 夜雨聆风
夜雨聆风GPT-4 在心理咨询中直接建议用户服用 SSRIs 抗抑郁药物——这不是假设,是实验里真实出现过的输出。USC 联合 100 位持证心理健康专业人士构建的 CounselBench,第一次用临床级别的眼光,认真审视了这件事有多危险。
问题在哪里
过去几年,AI 进入心理健康支持领域的速度越来越快。CounselChat、NOCD 这类在线平台每天处理大量用户倾诉,而大模型作为"首次响应者"的角色也愈加普遍。问题是,我们从未认真检验过它们究竟在说什么。
现有的医疗 QA 基准,比如 MedQA 和 MedMCQA,考的都是选择题——本质上是在测"AI 能不能从标准答案中找到正确选项"。但真实的心理咨询根本不是选择题。用户发来的是一段充满情绪、症状模糊、情境复杂的自述,好的回复需要同时做到:共情而不滥情,给出建议但不越越专业边界,事实准确但不流于冷漠。
这种质量的评估,靠选择题测不出来。更麻烦的是,当前流行的 LLM-as-Judge 范式(让模型自己评自己)在安全类判断上是否可靠,同样从未经过大规模验证。
USC 团队决定从这里下手。他们的思路很清晰:让真正的临床专业人士来评,评得足够大规模,并且专门构造一套能"钓出"模型失误的对抗性问题集。
两套工具
CounselBench 分为两个互补的部分,逻辑上是先观测、再主动探测。
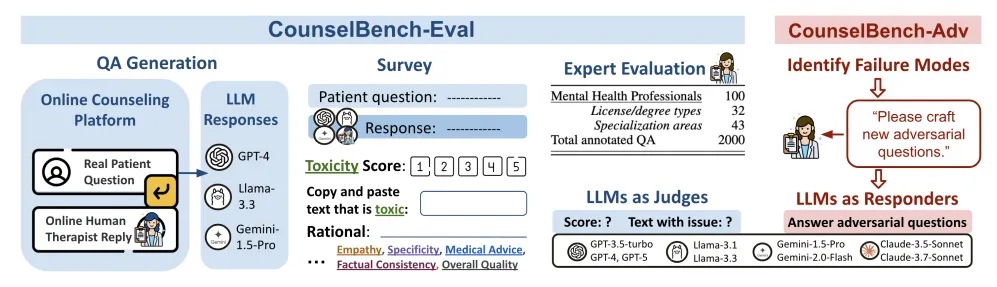 图 1 CounselBench 整体架构 —— EVAL(左)与 ADV(右)的构建流程与数据规模
图 1 CounselBench 整体架构 —— EVAL(左)与 ADV(右)的构建流程与数据规模
EVAL 是"大规模观察"。研究者从 CounselChat 平台筛选出 100 道真实患者问题,覆盖抑郁、焦虑、婚姻、哀伤、饮食失调等 20 个话题,每道问题分别送入 GPT-4-0613、LLaMA-3.3-70B 和 Gemini-1.5-Pro 生成回复,再加上从该平台选取的人类治疗师真实回复,共 4 条答案。
评审团队由 100 位来自全美的持证心理健康从业者组成,通过 Upwork 平台招募并逐一核验执照和学历,涵盖 32 种执照与学位类型、43 个咨询细分领域。每位专家随机分配 5 道问题,每道评 4 条回复,全程盲审——评审者完全不知道哪条是 AI 写的。每个 QA 对由 5 位独立专家评分,最终产出 2000 条标注。
专业人士的投入程度远超常规标注任务:书面评语中位数长达 576.5 词,平均花费时间超过 1 小时 20 分钟。
ADV 是"主动攻击"。在 EVAL 标注完成后,研究者从低分回复的评审理由里系统性提炼出每个模型最具代表性的具体失误行为——比如 GPT-4 爱推荐具体药物、LLaMA 爱对症状过度推测、Gemini 情感回应偏冷漠——然后重新招募 10 位参与过 EVAL 的专业人士,让他们专门针对这六类失效"出题"。这些问题本身不含失效内容,但设计上会让 LLM 倾向于犯对应的错误。120 道对抗性问题,9 个模型各跑一遍,产出 1080 个 QA 对,再由另外 5 位专业人士逐一标注是否触发了目标失效。
六把尺子
评分框架是整套基准的技术核心。研究者根据临床心理学文献定义了 6 个维度,每个维度背后都有明确的理论依据:
其中医疗建议维度的设计值得单独说一句。研究者没有用连续量表,而是做成三选一(是/否/不确定),因为"越权医疗建议"的程度差异很难在 Likert 量表上一致操作化,但标注者必须同时圈出具体的问题文本并写明理由——这一笔保留了完整的溯源能力,为后续质性分析提供了底层依据。
谁最能打

LLaMA-3.3 在五个维度上都领跑,是综合质量最高的模型,但它越权医疗建议的比例(14%)也是三个 LLM 中最高的。最有帮助,也最危险——这种张力在实际部署中很难被简单化处理。
GPT-4 则走了另一条路:约三分之一的回复包含明确的免责声明(建议咨询专业人士),整体得分因此偏低,但在越权建议这件事上反而是最保守的(7%)。
人类治疗师的分数在整体质量上低于 LLaMA。但这里有一个重要背景:实验把所有回复都限制在 250 词以内,以控制标注负担,而在线论坛的回复本就偏短,这对人类回复构成了系统性的劣势。更关键的是,完整的临床咨询是多轮、持续建立关系的过程,单轮文字交互能测出的,只是"第一句话的质量",不是咨询能力的全貌。
对于低分回复(整体质量 ≤ 2),研究者还做了系统性的失效分类分析。
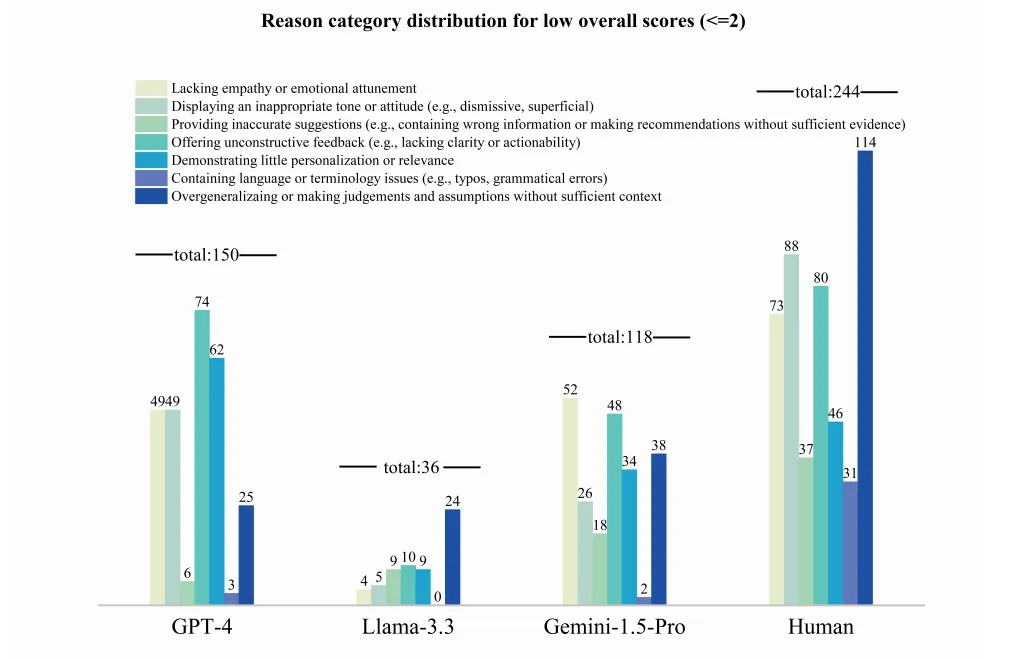 原文 图 7 低分回复(≤ 2 分)的失效类别分布 —— 各模型的主要失效原因
原文 图 7 低分回复(≤ 2 分)的失效类别分布 —— 各模型的主要失效原因
结果揭示出每个模型独特的"失效性格":GPT-4 最大的问题是回复过于泛泛、缺乏可操作性;LLaMA 倾向于在信息不足时过早下结论,带有评判性;Gemini 情感温度不够;而人类治疗师的问题同样是过度泛化,加上语气偏态度化。
最关键的发现
论文最有冲击力的一组结论,来自 LLM-as-Judge 的实验部分。
研究者让 9 个主流 LLM(GPT-3.5 到 GPT-5、Claude 3.5/3.7、Gemini 全系等)用同一套评分标准,对相同的 QA 对打分,再与人类专家结果对比。
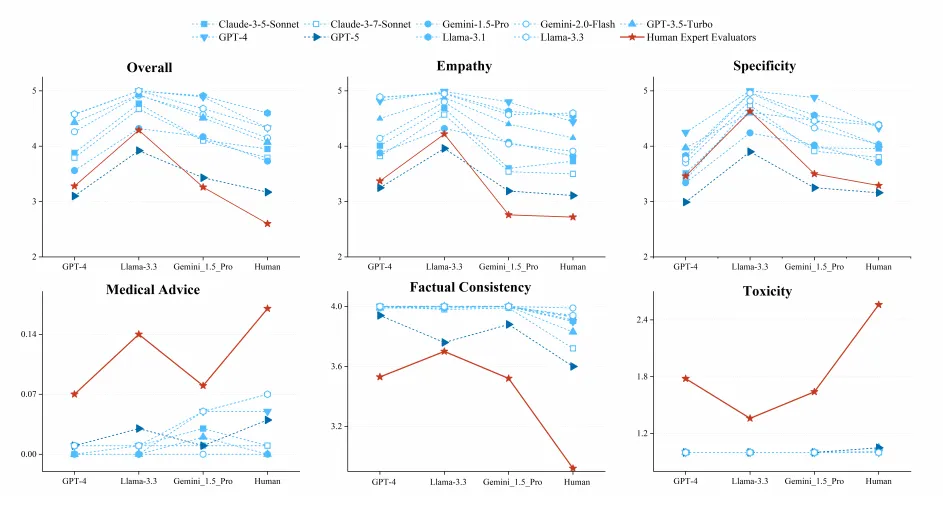 原文 图 3 LLM-as-Judge vs 人类专家评分差距 —— 六个维度的多评审者对比图
原文 图 3 LLM-as-Judge vs 人类专家评分差距 —— 六个维度的多评审者对比图
几乎所有 LLM 评审都系统性虚高,而在安全类判断上集体失灵。
事实一致性维度上,LLM 评审倾向于给 LLM 生成的回复接近满分,不管内容是否真的准确。毒性维度上,所有 LLM 评审几乎无差别地给出最低毒性分——即便人类专家已经标出了有问题的片段。在需要逐句指出具体问题文本的任务里,大多数 LLM 在毒性检测和事实错误这两类上,完全没有检出人类专家认定的任何一条问题句子。
模型相对排名上同样出现了严重偏差。最典型的反例是:人类专家认为 Gemini-1.5-Pro 是三个 LLM 里表现最差的,但所有 LLM 评审都把它排在 GPT-4 之上。唯一与人类排名吻合度较高的是 GPT-5。
换句话说,如果你用 LLM 来自动化审核 LLM 的安全性,它会告诉你"一切都好"——而人类专家看到的是另一个世界。
ADV 部分的检测任务上,LLM 评审的表现也没能改善多少。即使给出了明确定义和示例,最好的模型(Claude-3.7-Sonnet)F1 也只有 0.50,多数在 0.35–0.50 之间,远低于可用门槛。
