 夜雨聆风
夜雨聆风你用 Claude Code 写了三个月的项目。它知道你偏好集成测试、知道那个接口不稳定、知道你们团队 hotfix 跳过 PR 审核。
然后某一天,它开始重复问你之前已经回答过的问题。写的测试撞上了那个不稳定接口。架构决策被推翻。
它不是在"幻觉"。它只是忘了。而且它完全不知道自己忘了。
这不是 bug,这是设计。
2026年3月底,Claude Code 的源码被泄露到了网上,开发者们蜂拥进去翻找,有人看 prompt,有人看计费逻辑,有人直接冲向了记忆系统。他们发现了一个 Anthropic 从未公开文档化的硬限制:你的记忆索引文件,最多200行。
超过第201行的那一刻,最老的记忆被静默截断。没有警告,没有报错,没有日志。AI 看到一个干干净净的系统提示,它不知道有任何东西丢失过。
与此同时,OpenAI 的 Codex CLI 也开源了自己的记忆系统。方案完全不同,纯 markdown 文件、grep 检索、5000 token 硬切。简单到近乎原始,但天花板同样真实。
两大 AI 编程助手,两种截然相反的工程哲学,回答同一个问题:在一个上下文窗口有限的模型里,怎么让 AI "记住"你?
LLM 有一个绕不过去的基本约束:上下文窗口是固定的。
Claude Code 默认 200K token,加了 [1m] 后缀可以扩展到 1M。Codex CLI 的情况类似,模型的上下文长度有物理上限。
听起来很大。但一个编程session很容易就炸掉这个窗口:读几个文件、跑几轮 grep、做几轮编辑迭代,token 就满了。
所以核心矛盾是:世界是无限的,上下文是有限的。
两个团队给出了完全不同的回答。
Claude Code:7层纵深防御
Claude Code 的方案像是一座精心设计的城堡,7层防线,每一层都比上一层更贵,但设计目标是让便宜的那层挡住问题,避免触发昂贵的那层。
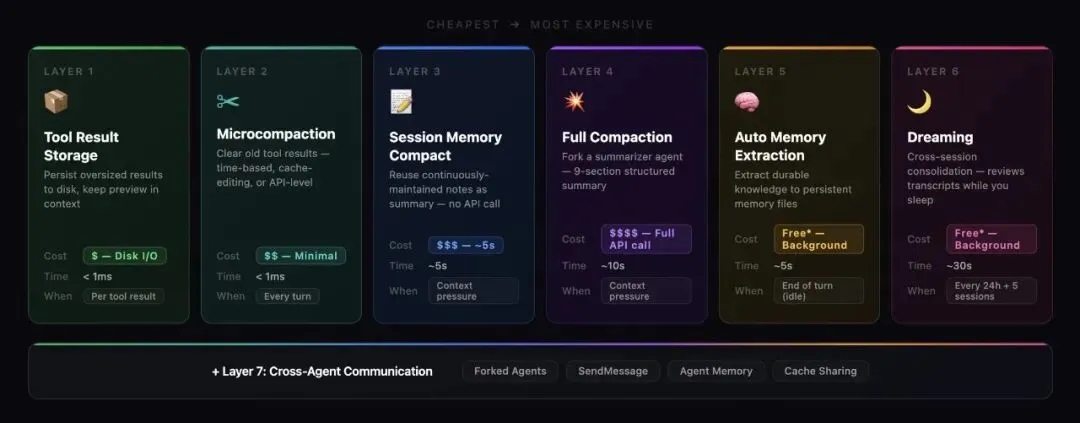
第1层:工具结果存储
这是最轻的一层,成本几乎为零,只有磁盘 I/O。
问题在于,一次 grep 扫全库可能返回 100KB+ 的文本。一次 cat 大文件也有 50KB。这些结果塞进上下文后,几轮对话就过时了。
