 夜雨聆风
夜雨聆风理解 AI Agent 的核心技术:过滤Context和模型自主做Context Engineering
Context Engineering erklärt: Context Filtering und autonomes Context Engineering

Folien:
https://github.com/createmomo/Notes-on-AI-Agents
之前的文章:
从 OpenClaw 看 AI Agent 的运作原理 理解Context Engineering
Frühere Artikel:
Wie KI-Agenten funktionieren: Der Fall OpenClaw Context Engineering Explained
目录:
那么多 token 都来自哪里? 过滤:按需加载 System Prompt 中的过滤 让模型自己做 Context Engineering 存在硬盘上的 Context
Inhalt:
Woher kommen all diese Tokens? Filtering: Laden nach Bedarf Filtering im System Prompt Das Modell selbst Context Engineering durchführen lassen Auf der Festplatte gespeicherter Context
关于这篇笔记的说明:
主要参考了Hung-yi Lee老师2026年的机器学习课程(https://www.youtube.com/watch?v=urwDLyNa9FU),其中一小部分内容根据个人理解可能有微小的调整; 保留了最核心的内容,所以比较简短,但也尽量保留了知识的完整。所以适合快速的回顾复习,当然也适合新手快速理解。
Hinweis zu dieser Notiz:
Diese Notiz basiert hauptsächlich auf dem Machine-Learning-Kurs von Prof. Hung-yi Lee aus dem Jahr 2026 (https://www.youtube.com/watch?v=urwDLyNa9FU). Ein kleiner Teil des Inhalts kann aufgrund meines eigenen Verständnisses leicht angepasst worden sein; Es wurden nur die zentralsten Inhalte beibehalten. Deshalb ist diese Notiz relativ kurz, versucht aber zugleich, die Wissensstruktur möglichst vollständig zu erhalten. Sie eignet sich daher gut für eine schnelle Wiederholung, aber auch für Einsteigerinnen und Einsteiger, die sich rasch einen Überblick verschaffen möchten.
1. 那么多token都来自哪里呢?Woher kommen all diese Tokens?
前面的文章我们介绍了一些压缩Context的概念。但是你有没有发现,在我们介绍的时候,都是在Context已经很长的情况下,然后Agent再去压缩Context。这当然是控制Context长度的一种方法。但是,有没有一种可能,从一开始,我们就想办法,让进入Context的内容(也就是tokens)就不要那么多呢?
In den vorherigen Artikeln haben wir einige Konzepte zur Komprimierung von Context vorgestellt. Vielleicht ist dir dabei aber aufgefallen: Diese Methoden kommen meist erst dann zum Einsatz, wenn der Context bereits sehr lang geworden ist.
Das ist natürlich eine Möglichkeit, die Länge des Context zu kontrollieren. Man kann die Frage jedoch noch einen Schritt weiterdenken: Gibt es vielleicht eine Möglichkeit, von Anfang an zu verhindern, dass so viele Inhalte, also so viele Tokens, überhaupt in den Context gelangen?
要弄清楚这个问题,肯定是要先搞清楚,在我们的Context中,到底包含了哪些内容、哪些内容的占比最大。(一般来说,我们肯定是要先解决分量最大的那个,这样带来的效果才会更快更明显)
Um diese Frage zu klären, müssen wir zunächst verstehen, was in unserem Context eigentlich enthalten ist und welche Inhalte den grössten Anteil ausmachen. Im Allgemeinen sollte man zuerst den Teil angehen, der am meisten Gewicht hat, denn dadurch werden die Auswirkungen meist schneller und deutlicher sichtbar.
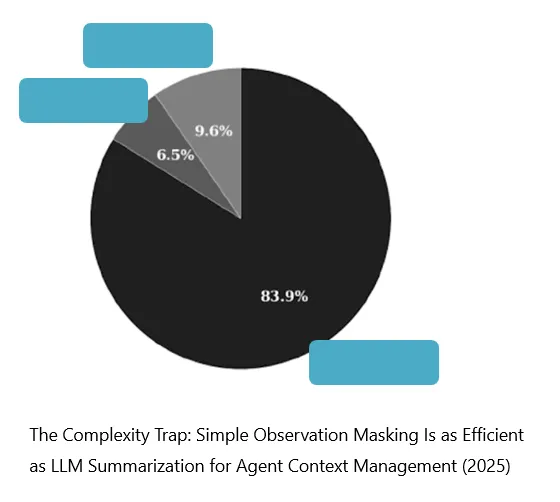
这篇论文就分析了类似的事情。从图中我们可以看出,确实有一个比例非常非常的大。
Diese Studie analysiert genau ein ähnliches Problem. Aus der Abbildung lässt sich erkennen, dass ein bestimmter Anteil tatsächlich sehr, sehr gross ist.
Man kann die Inhalte im Context grob in drei Kategorien einteilen: Action, Reasoning und Observation.
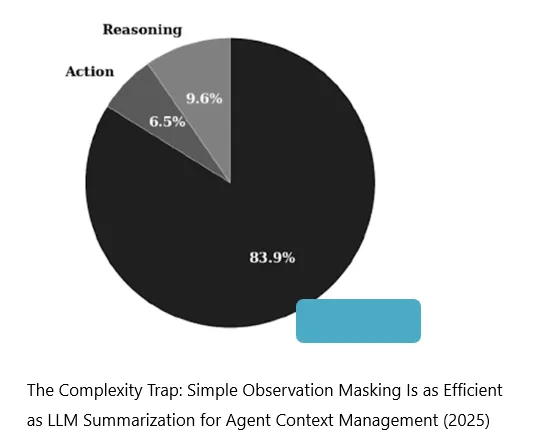
Action: 表示的是模型去产生执行工具的指令,一般来说这些指令都很短。它的占比也确实不高。
Action bezeichnet die Anweisungen, die das Modell erzeugt, um Tools aufzurufen. Wenn das Modell beispielsweise entscheidet, eine Datei zu lesen, ein Programm auszuführen oder ein externes Tool aufzurufen, muss es einen entsprechenden Befehl erzeugen. In den meisten Fällen sind solche Anweisungen relativ kurz, weshalb ihr Anteil am Context tatsächlich nicht sehr hoch ist.
Reasoning:大体是在指模型自己说出来的话。
Reasoning kann grob als das verstanden werden, was das Modell selbst formuliert. Dazu gehören beispielsweise Inhalte, die entstehen, wenn das Modell eine Aufgabe analysiert, seinen Gedankengang erklärt oder den nächsten Schritt plant.
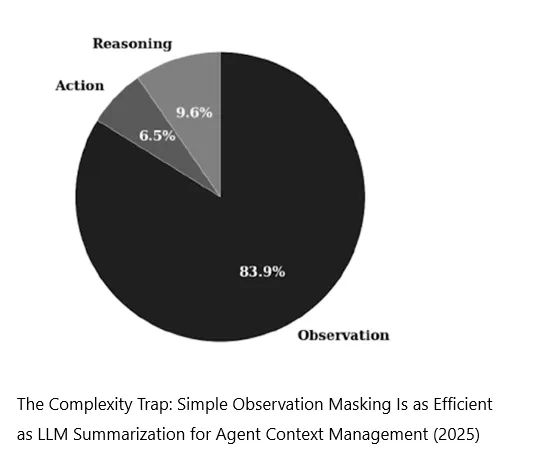
Observation:来自外界的输入,比如载入的文件的内容、一些工具的输出啊等等。
Observation bezeichnet Eingaben aus der Aussenwelt, zum Beispiel den Inhalt geladener Dateien, Ausgaben von Tools, Suchergebnisse, Log-Inhalte oder Fehlermeldungen nach der Ausführung eines Programms.
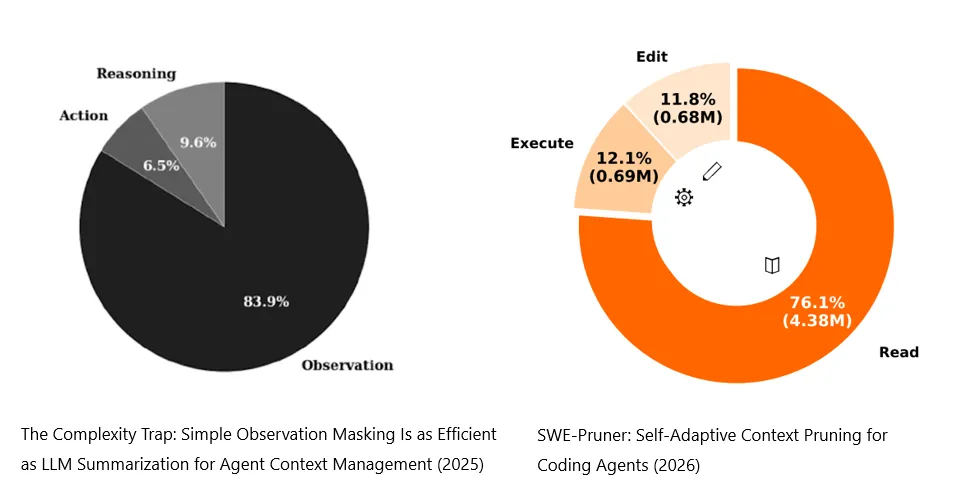
除此之外,还有一篇论文做了类似的事情,以及也得出了相似的结论。只不过这一篇论文主要是集中在software engineering这个主题上。比如让模型去修改代码、执行程序等。
Darüber hinaus gibt es eine weitere Studie, die etwas Ähnliches untersucht und zu ähnlichen Schlussfolgerungen gelangt. Der Unterschied besteht darin, dass sich diese Studie hauptsächlich auf das Thema Software Engineering konzentriert, also beispielsweise darauf, Modelle Code ändern, Programme ausführen oder Fehler beheben zu lassen.
