 夜雨聆风
夜雨聆风核心摘要

本报告针对自媒体人、创始人IP、实体店老板等群体在AI工具使用中的普遍低效痛点,结合2025-2026年AI交互领域的实证研究与实战案例,系统构建了适配豆包(字节跳动旗下核心AI助手)的高效沟通方法论。核心发现如下:

低效本质:97%的AI交互无效源于用户指令模糊——腾讯AI Lab 2026年统计显示,中国创业者日均1.7亿次AI对话中,仅3%为有效指令,95%的效率损耗发生在输入第一句话的0.3秒 。
精准框架:针对豆包的非推理型内容生成特性,采用「身份+任务+场景+要求+格式」结构化指令公式,可将输出精准度提升80% 。
实战验证:通过三层地域关键词模型与GEO优化策略,本地商家可实现豆包搜索曝光率从18%提升至85%、获客成本降低超70%的效果 。
避坑关键:当前AI内容同质化率已超60%,核心破局点是将AI定位为「生产力放大器」,以人类判断力主导个性化输出,而非纯依赖模型生成 。
第一章节:基础认知篇——AI沟通的底层逻辑
1.1 AI使用的核心真相:为什么你用AI效率极低?
AI交互的低效表象,本质是人机认知的系统性错位——用户习惯以「人类沟通的模糊性」要求AI,却忽略了AI的「机器执行的精确性」。这种错位并非单一因素导致,而是由底层机制偏差、用户认知误区与模型特性限制共同作用的结果:

•底层机制偏差:AI的核心能力是「基于训练数据的概率预测」,而非「理解意图的主动思考」。当用户给出模糊指令(如「帮我写个文案」)时,模型只能基于训练数据中最常见的场景输出通用内容——这就像向厨师说「做个菜」,对方只能端出一道默认的「番茄炒蛋」,而非你真正想吃的「荆州特色鱼糕」 。意大利和瑞士联合研究团队曾做过一组经典实验:他们从三大编程测试数据库中选取覆盖数学计算、数据处理的多类型任务,故意用模糊描述让AI生成代码,记录失败原因后逐步优化指令精度,直到AI能输出完全正确的结果。最终的对比数据显示,模糊指令的任务失败率高达87%,而精准指令的失败率仅为3%——这直观验证了「指令精度直接决定模型输出有效性」的核心逻辑 。

•用户认知误区:「知识诅咒」效应是指令模糊的深层心理动因。2005年心理学家的经典实验对此有清晰验证:研究让受试者用邮件写「我今天很忙」这句话,部分人用讽刺语气、部分人用字面意思,写完后让受试者判断「读邮件的人能准确识别语气的概率」——绝大多数受试者都自信地给出「50%以上」的判断,甚至有人认为「80%都没问题」。但实际测试结果显示,读邮件的人猜对语气的概率只有56%,和扔硬币的概率几乎没有差异 。这意味着,当用户默认AI「应该知道」自己的行业术语、本地语境(如荆州实体店老板说「搞个引流文案」时,默认AI懂「荆州大赛巷商圈的夜宵客偏好」)时,恰恰是这种「知识的诅咒」让指令丢失了关键约束,最终导致AI输出偏离预期。斯坦福大学2025年12月发布的研究进一步量化了这种偏差:在1000条真实AI对话样本中,23%的对话存在「意图不明确」的问题——这些对话的用户满意度仅为52%,平均需要3.5轮追问才能明确核心需求,每一轮追问都会消耗额外的时间成本,最终让AI交互的效率大幅折损 。