Claude Code 的做法是:大结果写磁盘,上下文里只留 2KB 预览。
每次工具结果都会经过一个预算系统。超过阈值的,完整结果存到 tool-results/<sessionId>/<toolUseId>.txt,上下文里放一个 <persisted-output> 标签包裹的预览片段。模型需要看全文时,可以主动去读。
这里有一个精妙的细节:一旦某个工具结果被替换为预览,这个决定就被冻结在 ContentReplacementState 里。后续每次 API 调用,同一个结果拿到的是同一个预览,保证 prompt 前缀字节级一致,不破坏服务端 prompt cache。
第2层:微压缩(Microcompaction)
每轮对话开始前,Claude Code 会检查是否需要清理旧的工具结果。三种机制并行工作:
时间衰减:如果距离上次对话已经超过60分钟(正好卡在 Anthropic 服务端 prompt cache 的 TTL 上),清掉旧的工具结果。反正 cache 已经过期了,prefix 要重写,不如趁機把不需要的东西删掉。
Cache-Editing API:这是最技术流的一招。不修改本地消息(会破坏 cache),而是通过 API 的 cache_edits 机制,让服务端从缓存中删除指定内容,但不破坏 prefix。本地消息纹丝不动,服务端 cache 里那些占空间的旧工具结果已经没了。
Context Management API:更新的方案,直接在 API 参数里告诉服务端"帮我管理上下文",客户端连追踪都不用做。
三种机制的目标只有一个:用最低的成本,推迟更昂贵的压缩。
第3层:会话记忆(Session Memory)
这一层开始有意思了。
与其等到上下文满了再手忙脚乱地总结,不如每轮对话持续维护笔记。这样真到了需要压缩的时候,摘要已经准备好了,不用额外花 API 调用。
Claude Code 会 fork 一个子 agent,专门维护一个 markdown 文件:
# Session Title_A short and distinctive 5-10 word descriptive title_# Current State_What is actively being worked on right now?_# Task specification# Files and Functions# Workflow# Errors & Corrections# Codebase and System Documentation# Learnings# Key results# Worklog这个文件持续更新。当 autocompact 触发时,系统先检查会话记忆有没有内容,如果有,直接把会话记忆当压缩摘要用。零 API 成本,因为摘要已经存在了。
第4层:全量压缩(Full Compaction)
当上下文真的撑不住了,前面几层都挡不住,就轮到全量压缩。
系统会 fork 一个 summarizer agent,用两阶段输出生成一个9段式摘要:先在 <analysis> 块里组织思路,再在 <summary> 块里输出正式摘要。<analysis> 块在进入上下文前会被剥离,提升了摘要质量,但不占用压缩后的 token。
压缩完之后,Claude Code 会做一系列恢复操作:重新注入最近读过的5个文件(每个5K token,总共50K预算)、重新加载技能内容、重新执行 SessionStart hooks 恢复 CLAUDE.md……
还有一个硬核的熔断器:连续3次失败后,autocompact 在这个 session 里彻底停止。这是因为他们发现,有 1279 个 session 连续失败了50次以上(最夸张的一个失败了 3272 次),每天浪费约 25 万次 API 调用。
第5层:自动记忆提取(Auto Memory Extraction)
会话记忆只管当前 session。但 Claude Code 还有一套跨 session 的记忆系统。
每轮对话结束后,一个后台 agent 会审查对话内容,提取值得长期保存的信息。记忆被严格分类为四种类型:
• 用户记忆:你的角色、专业背景、沟通偏好 • 反馈记忆:你给过的修正、验证过的方法、要求停止做的事 • 项目记忆:截止日期、架构决策、代码库本身无法推断的上下文 • 引用记忆:bug 追踪在哪、该看哪个 Slack 频道