我们可以看出来,其中大概有12%和执行程序有关、11%和修改相关,大部分是在读代码(Read),占了相当大的比例。
Man kann erkennen, dass etwa 12 % mit der Ausführung von Programmen zusammenhängen und 11 % mit Änderungen. Der grösste Teil entfällt jedoch auf das Lesen von Code, also Read, und macht einen beträchtlichen Anteil aus.
总之,到底有没有办法治本呢?也就是说,有没有办法从一开始就不要读入这么多的内容进入Context呢?
Die zentrale Frage lautet also: Gibt es eine Möglichkeit, das Problem an der Wurzel zu lösen? Mit anderen Worten: Gibt es eine Möglichkeit, von Anfang an zu vermeiden, dass so viele Inhalte in den Context eingelesen werden?
2. 过滤(按需加载)Filtering: Laden nach Bedarf
本质上来说,就是按需加载。当我不需要一些内容的时候,就先不要让它们进入Context。只有当我需要的时候,才把他们读进来。
Im Kern geht es um Laden nach Bedarf. Wenn bestimmte Inhalte gerade nicht gebraucht werden, sollten sie zunächst nicht in den Context gelangen. Erst wenn sie wirklich benötigt werden, werden sie eingelesen.
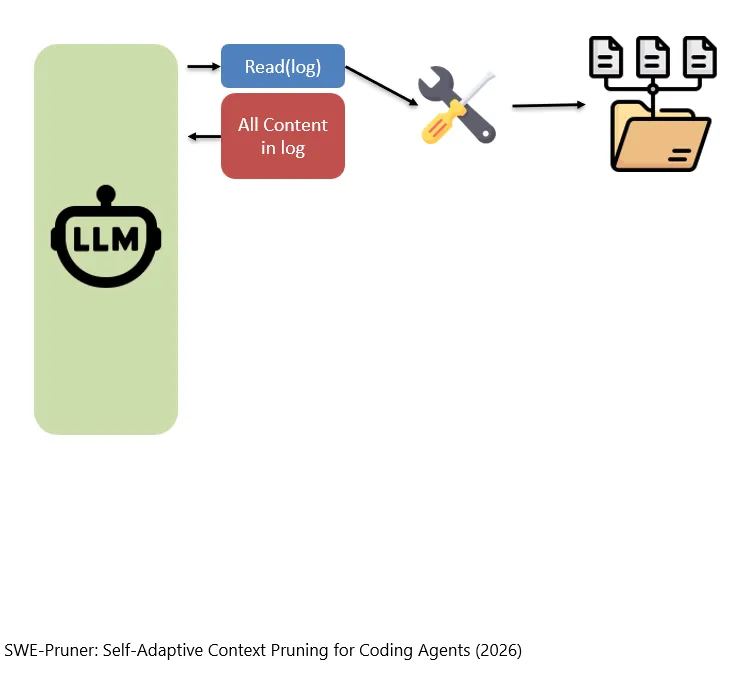
比如,当我们需要读取一些日志的时候,模型就说,请调用Read的工具吧,把log读进来我看一下。
Wenn wir beispielsweise einige Logs lesen müssen, kann das Modell sagen: Bitte rufe das Read-Tool auf und lies den Log ein, damit ich ihn mir ansehen kann.
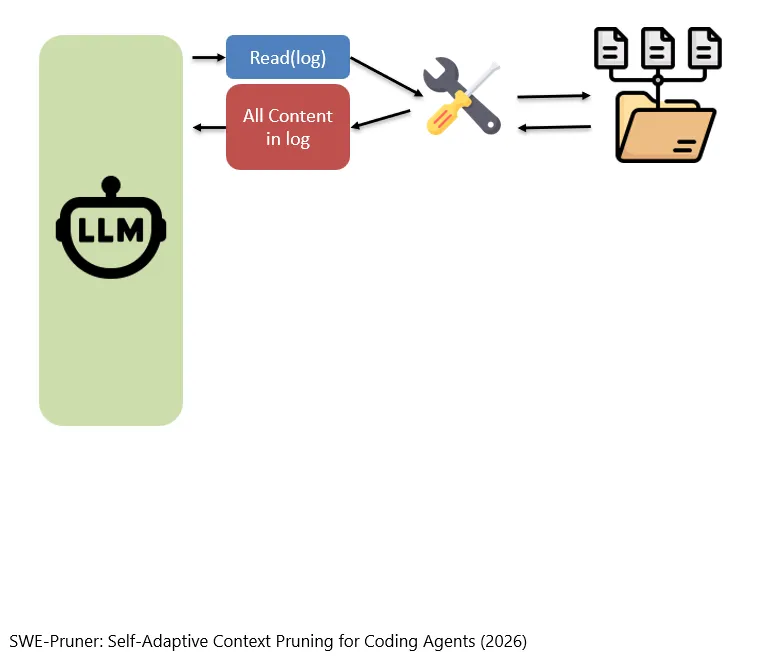
然后这个Read工具就会打开存在硬盘上的log,然后把它读进来。
Dann öffnet dieses Read-Tool den auf der Festplatte gespeicherten Log und liest ihn in den Context ein.
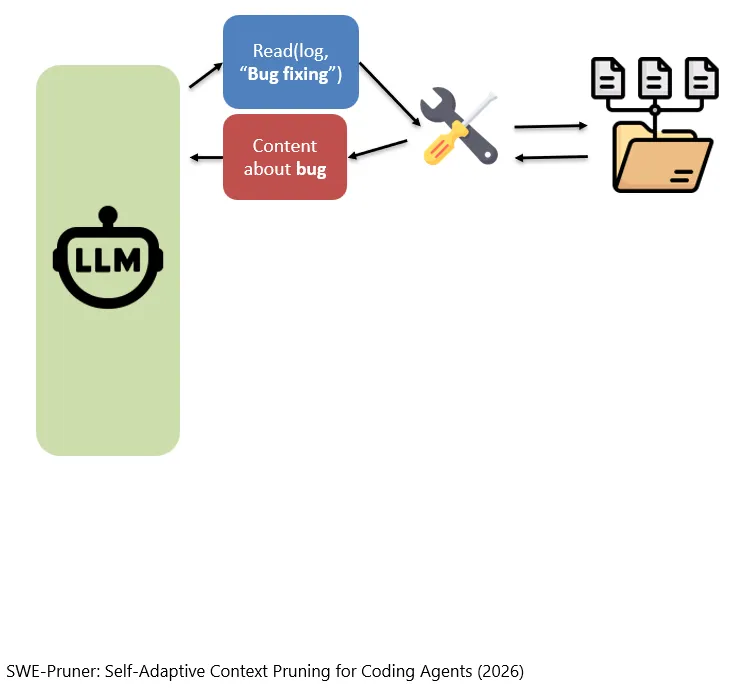
我们也可以把这个工具做的更加精致一些,比如,模型说想要在log中读一下和“Bug Fixing”相关的,那么这个工具就会只返回和“Bug Fixing”相关的日志内容。
Wir können dieses Tool auch noch feiner gestalten. Wenn das Modell beispielsweise sagt, dass es im Log nur die Inhalte im Zusammenhang mit „Bug Fixing“ lesen möchte, gibt das Tool nur jene Log-Inhalte zurück, die mit „Bug Fixing“ relevant zusammenhängen.
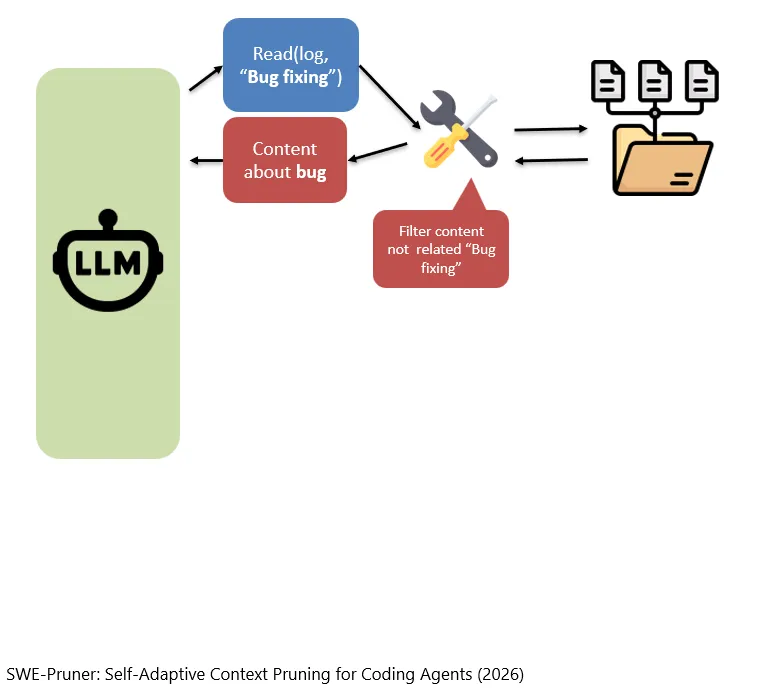
所以,这个工具起到了“过滤”的作用。
Damit übernimmt dieses Tool eine „Filtering“-Funktion.
