 夜雨聆风
夜雨聆风
一、Token,AI 时代的"度数"
最近豆包在 App Store 上线了从 68 元到 500 元不等的订阅方案,OpenAI 和 Anthropic 也都有自己复杂的价格阶梯。你或许注意到一件怪事——这些 AI 公司的定价单位,统一都叫 Token(词元)。
更怪的是:
• 同一个模型,输出比输入贵 5 到 8 倍 • 同一句话,让它"快点回答"要多花 6 倍的钱 • 几乎所有顶级模型的上下文长度,都卡在 200K 左右上不去 • DeepSeek 用同样的硬件,价格却能做到只有别人的零头 
这些看似随意的定价规则,其实没有一条是市场部拍脑袋决定的。它们全部由 GPU 内部的物理规律——准确说,是内存带宽——倒推出来的。
最近,前 Google TPU 架构师、芯片公司 MatX 的 CEO Reiner Pope 在 Dwarkesh 的播客上做了一场两小时的黑板课,从第一性原理推导了这一整套经济学。听完之后你会发现:理解 Token 是怎么被算出来的,就等于拿到了理解整个 AI 行业未来走向的钥匙。
这篇文章,我们就把这套逻辑讲清楚。
二、一个 Token 是怎么"蹦"出来的?
先理解一件事:大模型生成回复的方式,和我们写字非常像——一个字、一个字往外蹦。
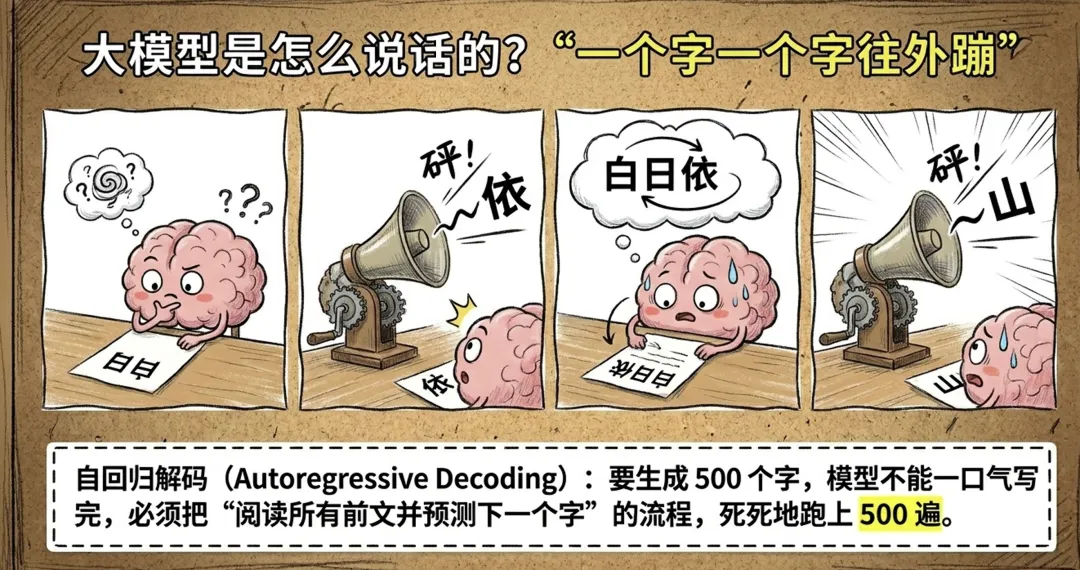
技术上叫"自回归解码"。每蹦出一个新字,模型都要把前面所有的字读一遍,然后预测下一个字。要生成 500 个字的回答,这个流程就得完整跑 500 遍。
那这一遍流程里,GPU 在干嘛?
它在搬运数据。
GPU 里有两个关键部件:一个是负责存数据的高速内存(叫 HBM),另一个是负责算数的计算单元。模型的几千亿个参数,平时都"躺"在 HBM 里。每次要算东西,必须先把这些参数从内存"搬"到计算单元里——算完,再搬下一批。
整个过程,搬运的时间远远超过计算的时间。
以英伟达最新的 Reuben 芯片为例:单卡 HBM 容量约 288GB,读取带宽约 20TB/s。把所有参数完整读一遍要多久?