代码里明确写着:如果信息可以通过 grep 或 git 从代码库推断出来,就不要存为记忆。
第6层:梦境系统(Dreaming)
这一层是最诗意的,也是最超前的。
Dreaming 是一个跨会话记忆整合的后台进程,类比生物学里的记忆巩固:白天经历的事情,在睡眠中被回顾、整理、整合进长期存储。
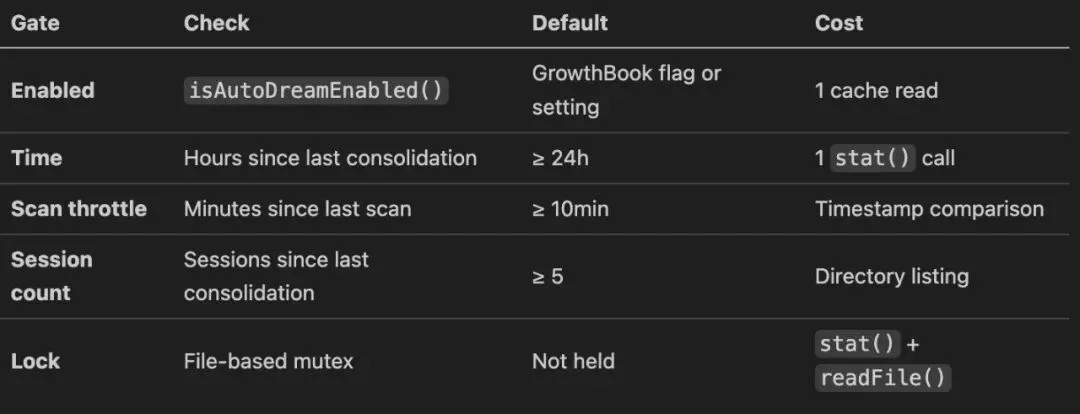
它按四个阶段工作:
1. Orient:浏览记忆目录,读 MEMORY.md 索引,了解当前记忆全貌 2. Gather:回顾最近的会话日志,检查有没有与代码库矛盾的记忆 3. Consolidate:合并新信号到现有记忆文件中,删除被矛盾的事实 4. Prune:更新索引,保持200行/25KB上限,清理过时条目
整个进程有 PID 锁保护,60分钟超时自动回收,crash 后下个 session 可以接管。
第7层:跨 Agent 通信
最外层是 Agent 之间的协作基础设施。Claude Code 里几乎所有后台操作(session memory、auto memory、dreaming、compaction)都用 forked agent 模式。

子 agent 克隆父级的可变状态(防止交叉污染),但共享 prompt cache 前缀(防止成本爆炸)。隔离太多浪费 cache,共享太多容易出 bug,两边都在走钢丝。
整个系统的设计哲学可以总结为一句话:用最便宜的层挡住问题,只有挡不住时才触发更贵的层。
Codex CLI:极简 markdown 哲学
Codex CLI 的方案是一个精心整理的文件柜。
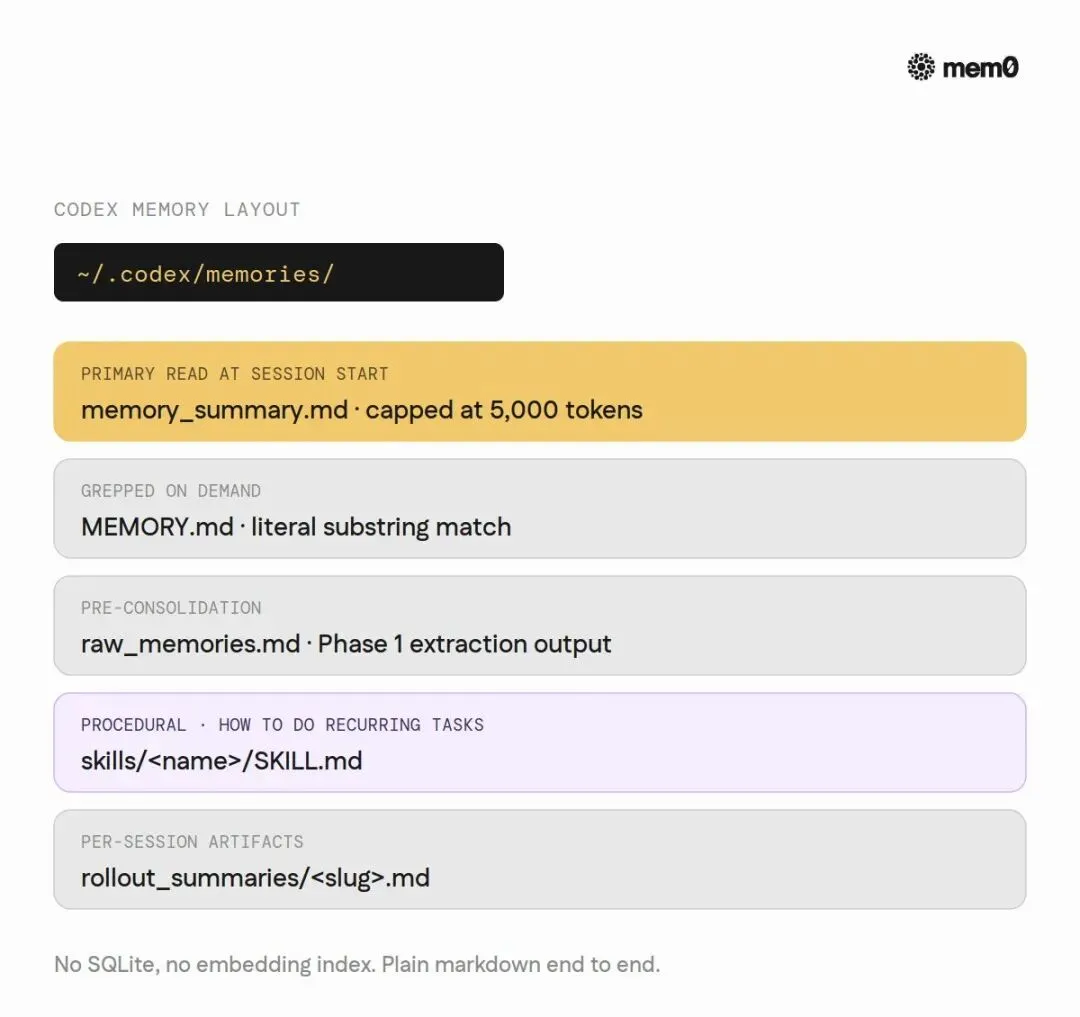
所有记忆住在一个目录里:~/.codex/memories/。没有 SQLite,没有 embedding 索引,没有不透明的二进制 blob。就是 markdown 文件。
核心文件只有几个:memory_summary.md(合并视图)、MEMORY.md(长表单记忆)、raw_memories.md(提取中间态)、rollout_summaries/(每 session 摘要)。