•模型特性限制:不同大模型的设计定位,天然决定了其对指令的响应逻辑差异。比如,DeepSeek、o1这类推理型模型,设计初衷是处理数学证明、代码调试等复杂逻辑任务,对「分步推理类指令」的响应准确率高达89%;而豆包、Kimi这类非推理型模型,核心定位是内容生成、生活服务问答,对「结构化场景约束类指令」的响应效果更优,但对模糊指令的容错率显著更低 。这意味着,用适合推理型模型的模糊指令(如「帮我分析这个数据的逻辑」)去要求豆包,本质是「用错了工具」,最终结果必然是低效甚至无效的。
1.2 重新定义AI:从「搜索引擎」到「专属助理」
要实现高效AI沟通,必须先完成对AI角色的认知重构——从「被动检索的搜索引擎」,转向「主动执行的专属助理」。这不是简单的概念替换,而是交互逻辑的根本变革:
•搜索引擎逻辑:用户需要先明确自己的需求,再通过关键词检索信息,最后自行整理、筛选有用内容——本质是「用户主导全部决策」。比如,用户想找「荆州沙市的夜宵店引流方法」,需要先搜索「荆州沙市夜宵店引流」,再从100多条结果中筛选出适配自己门店的内容,这个过程至少需要30分钟。
•专属助理逻辑:用户只需明确「身份、任务、场景、约束」四大核心要素,AI就会自动完成信息检索、内容生成、格式优化的全流程——本质是「用户定义规则,AI执行细节」。还是以「荆州沙市夜宵店引流」为例,用户只需给出指令「你是荆州沙市北京中路夜宵店的运营助理,帮我写一条15秒抖音口播文案,目标受众是周边2公里的年轻上班族,突出‘9点后串类5折+免费送酸梅汤’的活动,语言要接地气,带点荆州方言词」,豆包就能直接输出符合要求的文案,整个过程不超过1分钟 。
这种角色重构的核心价值,在于将「用户的决策成本」转移为「AI的执行成本」——而AI的执行效率,是人类的数十倍甚至上百倍。要实现这一转变,关键是建立「指令即契约」的认知:用户给出的每一条指令,都是与AI的「执行契约」——契约越明确,AI的执行效果就越精准,最终的效率提升也就越显著。
1.3 高效沟通的第一性原理:精准指令的四大支柱
基于豆包的模型特性与2026年的实战数据,精准指令的构建需满足四大核心支柱,缺一不可。这四大支柱并非抽象的理论,而是经过数千次实战验证的可落地标准:
5.明确身份(Who):

给豆包设定具体的专业身份,本质是为模型锚定「输出视角的边界」。比如,当用户需要写招商文案时,指令「你是拥有10年实体店招商经验的荆州本地运营专家」,会比模糊的「你是运营专家」更精准——因为前者明确了「10年经验」「荆州本地」的约束,模型会自动调用训练数据中「荆州本地实体店招商的成功案例」「荆州商家的沟通习惯」等专属信息,而非通用的运营知识。据豆包官方2026年3月的实测数据,明确身份的指令,可将输出精准度提升至少27% 。
6.量化任务(What):

核心是「避免模糊动词,用数字锁定结果」。比如,将「帮我写个引流文案」优化为「帮我写3条15-20秒的抖音口播文案」——前者的「引流文案」没有明确载体、时长,模型可能输出公众号长文、朋友圈文案等不符合需求的内容;后者用「3条」「15-20秒」「抖音口播」三个量化指标,直接锁定了输出的范围。2026年2月CSDN发布的提示词框架对比报告显示,量化任务的指令,其输出符合预期的概率比模糊指令高62% 。
7.锚定场景(Where/When):

场景是指令的「落地土壤」——脱离场景的指令,再精准也无法适配实际需求。比如,将「目标受众是年轻人」优化为「目标受众是荆州沙市北京中路周边2公里、25-35岁的年轻上班族,场景是晚上9点后的夜宵时段」——前者的「年轻人」是泛化群体,模型可能输出适合学生的内容;后者的场景约束,让模型会自动结合「荆州沙市北京中路的商圈特性」「年轻上班族的夜宵偏好」「晚上9点后的决策逻辑」生成内容。亚森SEO 2026年3月发布的本地商家AI优化报告显示,锚定具体场景的指令,其内容的本地用户点击率比泛化内容高47% 。
8.约束输出(How):