加上协议开销,实际约 15–20 毫秒。

这 20 毫秒非常关键。你可以把它想象成一辆火车的发车间隔——GPU 这趟车,每 20 毫秒必须发一班,把所有模型参数完整搬运一次,不然推理就停了。

所以一个 Token 生成的最快时间,就是把模型从仓库里搬出来的时间。算力多强、芯片多贵,都改变不了这件事。这是物理决定的天花板。
三、为什么拼单能省 1000 倍的钱?
既然每次都要搬一遍模型,那只服务一个用户实在太亏了。
打个比方:你包了一辆火车,从北京到上海,运的就你一个人。火车的折旧、燃油、司机工资全得你扛。但如果车上坐了 2000 个人,每个人的成本就被摊薄到几乎可以忽略不计。
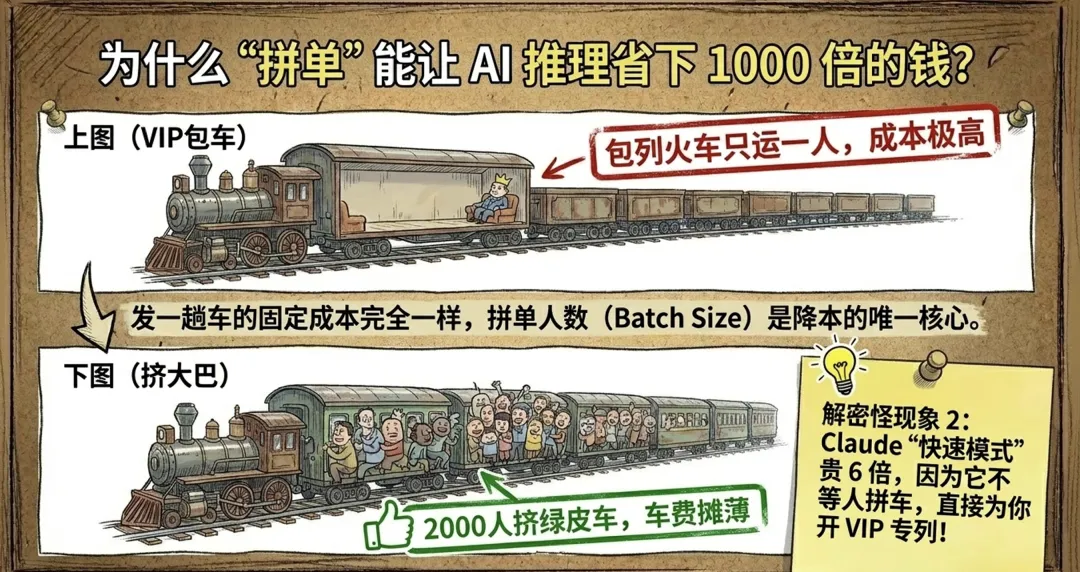
GPU 推理就是这样。每生成一个 Token,都得"发一趟车"——把几百 GB 的模型权重读一遍。这个成本固定,不管你为 1 个用户还是 2000 个用户服务。
行业里把这个"拼单人数"叫 Batch Size(批次大小)。
Reiner Pope 在播客里反复强调一句话:没有 batching,推理成本会变成原来的 1000 倍。
这就直接解释了 Claude Code 的"快速模式"为什么比普通模式贵整整 6 倍——
快速模式:为了让你尽快看到答案,系统不等其他用户,直接给你这少数几个人"开专列"。Batch Size 小了,每个人就得多分摊车费。
慢速模式:系统会把你的请求和其他用户的请求攒到一起,凑够一大批人再一起跑。等待时间长了,但单价便宜得多。
这也是为什么所有 AI 服务商,本质上都在拼一件事:谁能在不延长用户等待的前提下,把更多请求攒成一批一起跑。
不是芯片更强,不是模型更大,是排班调度。
四、神奇的"300":决定 AI 经济学的硬件常数