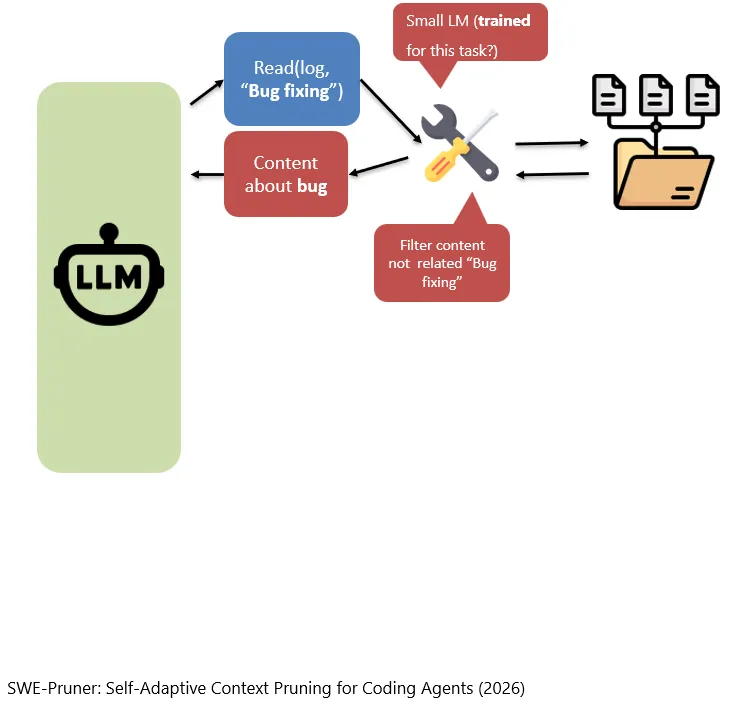
那么,这个所谓的工具,到底是做一些工程上的技巧,还是训练一个小的模型来专门做这件事情,可以根据情况来自行决定。
Was dieses sogenannte Tool genau ist, kann je nach Situation entschieden werden. Es kann sich um bestimmte technische Engineering-Tricks handeln, oder man kann ein kleines Modell trainieren, das speziell diese Aufgabe übernimmt.
总之,就是让这个工具想尽办法更智能一些,让它只读取需要的内容。
Kurz gesagt geht es darum, dieses Tool möglichst intelligent zu machen, damit es nur die Inhalte liest, die tatsächlich benötigt werden.
Memory

之前我们也提到过Agent的体系里面一般会有memory_get这个工具。其实也是使用了类似于过滤的概念:到底要读取哪些记忆到Context中,Agent会自己来决定,而不是全部都读入。
Wir haben bereits erwähnt, dass es im System eines Agents normalerweise ein Tool wie memory_get gibt. Auch hier wird ein ähnliches Filtering-Konzept verwendet: Der Agent entscheidet selbst, welche Erinnerungen in den Context eingelesen werden sollen, statt alle Erinnerungen auf einmal zu laden.
过滤(System Prompt)Filtering im System Prompt
前面我们也提过,System Prompt是一种特殊的Prompt,在每一轮和模型的对话中,这部分内容是都要一直跟着的。
Wie bereits erwähnt, ist der System Prompt eine besondere Art von Prompt. In jeder Runde der Interaktion mit dem Modell wird dieser Teil des Inhalts immer mitgeführt.
在System Prompt中,会放置很多有用的信息。比如模型现在有哪些可以使用的工具,当在对话中万一需要用到哪个工具,模型就可以根据System Prompt中的指引,去找到对应的工具并调用。
Im System Prompt werden viele nützliche Informationen abgelegt. Zum Beispiel kann dort stehen, welche Tools dem Modell derzeit zur Verfügung stehen. Falls im Gespräch ein bestimmtes Tool benötigt wird, kann das Modell anhand der Hinweise im System Prompt das entsprechende Tool finden und aufrufen.
但,在System Prompt中,关于各式各样的tools的信息,我们到底要放多详细呢?还是只放一部分呢?还是...
Aber wie detailliert sollten die Informationen über die verschiedenen Tools im System Prompt eigentlich sein? Sollten wir nur einen Teil davon hineinlegen? Oder sollte man es anders machen?

比如,在上图中,现在有一个关于使用github的工具。如果要把这个工具的信息塞到System Prompt里面,就需要多于4600的tokens呀。
Im obigen Beispiel gibt es etwa ein Tool zur Nutzung von GitHub. Wenn man die Informationen zu diesem Tool in den System Prompt einfügen wollte, bräuchte man mehr als 4.600 Tokens.
而你可能运行一整天,也用不了这个工具几次,但是这4600多个token却一直跟在你和模型的对话中,这不就是在白白烧钱吗?
Vielleicht läuft der Agent einen ganzen Tag lang, und dieses Tool wird nur wenige Male verwendet. Die mehr als 4.600 Tokens würden jedoch die ganze Zeit über jede Interaktion zwischen dir und dem Modell begleiten. Wäre das nicht einfach eine unnötige Verschwendung von Geld?
所以,还是要想办法,不要载入太多的信息。只有需要的之后,再去查阅就好了。
Daher müssen wir weiterhin Wege finden, nicht zu viele Informationen zu laden. Erst wenn sie benötigt werden, sollte das Modell sie nachschlagen.
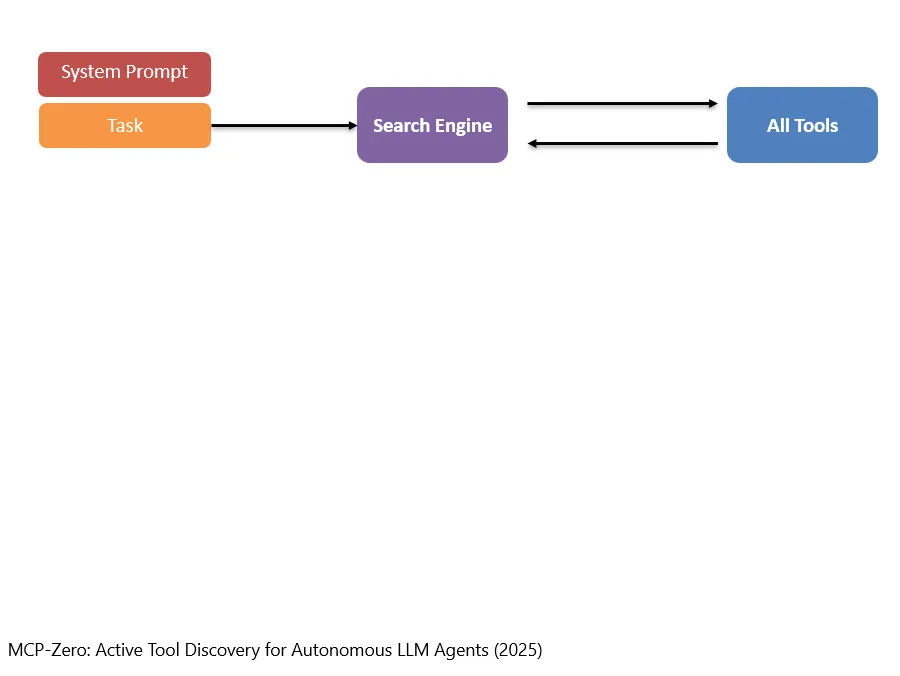
一种传统的思路是说:就先不加载可以用的tools。只有当一个task,需要寻找合适的工具时,就使用类似于RAG的概念,去搜索有哪些工具可以用。
Ein traditioneller Ansatz besteht darin, die verfügbaren Tools zunächst nicht zu laden. Erst wenn eine Aufgabe ein geeignetes Tool erfordert, nutzt man ein RAG-ähnliches Konzept, um zu suchen, welche Tools verfügbar sein könnten.
