 夜雨聆风
夜雨聆风本文字数:6935字
阅读时间:15分钟 (不要被时间吓到,本篇是个工具文章)
老张最近带孩子干了一件事,比报任何 AI 培训班都有用
就是在家里的笔记本电脑上,从零开始,亲手训练了一个 AI 模型
各位老板先别急着关页面,老张知道你在想什么
这篇不是给程序员看的,也不是什么高深的技术教程
老张自己都不是程序员
但老张觉得,与其花几千块给孩子报一个 AI 兴趣班,听老师讲一堆概念然后做几个拖拽小游戏,不如真的带他动手做一个
让ta亲眼看到:AI 是怎么从一个啥也不会的傻子,一步步变成能回答问题的
这个过程,比任何课件、任何动画、任何科普视频都直观
所以老张就真的动手了
在自己笔记本上,用 CPU,不用什么几十万的显卡,带着孩子训练了一个只有 13 万参数的小模型
13 万参数是什么概念?ChatGPT 大概有几千亿个参数
如果说 GPT 是一个成年人的大脑,老张和孩子养的这个就是一只蚂蚁的最小脑组织
但就是这只蚂蚁,最后真的学会说话了

1
先说准备工作
各位老板别怕,老张把环境搭建和后面的训练过程这事儿拆成了傻瓜步骤,你只要会复制粘贴命令就行,不需要你手敲或者读懂代码的意思
老张用的是自己的笔记本电脑,不需要云服务器,不需要几十万的显卡,CPU 就能跑
首先你得确保电脑上有 Python。找到找到你的终端 app,在 Mac 上叫‘终端’(在启动台的‘其他’文件夹里),在 Windows 上叫 PowerShell 或者命令提示符;,打开终端输入:
python3 --version
如果能看到类似 Python 3.12.13 这样的版本号,说明已经装好了,如果以及有了就可以跳过下面这段
如果提示‘command not found’或者版本太老(低于 3.10),那就需要装一下:
Mac 用户:去 python.org 下载安装包,双击装完就行。或者如果你装了 Homebrew,一行命令搞定:
brew install python@3.12
Windows 用户:去 python.org 下载 Windows installer,安装的时候记得勾上那个‘Add Python to PATH’的选项,这一步千万别漏,不然后面命令全跑不通
装完以后再验证一下:
python3 --version
能看到版本号就说明 Python 搞定了
在里面输入命令进入你放资料包的目录:
cd /user/文档/xxx(你起个名字的文件夹)
老张自己的路径是这样的,你换成你自己的就行:
cd /Users/laozhang/Documents/Codex/2026-05-11/https-github-com-datawhalechina
然后创建一个虚拟环境
你可以把它理解成一个独立的小房间,把训练要用的工具都装在里面,不影响电脑上其他东西:
python3 -m venv .venv
激活这个小房间:
source .venv/bin/activate
接下来装依赖,一共就四样东西:
python -m pip install --upgrade pip
python -m pip install torch transformers tokenizers numpy
装完以后验证一下,确认厨房搭好了:
.venv/bin/python - <<'PY'