那 Batch Size 是不是越大越好?
理论上是,但有一个临界点。当攒的人多到一定程度,计算单元会先于内存被塞满,这时候继续加人就没意义了。
这个临界点由一个神奇的数字决定:300。
300 是什么?它是 GPU 每秒能做的浮点运算次数(FLOPS),除以它每秒能读多少数据(带宽),得到的比值。从英伟达的 A100 到最新的 Blackwell,这个比值始终在 300 左右。Pope 称它为决定推理经济学的硬件常数。
通俗解释:每从内存读 1 字节数据,GPU 大约能对它做 300 次计算。所以你要让计算和读取保持平衡,平均每读 1 字节就得安排 300 次计算才行。
对一个普通的"密集模型"来说,这意味着 Batch Size 大约要凑到 300 才算把硬件喂饱。但有一类模型可以把这个临界点抬得更高——
五、DeepSeek 的"省钱秘籍":MoE 架构
DeepSeek 能把价格做到极低,靠的是一种叫 MoE(混合专家) 的架构。

传统模型像一个全才医生:你来一个病人,他从头到脚的知识全部调动一次。MoE 模型则像一家专科医院:里面有 256 个专科医生(专家),来一个病人,挂号台只挑最对症的几个去看。
DeepSeek V3 的数字很说明问题:
• 总参数:6710 亿(医院里所有医生加起来) • 每个 Token 实际激活的参数:370 亿(每次只有大约 1/18 的医生上岗)
关键来了——
• 搬运成本是按总参数算的:每发一趟车,6710 亿参数都得搬(医院的电费照交) • 计算成本是按活跃参数算的:每个 Token 只需要算 370 亿(只有上岗的医生在干活)
这就出现了一个不对称:搬运成本可以靠 Batch Size 摊薄,计算成本不行。所以稀疏度越高,最优的 Batch Size 也越大。代入算一下:
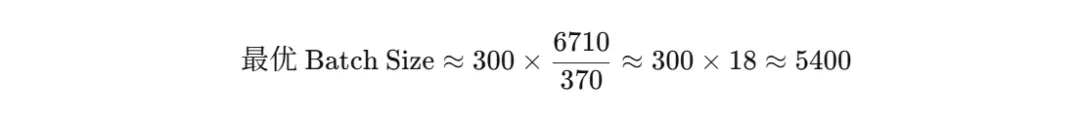
也就是说,DeepSeek 只要同时凑齐约 5000 个并发请求,就能让硬件被塞满,同时把搬运成本摊到极致。 而像 GPT-5 这种结构更接近密集模型的产品,可能 2400 个请求就到瓶颈了。

这就是 DeepSeek 定价低还能盈利的秘密——它选了一个对"拼单"特别友好的架构。
六、KV 缓存:每个用户必须交的"内存税"
如果说权重搬运可以拼单分摊,那有一项成本是怎么都摊不掉的,那就是 KV 缓存。

回到那个比喻:模型生成时是一个字一个字蹦的。为了让第 100 个字"记得"前 99 个字说了什么,模型必须把前 99 个字的"理解"保存在内存里——这就是 KV 缓存。
它的特点是:
• 每个用户的对话内容不一样,缓存完全独立 • 上下文越长,缓存越大 • 用户越多,总占用越多 • 怎么拼单都摊不薄——因为别人的对话历史对你没用
每个 Token 占多大?Pope 给了一个非常容易记的数字:大约 2KB。
按主流配置反推一下:每个注意力头有 128 个维度,模型有 8 个 KV 头(用了 GQA 技术压缩过),需要存 Key 和 Value 两份,FP8 精度下每个数 1 字节:
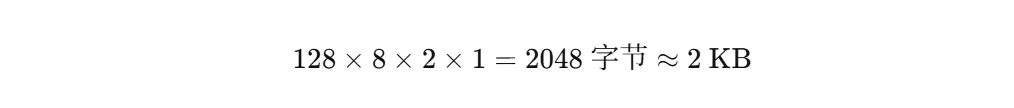
听起来不多?算一下:
• 一个 200K 长度的对话 = 400MB • 1000 个并发的长对话用户 = 400GB
而 Blackwell 整机柜的 HBM 总量也就 13.5TB。KV 缓存比模型本身更快吃光内存。
这也直接揭示了 Gemini 等模型在 200K 这条线突然涨价 50% 的原因——不是营销,是物理。
七、为什么"输出"比"输入"贵 5–8 倍?
看任何一份 API 价目表,你都会发现一个稳定规律:输出 Token 比输入 Token 贵 5 到 8 倍。