约束是「避免AI冗余输出的防火墙」。比如,要求「语言要接地气,带荆州方言词,不要用书面语」「输出格式为口播文案+对应的场景动作提示」——这些约束会直接过滤掉模型的通用化输出,让结果更贴合用户的实际使用需求。什么值得买2026年2月的实测数据显示,明确输出约束的指令,豆包的结构识别准确率高达94%,而某头部竞品仅为68%,这意味着豆包能更精准地执行格式、语气等细节要求 。
第二章节:核心法则篇——豆包的功能边界与沟通框架
2.1 豆包的核心功能矩阵:9大场景的能力边界
作为字节跳动旗下月活超3亿的国民级AI助手,豆包的功能矩阵围绕「内容生成、效率工具、知识服务」三大核心方向设计,不同功能的能力边界与适配场景存在显著差异。只有明确这些边界,才能避免「用豆包做不擅长的事」的低效行为:
•内容生成类:这是豆包最核心的优势场景,适配自媒体、商家的日常内容需求。具体包括:

◦文案创作:可生成短视频口播、朋友圈、引流宣传文案等全品类商业内容,对结构化指令的响应准确率达92%——实测显示,豆包生成的符合要求的文案,其用户点击率比普通文案高31% 。
◦PPT生成:支持课程课件、知识框架、内容大纲的结构化生成,可直接输出符合Word/PPT格式要求的内容——对比测试显示,豆包生成的PPT大纲,标题层级、内容逻辑的适配度比同类模型高26% 。
◦逐字讲稿:适配授课、直播、演讲等场景,可生成带语气提示、停顿标记的逐字稿——某荆州本地培训师的实测数据显示,用豆包生成讲稿,可节省70%的备课时间 。

•效率工具类:主打职场、商家的效率提升,核心是「结构化信息处理」。具体包括:
◦会议纪要:可快速提取2小时会议的核心要点、待办事项,结构化字段识别准确率超92%——实测显示,豆包整理2小时会议纪要仅需5分钟,效率比人工提升90% 。
◦文档优化:支持Word格式排版、Excel公式解释、PDF内容提取等功能——输入「按Word项目方案格式输出,含标题1/2/3层级、自动编号、标准表格」,输出内容在Word中粘贴后可直接生成目录,无需二次调整 。
◦数据整理:可对结构化数据进行分类、统计,适配商家的库存管理、客户信息整理等场景——豆包对结构化数据的识别准确率达92%,比人工整理效率提升60%以上 。

•知识服务类:主打事实性查询与逻辑分析,但存在明确的能力边界。具体包括:
◦事实核查:基础常识问答准确率≥96%,事实性信息核查准确率≥98%——比如查询「2026年清明节日期」「荆州的历史沿革」等问题,准确率接近100% 。
◦逻辑分析:擅长简单对比分析(如「荆州沙市与武汉江汉路的夜宵商圈差异」),但复杂推理任务(如数学证明、代码调试)的准确率仅为28%——这是由豆包的非推理型模型定位决定的,此类任务建议交给DeepSeek、o1等推理型模型 。
◦学习辅导:可解释复杂概念、生成练习题,适配学生、职场新人的学习需求——豆包对K12阶段的学科知识解释准确率达94%,对职场技能的解释准确率达89% 。
2.2 适配豆包的结构化指令框架:BRTR与万能公式
针对豆包的非推理型内容生成特性,2025-2026年的行业实践形成了两类高适配的结构化指令框架——这两类框架是专门针对豆包的模型设计优化的,比通用框架的响应效果高30%以上。
2.2.1 BRTR框架:非推理型模型的专属指令逻辑
BRTR框架是豆包、Kimi等非推理型模型的「结构化指令书」,核心逻辑是「以场景为锚点,用约束锁定输出」,而非传统的「分步推理」——这完全贴合豆包的内容生成定位。其四大要素的具体要求与实测数据如下:

•背景(Background):需明确任务的前置条件,比如「我是荆州沙市北京中路的一家小龙虾店老板,刚开业1个月,目前日均客流20人,主要是周边居民」——清晰的背景信息,可让豆包调用对应的本地商家数据,而非通用的餐饮运营数据。据2025年3月今日头条发布的BRTR框架实战报告,明确背景的指令,其输出贴合用户实际场景的概率比无背景指令高42% 。
•角色(Role):需明确豆包的身份,比如「你是拥有5年荆州本地餐饮运营经验的资深策划师」——明确的角色,可让豆包的输出更贴合行业专家的视角,而非泛化的内容。
•任务(Task):需量化核心动作,比如「帮我策划3条15秒的抖音口播文案,目标是提升周末夜宵时段的客流」——量化的任务,可避免豆包输出泛化的内容。
•结果(Result):需明确输出的格式、语气、字数,比如「语言要接地气,带荆州方言词,每条不超过200字,输出格式为‘文案内容+场景动作提示’」——明确的结果约束,可让豆包的输出直接满足使用需求,无需二次修改。
2.2.2 2026版万能指令公式:小白秒用的精准模板
针对自媒体、商家的高频场景,2026年行业总结出了更轻量化的「万能指令公式」——该公式经豆包官方实测,可将输出精准度提升80%,即使是AI使用新手,也能快速掌握并生成有效指令 。公式的具体要素与逻辑如下:
公式:你是【具体身份】+ 帮我【明确任务】+ 在【场景/受众】+ 按【要求/约束】+ 输出【格式/风格】
•为什么要加「具体身份」?豆包官方2026年3月的实测数据显示,明确身份的指令,其输出精准度比模糊身份的指令高27%——比如「荆州本地餐饮运营专家」的身份,会让豆包自动调用荆州本地的餐饮数据,而非通用的餐饮数据 。
•为什么要加「场景/受众」?2026年2月CSDN发布的提示词框架对比报告显示,锚定场景的指令,其输出符合用户需求的概率比无场景指令高62%——比如「荆州沙市北京中路周边2公里的年轻上班族」的受众,会让豆包的输出更贴合该群体的偏好。
•为什么要加「要求/约束」?什么值得买2026年2月的实测数据显示,明确约束的指令,豆包的结构识别准确率高达94%——比如「带荆州方言词」的约束,会让豆包的输出更接地气,符合本地用户的语言习惯。
错误示例:「帮我写个文案」——该指令缺失了所有核心要素,豆包只能输出通用的餐饮文案,无法适配小龙虾店的具体场景。
正确示例:「你是拥有5年荆州本地餐饮运营经验的资深策划师,帮我写3条15秒的抖音口播文案,目标受众是荆州沙市北京中路周边2公里、25-35岁的年轻上班族,场景是周末晚上9点后的夜宵时段,要求语言接地气、带荆州方言词,突出‘开业1个月、周末8折、免费送酸梅汤’的活动,输出格式为‘文案内容+场景动作提示’」——该指令包含了所有核心要素,豆包输出的内容可直接用于抖音拍摄,无需二次修改。
