在这里了。Omni是个好产品,但它不在那条"自我进化"的主线上。
布林当然没有只说不做。评价完Mythos之后,谷歌紧急组建了一个由Sebastian Borgeaud领导的新编程团队,诺贝尔奖得主John Jumper也在里面。

这意味着他们得另起一个炉灶,重新练一炉以代码能力为核心的料。但对手不会等他们——Anthropic的Opus 4.7已经在那了,Mythos已经在那了。
· · ·
伟大不能被计划
说实话,这件事让人挺感慨。两三年前你要问我,做大模型需要什么?
需要足够的人才——谷歌有DeepMind加Brain。
需要足够的钱——谷歌几乎无上限。
需要足够的卡——谷歌自己还生产TPU,行业里唯一今天能对英伟达构成威胁的产品线。
我从来没想过,谷歌在这条路上会走得如此吃力,甚至在方向上出了问题。
所以科技创新真的没有稳操胜券。很多时候比的不是钱,不是设备,甚至不是人数,比的是认知,是真正能跟实践结合、不断自我迭代的思路。一旦某条路上的人找到了那个实践-认知-再实践的飞轮,创业者就真的有机会去颠覆那些看起来不可战胜的巨兽。
"伟大不能被计划"。大方向你知道会成,但哪条具体的路径才是真正的道路,没人能提前定义。谷歌这次能不能赶上来,我们拭目以待。
当然,谷歌还有一个杀手锏,叫TPU。下一期跟大家聊聊,TPU和英伟达GPU的竞争到底怎么样。
今天就到这,如果本文对你有帮助,欢迎收藏转发。如果对硅谷AI感兴趣,点个关注下期咱们接着聊。
顺便说一句,傅盛AI战队正在集结,如果你:
年龄在16-26岁之间,不管你是高中生、大学生、还是刚工作,都可以来。
会用AI工具解决实际问题,不管你是用AI做产品、写代码、搞设计、做运营,只要你能用AI搞出有意思的东西就行。
敢想敢干,不怕失败。
欢迎年轻人跟我们一起做AI,表现突出者我亲自带你。
发邮件、公众号后台发私信、评论区留言都可以,等你来加入。