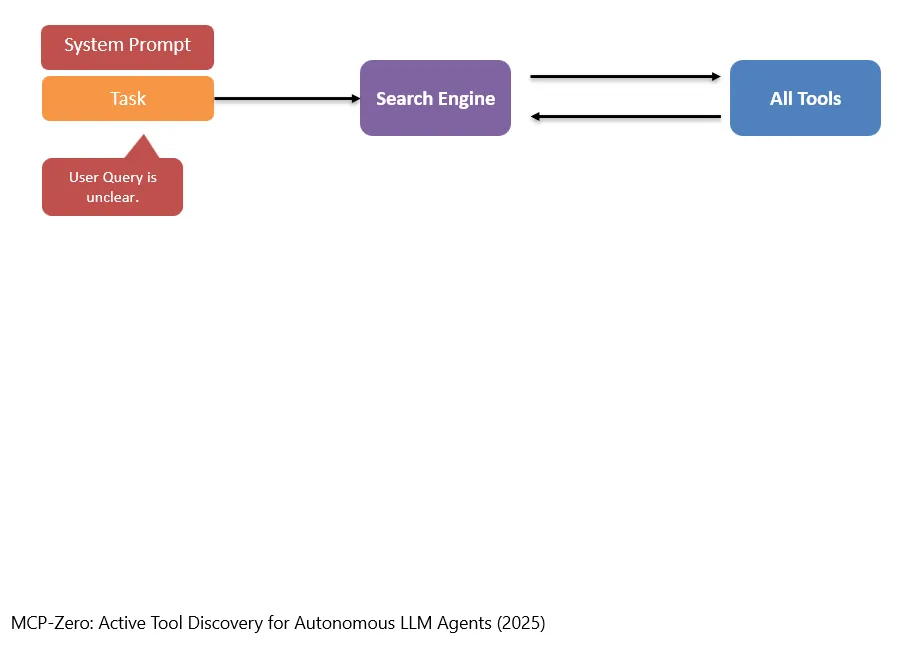
但其实这种方法往往表现的不是很好,因为很多时候,用户的需求(也就是对task的描述和定义)是很模糊的,很难直接根据他们的描述来搜索使用哪些工具。
In der Praxis funktioniert diese Methode jedoch häufig nicht besonders gut. Denn die Bedürfnisse der Nutzerinnen und Nutzer, also die Beschreibung und Definition der Aufgabe, sind oft sehr vage. Es ist schwierig, allein anhand dieser Beschreibung direkt nach den passenden Tools zu suchen.
比如,task是想让模型去修复某个bug。但很可能完成这个任务不是只用一个工具就可以了,有可能需要Read工具、编辑的工具等等。但仅仅根据用户的描述,很难让搜索引擎自己一下子决定使用哪些工具。
Ein Beispiel: Die Aufgabe besteht darin, das Modell einen bestimmten Bug beheben zu lassen. Wahrscheinlich reicht dafür aber nicht nur ein einziges Tool aus. Möglicherweise braucht man ein Read-Tool, ein Editing-Tool und weitere Tools. Allein anhand der Beschreibung der Nutzerin oder des Nutzers ist es für die Suchmaschine schwer, sofort selbst zu entscheiden, welche Tools verwendet werden sollten.
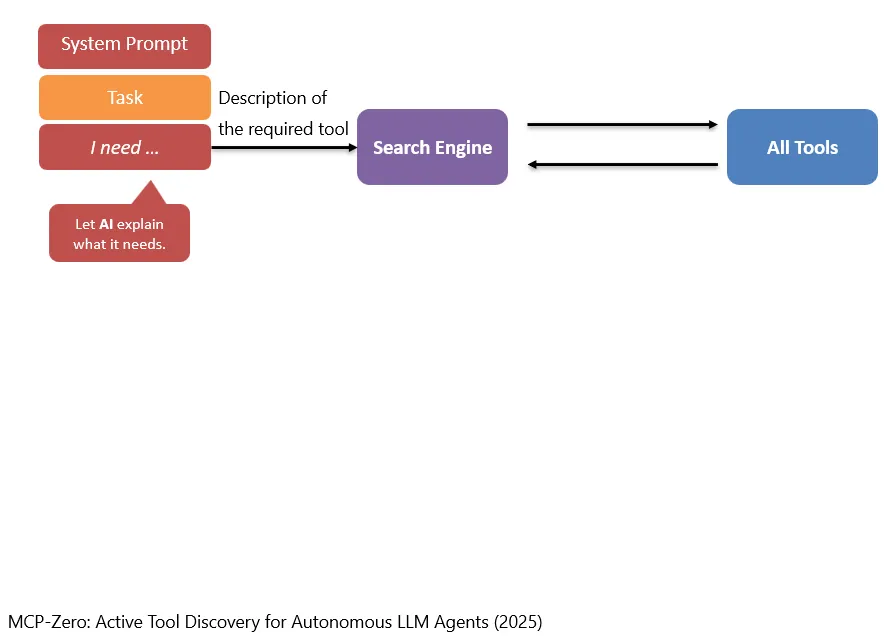
所以,一个可以考虑的改进思路是:让AI模型自己去决定,它想要什么工具,也就是让他自己讲出来“Description of the required tool”。
Ein möglicher Verbesserungsansatz besteht deshalb darin, das AI-Modell selbst entscheiden zu lassen, welche Art von Tool es benötigt. Mit anderen Worten: Das Modell formuliert selbst eine „Description of the required tool“.
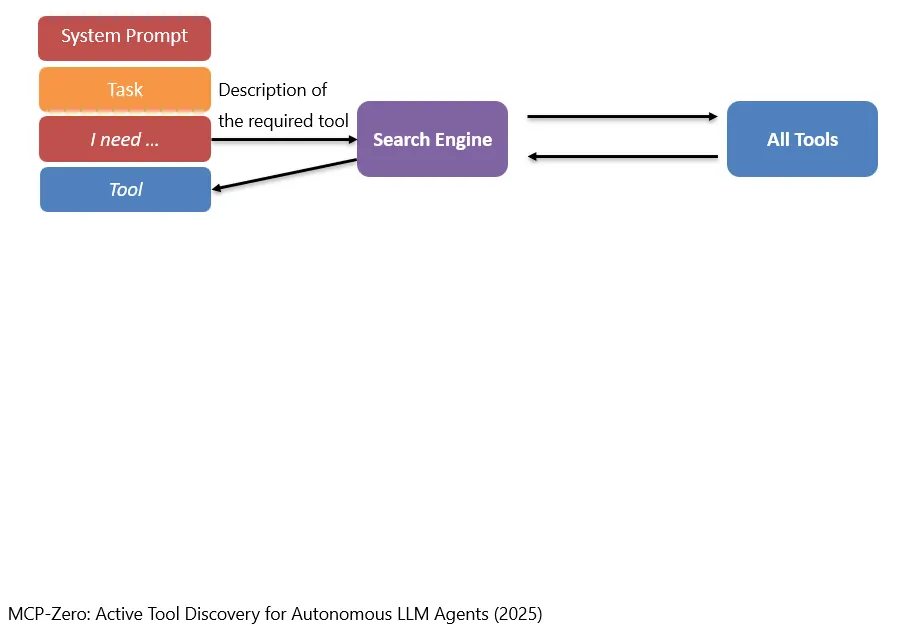
讲出来之后,搜索引擎再发挥它的作用。
Nachdem diese Beschreibung erzeugt wurde, kann die Suchmaschine ihre Rolle übernehmen.
Skill
之前我们也提到过Agent中的Skill的概念,当我们用户提出一个任务,如果Agent中有预先装好的Skill并且适合这个任务,那么Agent就会去调用这个Skill来完成任务。
Wir haben zuvor auch das Konzept des Skills in einem Agent erwähnt. Wenn Nutzerinnen oder Nutzer eine Aufgabe stellen und der Agent über einen vorinstallierten Skill verfügt, der zu dieser Aufgabe passt, ruft der Agent diesen Skill auf, um die Aufgabe zu erledigen.
这里,其实也是采用了按需加载的概念。也就是说,Agent不会把Skill的详细内容,一下子全部载入到Context中。
Auch hier wird im Grunde das Konzept des Ladens nach Bedarf verwendet. Das heisst, der Agent lädt nicht den gesamten detaillierten Inhalt eines Skills auf einmal in den Context.
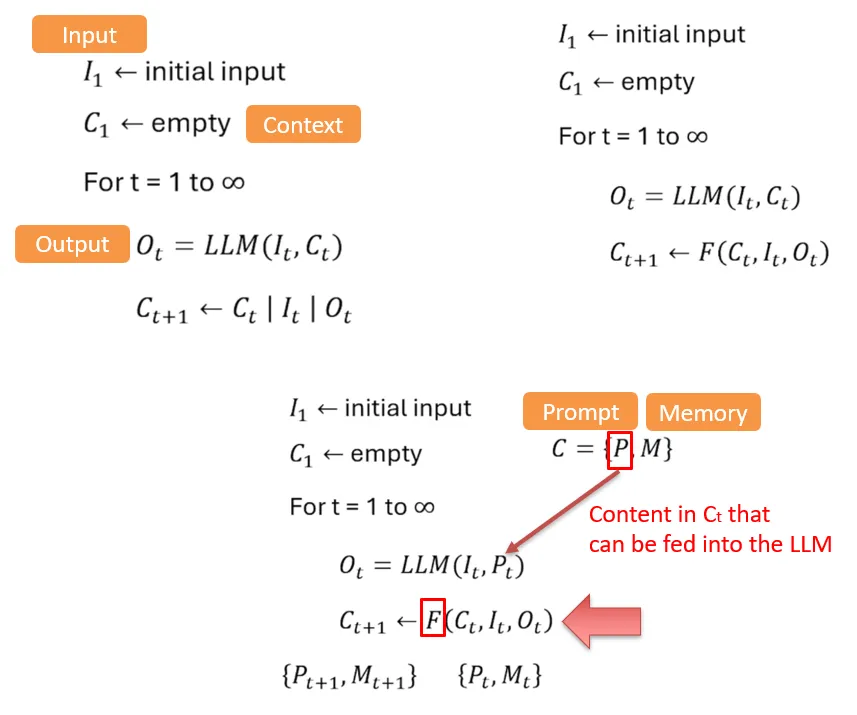
那,我们现在再次返回看一下这个公式。在F这个函数中(根据当前的Context,输入和模型的输出来决定新的Context包含哪些内容),大部分来说其实都是由人类自己来决定的。
Kehren wir nun noch einmal zu dieser Formel zurück. In der Funktion F, die anhand des aktuellen Context, der Eingabe und der Ausgabe des Modells entscheidet, welche Inhalte im neuen Context enthalten sein sollen, wird der grösste Teil im Grunde von Menschen festgelegt.