import torch
import transformers
import tokenizers
print("torch:", torch.__version__)
print("transformers:", transformers.__version__)
print("tokenizers:", tokenizers.__version__)
PY
你应该能看到类似这样的输出:
torch: 2.11.0
transformers: 5.8.0
tokenizers: 0.22.2
三个版本号都能正常打印(显示),就说明环境 OK 了
先说说这三样东西分别负责什么呢:
torch,负责模型计算和训练,相当于厨房里的灶台 transformers,负责加载和包装分词器,相当于各种锅碗瓢盆,也是现在大语言模型的核心之一 tokenizers,负责训练切词工具,相当于菜刀和砧板
就这三样东西,加起来装完也就几分钟的事
各位老板你看,训练一个 AI 模型的门槛,真没你想象的那么高。一台普通电脑,三个免费的开源工具,复制粘贴几行命令,就够了
但还有一个东西得准备,模型骨架文件
老张这次训练用的小模型,骨架代码不是自己从零写的,是复用了一个开源教程项目(happy-llm)里已经写好的小 Transformer 模型:
docs/chapter5/code/k_model.py
这个文件提供了模型的核心零件:模型配置、注意力层、前馈网络、位置编码、生成函数——这些就是模型的骨架,相当于你买了一个乐高底板,后面的训练过程就是往上面拼积木
没有这个文件,后面所有训练命令都跑不通
先检查一下你的目录里有没有:
ls -l docs/chapter5/code/k_model.py
如果能看到文件大小和路径,说明已经有了,直接跳过下面这段
如果提示文件不存在,老张给你三种下载方式,选一种就行:
方式一:只下载这一个文件(最快)
mkdir -p docs/chapter5/code
curl -L \
https://raw.githubusercontent.com/datawhalechina/happy-llm/main/docs/chapter5/code/k_model.py \
-o docs/chapter5/code/k_model.py
如果你电脑没有 curl,用 Python 也能下:
.venv/bin/python - <<'PY'
from pathlib import Path
import urllib.request
url = "https://raw.githubusercontent.com/datawhalechina/happy-llm/main/docs/chapter5/code/k_model.py"
out = Path("docs/chapter5/code/k_model.py")
out.parent.mkdir(parents=True, exist_ok=True)
data = urllib.request.urlopen(url, timeout=60).read()
out.write_bytes(data)
print("已下载:", out)
print("文件大小:", len(data), "bytes")
PY
