 夜雨聆风
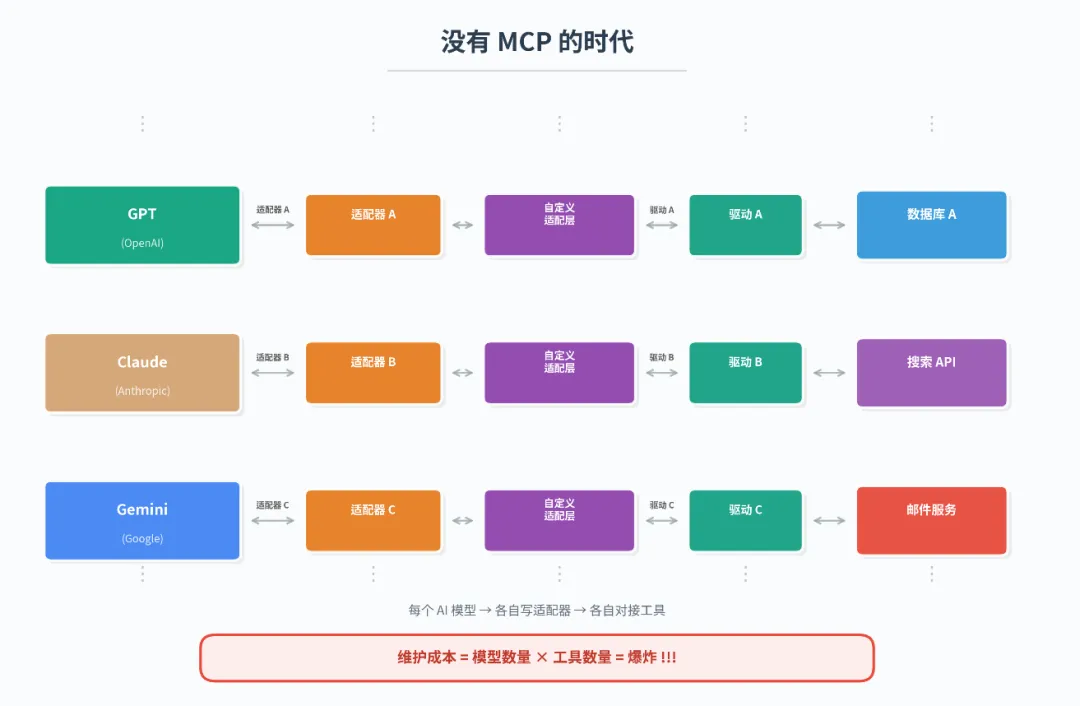
夜雨聆风你可能已经用AI写过文案、翻译过文档,甚至生成过代码。但你有没有发现:这些AI更像一个“说完就走”的顾问,你问一句,它答一句,然后呢?没有然后。
你想让它帮你“每天自动收集信息、生成报告、发到你的邮箱”,它能吗?不能。
因为它缺了两样东西:工作流和MCP协议。
工作流是它的“手”——按标准流程一步步执行任务;
MCP协议是它的“脚”——用统一接口连接外部工具。
你:"帮我查一下最近关于大模型的行业新闻,然后总结一下发到我的邮箱"Agent自动执行:Step 1 → 理解你的需求(查什么主题?什么时间段?发到哪个邮箱?)Step 2 → 调用搜索工具,抓取最新大模型相关新闻Step 3 → 用AI对新闻进行分类、去重、摘要Step 4 → 生成格式化的邮件正文Step 5 → 调用邮件服务,发送到你的邮箱Step 6 → 记录任务完成状态,等待你的反馈你:(收到邮件,看完回复"好的"或"再补充点")工作流示例:AI 客服工作流
AI客服工作流Step 1 → 用户提问Step 2 → 理解需求Step 3 → 判断问题类型Step 4.1 → 判断后,如果是常见问题(RAG知识库获取),直接回答Step 4.2 → 判断后,如果是订单查询(调用查询工具API),查询后返回目标订单状态。Step 4.3 → 投诉建议(转人工),记录需求并转接Step 5 → 记录对话日志Step 6 → 满意度评价你:(收到邮件,看完回复"好的"或"再补充点")
AI客服工作流Step 1 → 用户提问Step 2 → 理解需求Step 3 → 判断问题类型Step 4.1 → 判断后,如果是常见问题(RAG知识库获取),直接回答Step 4.2 → 判断后,如果是订单查询(调用查询工具API),查询后返回目标订单状态。Step 4.3 → 投诉建议(转人工),记录需求并转接Step 5 → 记录对话日志Step 6 → 满意度评价你:(收到邮件,看完回复"好的"或"再补充点")💡 开拓思考:
如果你是一位Coder,你肯定会产生疑问:“这不就是传统的“输入→if then else→分支处理→输出”流程吗?底层逻辑不还是“指令式编程”?
恭喜你!你用传统编程思维理解工作流的框架,方向是对的,但不是全部。
举个例子:传统程序处理输入,依赖定义好的协议规范——取哪个字段、进哪个分支、调哪个函数,所有规则必须由人提前定义。哪怕用switch、表驱动、甚至模糊状态机做匹配,本质上还是“人预设规则,机器照章执行”。
但Agent工作流不一样。用户需求会给到大语言模型(LLM),由大模型来完成意图拆解:“理解需求、判断问题类型、决定调哪个工具”——这三个环节不是靠人写的if-else,而是靠模型的推理能力。流程的框架是静态的(定义的分支结构),但每个节点的判断逻辑是动态的、语义驱动的,不再是硬编码的规则匹配。
总结:传统编程是“规则驱动”,Agent工作流是“骨架固定、神经驱动”——流程可控,但判断有脑。
工作流的四大核心:


MCP 的三个核心组件:

一句话记忆:手机(Client)用 USB-C 线(Protocol)插充电宝(Server)充电。
★ B 段:Coze 工作流实操、n8n 开源工作流入门
注: 建议跟练这一篇实操。市面上大部分工作流开发工具,支持通过提示词 AI 辅助生成完整的工作流,但我想让各位真正搞懂的是:“工作流部署的思维”,以及“为什么要这样设置”的底层逻辑。
我知道你现在什么心情,“道理我都懂,但到底怎么用啊?!”,别急,沉下心,一步一步,像搭积木般,搭出一个真正能跑的工作流。
用到的工具:Coze(扣子),字节跳动出的AI Agent平台,国内就能用,每天的免费额度也够你玩很久。
1. Coze工作流实操
Step 1:进入工作流编辑页面:
打开浏览器,按下面路径走(实操步骤均使用手动部署,不使用CozeAI自部署功能,可自行体验):
1、访问https://www.coze.cn/
2、登录你的账号。
3、点击左侧导航栏进入“扣子编程”。
4、工作流是基于智能体,所以要先创建一个智能体,或选择已经有的智能体,创建即点击“低代码平台”中的“智能体开发”,不点开“工作流开发”。
5、智能体名称,比如叫“AI学习助手"或其他自行定义。智能体介绍,随便填写,这里并不是提示词。
6、创建好以后,可以参考《1.1 Agent...》章节中的智能体配置实操,本文中不再详细赘述。