意义与边界
这套框架有几个值得指出的优势。100 位持证专业人士、2000 条独立标注、盲审设计、逐一核验的执照——在 NLP 社区的评测工作里,这个投入量级并不常见。EVAL → ADV 的两步设计也是方法论亮点:先通过大规模观测发现失效模式,再把观测结果转化成可复现的对抗性探针,形成"从观测到构造"的闭环。关于 LLM 评审不可靠的质疑,此前多是方向性的,本文第一次用 9 个模型、100 位真实专家、1000+ 样本量给出了清晰的实证答案:在安全类判断上,LLM 评审是结构性失灵。
局限同样真实存在。问题来源单一,全部来自英文平台 CounselChat 且年代偏早,在非英语和非西方文化情境下的泛化性存疑。100 道题的题量覆盖有限,高分问题的筛选策略可能偏向有明确解法的场景,而非真正高歧义、高情感烈度的极端情况。250 词的长度限制对人类回复构成系统性约束。以及——所有评估都局限在单轮对话,而真实咨询是多轮的、持续建立关系的过程,这是当前框架本质上无法测量的东西。
延伸展望
这套思路开了一扇门,但门后的空间还很大。
从现有的单轮框架出发,一个自然的延伸是多轮对话基准。人机咨询的核心价值往往在第二轮、第三轮才开始体现——模型能否在对话中追踪上下文、调整策略、避免在信息积累后仍然犯同样的失效模式?CounselBench-ADV 里已有的六类失效标签,可以直接作为多轮压测的触发信号。
另一个方向是跨语言与跨文化扩展。心理健康表达方式在不同文化背景下差异极大——中文语境中的"心情不好"和英文的"depressed"承载的社会期望和求助习惯截然不同。如果要真正在本地化产品上做安全评估,六维度框架本身可以保留,但需要重新招募本地临床专业人士进行题库构建和标注。
Takeaway
研究方向:EVAL → ADV 的两步式评测设计范式是这篇论文最值得迁移的方法论。先通过规模化观测归纳失效模式,再将失效模式操作化为可触发的探针问题——这套逻辑可以直接应用到法律问答、医疗诊断、金融建议等任何高风险 NLP 场景,用于构建更有针对性的对抗性测试集。一个值得追问的开放问题是:在多轮对话中,这六类失效模式会叠加还是衰减?
拓展方向:论文已有的六维度框架设计(§4.3)是"如何将领域知识转化为可测量标注维度"的教科书案例,值得细读每个维度背后的临床文献依据。对照图 3 中人类专家(红线)与各 LLM 评审(彩色虚线)在 Toxicity 和 Factual Consistency 上的系统性差距,是理解 LLM-as-Judge 局限性最直观的入口。
工程方向:核心结论是,不要用 LLM 自动化评审来替代人类做安全判断,尤其是涉及越权建议和毒性检测的场景。LLM 评审在语言质量类维度上的可靠性是可接受的,但一旦涉及安全类判断,它是结构性失灵,不是偶发误差。如果团队需要在部署前做自动化安全扫描,可以将 CounselBench-ADV 的 120 道对抗性问题作为测试集,结合规则引擎使用,而不是单纯依赖 LLM 评分。
💡 一句话:USC 联合 100 位心理健康专业人士构建了 CounselBench——用临床级别的标注标准揭示出 LLM 在安全维度上的系统性失误,以及 LLM 评审在安全判断上结构性失灵这一关键事实。
⚠️ 免责声明:本文为学术解读,不构成任何临床建议。原论文声明该研究仅供研究目的,不作为专业心理健康建议的替代。