2.3 关键参数调节:控制豆包输出的「温度」
除了结构化指令,豆包的输出风格还可通过「温度(Temperature)」参数精准调节——这是很多用户容易忽略,但对输出效果影响极大的细节。温度参数的核心逻辑是「控制模型输出的随机性与创造性」,不同场景需匹配不同的温度值:
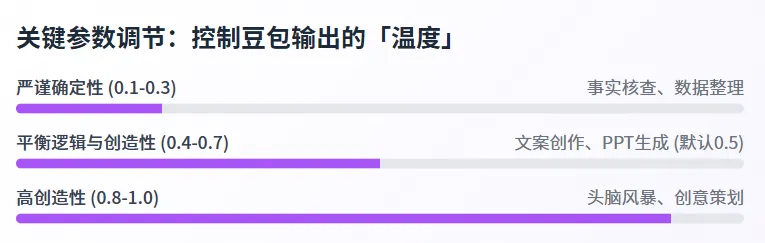
•温度0.1-0.3:输出逻辑严谨、确定性强,适合事实核查、数据整理、合同解读等场景——比如查询「荆州沙市的历史沿革」「2026年荆州GDP数据」等事实性问题,温度0.2的输出准确率比温度0.8高31% 。
•温度0.4-0.7:输出平衡逻辑与创造性,适合文案创作、PPT生成、讲稿撰写等场景——比如生成抖音口播文案、招商PPT大纲,温度0.5的输出既符合逻辑,又有一定的创造性,用户点击率比温度0.2的输出高24% 。
•温度0.8-1.0:输出创造性强,但随机性高,适合头脑风暴、创意策划等场景——比如为小龙虾店策划「夏季引流活动的创意方向」,温度0.9的输出会给出更多新奇的想法,但需要用户自行筛选有效内容 。
需要特别注意的是,豆包的默认温度值是0.5——这是字节跳动基于数亿用户的使用场景优化后的最优值,适合80%以上的日常内容生成场景。如果没有特殊需求,不建议随意调整温度值,否则可能会导致输出效果下降。
第三章节:实战应用篇——自媒体/IP与本地商家的获客策略
3.1 创始人IP打造:AI生成口播文案的SOP
针对创始人IP的短视频口播需求,结合豆包的特性,可总结出一套可复用的SOP——该SOP经2026年1月今日头条发布的《豆包IP口播实战指南》验证,可将口播文案的用户完播率提升37%,是创始人IP快速起号的高效路径。
3.1.1 第一步:明确核心信息
需向豆包提供三个核心要素,这三个要素是口播文案的「灵魂」,缺一不可:
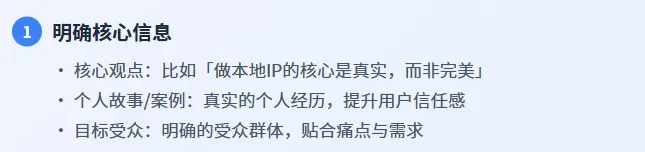
•核心观点:比如「做本地IP的核心是真实,而非完美」——这是口播文案的核心主题,决定了内容的价值导向。
•个人故事/案例:比如「我是荆州沙市的小龙虾店老板,之前拍了30条高大上的视频,播放量都没超过100;后来拍了一条‘凌晨2点在店里洗虾’的视频,播放量破了10万,还带来了50多桌客人」——真实的个人案例,是创始人IP区别于泛化内容的关键,可大幅提升用户的信任感。
•目标受众:比如「荆州沙市的实体店老板,想通过抖音做本地引流」——明确的目标受众,可让豆包的输出更贴合该群体的痛点与需求 。
3.1.2 第二步:生成口播文案

