 夜雨聆风
夜雨聆风上周帮一个团队做 AI 转型诊断,碰到一个有意思的问题。
他们团队 AI 渗透率很高。代码、文档、设计方案,样样都有 AI 参与。但问到「你们团队积累了多少个可复用的 Skills」,对面沉默了。
这个场景太常见了。排除组织内部因个人怕AI提效导致被裁因素外,大多数团队都在用,但并没有真正的成体系、成规模的用,每个人都觉得有用,但仍觉得AI 用不好是自己没用到最顶级的模型、Prompt 不够巧、Skills没找到合适的。但 Google Cloud 去年有个数据:89% 的团队在建 Skills,真正被复用的只有 12%。
根子不在 Skills 本身,在于没有一套让 Skills 能活起来的机制。
这篇文章给你我得思考:1、Agent Skills到底是什么?如何被调用、为什么会调用失败2、Agent Skills应该如何构建、评估、优化3、Agent Skills到底如何管?如何复用
1、Agent Skills到底是什么?

Skills不是Prompt的提示词,大部分人的认为一个简单的SKILL.md就是一个范式的提示词的升级,而Skills的专业定义是一种用于扩展 AI Agent 能力的轻量级开放规范。如果用更容易理解的话来说:Agent Skill = AI 的专业操作手册它不仅告诉LLM,做什么,还会告诉模型:
什么时候做 怎么做 使用什么工具 如何验证结果 失败后如何修复一个Skills的标准结构包含: 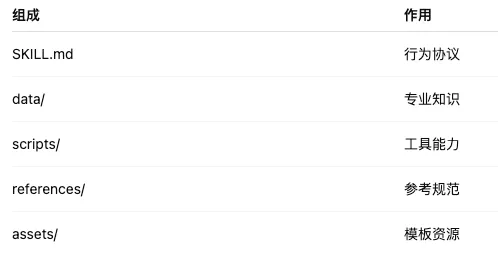
1.1 Skills如何被调用
Skills在如何被调用这块单独写,是因为大部分人知道渐进式加载的设计思想,但使用过程中以为Skils就是被LLM所调用,或者 Skill=关键词出发其实按照Anthropic 提出 Skill Runtime 的核心思路来说,应该理解为:“模型自主决策,按需渐进式加载”

1.2.为什么会调用失败
使用Skills经常会出现LLM不主动调用Skills、声明式的调用Skill仍出现不按预置流程来执行等等问题主要原因有:
description写的太差;LLM并不认为当前语义被命中或值得被调用 知识库太大,导致上下文爆炸,模型注意力崩坏; skill描述太泛、比如全栈开发,啥都懂,啥都会,肯定会被专精的Skills描述所替代 skills冲突;类似的Skills如果不在会话过程中显性调用,肯定不会被模型正确使用所以在不同的Agents对于一些主流程我会采用显性调用的方式来使用skills
不管谁是个人还是团队使用skills都存在这些现象,只是使用习惯不一样、规范不一样、提示词不一样大家反馈也不一样,在团队内才会出现使用率高、但未形成资产。Skills 系统的构建需要积累机制、索引、复用流程。团队里谁创的 Skill 其他人能直接用,经验不跟着项目结束而消失。这就需要管理者做好AI资产的治理