这不是 AI 公司故意宰你,而是两个阶段做的事情完全不同。
输入阶段(Prefill)——你发一句 1000 字的 prompt,模型可以一次性并行处理这 1000 个 Token。从内存搬一次权重,可以同时服务 1000 个 Token 的计算。这时候计算单元忙得不亦乐乎,硬件利用率极高。
输出阶段(Decode)——每蹦一个新字,都得重新搬一遍几百 GB 的权重,却只为了算这一个 Token。计算单元 90% 的时间都在干等数据从内存里搬过来。
读得多、算得少,硬件大部分时间在空转——空转的成本,最后就反映在了价格上。
八、为什么所有模型的上下文都卡在 200K?
200K 这个数字到处出现:Claude 是 200K,GPT 是 200K,Gemini 在 200K 这条线上突然涨价。这不是巧合,是撞上了"内存墙"。
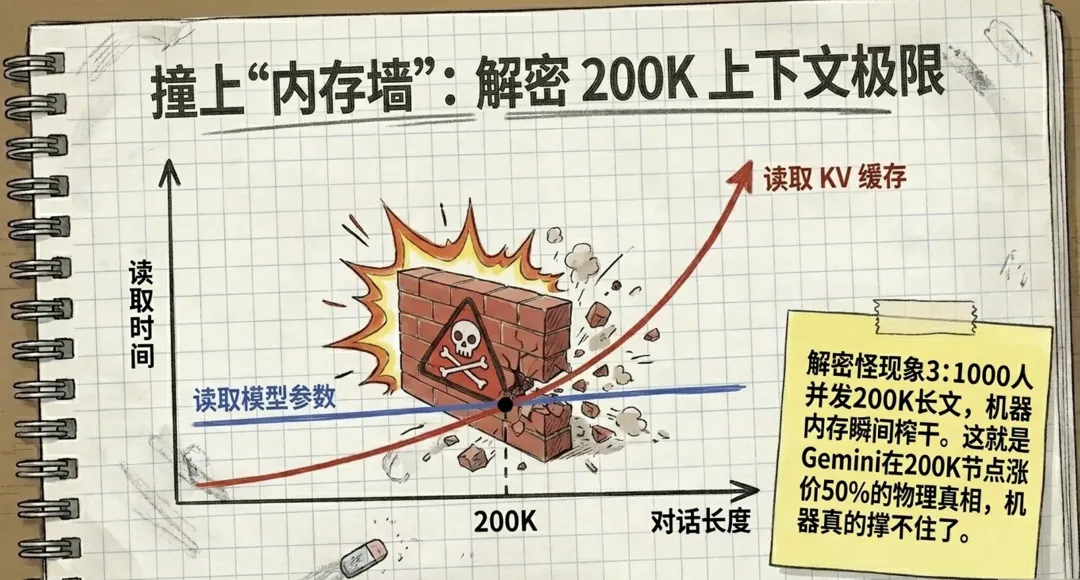
回顾一下两个数字:
• 每个 Token 的 KV 缓存:约 2KB • 模型的活跃参数读取量:约 100GB 量级
当上下文长度超过某个临界点,读 KV 缓存的时间会超过读模型权重的时间——这时候上下文每加长一点,延迟就增加一点,而且越往后越夸张。
代入硬件常数 300 简单算一下,这个临界点大约就落在 200K 附近。
短期内,HBM 内存带宽的增长速度远远跟不上算力的增长速度。Pope 在播客里说了一句相当悲观的话:
“HBM 就是这样了,不会有大幅提升。我看不到很好的解决路径。”
所以指望明年突然出现 1000 万上下文的模型——除非有架构上的根本突破,否则物理不允许。
九、彩蛋:从定价能反推训练量?
最后一个让人吃惊的推论。
经济学上有个朴素原则:当一件事的两个成本中心相互可替代时,理性的玩家会让它们大致相等。对大模型公司来说,这两个成本中心就是训练和推理。