换句话说,是我们人类再想进各式各样的方法(无论是工程上的技巧,还是我们在训练一些小的模型来辅助完成这个任务)来完成F函数的工作。
Mit anderen Worten: Wir Menschen versuchen, mit verschiedensten Methoden die Arbeit der Funktion F zu erledigen, sei es durch Engineering-Techniken oder durch kleine Modelle, die speziell dafür trainiert werden, diese Aufgabe zu unterstützen.
模型自己来想办法做Context Engineering (Das Modell selbst Wege für Context Engineering finden lassen)
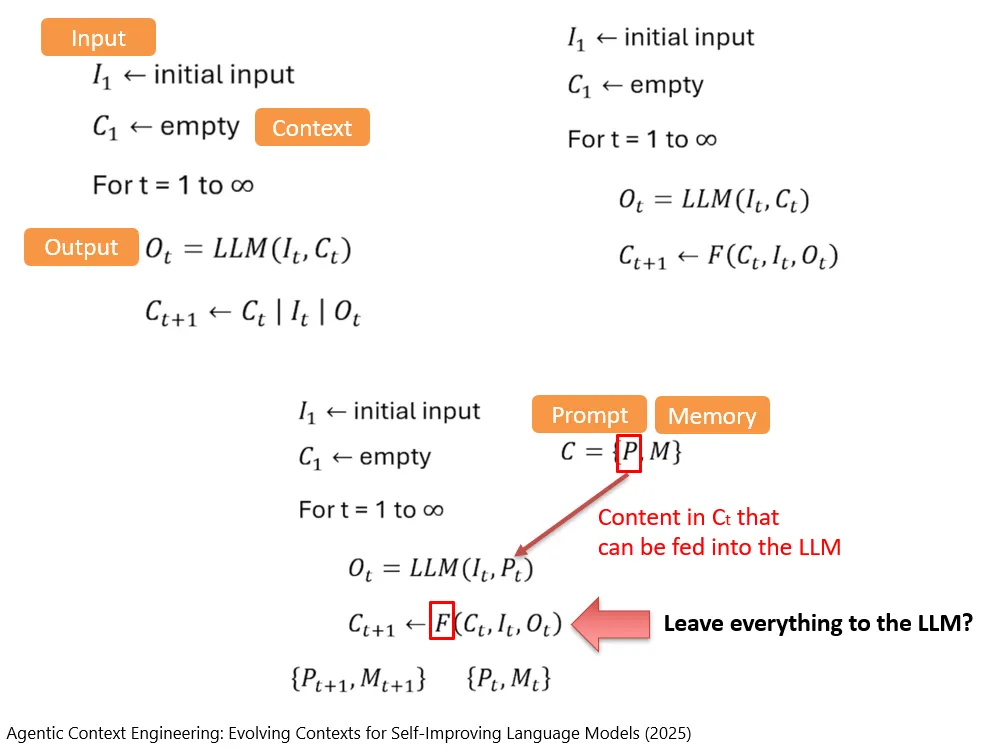
那,有没有可能,让这部分变得更加智能一些呢?也就是,我们人类不会想尽办法来给他做Context Engineering,而是模型自己去想办法,它自己随便怎么折腾自己的Context。
Gibt es also eine Möglichkeit, diesen Teil intelligenter zu machen? Anders gesagt: Statt dass wir Menschen versuchen, für das Modell Context Engineering zu betreiben, könnte das Modell selbst Wege finden, mit seinem eigenen Context umzugehen, ganz gleich, wie es diesen Context bearbeiten möchte.
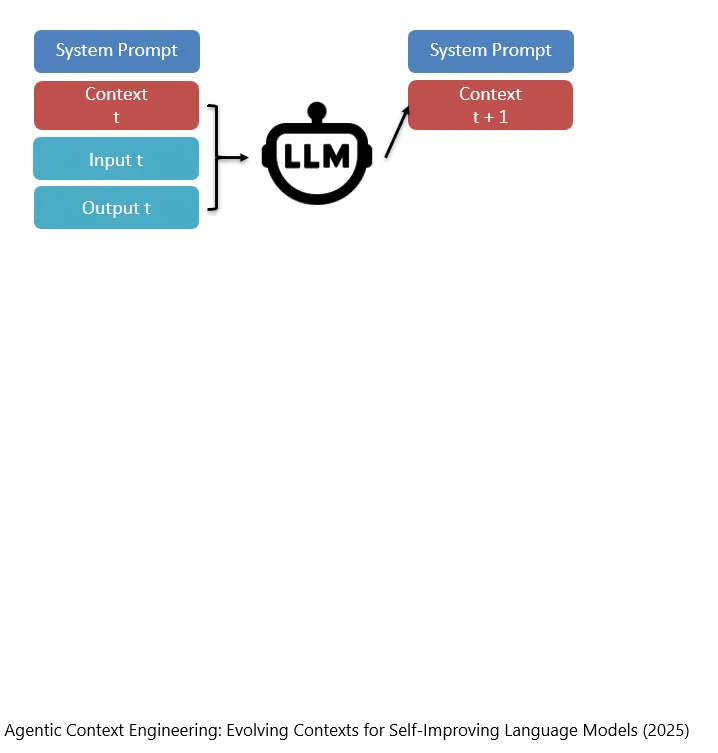
比如在这篇论文中,当产生Context_t和Input_t和Output_t之后,然后模型自己根据这三者去产生新的Context_{t+1}。
In dieser Studie wird beispielsweise, nachdem Context_t, Input_t und Output_t erzeugt wurden, vom Modell selbst auf Grundlage dieser drei Elemente ein neuer Context_{t+1} erzeugt.
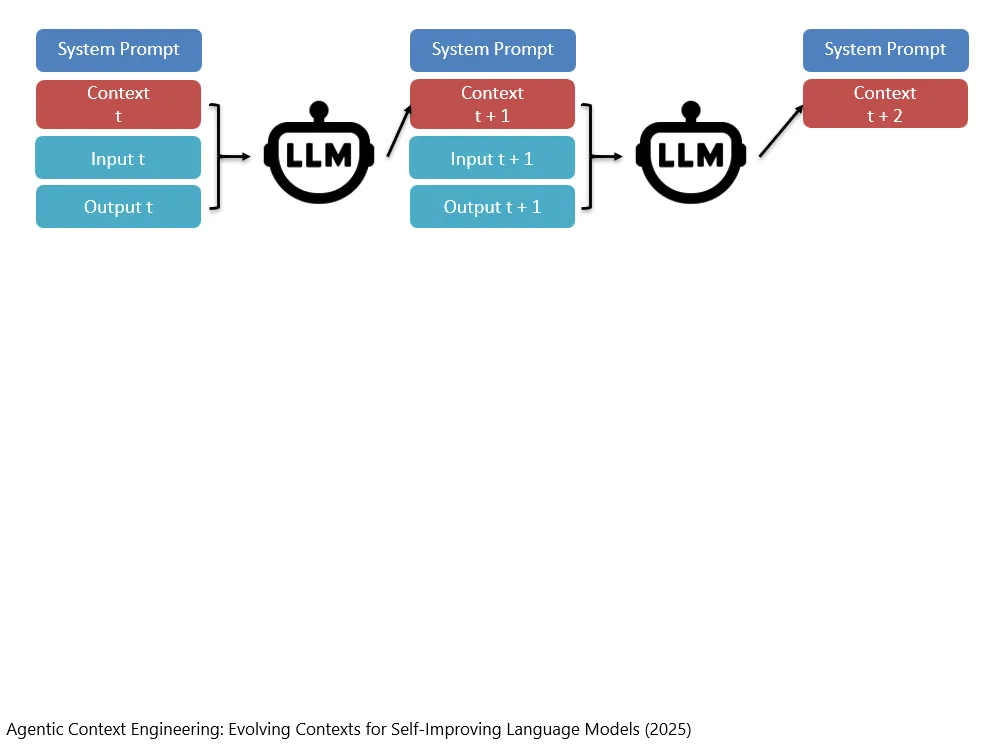
然后以此类推,得到Context_{t+2}。
Nach derselben Logik erhält man dann Context_{t+2}.