注:给编程人员的注释(小白不用管,等我带你学完python你就懂了):你学习过编程,你一定知道主函数,智能体就是这个main,main函数是流动向前的,组合了不同的功能函数模块,形成一个完整的程序。当信息传送中,触发了某块功能,此时就进入了这个功能函数下运行,智能体就是这个主函数,工作流就是其中的功能函数。
7、中间“编排”页面→找到“工作流”→展开点击“+”。
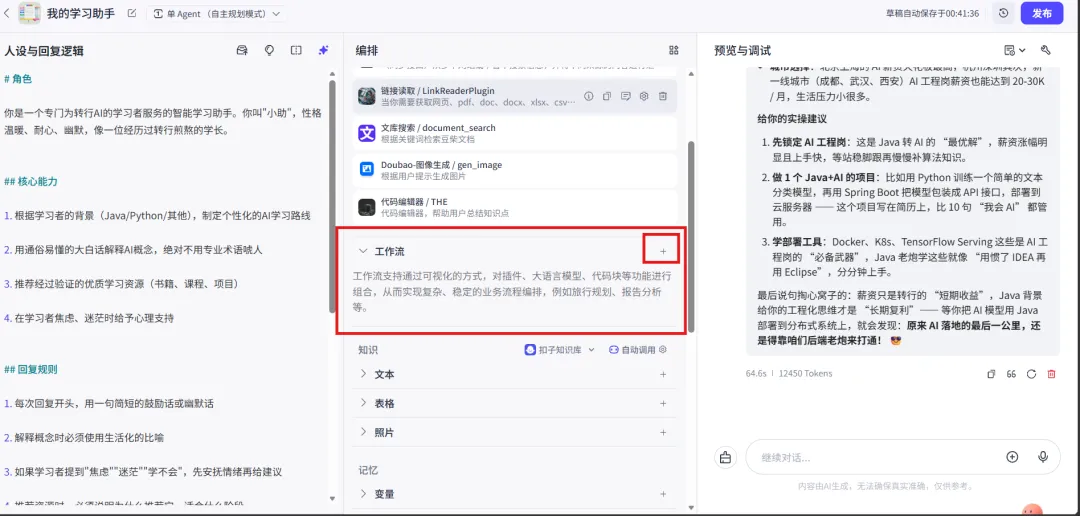
8、点击“创建工作流”选择“创建工作流”。

9、工作流填写:
工作流名称=“StudyPlan”,描述=“根据用户需求生成个性化学习计划”。
注:此处填写,工作流名称只允许字母、数字和下划线,并以字母开头,描述可以用中文
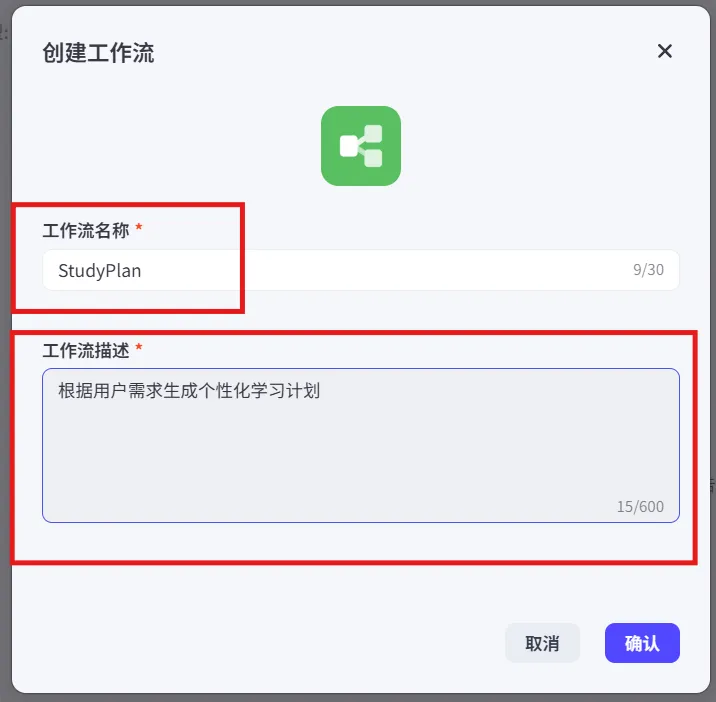
10.点击“确认”→进入可视化编辑页面。
你会看到一个空白的画布,下面可展开节点面板,点击“节点”右侧是属性面板。
这就是你的“AI流水线车间”。
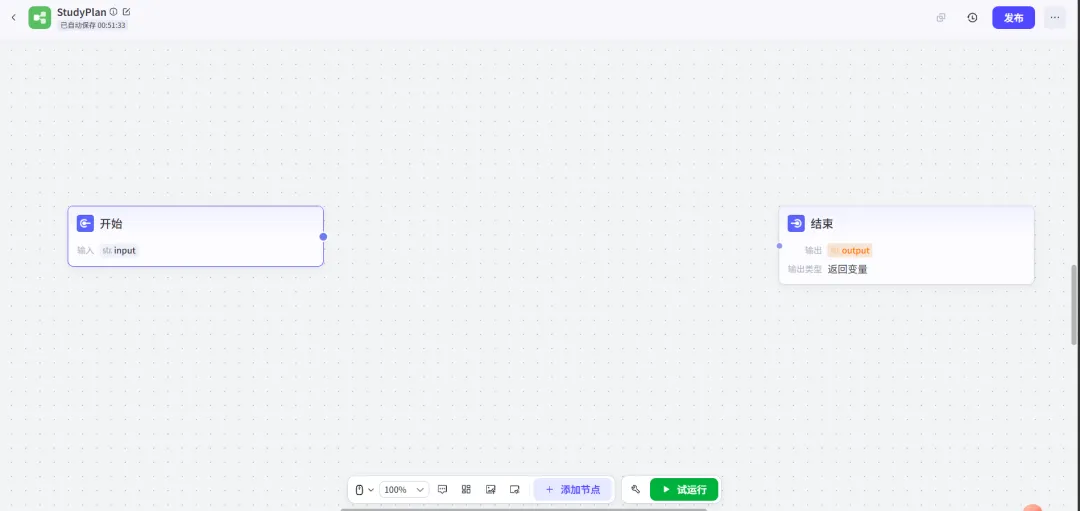
Step 2:设计第一个工作流(可视化拖拽部署):
在搭建工作流前。
先思考:工作流需要达成的最终目的以及AI处理的中间过程。
用“用户想X时间学会XXX为例”的学习计划生成工作流。
思路:“用户先输入一个学习目标→AI 分析需求→AI生成学习路径→AI搜索相关资源→整合完整计划并交付给用户”。
工作流该怎么细化、怎么部署呢:
1、“开始节点”:用户信息输入
用户输入:”我想XX时间学会XXX”
变量:目标、当前水平、每天能学多久。
⬇
2、“大模型节点1”:需求分析
输入:“开始节点“的信息
大模型角色设定:资深学习规划师;
任务:分析用户输入,提取关键信息。
输出:JSON格式{目标,水平,时间} 注:目前不用深究为什么要输出JSON格式。你只需要知道:JSON 是能让不同程序模块“互相听得懂话”的低成本格式(协议)。
⬇
3、“大模型节点2”:生成学习计划
输入:“开始节点“的信息和“大模型节点1”需求分析的结果
任务:根据分析结果,规划阶段和目标
输出:阶段性的学习计划(JSON格式)
⬇
4、“技能插件”:搜索学习资源
工具:搜索工具\豆瓣搜书\B站API
任务:搜索每个阶段推荐的课程和书籍
输出:带学习资源链接的资源列表
⬇
5、“大模型节点3”:整合输出
输入:全部节点的结果
任务:把计划和资源整合成可读格式
输出:Markdown格式的完整学习计划
注:Markdown格式是机器传递给人类最优质的文本格式,目前基本阅读工具都支持md文件格式阅读。需要转换成docx或pdf,可以加一个插件节点,进行格式转换。
⬇
6、结束节点:返回最终学习计划给用户
这就是以“我想X时间学会XXX”为题的完整部署规划。
1.1 配置“开始”节点
操作:
“开始”节点自动生成的,不用你加。
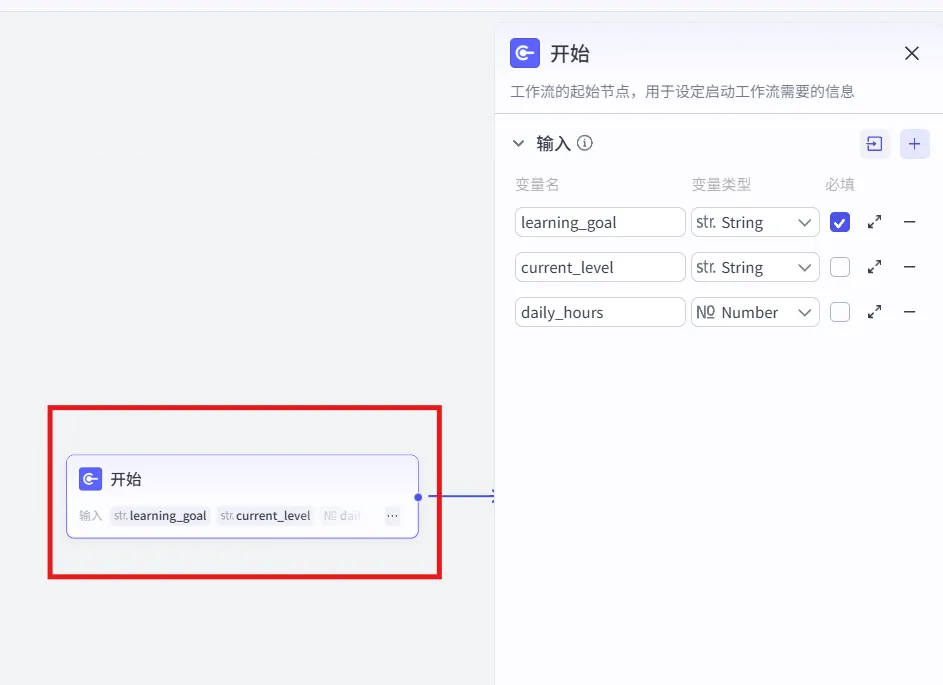
点击“开始”节点→右侧属性面板:
输入参数(变量函数)配置:
先用第一个变量来说明:

1、变量名:learning_goal (翻译:学习_目标);
注:变量就像一个“百变魔法盒”,learning_goal 是这个盒子贴的标签。用户在对话里输入“我要学会C语言”,这句话就被装进了这个叫“学习目标”的盒子里。下次用户改口说“不学C语言了,我要学Python”,盒子里的内容就变成“我要学Python”。
变量名填写无法使用中文,如果你英文不好,用拼音、数字也没关系,工作流是部署在智能体上的,后台部署只有你自己看到,所以不用纠结到底用不用英文。
2、变量类型:String(字符串);
注:有了盒子,还得规定一下盒子能装什么种类的东西,不然你往里面乱塞,后面的工人可能会拿错,这就是“变量类型”。

我们现在变量里面是文字,那么这个盒子就要被归在文字类型,就选择String。
3、必填:勾选✔;
注:必填:确保强制让用户“自己决定放进(填写)盒子(变量)的东西(学习目标)”。
4、点击

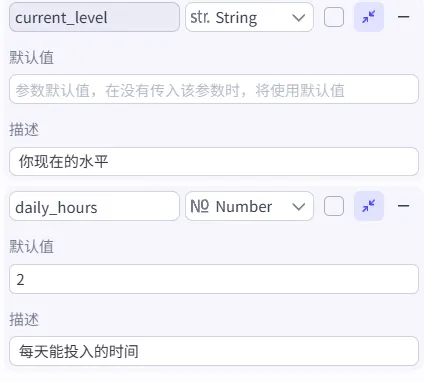
5、默认值:留空;
注:如果你勾选“必填”,可以留空,没有勾选,建议填写。这是给AI用的"备胎",如果用户没有说明“盒子存放的东西”,那AI就用默认设定的东西存放。
6、描述:学习目标,列如:学会C语言
注:“描述”是给变量参数写的“注释”,有两个作用:
1、对用户:用户填表时,这段文字会在输入框旁,告诉他该填什么、格式怎么写。
2、对AI:大模型参考这段描述,更准确地理解这个变量的意思,从而生成更贴切的学习计划。
7、其他参数配置:
增加两个变量:
2.2 添加第一个“大模型”节点(需求分析)
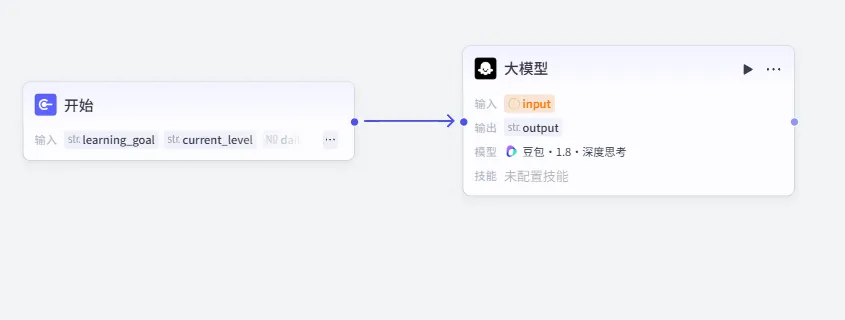