如果你预计未来这个模型要被调用 100 万亿次,那在训练阶段多花点钱,把它训得"更轻量、更聪明"(活跃参数小但效果好),就是值得的——因为推理省下来的钱远远超过训练多花的钱。
按这套逻辑,Pope 推算 GPT-5 这一代的训练量,可能是经典 Chinchilla 最优比例的整整 100 倍。换句话说,行业现在普遍处于"过度训练"状态——但这是有意为之,为的是让推理时更省钱。
这就是为什么模型越来越"小而强"。100B 参数能干出 500B 参数的活,省下来的不仅是显存,是十亿用户、千亿次调用乘出来的真金白银。
写在最后
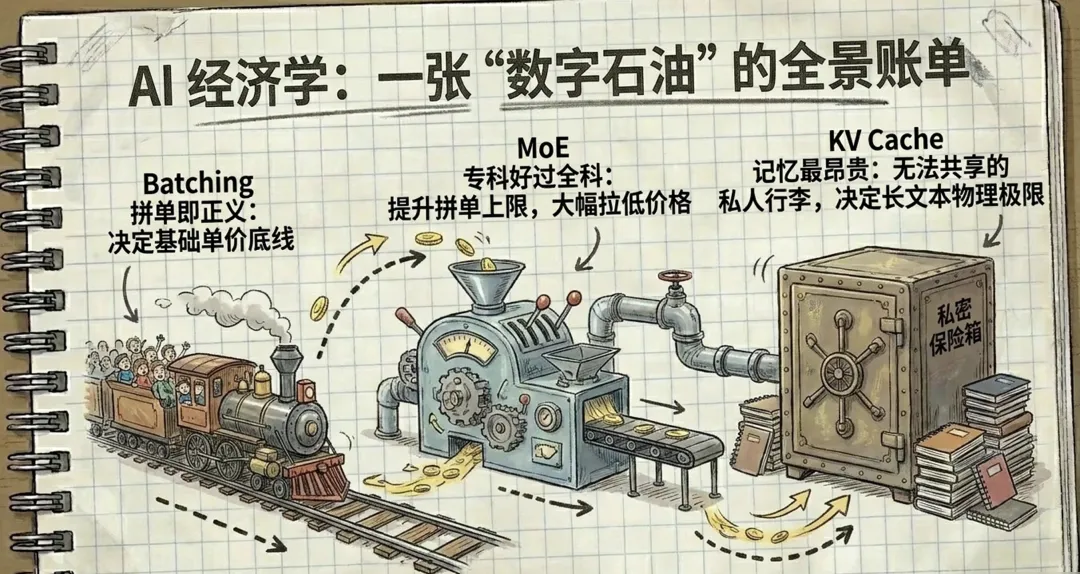
回到最初的问题:你为 AI 付的那笔钱,到底花在哪了?
答案是:绝大部分花在了"搬运数据"上,而不是"思考"上。
GPU 计算单元 90% 的时间在等内存。AI 公司的核心竞争力,不是哪家算法更聪明,而是谁能把这趟"每 20 毫秒一班的火车"塞得更满。Token 这个看起来抽象的小单位,背后是一整套精密到毫秒级的物流系统。
下次当你看到 AI 公司发布新的价格方案、新的上下文长度、新的"快速模式",你应该能立刻在脑子里跑一遍:
• 价格降了?大概率是 Batch Size 提上去了,或者用了更稀疏的 MoE • 上下文变长了?要么牺牲了延迟,要么用了新的稀疏注意力技巧 • 输出比输入贵很多?正常,物理就是这样 
理解了 Token 是如何被计算出来的,你就理解了这场"数字石油"战争的真正战场——不在云端,在内存和计算单元之间那段几厘米的距离里。