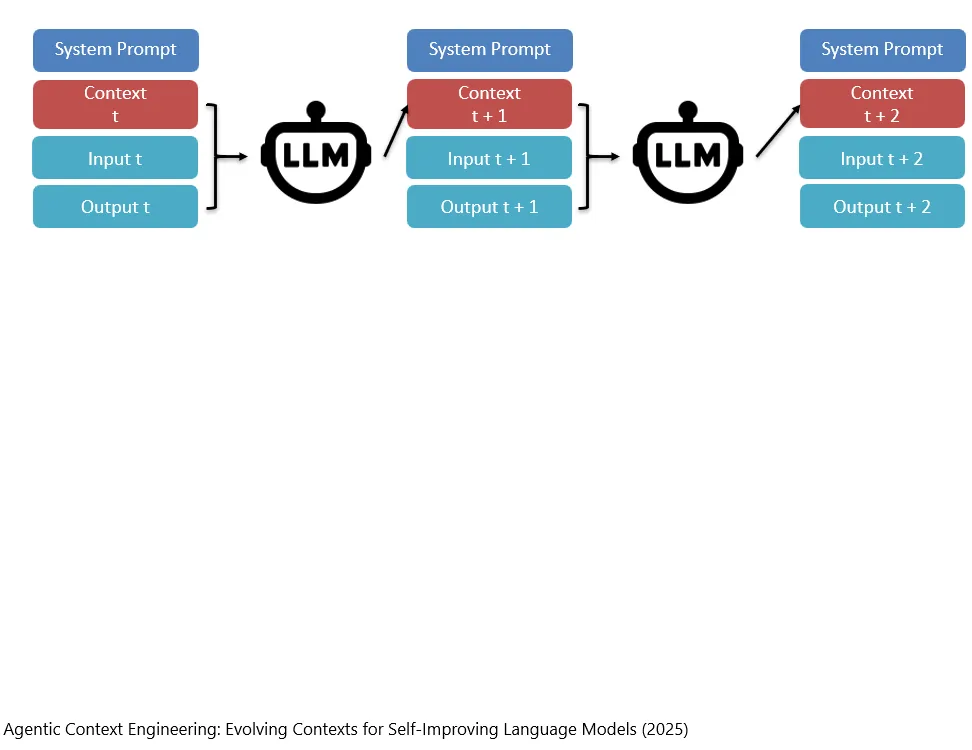
再然后一直执行下去。
Danach wird dieser Prozess fortlaufend weitergeführt.
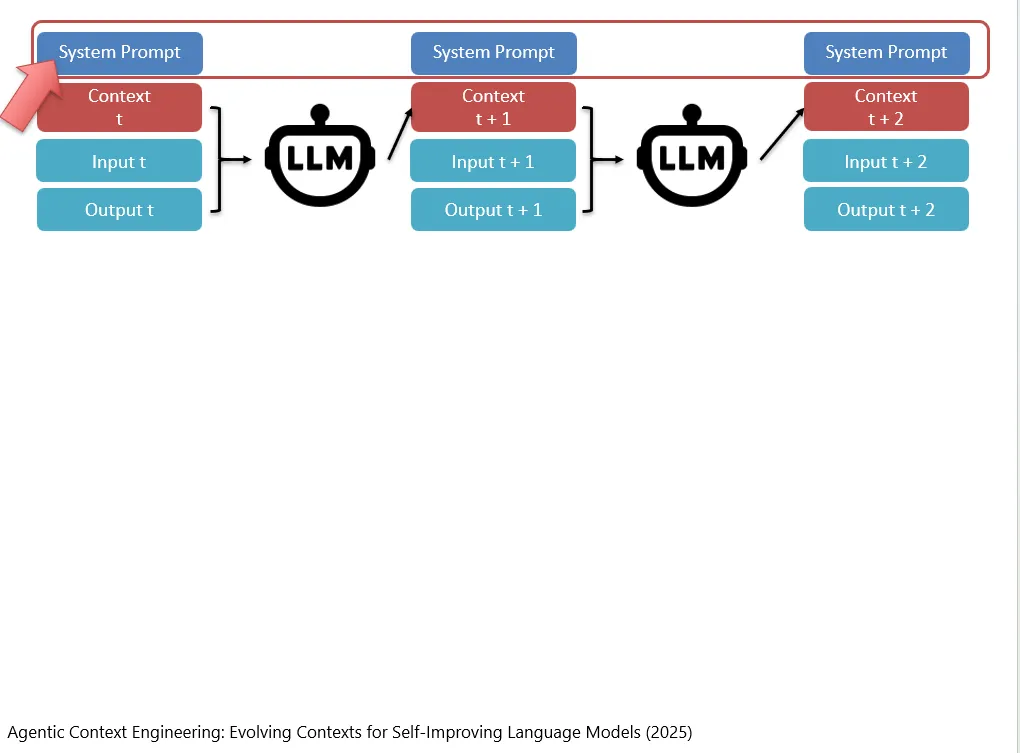
其实,你会发现,比较重要的内容(比如System Prompt)是没有参与这个过程的。也就是说,在类似的工作中,我们可以专门留出来Context中的一部分让LLM模型一定不要碰,以及也专门有一部分是给LLM来随便玩的,它愿意在里面放什么内容就放什么。
Dabei stellt man fest, dass wichtigere Inhalte, zum Beispiel der System Prompt, an diesem Prozess nicht beteiligt sind. In ähnlichen Arbeiten kann man also gezielt einen Teil des Context reservieren, den das LLM auf keinen Fall berühren darf, und zugleich einen anderen Teil bereitstellen, mit dem das LLM frei arbeiten kann. In diesen Bereich kann das Modell dann einfügen, was es möchte.
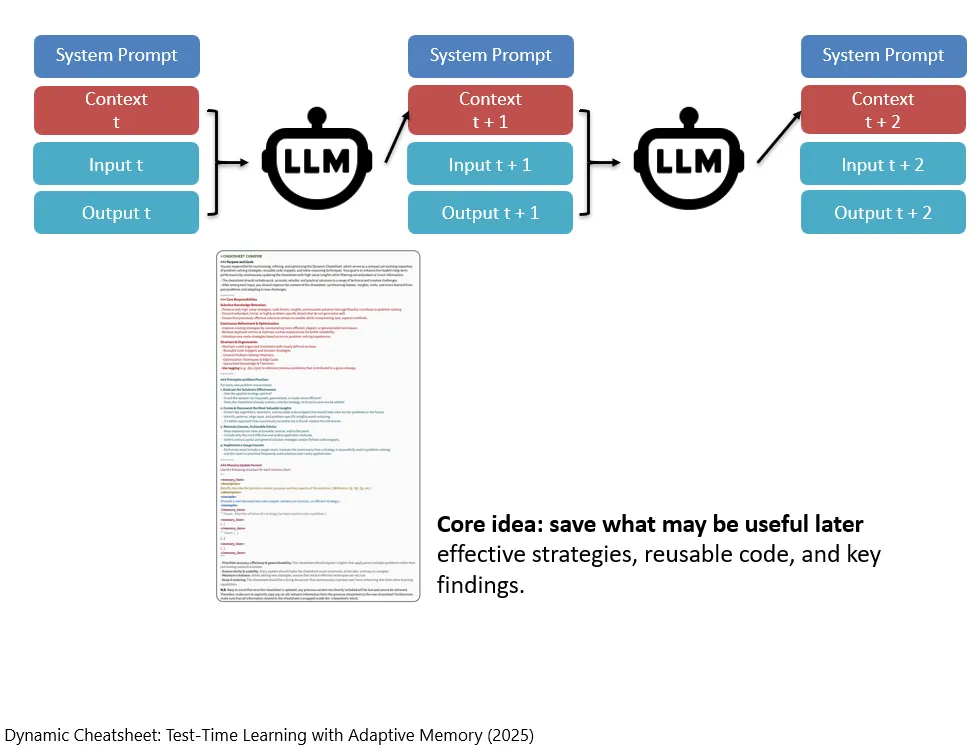
当然了,LLM模型自己去生成下一轮的Context这件事情,也不是随便让它自己瞎做的。我们人类是可以给他一定的指导。比如在这篇论文中,作者们给它的指导就有这么长(大概精神是过于具体的记录以后很可能用不上了,就没有必要保存了;只需要保留一些有效的经验策略、可重用的code和一些关键的发现)。
Natürlich bedeutet es nicht, dass das LLM den Context der nächsten Runde völlig blind erzeugen darf. Menschen können ihm weiterhin bestimmte Anweisungen geben. In dieser Studie geben die Autorinnen und Autoren dem Modell beispielsweise eine ziemlich lange Anleitung. Der Grundgedanke ist ungefähr folgender: Zu konkrete Aufzeichnungen werden später wahrscheinlich nicht mehr nützlich sein und müssen daher nicht gespeichert werden. Beibehalten werden sollten nur wirksame Erfahrungsstrategien, wiederverwendbarer Code und einige zentrale Erkenntnisse.