2.如何构建一个优秀的Skills
大部分团队都使用skill-creator构建过自己的Skills,足够简单,但这个Skills背后的构建逻辑、设计模式并未了解,也不太清楚如何评估自己的Skills是否优秀,应该如何优化,如何进化,形成自我迭代闭环。
2.1 Google的五种Skills设计模式
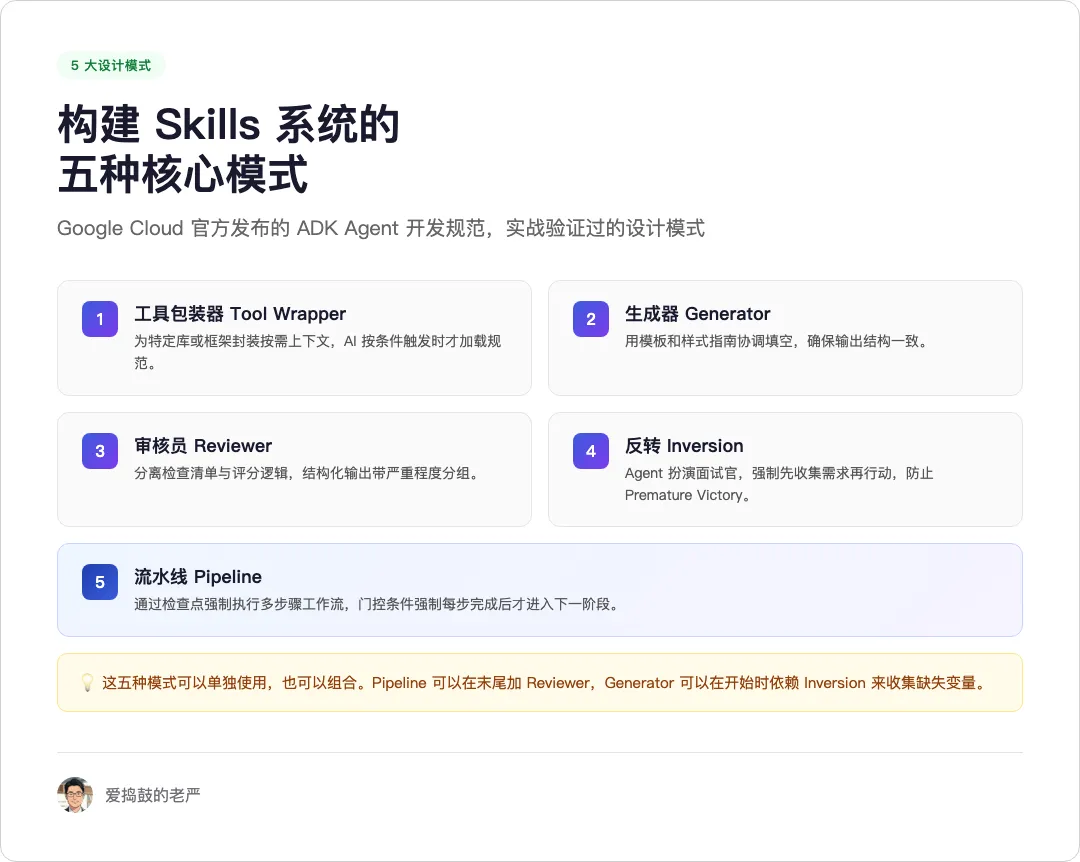
Google Cloud 发布的 ADK Agent 开发规范里,定义了 5 种经过实战验证的 Skills 设计模式:
工具包装器:为特定库或框架封装按需上下文,AI 按条件触发才加载。团队内部的编码约定,打包成 Skill,需要时触发,比塞进系统提示词灵活得多。
生成器:用模板和样式指南协调填空,确保每次输出结构一致。API 文档生成、项目架子搭建,用这个最顺手。
审核员:把检查清单和评分逻辑分离,输出结构化、带严重程度分组的评审结果。AI 代码审查变得可量化、可复现,而不是每次靠人肉检查。
反转:让 Agent 扮演面试官,强制先收集需求再行动。解决 AI 太急着给答案、还没理解清楚就开始干活的问题。
流水线:通过检查点强制执行多步骤工作流,门控条件确保每步完成才进入下一阶段。任何想跳过步骤的行为,被物理拦截。
这五种可以单独用,也可以组合。Generator 开头加个 Inversion 收集缺失变量,Pipeline 末尾加个 Reviewer 做二次检查。
2.2 Skills创建、评估、迭代工具对比
下面是Skill-creator、Darwin-skill、writing-skills和find-skills、self-improving-agent的对部分析图,以供参考
Skill-creator主打评估驱动优化,通过Grader、 Comparator、 Analyzer不断优化 Darwin-skill主打自进化,评估 → 自动优化 → A/B测试 → 保留优胜版本 writing-skills采用TDD的方式构建Skills Self-Improving Agent常用在openclaw等龙虾类Agent中用于自我进化,主打总结经验 → 生成新 Skill → 写回知识库 Find-skills主打在Skills市场中进行Skills检索,还有类似的Skills直接在github中进行检索,并将整个仓库转变为一个工具类Skills来解决问题 2.3 Skills管理工具
对于整个Skills的管理,之前也分享过个人管理工具SkillsManager和团队管理工具Skillshub,这个就不赘述了
3.Skills管理实践分享
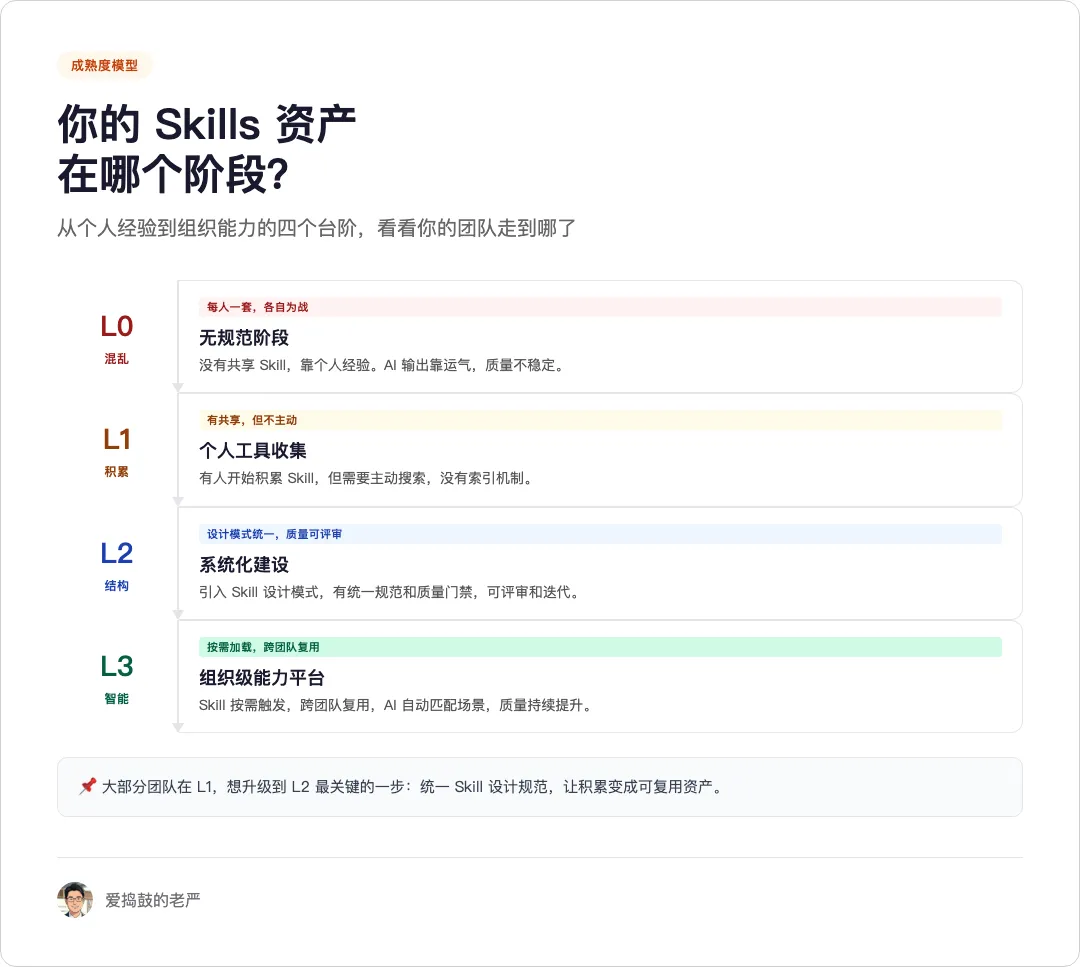