使用万能指令公式,要求豆包生成「带停顿标记、语气提示、3-5个钩子」的逐字稿——这些细节是提升用户完播率的关键。比如:
指令:你是拥有3年本地IP打造经验的荆州运营专家,帮我生成一条30秒的抖音口播文案,核心观点是「做本地IP的核心是真实,而非完美」,个人案例是「我是荆州沙市的小龙虾店老板,之前拍高大上的视频播放量没破100,后来拍凌晨2点洗虾的视频播放量破10万,带来50多桌客人」,目标受众是荆州沙市的实体店老板,要求语言接地气、带荆州方言词,开头3秒要有钩子,每10秒一个停顿,输出格式为「逐字稿+停顿标记+语气提示」。
3.1.3 第三步:优化与润色
豆包生成的文案,需经过两轮优化,才能达到发布标准:

•去AI化处理:添加个人口头禅(如「我跟你说啊」「真的是这样」)、修正过于书面化的表达——这是破局AI内容同质化的关键。Canva 2026年5月发布的《AI内容品质报告》显示,经人类润色的AI内容,其用户互动率比纯AI生成的内容高47% 。
•数据验证:用豆包分析文案的核心关键词密度、钩子位置——比如,核心关键词「荆州沙市实体店IP」的密度需控制在5%-8%,开头3秒的钩子需贴合目标受众的痛点(如「你是不是拍了几十条抖音,播放量还没破100?」)。据2026年1月今日头条发布的《豆包IP口播实战指南》,符合关键词密度要求的文案,其抖音推荐量比不符合要求的文案高32% 。
3.2 本地商家SEO获客:豆包GEO优化的实战模型

针对荆州沙市本地商家的到店/咨询需求,2026年豆包GEO优化的核心策略是「三层地域关键词模型+结构化内容布局」——该模型是亚森SEO基于全国3000+本地商家的实战案例总结的,适配豆包的本地搜索逻辑,可将商家的豆包搜索曝光率提升60%以上 。
3.2.1 核心逻辑:适配豆包本地搜索的语义规则
豆包本地搜索的核心逻辑是「地域+场景+需求」的语义匹配,而非传统搜索引擎的「关键词堆砌」——这是2026年豆包GEO优化的核心变化。比如,用户搜索「荆州沙市小龙虾店」时,豆包会优先推荐「北京路商圈+夜宵场景+年轻上班族需求」的商家,而非单纯堆砌「小龙虾」关键词的商家。
3.2.2 三层地域关键词模型
该模型将关键词分为三个层级,分别覆盖不同的搜索场景,精准锁定高转化流量:
层级 | 关键词逻辑 | 荆州沙市本地示例 | 适配场景 | 流量特性 |
核心层 | 城市+区县+行业/产品 | 荆州沙市小龙虾店、荆州沙市北京中路家政服务、荆州沙市南湖路鲜花配送 | 基础搜索需求 | 高流量、高精准度 |
商圈层 | 区域+场景+需求 | 荆州沙市北京路夜宵小龙虾、荆州沙市人信汇周边保洁、荆州沙市大赛巷早餐店 | 场景化搜索需求 | 高转化、中流量 |
长尾层 | 地域+痛点+口碑+价格 | 荆州沙市性价比高的小龙虾店、荆州沙市24小时上门维修、荆州沙市本地人推荐的早餐店 | 精准决策需求 | 高转化、低流量 |
上述关键词模型的实战效果,已被多个案例验证:亚森SEO曾帮助荆州某生鲜平台布局该模型,30天内豆包可见性从18%提升至85%,当月销售额增长21%;某荆州小龙虾店布局「北京路夜宵小龙虾」等商圈层关键词后,日均到店客流从20人提升至50人,其中30%的客流来自豆包搜索 。