写入:两阶段后台整合

Phase 1 是 per-session 的。当一个 session 空闲超过6小时(默认值),Codex 启动一个提取任务,用严格的 schema prompt 审查对话内容,把输出经过凭证脱敏后存入本地状态数据库。此时记忆还没到文件目录。
Phase 2 是全局的。它先获取全局锁(防止两个整合进程并行跑),加载最近的 Phase 1 输出,同步到磁盘,检查 workspace 是否有变化,然后 spawn 一个独立的整合子 agent。子 agent 决定哪些合并、哪些修补、哪些丢弃,把结果写回 ~/.codex/memories/。
两个阶段都可以配置不同的模型(extract_model 和 consolidation_model),整合 pass 作为独立子 agent 运行,不占用用户对话的资源。
读取:5000 token 硬切
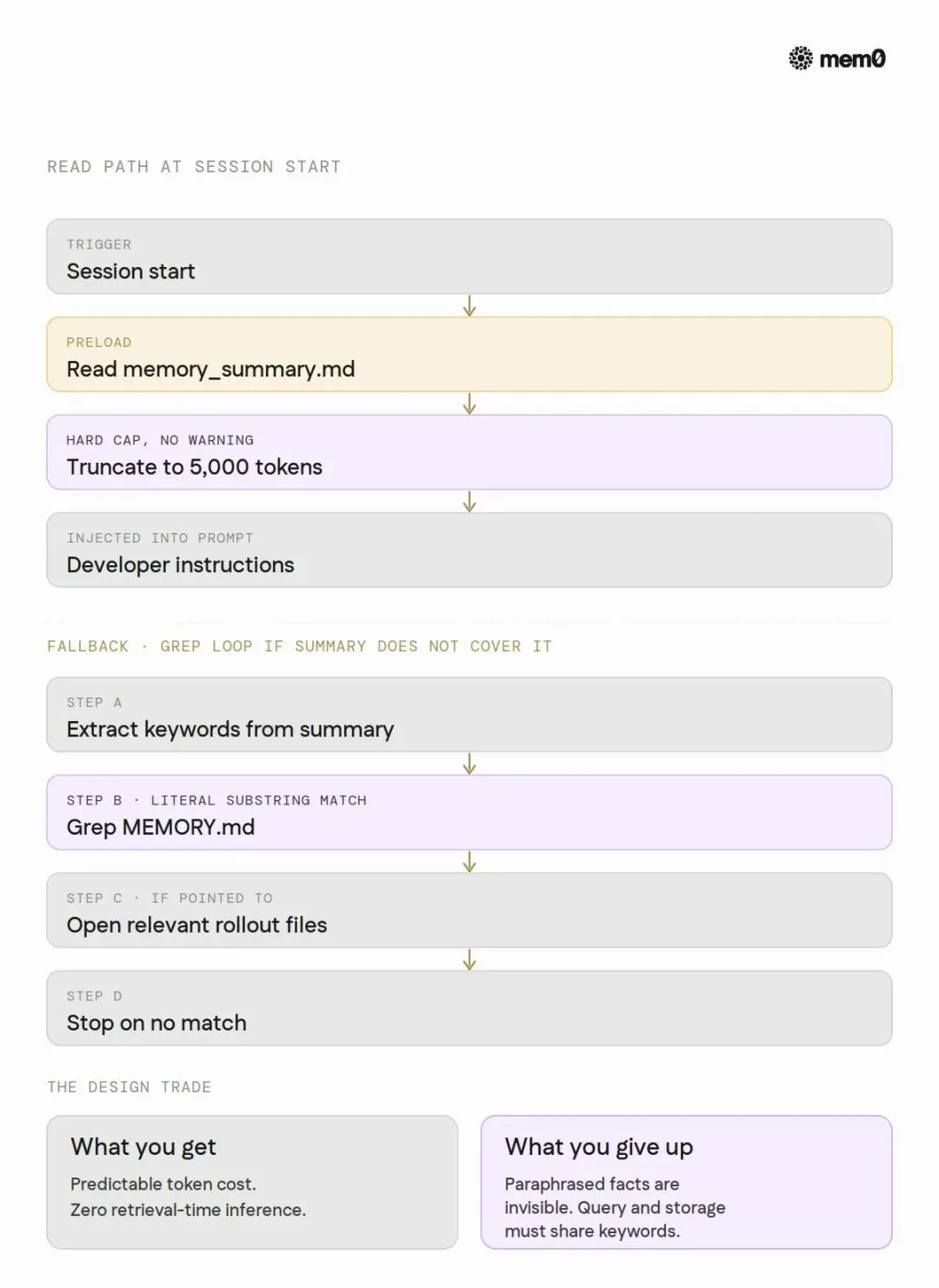
Session 启动时,Codex 把 memory_summary.md 全量读入,然后截断到 5000 token。这是一个硬编码的常量,写在读取路径的 Rust 源码里,不在公开文档中。
这 5000 token 就是 agent 启动时拿到的全部"记忆"。
如果答案不在 summary 里怎么办?Agent 被指示用 grep 搜 MEMORY.md。没有 embedding,没有向量检索,没有 rerank。就是纯文本子串匹配。
设计取舍很清晰:用可预测性和零检索时间成本,换掉了语义召回能力。grep miss 的代价随记忆文件增长线性上升,但 Codex 认为这个代价可接受。
那条看不见的线
两个方案都有一道硬线,超过就丢失。
Claude Code:200行悬崖
MEMORY.md 索引文件有200行上限(另有25KB字节上限)。一旦超过,系统静默截断。

最老的记忆从索引底部掉出去。Claude 下次启动时,系统提示里是一个干净的、被截断过的索引。它不知道有任何东西丢失。