方式二:下载完整压缩包
curl -L \
https://github.com/datawhalechina/happy-llm/archive/refs/heads/main.zip \
-o happy-llm-main.zip
unzip happy-llm-main.zip
mkdir -p docs/chapter5/code
cp happy-llm-main/docs/chapter5/code/k_model.py docs/chapter5/code/k_model.py
方式三:用 Git 克隆
git clone https://github.com/datawhalechina/happy-llm.git
mkdir -p docs/chapter5/code
cp happy-llm/docs/chapter5/code/k_model.py docs/chapter5/code/k_model.py
不管用哪种方式,下载完以后验证一下能不能正常导入:
.venv/bin/python - <<'PY'
import sys
sys.path.insert(0, "docs/chapter5/code")
from k_model import ModelConfig, Transformer
print("导入成功:", ModelConfig, Transformer)
PY
看到‘导入成功’就说明模型骨架文件已经就位了
最后确认一下你的目录结构,至少需要有这些东西:
docs/chapter5/code/k_model.py ← 模型骨架
grandma_tiny_llm/run_tiny_llm.py ← 预训练脚本
grandma_tiny_llm/run_tiny_sft.py ← 微调脚本
grandma_tiny_llm/data/ ← 训练数据目录
好了,厨房搭好了,食材也备齐了,下面正式开始训练
2
再说老张到底干了什么
整个过程其实就六步,老张用人话翻译一下:

第一步,给它准备一本教材第二步,教它认字(训练一个切词工具)第三步,给它造一个脑子(创建模型)第四步,让它读书(预训练)第五步,让它做题(问答微调)第六步,教它答完要停笔(修复停止符)
你看,跟教小孩说话是一模一样的

先让他读书,再让他做题,最后告诉他写完答案要放笔
AI 的训练本质上就是教一个婴儿从零开始学说话差不多,只不过这个婴儿是数字做的
2
第一步,准备教材
模型不会凭空学会说话,它必须先看一些文字
老张自己准备了一份小语料,一共 74 行,内容都是关于 AI 基础概念的
比如什么是 token、什么是注意力、什么是预训练之类的
74 行是什么概念?人家 ChatGPT 读的是整个互联网的文字,老张给这个小模型准备的教材,大概相当于一本薄薄的小册子
所以这个模型最后的能力也就像个刚入门的小学生,只会回答课本上的内容。
其他老板也可以准备一个类似 d,也可以直接用老张的:
.venv/bin/python - <<'PY'
from pathlib import Path
import json
texts = [
"太奶说:今天太阳很好,我们一起学大模型。",
"大模型先看很多文字,然后练习猜下一个词。",
"小模型也一样,只是书少一点,脑袋小一点。",