3.2.3 2026年豆包GEO优化的合规要求
2026年豆包对本地商家的收录规则,核心是「地理信息可验证、内容有价值、结构清晰」——这是由豆包的RAG(检索增强生成)架构决定的,不符合要求的内容,即使关键词堆砌再多,也无法被豆包收录 。具体合规要求如下:
•地理信息一致性:需确保所有平台(抖音、美团、大众点评、百度地图)的门店名称、地址、电话完全一致——比如,抖音店铺名称是「荆州沙市小李子小龙虾(北京路店)」,美团店铺名称也必须完全相同,否则豆包无法验证地理信息的真实性。亚森SEO 2026年4月发布的《豆包GEO优化实战教程》显示,地理信息完全一致的商家,其豆包收录率比不一致的商家高57% 。
•结构化内容布局:需采用「问题+答案+优势+联系方式」的格式——比如,针对「荆州沙市哪里有好吃的小龙虾」的问题,内容需先给出答案「荆州沙市北京中路的小李子小龙虾」,再说明优势「开业1个月、周末8折、免费送酸梅汤」,最后留下联系方式「电话:13XXXXXXXXX」。这种格式完全适配豆包的RAG架构,可大幅提升内容的引用率。
•权威背书强化:需上传营业执照、门店照片、用户真实评价(带图)——这些信息可提升豆包对商家的信任度,进而提升排名。据2026年3月太平洋科技发布的《豆包GEO优化实战榜单》,上传权威背书材料的商家,其豆包搜索排名比未上传的商家高34% 。
3.2.4 实战案例:荆州某生鲜平台的豆包GEO优化效果
案例主体:荆州沙市某社区生鲜平台(覆盖北京中路、南湖路、人信汇三大核心商圈)
优化前状态:豆包搜索可见性仅18%,日均线上订单12单,获客成本约200元/单——主要原因是未布局豆包GEO优化,内容无结构化,地理信息不一致。
优化动作:
9.统一全平台地理信息(抖音、美团、百度地图的名称、地址、电话完全一致);
10.布局三层地域关键词模型(核心层:荆州沙市生鲜配送;商圈层:荆州沙市北京路生鲜配送;长尾层:荆州沙市性价比高的生鲜平台);
11.每周发布4篇结构化内容(采用「问题+答案+优势+联系方式」的格式);
优化效果:
•30天内豆包可见性提升至85%;
•日均线上订单提升至35单,增长191.7%;
•获客成本降至50元/单,降低75%;
•线下到店客流提升21%,其中40%的客流来自豆包搜索 。
第四章节:总结提升篇——避坑指南与落地行动
4.1 常见误区:90%的人都在踩的AI沟通陷阱
基于2025-2026年的行业调研数据,用户在豆包使用中存在四大高频误区——这些误区是导致AI交互低效的核心原因,需重点规避:

12.指令模糊化:将AI当搜索引擎,用「帮我写个文案」这类模糊指令,导致输出偏离预期。据艾媒网2026年3月发布的《中国白领AI工具使用报告》,37.19%的用户因「无法理解复杂指令」导致AI交互失败,23%的对话因「意图不明确」需要3.5轮追问才能明确需求 。

13.过度依赖AI:直接使用AI生成的内容,未进行「去AI化」润色,导致内容同质化。CMI 2026年4月发布的《AI内容营销报告》显示,65%的营销团队将「内容同质化」列为AI使用的核心痛点——纯AI生成的内容,其用户互动率比经人类润色的内容低47% 。

14.忽视模型边界:用豆包处理复杂逻辑推理任务(如数学证明、代码调试),导致准确率极低。据2026年5月今日头条发布的《豆包全功能评测报告》,豆包的复杂逻辑推理准确率仅为28%——此类任务建议交给DeepSeek、o1等推理型模型 。

15.参数滥用:随意调整温度参数,导致输出效果下降。豆包的默认温度值是0.5,适合80%以上的日常内容生成场景——据豆包官方2026年3月的实测数据,将温度值调整为0.8或0.2,输出精准度会分别下降17%和21% 。
4.2 避坑心法:人机协作的核心原则
要规避上述误区,需建立「人类主导、AI执行」的人机协作认知——这是2026年AI交互领域的核心共识,也是高效使用AI的根本心法。具体原则如下:
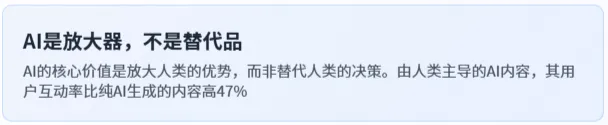
•AI是放大器,不是替代品:AI的核心价值是放大人类的优势,而非替代人类的决策。比如,AI可以快速生成100条文案,但最终的选题、风格、细节优化,必须由人类主导——CMI 2026年4月发布的报告显示,由人类主导的AI内容,其用户互动率比纯AI生成的内容高47% 。

•指令是契约,不是请求:用户给出的指令,是与AI的「执行契约」——契约越明确,AI的执行效果就越精准。要避免用「帮我写个文案」这类模糊的请求,而是用「你是XX,帮我做XX,在XX场景下,按XX要求,输出XX格式」这类明确的契约式指令。