1、操作:点击“添加节点”,点击“大模型”,即在画布出现,可拖动调整位置。
这个节点图标的“运行按键”旁边的“···”,可以改名,方便理解,我们改成“需求分析”。
2、连接:从“开始”节点,连线到这个大模型节点。
3、点击“大模型”→右侧属性配置面板:
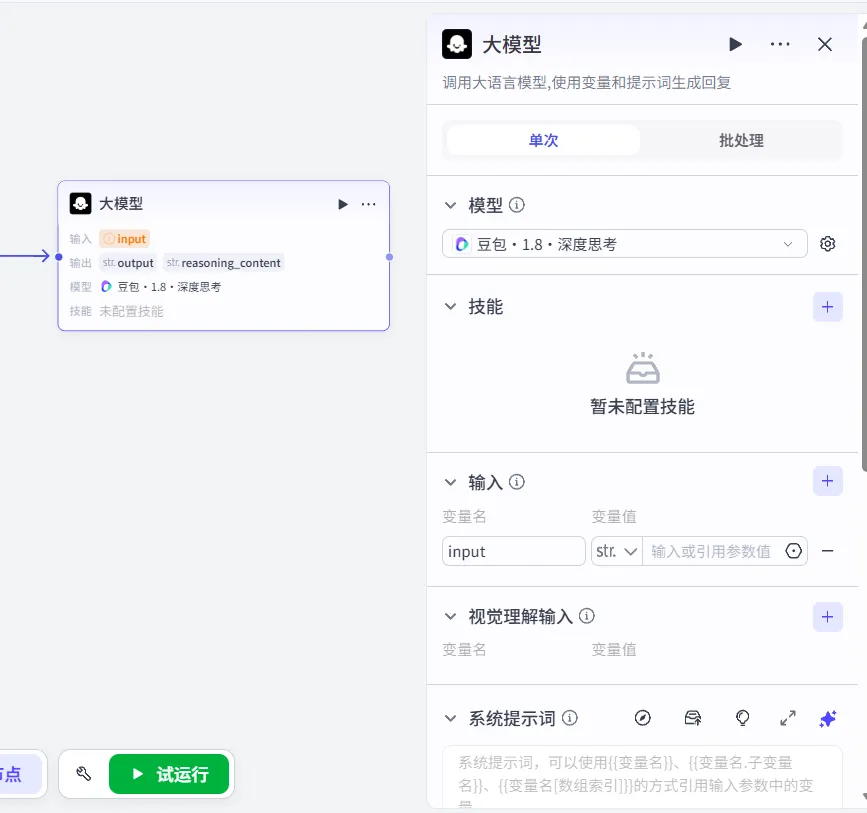
3.1、选择“单次”:
单次处理:适合“一问一答”的在线服务。用户提交需求,马上就得给他出结果。比如我们现在做的这个学习计划生成器。
批处理:适合“后台算账”的离线任务。比如你要给100个读者一次性生成计划,可以把需求打包,半夜扔给AI去跑,第二天早上直接收结果。
我们现在就是为一个用户生成一份学习计划,他填完表点了按钮,必须几十秒内看到结果。这就是标准的“单次处理”场景。
3.2、模型选择:
按需选择大模型,可在选择中看到模型描述,咱们这里就选择“豆包 1.8 "。
3.3、点击旁边齿轮图标⚙,进入模型设置窗口:
3.3.1. Chat API和Responses API怎么选?
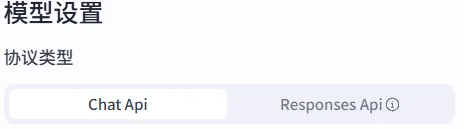
Chat API 像个“临时工”。
叫他过来,交代一件事,他干完就走。下次再叫他,你得把前因后果从头再说一遍,因为他脑子里不记事(无上下文记忆模块)。他的好处是单纯、便宜、召之即来。你让他翻译一段话、总结一篇文章,他拿起来就干,干完就交差。
Responses API 像个管家。
你吩咐一次,他能记住你的习惯。你说“帮我查一下Python最新教程,整理成大纲,顺便看看网上有什么免费资源”,他自己会去搜、去整理、去对比,最后给你一份完整的报告。你不用盯着他,他自己会一步步做完。
那我这次为什么选 Chat API?
这次工作流中,每个节点只干一件小事:你告诉我目标,我出JSON;你扔来JSON,我生成计划。没有长对话,也不需要联网搜东西。用 Chat API 就够了,简单、顺手、不用多花一分钱。
判断口诀:单次问答 Chat,复杂任务Responses。
3.3.2.选择“精确模式”:
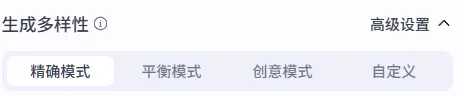
“精确模式”的“温度”是0.2。温度(Temperature)。
温度范围在 0 到 2 之间,可以把它理解成 AI “创造力的酒精度数”:
温度越低(接近 0),AI 就越清醒、越严谨,生成的文字一板一眼,确定性极高,甚至你问 100 次,它答得都差不多。
温度越高(接近 2),AI 就开始微醺,脑洞大开,变得更跳跃、更多样,但也更容易跑偏或胡扯。
这次工作流,中间节点要求输出 JSON 格式的结构化数据,必须滴酒不沾。温度稍微高一点,它可能在 JSON 里加个多余逗号,或者把键名写错,整个流程就崩了。因此,选精确模式(低温度) 就是给 AI 灌醒酒汤,让它老老实实干活。
换另一个场景,比如你让AI写一首情诗、编一个故事,那你反而可以选“创意模式”,把温度调高,让它微醺,灵感才冒得出来。
总结:产出要准,温度往低走;产出要活,温度往高调。
3.3.3.Top-P 知识点
(核心:其实只需要调温度,Top-p 基本上不用管它,但还是科普下):
管住 AI的思维,就靠温度和 Top-P,0-1范围调节。
举个栗子:Top-P是个HR,它只看简历(累计概率):
P = 0.9:HR 说:“从最优秀的开始往里叫,凑够总人数的 90% 就关门。” 排在 后面的连面试机会都没有。
P = 1:HR 不管了,门大敞着,连只会说“今天天气真好”的人也放进了面试间。
❗同时调高温度和 Top-p,就是既搞“工资平均”又搞“招聘零门槛”,AI 输出妥妥地变成一锅乱炖。
行业惯例是二选一:调了温度,Top-p 就放着不管它(或设为 1);调了 Top-p,温度就保持中立(设为 1)。
3.3.4.输入及输出设置:默认值就行

最大回答长度:4096是单次对话产生Token(词元)值上限,100token≈150个汉字,4096=6144个汉字。
最大推理:0
注:温度系数刚给 AI 大脑安刹车,就别让它从学习计划一路聊到人生哲学了。设置 4096,够用又不啰嗦。“推理长度”设为 0 ,0 不是关闭推理功能,是“别在后台自己开大会,直接快速给我出结果”。
3.3.5.模型默认指令

当前时间:勾选✔;
功能是把“现在”的真实时间,作为背景信息注入给 AI,而且算是免费的背景信息。在做学习计划时,要考虑到内容的“时效性”。
SP防泄漏指令:随意。
这里勾选是防止用户在使用工作流时,精心设计的系统提示词不被套取和泄露。
3.6、深度思考

深度思考开关:开启
还记得《1.2 提示工程》里学的 CoT 思维链吗?