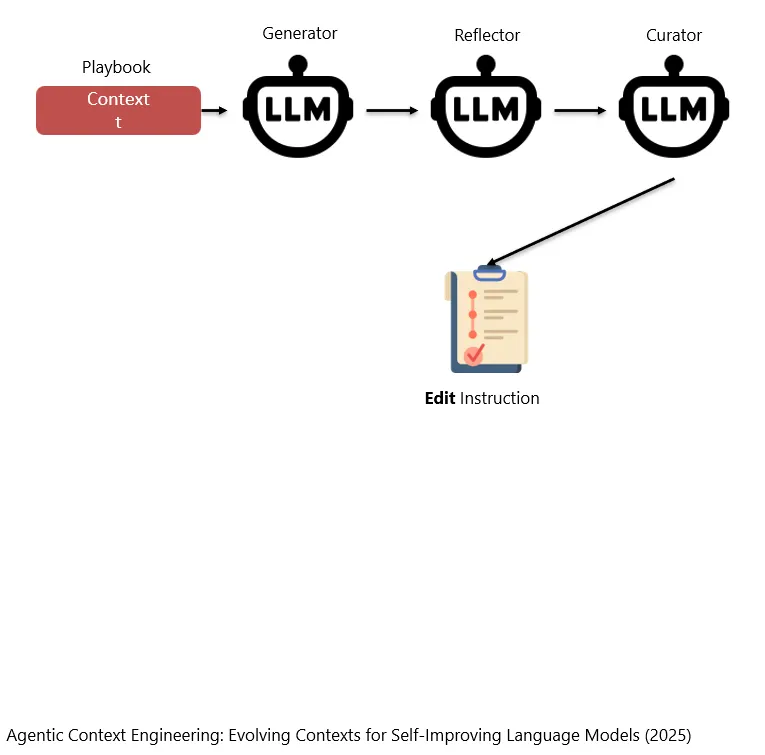
与上一篇论文不同,这篇论文做了更复杂的事情。(注意:在这篇论文中,他们把Context称作Playbook)。
Im Unterschied zur vorherigen Studie macht diese Arbeit etwas Komplexeres. Hinweis: In dieser Studie wird der Context als Playbook bezeichnet.
在这个工作中,Context不是仅仅经过一个模型,而是要经过3个模型。这3个模型分别做过不同方面的检查之后,不会直接产生新的Context(因为直接产生新的Context可能会损坏一些关键内容),而是会先生成一个如何修改Context的指令(Edit Instruction)。
In dieser Arbeit durchläuft der Context nicht nur ein einziges Modell, sondern drei Modelle. Nachdem diese drei Modelle jeweils Prüfungen aus unterschiedlichen Perspektiven durchgeführt haben, erzeugen sie nicht direkt einen neuen Context, denn eine direkte Erzeugung eines neuen Context könnte wichtige Inhalte beschädigen. Stattdessen erzeugen sie zunächst eine Anweisung dazu, wie der Context geändert werden soll, also eine Edit Instruction.
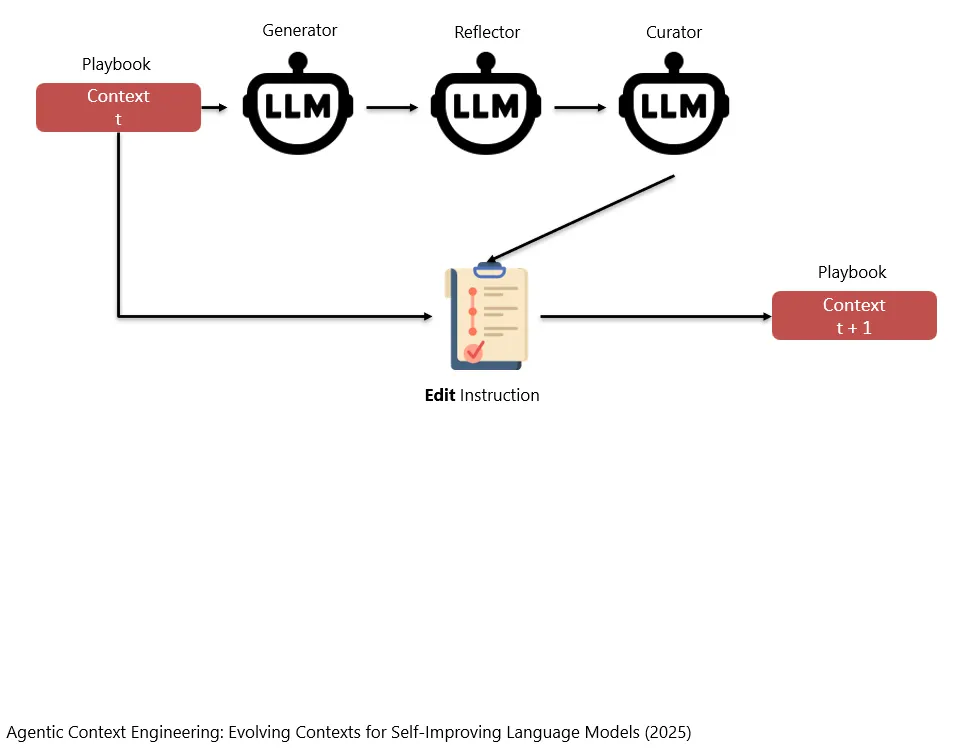
根据这个Edit Instruction,再去生成新的Context。
Auf Grundlage dieser Edit Instruction wird anschliessend ein neuer Context erzeugt.
存在硬盘上的Context (Auf der Festplatte gespeicherter Context)

还有一种情况是,上下文特别特别特别的长,一直长到了要存在硬盘上再行。
Es gibt noch eine weitere Situation: Der Context wird extrem lang, so lang, dass er auf der Festplatte gespeichert werden muss.
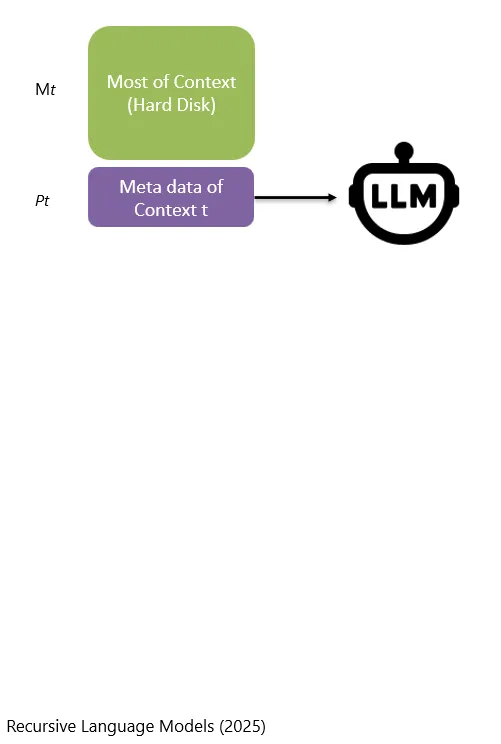
那在实际的运行过程中,其实只需要载入一小部分关键的信息到实时的Context中。在这篇论文中,这些关键信息叫做metadata。比如说:这个Context的全文到底有多长、被切成了几段、存放在了哪里等。
Im tatsächlichen Ablauf muss nur ein kleiner Teil wichtiger Informationen in den Echtzeit-Context geladen werden. In dieser Studie werden diese wichtigen Informationen als metadata bezeichnet. Dazu gehört zum Beispiel, wie lang der vollständige Context ist, in wie viele Abschnitte er aufgeteilt wurde, wo er gespeichert ist und so weiter.
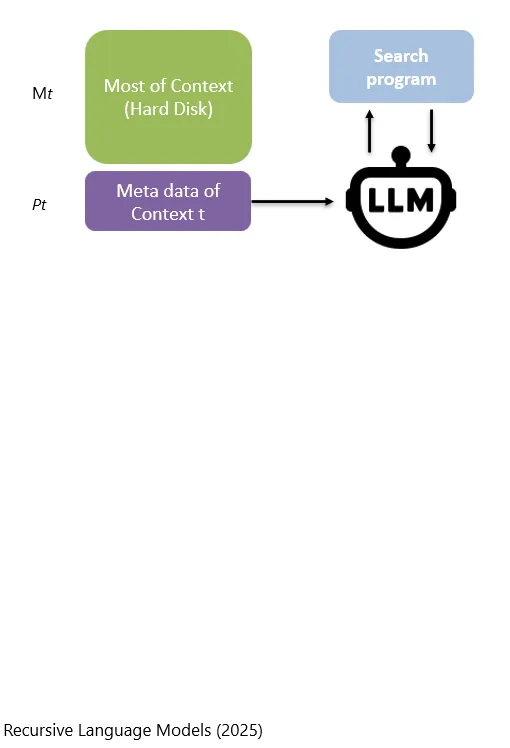
LLM模型会根据这些metadata(P_t),看看需要读取硬盘(M_t)中的哪些资料。
Das LLM entscheidet anhand dieser metadata, P_t, welche Materialien es von der Festplatte, M_t, lesen muss.