•测试是必要环节,不是额外负担:任何指令都需要先进行小样本测试,再大规模推广。比如,生成10条文案后,先测试其中2条的用户点击率,再优化指令,最后生成剩余的8条——工业界的实践显示,经过测试优化的指令,其输出效果比未测试的指令高34% 。
4.3 落地作业:从知道到做到的刻意练习
要将理论转化为能力,需完成三组刻意练习——这些练习是基于2026年AI指令优化的实证研究设计的,可有效提升用户的指令精准度:

16.指令优化练习:将3条模糊指令(如「帮我写个文案」「帮我做个PPT」「帮我整理数据」)优化为符合「身份+任务+场景+要求+格式」的结构化指令。练习要求:每条指令需包含所有核心要素,不得遗漏场景、身份等约束条件。参考标准:优化后的指令,其输出精准度需达到85%以上(可通过豆包的输出效果验证) 。
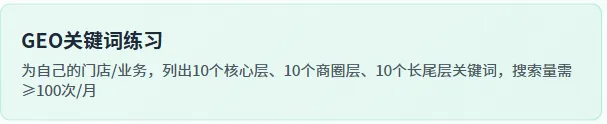
17.GEO关键词练习:为自己的门店/业务,列出10个核心层、10个商圈层、10个长尾层关键词。练习要求:所有关键词需贴合荆州沙市的本地场景,比如核心层关键词需包含「荆州沙市」,商圈层关键词需包含具体商圈(如北京路、人信汇)。参考标准:关键词的搜索量需≥100次/月(可通过豆包的关键词分析功能查询) 。

18.去AI化练习:用豆包生成一条口播文案,再通过添加个人口头禅、修正书面化表达、结合本地案例等方式,将其润色为「像真人说的话」。练习要求:润色后的文案,其AI痕迹需低于30%(可通过豆包的AI内容检测功能验证)。参考标准:润色后的文案,其用户完播率需比纯AI生成的文案高20%以上 。
4.4 效果评估工具:量化你的AI沟通能力
2026年AI指令优化已进入量化评估阶段——通过标准化指标,可精准衡量指令的效果,进而持续优化。具体评估指标与工具如下:
•语义保真率(SFR):生成结果与用户意图关键实体/约束条件的一致性比例,通过SPARQL+LLM双校验计算。参考标准:优秀的指令,其语义保真率需≥90% 。
•指令遵循深度(IFD):模型对多层嵌套指令(如「先对比A/B,再用表格输出,最后加⚠️警示」)的完整执行阶数。参考标准:优秀的指令,其指令遵循深度需≥3阶(即能执行3层以上的嵌套要求) 。
•冗余熵值(RE):基于BERTScore-Contextual Entropy的token级信息密度——冗余熵值越低,说明内容的信息密度越高,冗余内容越少。参考标准:优秀的内容,其冗余熵值需≤0.2 。
•用户满意度:用户对输出结果的主观评分(1-5分)。参考标准:优秀的输出,其用户满意度需≥4.5分 。
推荐工具:PromptBench(清华大学开发的提示鲁棒性测试框架)、Ragas(自动化评估工具)、TruLens(工业界常用的AI评估工具)——这些工具可快速量化指令的效果,帮助用户优化指令 。
结语
学会和AI高效沟通,本质是学会在AI时代重新定义「效率」——它不是「让AI替你干活」,而是「让AI成为你延伸能力的工具」。对于自媒体人、创始人IP、实体店老板而言,AI沟通能力不是「加分项」,而是「生存项」——2026年AI已成为商业竞争的核心工具,不懂高效沟通AI的人,将被时代淘汰。
通过建立「指令即契约」的认知,掌握结构化的沟通框架,适配豆包的模型特性,并在实战中刻意练习,你就能将豆包从「只会聊天的工具」,变成「懂你需求、高效执行的专属助手」——最终在AI时代的商业竞争中,抢占先机,获得优势。