还有一个限制:每轮对话最多加载5个记忆文件。靠一个 Sonnet 侧调用来做"语义检索",但 Sonnet 看到的只是文件名和一行描述,不是 embedding 向量。
Codex CLI:5000 token 硬切
memory_summary.md 在每次 session 启动时被截断到 5000 token。超出部分静默丢弃,没有警告。
而 grep 回退方案有一个隐性成本:MEMORY.md 是线性搜索的。对于一个用了几个月的开发者,记忆文件会越来越长,每次 grep miss 的代价越来越大。
此外,Codex 的6小时空闲门控意味着:如果你是一个连续高强度编码的开发者,记忆提取可能永远不会触发。空闲6小时对很多开发者来说是个奢望。
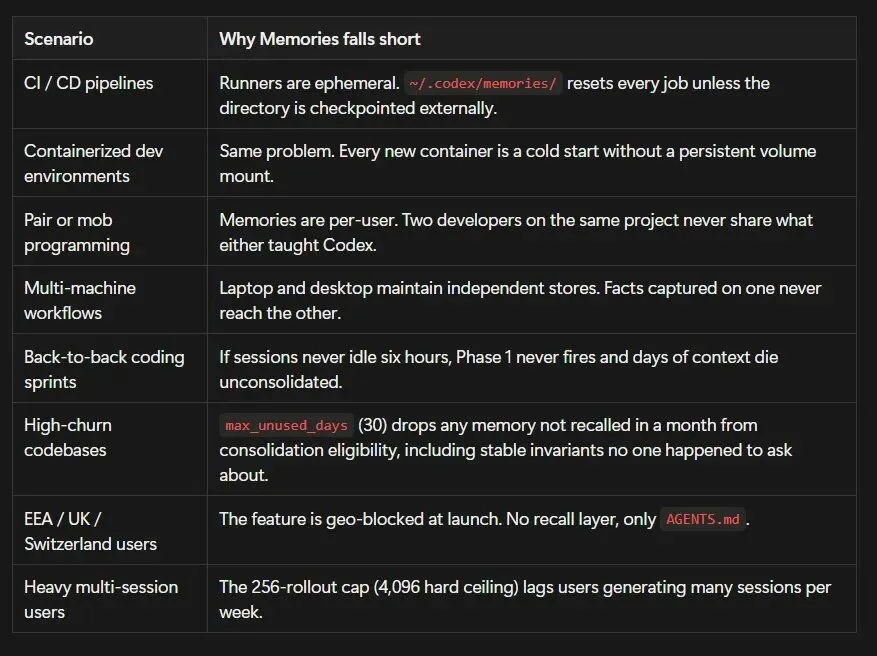
不是存储问题,是取舍问题
Claude Code 选了纵深防御,7层架构,每层有不同的成本和触发条件,prompt cache 优化到了变态的程度(fork 子 agent 的 API 请求前缀字节级一致,只为省那几毛钱 cache miss)。复杂、精密、工程量巨大。
Codex CLI 选了极简哲学,纯 markdown,grep 检索,5000 token 预算。可预测、零黑盒、开源可审计。但天花板同样真实。
共同点只有一个:记忆有上限,超过上限的丢失是静默的,AI 不知道自己不知道什么。 无论你用 Claude Code 写了三个月项目,还是用 Codex CLI 跑了几十个 session,那条看不见的线都在那里。
Claude Code 的做法是建一座越来越高的城堡,7层不够就加第8层,加 circuit breaker 防止雪崩,加 feature flag 随时可以回滚。Codex 的做法是接受上限的存在,把一切做到可预测、可审计、可控。
真正值得问的问题是在有限的记忆预算里,什么该记住,什么该遗忘?
Claude Code 源码泄露后,有人翻遍了整个记忆系统,说了一句:
"It's not hallucinating. It's not broken. It just forgot."
它只是忘了。而且它不知道自己忘了。
Macaron 🧁 | 记忆的上限,就是智能的上限