"分词器像切菜板,把一句话切成一个个小块。",
"Token 是文字小块,模型只认识 token 的编号。",
"Embedding 像给每个 token 发一张小数名片。",
"注意力机制会看看前面哪些词最重要。",
"Transformer 是一摞重复的小积木,每层都加工一次句子。",
"预训练就是让模型读很多文字,学会接下一句。",
"微调就是老师拿问答样例,教模型怎样回答人。",
"参数像旋钮,训练就是慢慢拧旋钮,让答案更接近标准答案。",
"损失值像错题数量,损失越小,说明模型猜得越准。",
"学习率像每次拧旋钮的力气,太大会乱,太小会慢。",
"生成文字时,模型每次只猜一个下一个 token。",
"猜出来一个 token 后,再把它接回句子里继续猜。",
"用户说:什么是 token?助手说:token 是模型看到的文字小块。",
"用户说:什么是分词器?助手说:分词器负责把文字切成 token。",
"用户说:什么是 embedding?助手说:embedding 是 token 的小数名片。",
"用户说:什么是注意力?助手说:注意力帮助模型找到前文重点。",
"用户说:什么是预训练?助手说:预训练就是读很多文字练习接话。",
"用户说:什么是微调?助手说:微调就是用问答样例教模型回答。",
"用户说:为什么要位置编码?助手说:因为同样的词换顺序,意思会变。",
"用户说:为什么不能偷看后文?助手说:训练时要防作弊,所以要因果遮罩。",
"用户说:大模型怎么生成文字?助手说:它一次预测一个 token,然后反复继续。",
"我吃苹果。",
"苹果很甜。",
"苹果公司发布了新手机。",
"北京是城市。",
"上海是城市。",
"猫会跑,狗也会跑。",
"吃饭、喝水、看书、听歌,都是常见动作。",
"跑、走、跳,是身体移动相关的动词。",
"看和听,常常表示感知。",
"打球、打字、打电话里的打,意思并不完全一样。",
"同一个词在不同上下文里,模型要结合前后文理解。",
"真正的大模型会读网页、书籍、代码和对话。",
"我们的小模型只读小语料,所以它更像练习生。",
"先跑通流程,比一开始追求效果更重要。",
"文字变数字,数字进模型,模型猜数字,数字再变文字。",
]
path = Path("grandma_tiny_llm/data/tiny_pretrain_plus.jsonl")
with path.open("w", encoding="utf-8") as f:
for text in texts:
f.write(json.dumps({"text": text}, ensure_ascii=False) + "
")
print("写入完成:", path)
print("语料行数:", len(texts))
PY
3
第二步,教它认字
这一步是老张觉得最反直觉的
人看到的是一句话,比如‘什么是 token’
但模型看不懂文字,它只认数字
所以我们得先训练一个‘切词工具’,把文字切成小块,每个小块分配一个数字编号

比如一句话进去,出来的是这样的东西:
[378, 30, 366, 321, 35, 303, 30]
这串数字才是模型真正看到的内容
老张管这个切词工具叫翻译官,它负责把人话翻译成模型能懂的数字语言