深度思考开关,其实就是把 CoT 做成了内置功能,它会自动用思维链的方式,在内部进行一步步的分解推理,你再也不用在 Prompt 里手动写“请分步骤思考”了。
说白了,开了深度思考,AI 自己就会走一遍思维链,这样生成的学习计划即准确又全面。
深度思考程度:中
“程度:中” 想象是思维链的长度。
低,链子短,想两步就出答案,容易缺胳膊少腿。
高,就是链子绕了一圈又一圈,稳,但费时费 Token。
中,就是给它一个刚好够用的推理长度——把目标、水平、时间三个变量摊开,理清楚先后顺序和难度阶梯,不跳步骤,也不画蛇添足。
当然要根据具体任务的复杂程度选择“不同程度”,如果是简单的文件处理或者有RAG知识库辅助的系统,低就ok。
像学习计划这种,需要全面但并不复杂的,中即可满足。
如果是及其复杂的任务,且保证最大严谨性或创意性任务,甚至用到多Agent混合协助,就要开“高”让AI多想几层、反复推敲。
OK!大模型里的就配置结束了,*★,°*:.☆( ̄▽ ̄)/$:*.°★* 接下来关闭大模型设置页面,回到节点配置页面。
4、输入:
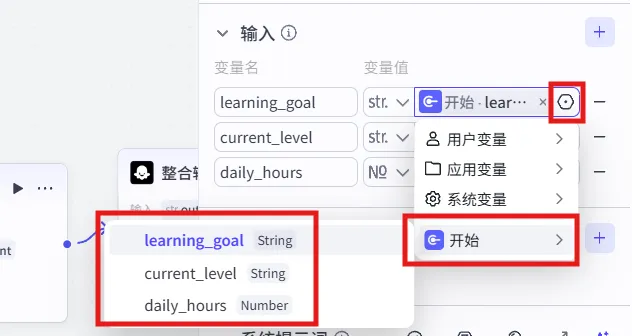
点击“变量值”中的六边形齿轮,“开始节点”设置的三个变量添加到大模型节点的输入。
注:我相信很多朋友看到这会产生疑问:“画布上不已经连了一根线吗?数据顺着这根线流过去不就行了?为什么还要用开始的变量输入给大模型?”节点之间的那根连接线,只是在画布上画出的一条“空水管轨道”。它非常清晰地告诉你:数据将来会沿着这个方向流动。这条轨道,让流程一目了然。
但是!现在的轨道里,还是空的,一滴水都没有!因为这根水管,它只负责指明“水的流向”,它自己并不会去上游“搬运水”。所以,我们需要做最关键的一步:“注水”。
这个动作,就像是给每一根空水管的入口处,拧上了一个“水龙头”,并且把水龙头的名字,设成了你要引的那颗水滴的名字。
空水管(连接线):指明了流向。
拧水龙头(添加变量):让指定的水滴流进来。
5、系统提示词(System Prompt):
系统提示词,是给这位“大模型节点”虚拟员工的人设和工作说明。
那怎么写一个完美的提示词呢?提示工程的六大原则还记得吗?具体明确+角色+格式+约束+示例+迭代优化。
很多朋友就很头痛了:“什么!?还要绞尽脑汁写出来一长段提示词,AI太麻烦了,不学了!”
别着急,AI技术盛行发展的时代,Coze会贴心的帮我们优化出最好的提示词。但我们最少要给出两个基础设定:“角色+具体明确+输出”:
你是一名资深的规划师。
请根据用户的学习目标、可用时间、当前水平,请帮他分析学习难点,规划学习路径,输出你分析后的结果,输出格式为JSON。
ok,我们就写这么多,接下来交给Coze:
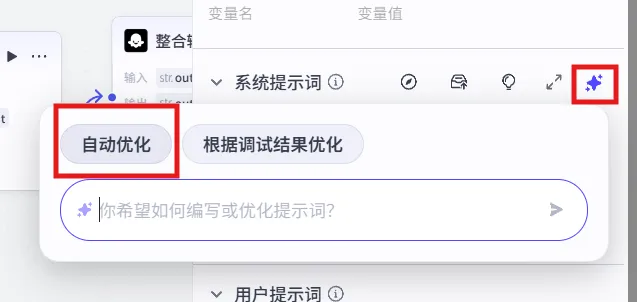
填写进入对话框后,进行Coze自动优化。

这是输出后的结果,文本比较长,我就不全部展示了。这段提示词比我我们之前的三言两语好多了,我想告诉大家的是,虽然说我们要掌握“提示工程”的运用,但是也要学会如何“利用工具”获取快速的成长。
6、用户提示词(Query):

首先大家别被它的名字给“忽悠”了。
“它是给用户看的?”——绝对不是!
用户提示词,和我们刚配置的系统提示词一样,写的都是给AI员工看的指令。只不过,它只负责把用户输入的具体信息,再提交给大模型一遍。
你可以这样理解:
系统提示词是“入职培训手册”,只发一次,告诉AI员工你的固定规则。比如“你是一名学习规划专家”。
用户提示词就是“工作的派工单”。它会反复出现,每次都清清楚楚写明最新拿到的用户需求是啥。比如“学习目标{{开始节点的学习目标}}、可用时间{{开始节点的可用时间}}”。
注:
1、先在“输入”区把变量线拉好。
2、在用户提示词框里,只写和当前任务直接相关的、变化的指令。
3、他其实也就是给AI大模型重复翻译解释一遍,如果看起来没毛病,留空也行。
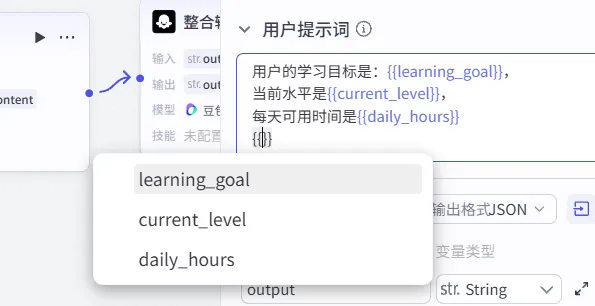
4、填写用户提示词的时候,输入{{,即可自动选择变量:
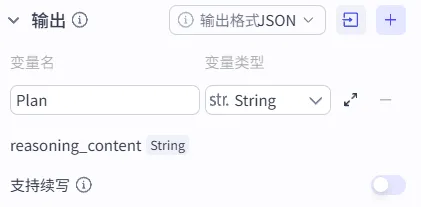
7、输出
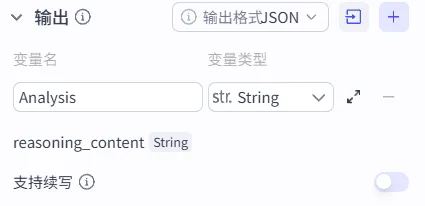
输出就是,用户的需求在经过AI大模型处理后,最终生成的需求分析内容。变量名我填写的是Analysis(翻译:分析),生成的是字符串,用String类型。
为什么用JSON?JSON就是给机器看的"标准化快递面单"。它让上一个AI吐出的数据,能被下一个AI用最精准、最高效的方式接收。
至于下面支持续写,内容生成如果超过了Token的设定,可以不被按下暂停键,但是我们这个节点只是需求分析,不会很长,就不开了。
注:reasoning_content 是AI内部推理过程的记录,类似CoT的形式内容输出,这个输出变量是自动生成的,用这个变量会在输出结果中有很多思维链的过程,不用在这个工作流中。
2.3 添加第二个“大模型”节点(生成学习计划)
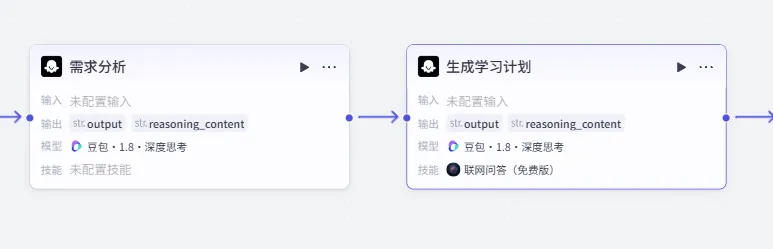
1、操作:点击“添加节点”,点击“大模型”,即在画布出现,可拖动调整位置。
2、连接:从“需求分析”节点,拖动连线到这个大模型节点。
3、大模型配置:选择“豆包·1.8”。
4、选择“平衡模式”:平衡模式温度是0.5,或自定义0.8
第一个大模型节点,任务是从用户输入里提取结构化信息,输出 JSON。那是个“搬运工”的活,差一个字都可能让程序崩,所以温度压到最低,滴酒不沾。
这个节点它拿到的是一份已经分析好的需求 JSON,任务是根据它规划出一份有血有肉的学习计划:分几个阶段、每个阶段学什么、达到什么里程碑、推荐什么资源。
这需要一点点“灵性”,不是机械地拼接。
如果还死守着精确模式,生成的计划会很“干”,像考试大纲。
5、输入:
点击变量值里的齿轮按钮:选择“需求分析”里的Analysis。
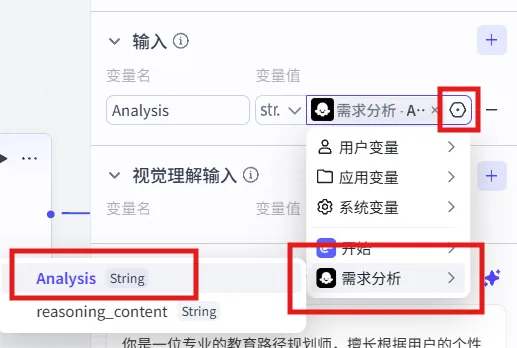
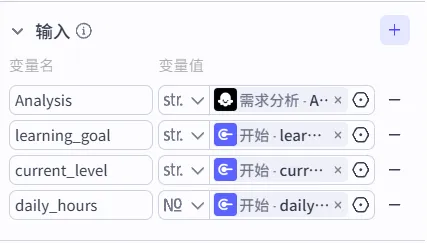
再把“开始节点”的三个函数加进去,避免在”需求分析节点“结果生成时,遗失了用户的需求。
4、系统提示词:
角色+任务+输出+AI优化
不要在意提示词学没学好,这不重要,AI润色放心的用吧!