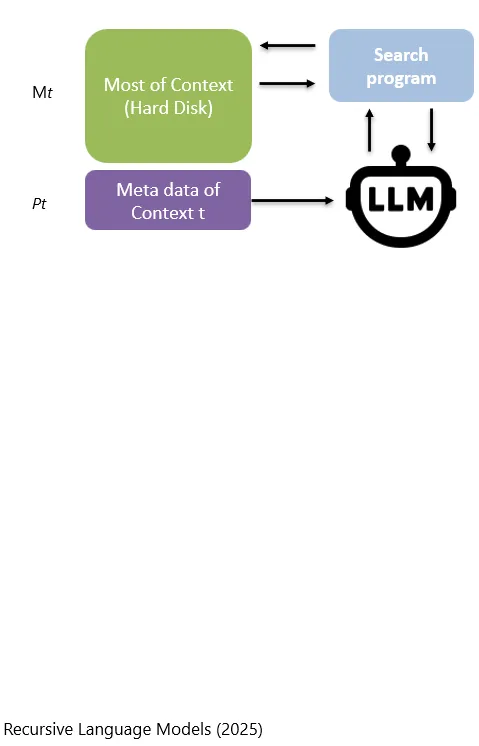
当然了,LLM也可以自己去写以及执行程序,去对硬盘中的内容做搜寻,他自己可以去做RAG把必要的信息拿出来,然后去修改他的metadata。
Natürlich kann das LLM auch selbst Programme schreiben und ausführen, um die auf der Festplatte gespeicherten Inhalte zu durchsuchen. Es kann eigenständig RAG durchführen, die benötigten Informationen herausholen und anschliessend seine metadata ändern.
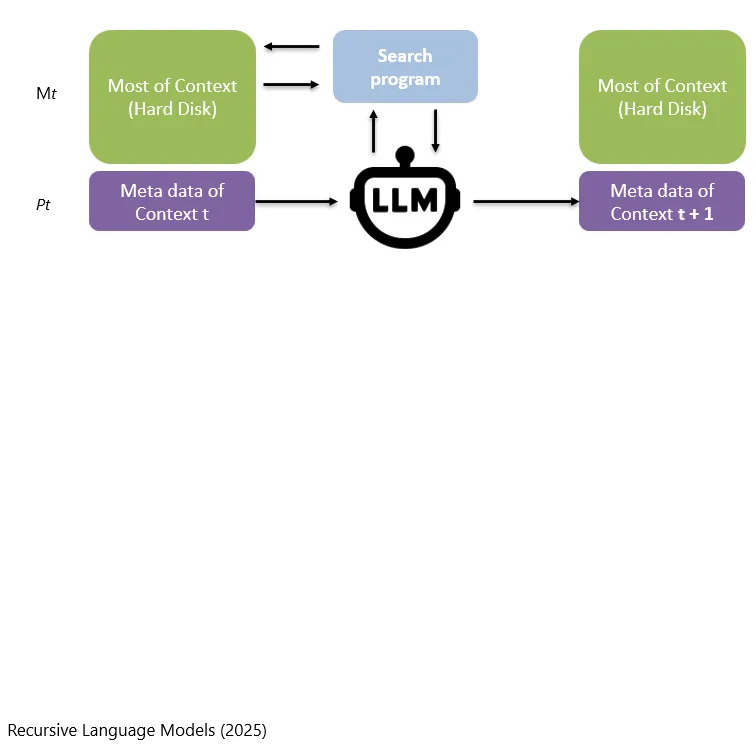
总之,这其中怎么引导LLM或者让LLM去用更好的方法去完成Context Engineering这件事情,是需要做Prompt engineering的,也就是说在给LLM看的Prompt中,要不断的、努力的尝试和暗示LLM模型在必要的时候去调用RAG的方式,去搜索需要的资料。
Insgesamt erfordert die Frage, wie man das LLM anleitet oder dazu bringt, bessere Methoden für Context Engineering zu verwenden, weiterhin Prompt Engineering. Das bedeutet: In dem Prompt, den das LLM sieht, muss man immer wieder versuchen, dem Modell Hinweise zu geben, dass es bei Bedarf RAG verwenden soll, um nach den benötigten Materialien zu suchen.
所以,其实并没有什么特别的魔法突然一下子让模型的Context Engieneering突然变得特别好。
Daher gibt es eigentlich keine besondere Magie, durch die das Context Engineering des Modells plötzlich auf einmal aussergewöhnlich gut wird.
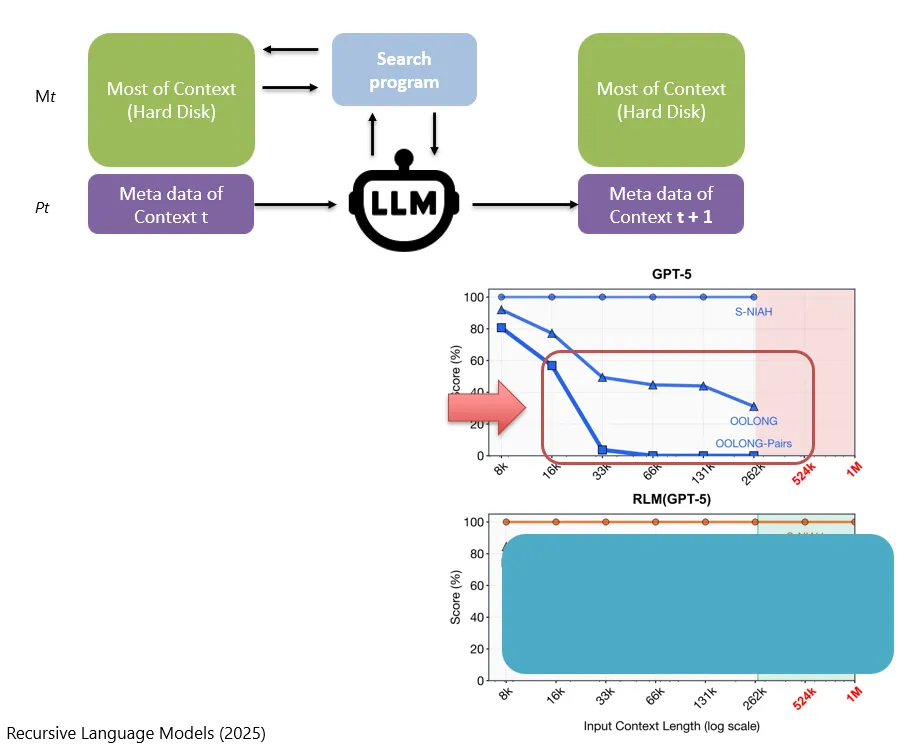
虽然这个方法看起来没有什么太神奇的地方,不过实际的表现效果是好的。在这个图中,上半部分是不采用这篇论文方法的表现,可以看的出来,随着token越来越长,在一些任务上的效果是有明显的下降的。
Auch wenn diese Methode auf den ersten Blick nicht besonders magisch wirkt, ist ihre tatsächliche Leistung gut. In dieser Abbildung zeigt die obere Hälfte die Leistung ohne die Methode aus dieser Studie. Man kann erkennen, dass die Leistung bei einigen Aufgaben deutlich abnimmt, je länger die Tokens werden.
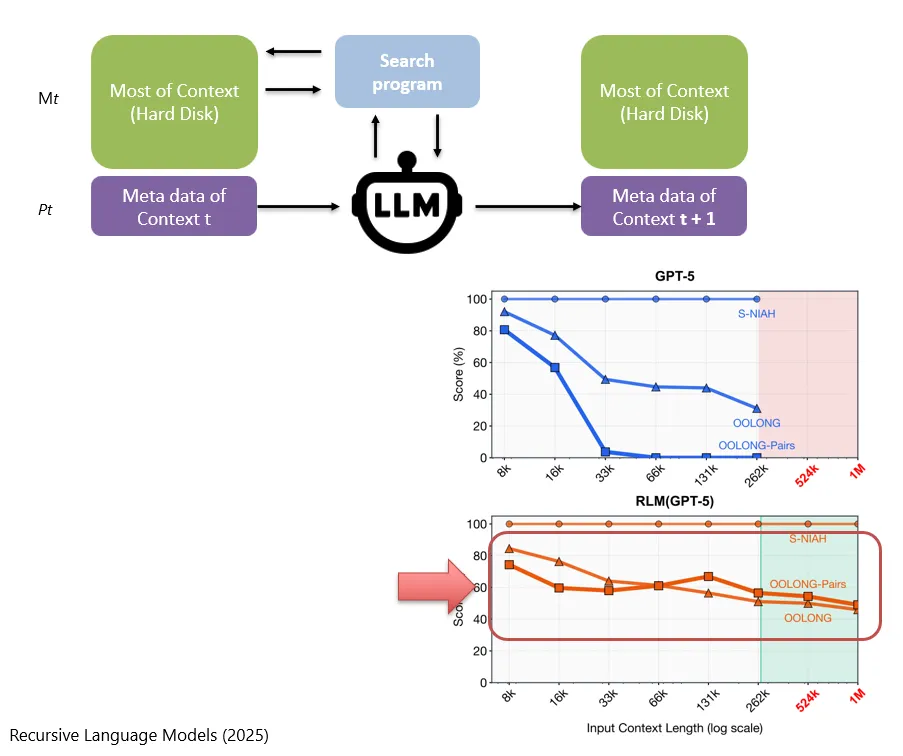
而如果采取这篇论文的做法,即使token变得很长,仍然可以收获不错的效果。
Wenn man hingegen die Methode dieser Studie verwendet, lassen sich auch dann noch gute Ergebnisse erzielen, wenn die Zahl der Tokens sehr gross wird.
更重要的是,这个方法其实更像是一种机制,可以应用到任何的LLM上,而不是只有特定的LLM可以使用。
More importantly, this method is more like a general mechanism. It can be applied to any LLM, rather than being limited to a specific model.