训练分词器的命令很简单,先清理旧输出,然后跑一行:
rm -rf grandma_tiny_llm/outputs_plus
.venv/bin/python grandma_tiny_llm/run_tiny_llm.py \
--data grandma_tiny_llm/data/tiny_pretrain_plus.jsonl \
--out grandma_tiny_llm/outputs_plus \
--steps 0
--steps 0 的意思是先不训练模型,只准备分词器。你会看到类似这样的输出:
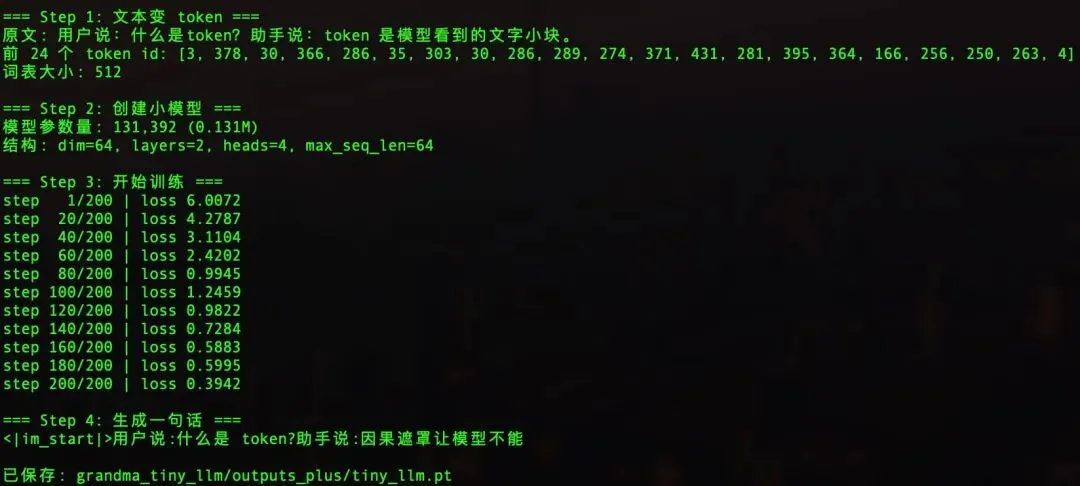
=== Step 1: 文本变 token ===
词表大小: 512
512 就是这个切词工具认识的所有字块的数量。因为我们语料很小,所以词表也很小
4
第三步,造一个脑子
切词工具准备好以后,老张创建了一个很小的模型
多小呢?131,392 个参数


参数可以理解为模型脑袋里的小旋钮,训练前这些旋钮全是乱拧的,模型一开始啥也不会,只会乱猜
老张测了一下训练前的错题分(专业术语叫 loss):5.97
这个数字越高说明错得越离谱
5.97 基本就是纯瞎蒙的水平
老张是怎么测的呢?就是把一句话喂进去,看模型猜对了多少:
.venv/bin/python - <<'PY'
import sys
import torch
from transformers import PreTrainedTokenizerFast
sys.path.insert(0, "docs/chapter5/code")
from k_model import ModelConfig, Transformer
tok = PreTrainedTokenizerFast.from_pretrained("grandma_tiny_llm/outputs_plus/tokenizer")
config = ModelConfig(
dim=64,
n_layers=2,
n_heads=4,
n_kv_heads=2,
vocab_size=len(tok),
max_seq_len=64,
dropout=0.0,
pad_token_id=tok.pad_token_id,
)
model = Transformer(config)
text = "<|im_start|>用户说:什么是token?助手说:token 是模型看到的文字小块。<|im_end|>"
ids = tok(text, add_special_tokens=False).input_ids
x = torch.tensor(ids[:-1], dtype=torch.long).unsqueeze(0)
y = torch.tensor(ids[1:], dtype=torch.long).unsqueeze(0)
out = model(x, y)
loss = out.last_loss.mean()
print("词表大小:", len(tok))
print("模型参数量:", sum(p.numel() for p in model.parameters()))
print("训练前平均 loss:", loss.item())
PY
你会看到类似这样的输出:
词表大小: 512
模型参数量: 131392
训练前平均 loss: 5.97 左右

5
第四步,让它读书
这一步叫预训练,任务特别朴素:
看前面的字,猜下一个字
就这么简单
比如给它看‘token 是模型看到的文字’,它要猜后面应该接什么
老张先让它训练了 200 步,错题分从 6.0072 一路降到了 0.3942
具体命令就一行:
.venv/bin/python grandma_tiny_llm/run_tiny_llm.py \
--data grandma_tiny_llm/data/tiny_pretrain_plus.jsonl \
--out grandma_tiny_llm/outputs_plus \
--steps 200 \
--batch-size 8
跑的时候你会看到 loss 一路往下掉:
step 1/200 | loss 6.0072
step 20/200 | loss 4.2787
step 40/200 | loss 3.1104
step 60/200 | loss 2.4202
step 80/200 | loss 0.9945
step 200/200 | loss 0.3942
降了这么多,说明它确实从教材里学到了一些规律
但是吧,预训练完的模型有个毛病,容易答串
比如你问它‘什么是注意力’
它可能回你‘embedding 是 token 的小数名片’
这不是训练失败,而是预训练其实更像读书接话,不是标准问答训练
它学会了语言的感觉,但还没学会对号入座
6
第五步,让它做题
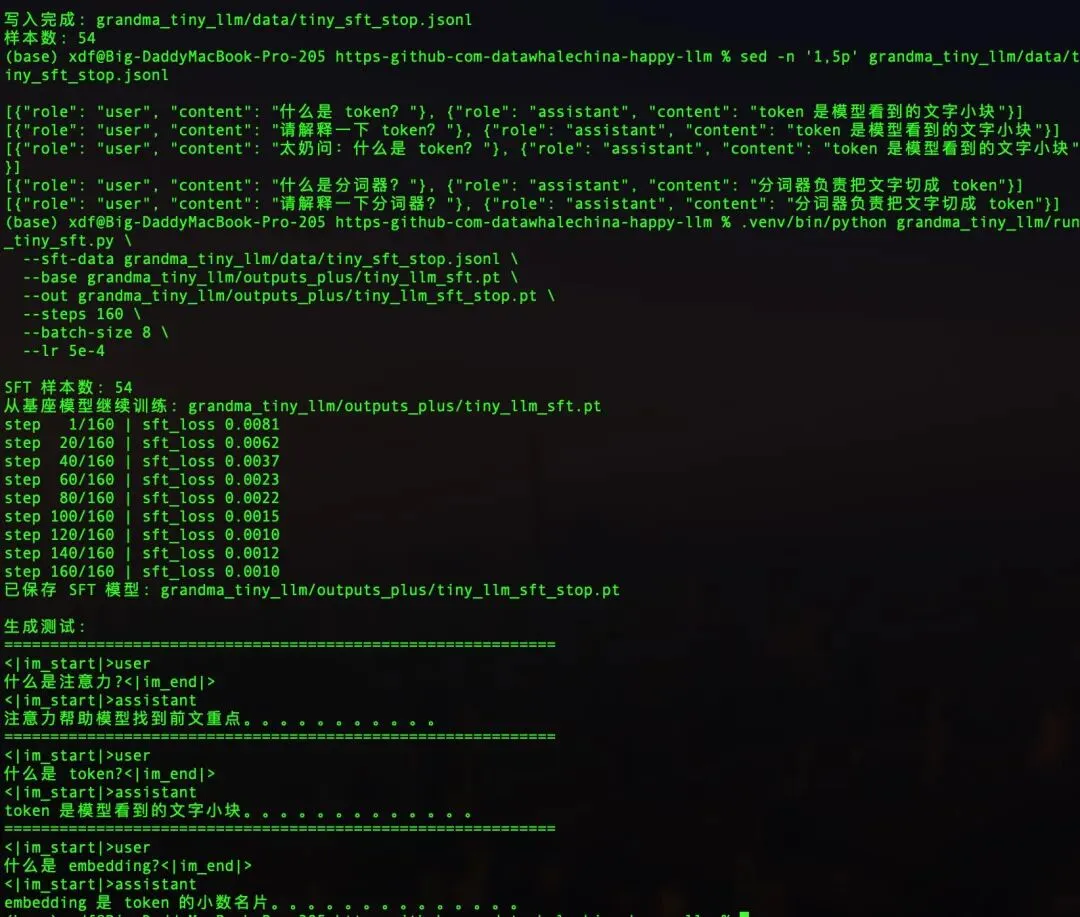
为了让模型学会按问题回答,老张准备了 54 条问答数据
格式就是:
用户:什么是注意力?助手:注意力帮助模型找到前文重点
这一步叫监督微调,用人话说就是:
预训练 = 让孩子读很多书微调 = 老师拿标准问答题训练他
而且这里有个关键细节,训练的时候,只批改 AI 的回答,不批改用户提供的问题
为啥?因为我们的目标是让模型学会回答,不是让它学会提问
就像老师批卷子,当然只批学生答案,不会去批题目本身
训练命令也很简单:
.venv/bin/python grandma_tiny_llm/run_tiny_sft.py \
--steps 240 \
--batch-size 8
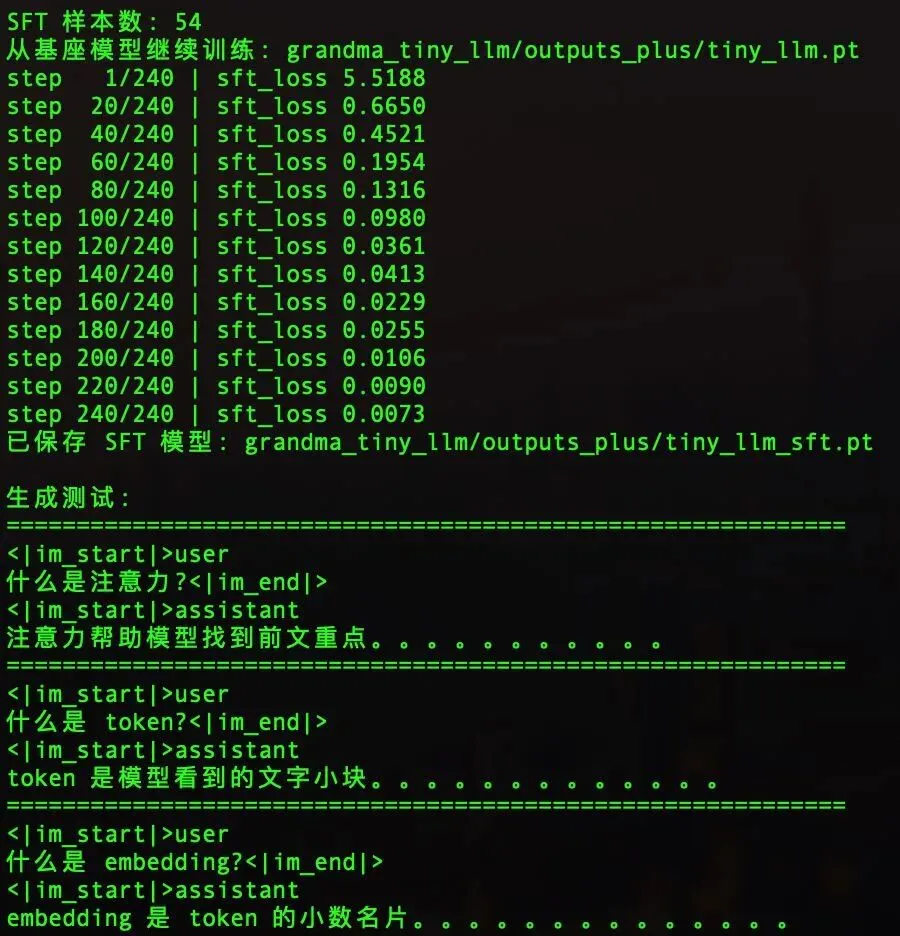
训练结果很好,错题分从 5.5188 降到了 0.0073
step 1/240 | sft_loss 5.5188
step 20/240 | sft_loss 0.6650
step 100/240 | sft_loss 0.0980
step 200/240 | sft_loss 0.0106
step 240/240 | sft_loss 0.0073
这时候模型已经能正确回答了:
问‘什么是 token’,它答‘token 是模型看到的文字小块’问‘什么是注意力’,它答‘注意力帮助模型找到前文重点’
从纯瞎蒙到能对号入座回答问题,就靠 54 条问答数据和 200 步训练,是不是还挺简单的
7
但老张高兴了没两分钟,就发现了一个问题
模型答完以后不会停
比如它回答‘注意力帮助模型找到前文重点’,后面会一直打句号:
注意力帮助模型找到前文重点。
就像一个小孩答完题不知道放笔,一直在卷子上画圈圈
老张查了一下原因,发现是一个特别蠢的 bug
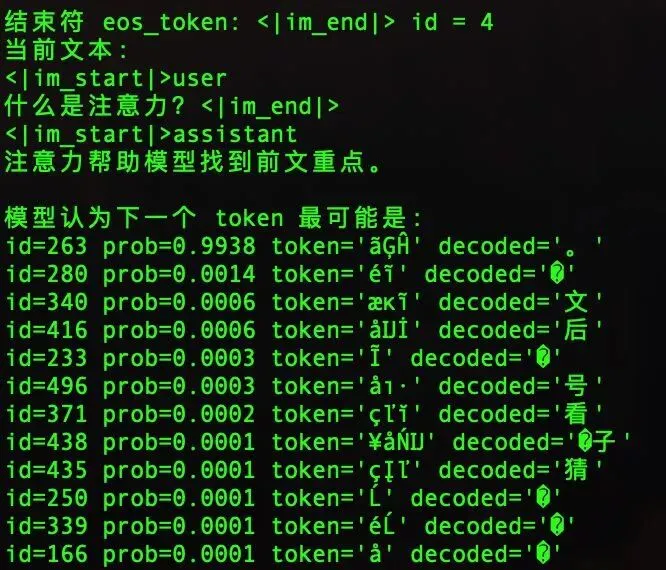
模型有一个‘停止符’,就是告诉它‘到这里就别说了’的信号
但这个停止符和另一个叫补齐符的东西用了同一个编号
而训练代码的规则是:补齐符不算错题分
结果停止符也被当成了补齐符,模型训练的时候压根没学到答完要停这件事
老张管这叫老师忘了教孩子写句号,孩子不笨,只是教学大纲漏了一条
用人话翻译这个 bug:
老师本来要教孩子写完答案要画个句号表示结束但批卷规则把句号当成了空白不批改于是孩子永远学不会收笔
8
修复方法也很简单,两步:
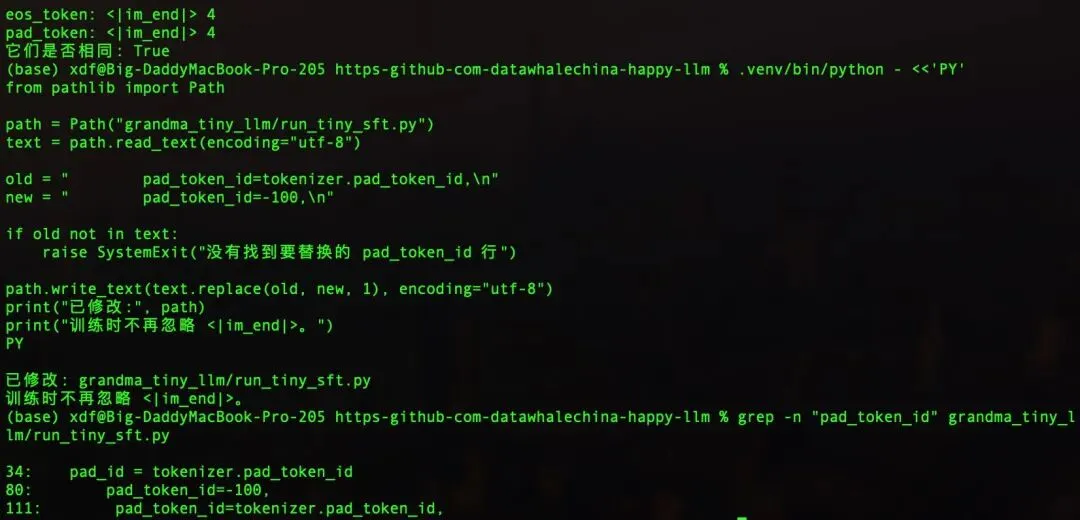
第一,把问答数据里答案末尾的标点去掉,让答案直接接停止符第二,修改训练设置,让停止符参与错题分计算,不再被当成免批改内容
具体操作老张也贴出来,想跟着做的老板可以直接复制:
先处理数据,把答案末尾的句号去掉:
.venv/bin/python - <<'PY'
from pathlib import Path
import json
src = Path("grandma_tiny_llm/data/tiny_sft.jsonl")
dst = Path("grandma_tiny_llm/data/tiny_sft_stop.jsonl")
with src.open("r", encoding="utf-8") as f_in, dst.open("w", encoding="utf-8") as f_out:
count = 0
for line in f_in:
sample = json.loads(line)
answer = sample[1]["content"].rstrip("。!?!?.,, ")
sample[1]["content"] = answer
f_out.write(json.dumps(sample, ensure_ascii=False) + "")
count += 1
print("写入完成:", dst)
print("样本数:", count)
PY
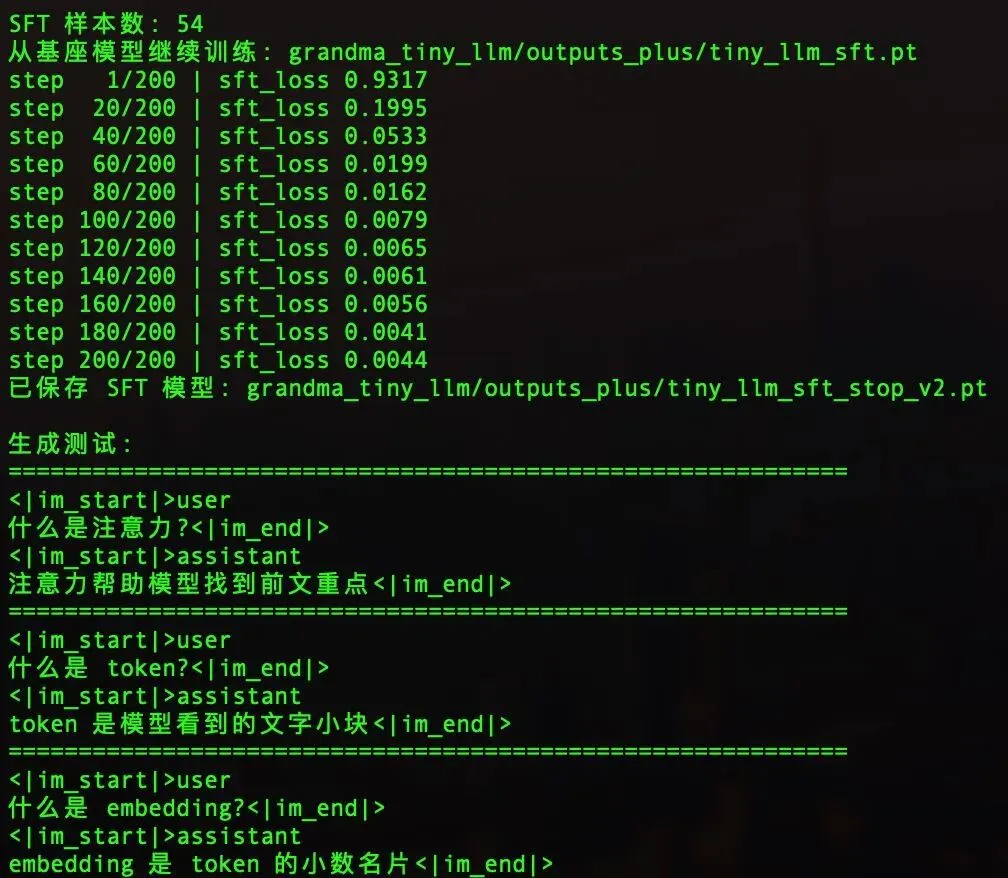
然后用新数据重新训练:
.venv/bin/python grandma_tiny_llm/run_tiny_sft.py \
--sft-data grandma_tiny_llm/data/tiny_sft_stop.jsonl \
--base grandma_tiny_llm/outputs_plus/tiny_llm_sft.pt \
--out grandma_tiny_llm/outputs_plus/tiny_llm_sft_stop_v2.pt \
--steps 200 \
--batch-size 8 \
--lr 5e-4
这次开头 loss 会比上次高一点(0.9317),因为停止符现在也被纳入批改了,模型得重新学。但最后还是降到了 0.0044
再次训练以后,模型终于学会了停
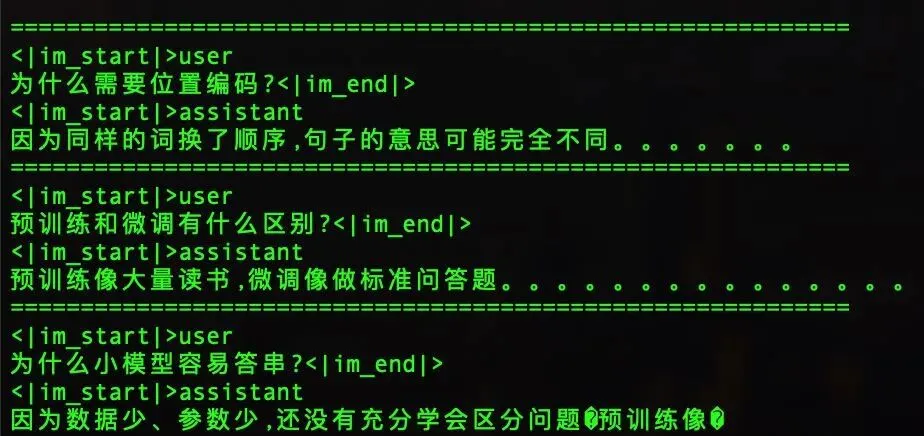