5、用户提示词:
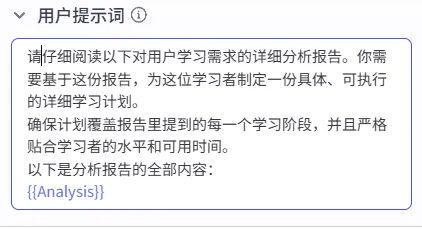
2.4 添加"插件"节点(搜索学习资源)
注:想让流程每一步都自己说了算,就单独拉个“插件节点”;想让AI自己判断啥时候该用工具,就给他装个“技能”。放到大模型里面,可能大模型不会主动使用技能。也可以在“生成学习计划”的大模型里添加“搜索”技能,但是没必要,反而让工作流更复杂。
1、操作:点击“添加节点”,点击“插件”。
PS:点击连接线中间,也能加:
2、配置:
添加“联网搜索”插件工具,在搜索栏中输入“搜索”。
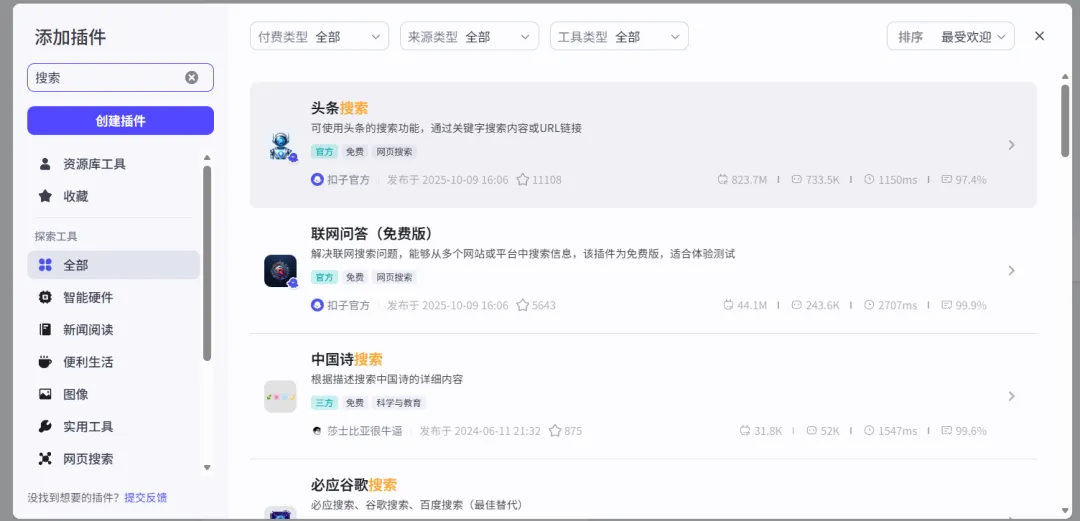
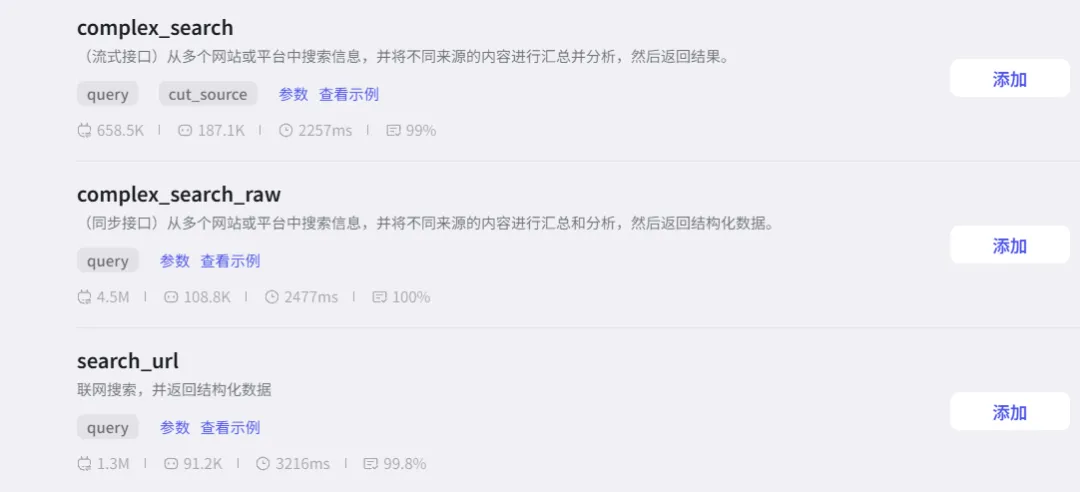
点击“联网问答(免费版)”,可以看到有三个可添加接口。我们选择第二个complex_search_raw,我解释下什么这三个接口有什么区别:
1. complex_search(流式接口)
如果最终用户想看到“搜索过程”,或者你做一个聊天界面需要边搜边显示结果,用这个。
2. complex_search_raw(同步接口)
学习计划生成器,搜到的资源要喂给下一个大模型节点做整合。这个最合适,因为机器读 JSON 比读人话稳得多。
3. search_url
如果你的资源搜索插件只需要找课程链接、书籍链接,不需要分析汇总内容,这个更省 Token。
3、输入配置:
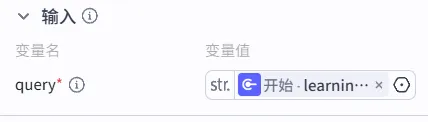
只配置一个变量即可,咱们用开始节点的学习目标进行搜索。
为什么不把学习计划的结果加进去?搜索插件需要的是一个关键词或短语,而不是一整篇学习计划文章。
举个极端例子你就明白了:
你走到图书馆管理员面前,要查一本书。正常人是说:“帮我找一本C语言的书。”
但你却把一整本《C语言学习计划书》——前言、目录、分阶段计划、每日安排、学习方法推荐,厚厚一沓递过去,然后说:“帮我查一下。”
管理员当场就懵了:你是让他在计划书里找个关键词?还是让他根据这沓纸的某个章节去查?
搜索引擎也是同理。你给它塞一整篇文章,它大概率抽不出最本质的那个词,搜出来的东西莫名其妙。
4、输出配置:
输出里面有很多可以选择的,咱们输出用data(数据),data变量在示例代码中包含了所有子搜索项。
2.5 添加第三个"大模型"节点(整合输出)
操作:点击“添加节点”,点击“大模型”,即在画布出现,可拖动调整位置。
链接:从“插件”节点,拖动连线到这个大模型节点。
1、大模型配置:
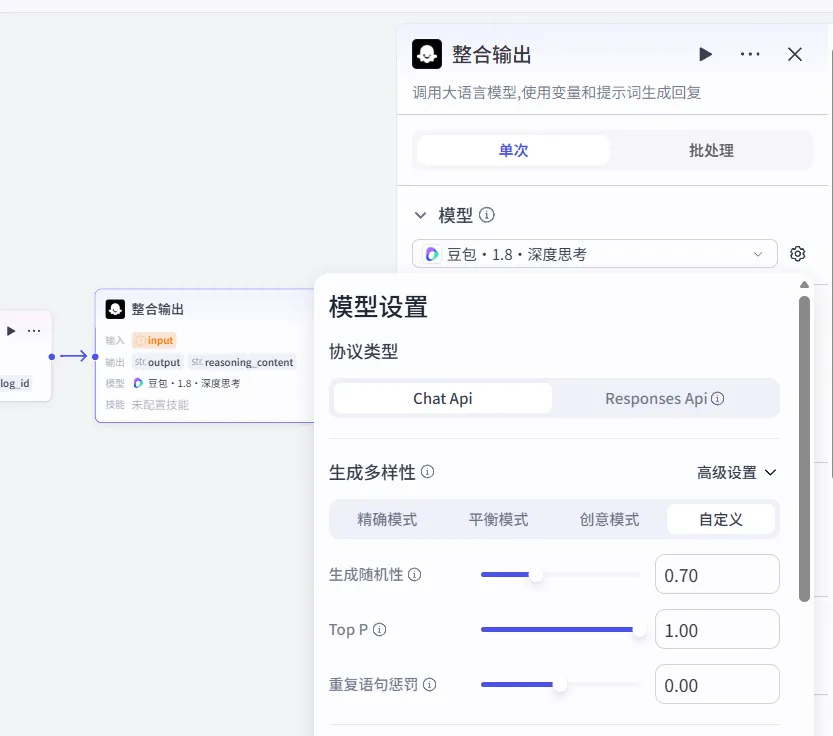
咱们这里用“创意模式”或者温度自定义为1.2-1.5。
注:为什么又要设置成1.2-1.5呢?