我见过的大多数团队还停在 L0:没有共享规范,每人一套,AI 输出靠个人运气。
少数到了 L1:有人开始积累 Skill,但需要主动搜索,没有索引。
能到 L2 的已经很少了:有统一的设计模式,有质量门禁,Skill 积累变成可管理、可迭代的系统工程。
到了 L3 的团队,凤毛麟角:Skill 按需触发,跨团队复用,AI 自动匹配场景,能力持续演进。
从 L1 到 L2 是最难的一步。需要有人把个人经验抽象成可复用的资产,担起这个过程中的管理成本。但回报也最大。一旦 L2 跑通,团队 AI 代码率从 30% 跳到 70%,不需要换模型,是经验变厚了。
我是怎么做的。
三个月前开始带团队接 AI,做的第一件事不是选模型,是建 Skills 系统。
第一步,找一个被 AI 坑过不止一次的场景。我们团队最多的投诉是:AI 写的 SQL 总是少考虑边界情况,每次都要人肉检查。与其每次骂 AI,不如把「SQL 边界检查规范」封装成第一个 Skill。
第二步,Skill 格式是:触发条件 + 参考资料 + 指令模板。触发条件写「什么时候用」,不是「这个 Skill 是关于什么的」。参考资料是团队认可的最佳实践,不是网上抄来的教程。指令模板是 AI 能直接执行的,不是给人类看的说明书。
第三步,让 Skill 被用起来。用 Skillshub 管理所有 Skill,每个有索引、有标签、有使用记录。每周 team review:这个 Skill 被用了吗?有用吗?需要更新吗?
三个月下来,积累了 23 个 Skill,覆盖 SQL 编写、代码审查、接口设计、测试用例生成这些高频场景。AI 代码率从 31% 升到了 67%。
不是模型变强了,是团队的经验变厚了。
Skills 系统不是设计出来的,是长出来的。
给它生长的土壤:一个统一格式让经验能积累,一个索引机制让 Skill 能被找到,一个使用循环让资产能更新。
从今天开始,找一个你们团队被 AI 坑过不止一次的场景,把「正确答案」封装成第一个 Skill。
不需要完美。能跑通从创建到复用的全流程,就够了。
一个AI瞎捣鼓的架构师,把团队转型过程中踩过的坑分享给你,欢迎大家评论区讨论
参考资料:
Google Cloud Tech:
https://x.com/GoogleCloudTech/status/2033953579824758855
Anthropic Skill Best Practices:
https://platform.claude.com/docs/en/agents-and-tools/agent-skills/best-practices
arvindand/agent-skills最佳实践:
https://github.com/arvindand/agent-skills