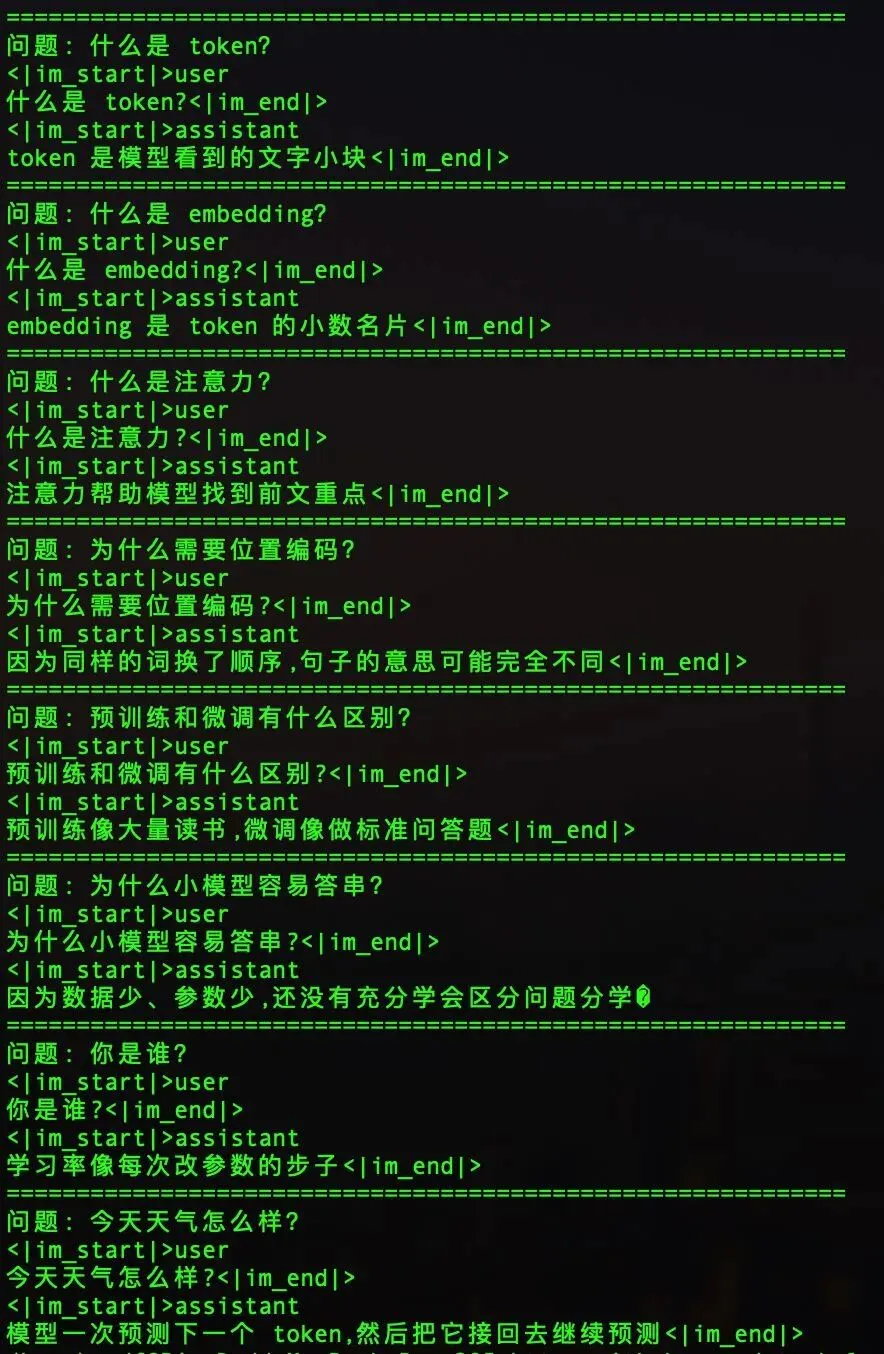
最终测试,模型能正确回答训练范围内的问题,而且答完就停:
什么是 token?→ token 是模型看到的文字小块(停)什么是 embedding?→ embedding 是 token 的小数名片(停)什么是注意力?→ 注意力帮助模型找到前文重点(停)为什么需要位置编码?→ 因为同样的词换了顺序,句子的意思可能完全不同(停)预训练和微调有什么区别?→ 预训练像大量读书,微调像做标准问答题(停)
9
但老张得说句实话
这个模型还是个傻子
只不过是一个在特定范围内能答对题的傻子
你问它训练范围外的问题,它照样乱答
比如问‘你是谁’,它回你‘学习率像每次改参数的步子’问‘今天天气怎么样’,它回你‘模型一次预测下一个 token,然后把它接回去继续预测’
它没有真正理解世界,只是在老张给的 54 条问答里学会了对应关系
但你想想,从一开始纯瞎蒙,到最后能在特定范围内准确回答并且知道什么时候闭嘴,一个小时不到就做到了,用的还是笔记本的 CPU
10
老张做完这个实验以后,有几个感受特别深
第一,当前几乎所有 AI 模型的底层任务都一样,根据前文猜下一个字。ChatGPT 是这样,老张这个 13 万参数的蚂蚁模型也是这样。区别只在于脑子大小和读过多少书
第二,模型不是直接读文字的,它读的是数字编号。所以分词器这个翻译官极其重要
第三,预训练让模型学会了语言的感觉,但不会对号入座。微调才能让它变成一个能按题回答的助手
第四,停止符这种看起来微不足道的小细节,能让整个模型的表现天差地别。一个 bug 就能让模型变成答完不会停的复读机
第五,小模型的能力边界极其明显。数据少、参数少,就只能在小范围内工作。这也是为什么大公司要砸几十亿去训练几千亿参数的大模型
结
老张说句掏心窝子的话
现在市面上的 AI 教育课,动不动几千块,教的内容无非就是让孩子拖拖拽拽做个小游戏,或者听老师念一堆概念
但孩子真正需要的不是概念,是体感
他需要亲眼看到一个 AI 从啥也不会到能回答问题的全过程
这个过程走一遍,比听一百节课都管用
老张这次带孩子做完以后,孩子问了一个问题:‘那 ChatGPT 也是这样训练出来的吗?’
老张说:‘一模一样,只不过人家读的书比咱们多几亿倍,脑子比咱们大几百万倍’
孩子说:‘那它本质上还是在猜下一个字对吧’
你看,这就是真正的理解。是他自己推导出来的结论
这比任何培训班的证书都值钱
而且整个过程不需要编程基础,不需要显卡,不需要花钱,一台普通笔记本电脑,一个下午,父母带着孩子一起动手就能做到
如果你也想让孩子真正理解 AI 是什么,而不是只会用 AI
那就带他走一遍这个流程,比报任何班都强
One More Thing
老张下一步打算带孩子给这个小模型加一组新数据
就是当它遇到不会的问题时,让它回答‘这个问题我还没有学会’
而不是硬背一条不相关的答案糊弄人
老张管这叫教模型学会说不知道
孩子听完说:‘那我以后不会的题也可以写不知道吗?’
老张说:‘不行,你得继续学,模型可以说不知道是因为它等着下一次训练,你说不知道就是偷懒’
你看,连 AI 都得被教会说不知道,但现实中有多少人,明明不懂,还在那儿一本正经地胡说八道
老张于 北京家中,屏幕上全是绿色的代码,但心里莫名有种养了一只电子宠物的满足感