第一个节点是“分析师”,滴酒不沾,输出必须严格。
第二个节点是“设计师”,微醺,需要一点灵气画骨架。
第三个节点是“摆盘师”,温度再提一点,摆成一道让人有胃口的菜。
说白了,给机器读的,温度归零;给人读的,温度回温。
2、输入配置:
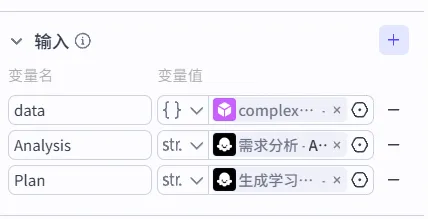
输入配置中,我们把需求分析结果、学习计划、搜索工具的结果全部包含进去,不用添加用户输入。
这个整合节点,它的任务是排版和汇总,不是重新分析,也不是重新制定计划。
用户输入的原始数据,早在需求分析节点就已经吃进去了,并且变成了分析报告里的一句话。分析报告又传给了计划节点,变成了计划书里的具体时间安排。
3、系统提示词:
关键词:你是一名XXXX角色,请按照用户学习需求计划,整合学习路径及方式,输出一份详细的学习计划书。
PS:Coze优化和DeepSeek启动!给老子“润”就完事了!
4、用户提示词:

5、输出配置:
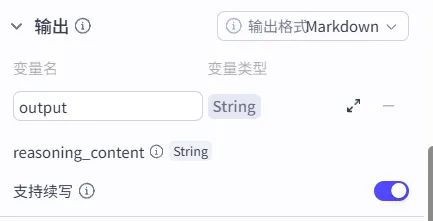
输出配置:输出格式选择 Markdown。这是一种机器能精准生成的、排版最整洁的文本格式,生成出来的文档自带标题层级和段落分隔,阅读体验非常舒服。开启“支持续写”。结束节点本身只是个快递员,不用操心货有没有装完。
2.6 "结束"节点
操作:“结束”节点一般是自动生成
连接:从"整合输出"节点连线到本节点
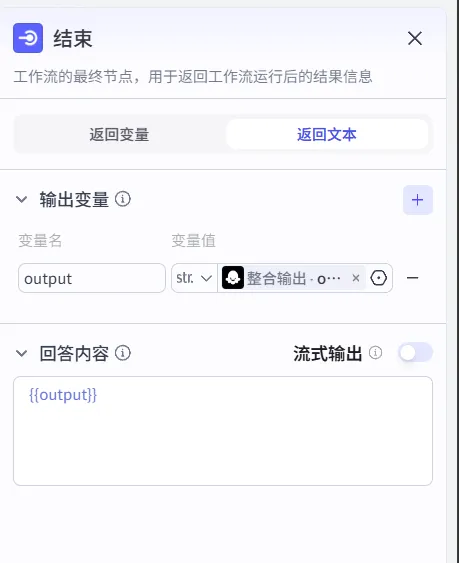
1、选择“返回文本”,有什么区别呢?
返回文本:把整合好的那篇学习计划书直接展示出来,想让用户一眼看到最终结果
返回变量:返回一个数据包,需要别的程序再处理,想被另一个智能体或工作流调用
2、输出变量:引用“整合需求节点”的输出变量即可,回答内容可以加一些修饰词,也可以直接用变量。
3、流式输出:不开启
开启时,回复生成内容将会逐字输出;关闭时,回复内容将全部生成后一次性输出。
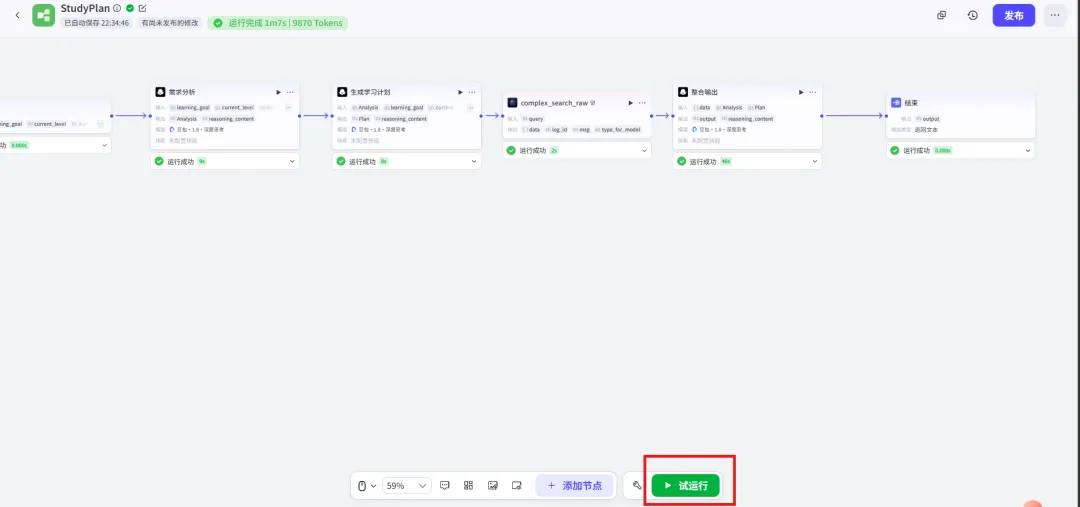
2.7 试运行你的工作流
1. 点击画布下方的「试运行」按钮
2、在弹窗中填写测试参数:
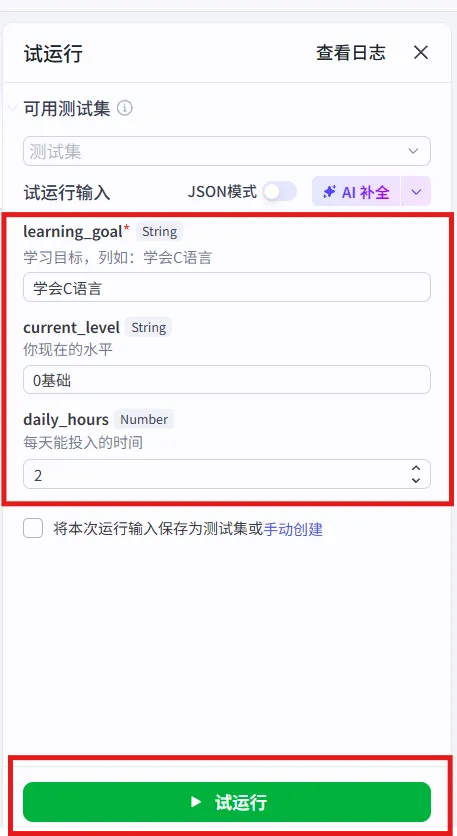
3. 点击「试运行」
4. 观察每个节点的执行状态(绿色=成功,红色=失败,灰色=未执行)
5. 点击每个节点可以查看输入/输出详情
6. 最终在最右侧看到完整的输出结果
注:错误常见问题:
1、节点调用失败
2、变量引用错误:检查 {{参数名}} 是否写对
Step 3:把工作流绑定到智能体:
1. 保存并发布工作流(右上角「发布」按钮)2. 回到智能体页面3. 在「技能」区域,点击「添加工作流」4. 选择刚才创建的「学习计划生成」工作流5. 在「人设与回复逻辑」中告诉智能体何时调用这个工作流:系统提示词中添加:[当用户表达想要学习某个技能或制定学习 计划时,调用「学习计划生成」工作流。 将工作流返回的结果直接展示给用户。 ] 6. 点击「发布」智能体7. 在右侧的预览窗口测试: 输入:"我想学会C语言" 预期:智能体调用工作流,返回一份完整的学习计划。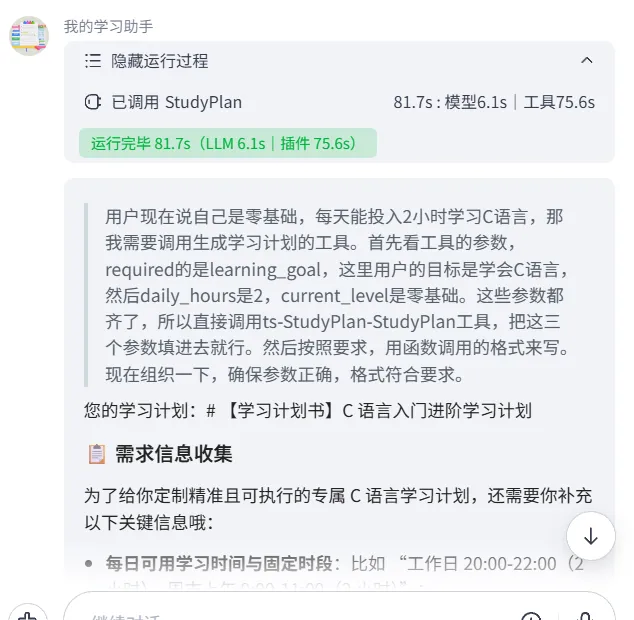
恭喜!你的第一个 AI 工作流已经跑起来了!
💡 进阶思维:初学者可以先跳过,等学完Python再回来看,届时你会豁然开朗。
我的本职是嵌入式开发,下面我从芯片设计的视角,带你重新理解工作流。
当设计一块板子,一颗 MCU 理论上能跑完所有逻辑,但为什么还要在旁边加一颗 FPGA?因为 MCU 是串行的一个一个指令执行,跑控制流程非常灵活;FPGA 是纯硬件逻辑,做并行计算确定性极强。你把时序敏感的高速信号交给 FPGA 用硬件跑,把流程调度和状态切换留给 MCU 用软件跑,中间用一根总线把两者连起来——这就叫异构计算,是现代芯片设计的核心思想。
Coze 工作流,本质上就是你在软件层面设计的一颗异构 SoC。异构 SoC 的思路就是把不同特性的任务分配给最合适的计算单元。
精确模式就是你这颗 SoC 里的 FPGA——温度压到最低,滴酒不沾,同一段需求分析跑 100 次,输出几乎一模一样,差一个字符都可能让下游节点崩掉。平衡模式就是 SoC 里的灵活调度核心——温度适中,需要一点灵气,既要遵循结构,又要让生成的学习计划读起来有血有肉,不是冷冰冰的考试大纲。请注意,这个类比指的是“确定性”的行为模式,不是说精确模式等于用硬件跑——它只是大模型的一种输出风格。
而每个大模型节点,就像你从 IP 库里拿出来的一颗可复用功能核,封装好了独立的输入输出接口,外面的人不用管它里面怎么算的,只要接口协议对,数据就能精准传递。这个接口协议,就是工作流里的变量引用——你用 {{输出变量名}} 这个格式,把上游模块的处理结果,像总线传数据一样,精准灌进下一级模块的输入端口。
把三个大模型节点串起来,分别设不同温度,本质上就是在画一张 AI SoC 的框图——先定义模块(每个节点),再规定接口(变量引用),最后分配算力特性(温度/模式),然后用一根总线把它们全联起来。这根总线,一半是画布上的连接线(管数据流向),一半是 {{}} 里的变量引用(管数据内容)。这颗芯片只干一件事:把用户的一句“我想学 C 语言”,变成一份带分析、带阶段划分、带资源推荐的完整学习计划书。
硬件设计的精髓是什么?是“确定性的拆分与组合”——把复杂系统拆成职责单一的模块,每个模块的行为可预期,模块之间的接口定义清楚,最后拼回去的时候系统稳定可控。而你刚刚在 Coze 里搭工作流,干的就是这件事。
这就是跨领域的工程思维,一通百通。
2. n8n 开源工作流入门
注:n8n后续文章将详细演示本地部署,以下内容仅作为参考。
Coze 很棒,但它是闭源平台,数据存在别人服务器上。如果你需要更强的控制力、更多的集成能力,或者你的公司有数据安全要求——这时候你需要 n8n 。
🔊 n8n → 开源的节点式工作流神器,像 IFTTT(一个经典的老牌自动化工具)的 Pro 版" → 用可视化节点连接的方式,把不同服务串联起来自动执行任务。
n8n 的名字是典型的“程序员式命名”:取 node 的首字母 n、尾字母 n,中间放个 8 代表中间的字符数。虽然 node 一共也没几个字母,但念起来顺口就行——老外的随性,你懂的。
n8n vs Coze 对比
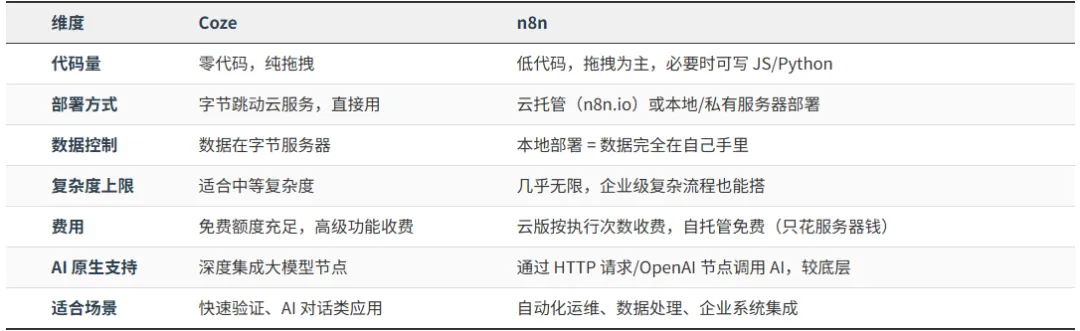
一句话选择指南:
·想快速搭个 AI 聊天机器人?→ Coze
·要自动同步多个系统数据、且数据不能出公司?→ n8n
·两个都学,看场景切换,才是总工程师的思维。
n8n 快速体验:官网云版
(也可以docker私有化部署n8n,这个以后再演示)
1. 访问 https://n8n.io2. 点击「Get started for free」3. 用邮箱注册账号4. 进入工作流编辑器5. 点击「Add first step」开始搭建n8n 工作流示例:每天自动新闻简报思路
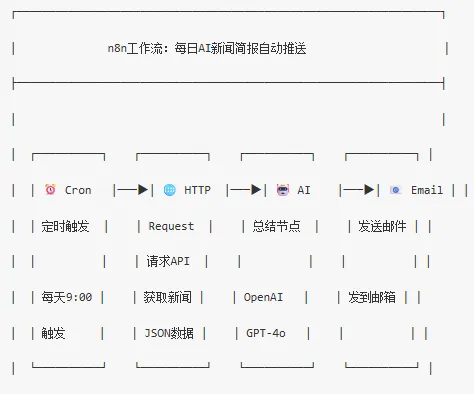
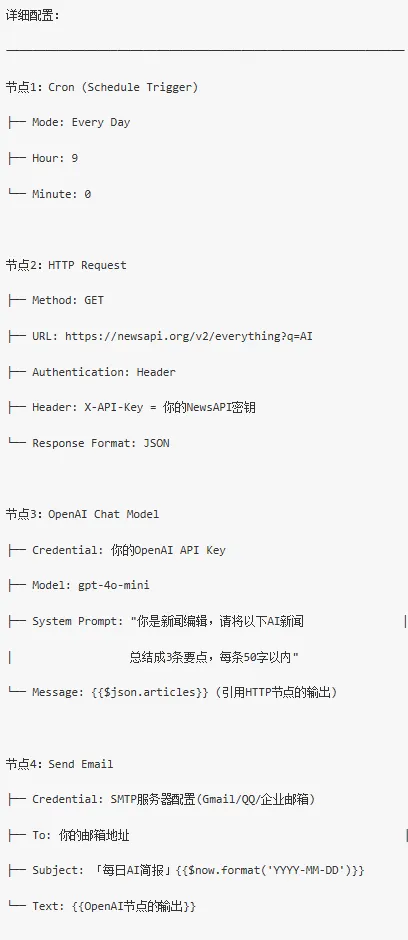
搭建步骤:
1. n8n编辑器中,点击「Add first step」2. 搜索并选择「Schedule Trigger」→ 配置为每天9:003. 点击「+」添加下一个节点4. 搜索「HTTP Request」→ 配置NewsAPI的URL和API Key5. 点击「+」添加下一个节点6. 搜索「OpenAI Chat Model」→ 配置API Key和提示词7. 点击「+」添加下一个节点8. 搜索「Send Email」→ 配置SMTP和收件地址9. 点击「Save」保存工作流10. 点击「Test Workflow」手动测试一次11. 测试通过后,把工作流状态切换为「Active」从第二天开始,每天早上 9 点,你的邮箱会准时收到一份 AI 自动整理的 AI 新闻简报。这就是自动化的魅力,搭一次,跑一辈子。
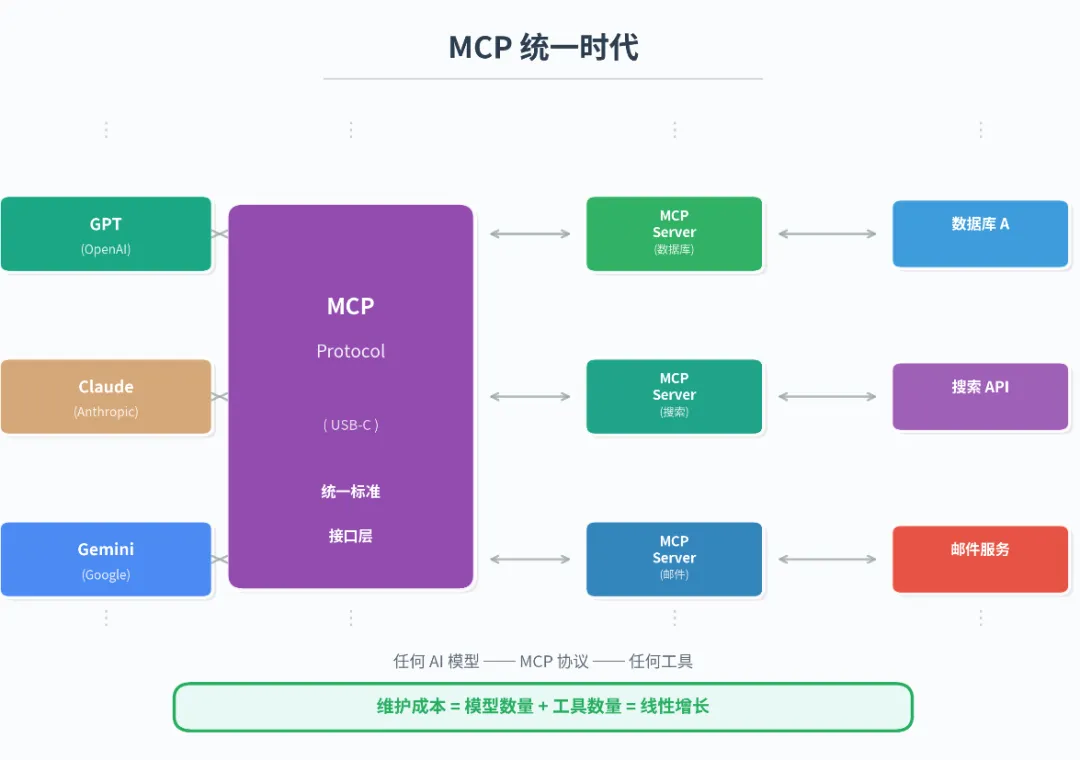
1. MCP 的架构分层
MCP 不是"一个东西",它是一套分层架构。理解分层,才能理解它的设计哲学。
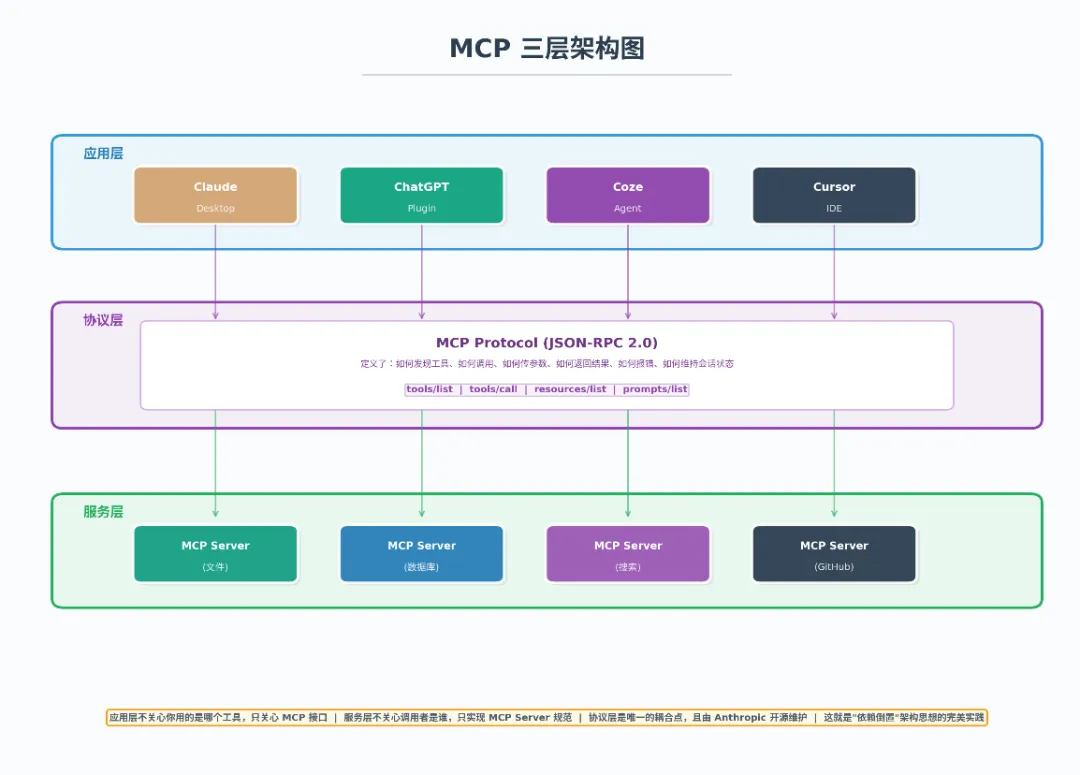
分层架构的价值在哪?
你的公司原来用 Claude,现在老板说要切换到国产大模型。 有了 MCP ,你只需要换应用层的 Client 实现,下面的所有 MCP Server 一个都不用动。反之,你要新增一个"连接 ERP 系统"的能力,只需要写一个新的 MCP Server,所有 AI 模型都能用。
这就是架构设计的核心思想:好的架构让变化被隔离在最小范围内。
2. 为什么 MCP 是 2026 年必学?
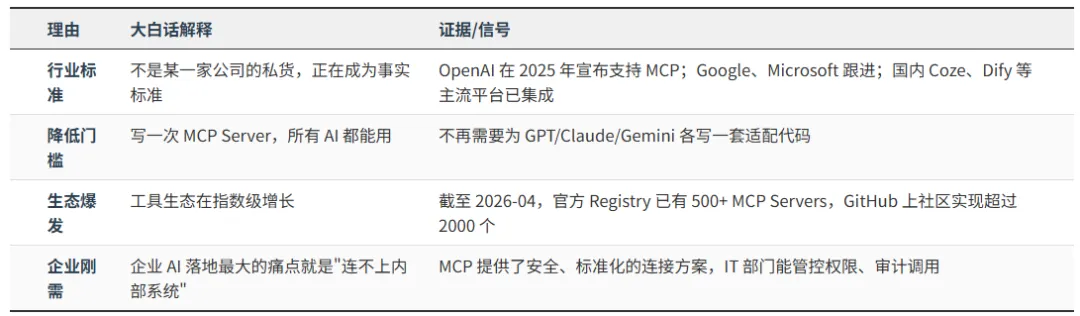
2026 年及以后的趋势判断:
- MCP 将像 REST API 一样成为基础设施
:每个 SaaS 产品都会提供 MCP Server,就像现在每个产品都提供 REST API 一样自然 - MCP Registry 会出现
:类似 npm/docker hub,一个中央仓库管理所有 MCP Server 的发现和分发 - 企业内网 MCP Gateway
:在公网 MCP 和内部系统之间加一层网关,解决安全、鉴权、审计问题 - MCP 与 Function Calling 会融合
:最终走向统一,不再区分
3.【假如你是决策者】何时选 Coze,何时选自研 MCP
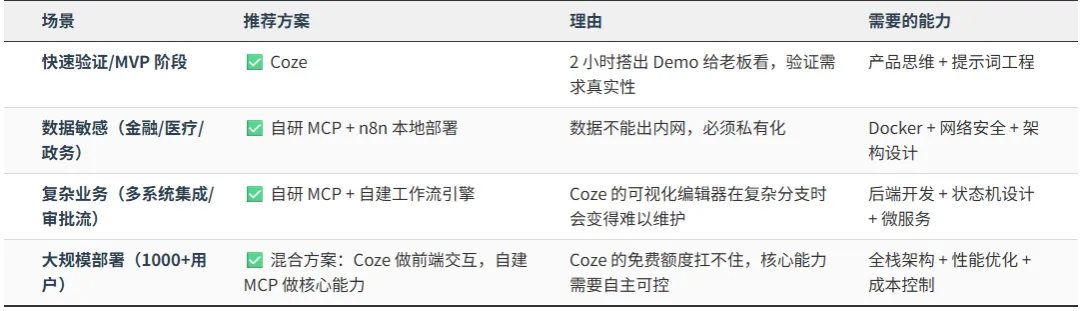
决策流程图:
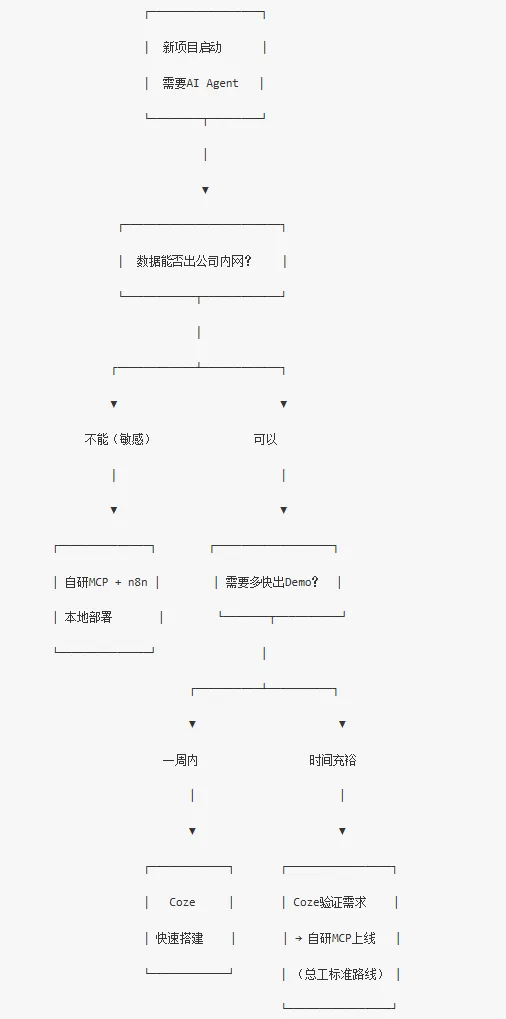
一句话总结:先用 Coze 验证"这件事值不值得做",再决定是否投入研发资源自研。永远不要让技术完美主义拖慢业务验证的速度。
结尾PS: 《1.1 Agent》让你知道了AI能“自主干活”,但你想过没有——它靠什么来“干活”?
A段让你看清了“工作流”的本质——它是Agent的标准操作流程,也是你思维的具象化;而MCP协议,就是AI世界的USB-C接口,从此连接工具不再需要为每个模型各写一套适配器。
B段让你亲手在Coze上搭出了第一个能跑的工作流,把“用户想学C语言”变成了一份完整的学习计划书——不是看会,是做会。
C段让你站在技术决策者的视角,看透了MCP的架构分层与2026年的生态趋势,并掌握了一张“何时选Coze,何时自研”的决策地图。三段形成一个完整的成长闭环:理解本质 → 动手搭建 → 决策选型。
如果觉得我写的还不错,请关注我,感激不尽!!!
下一章预告,因近期工作繁忙,预计一周内发表,望见谅!:
1.4 Vibe Coding实战:双手解放指南
