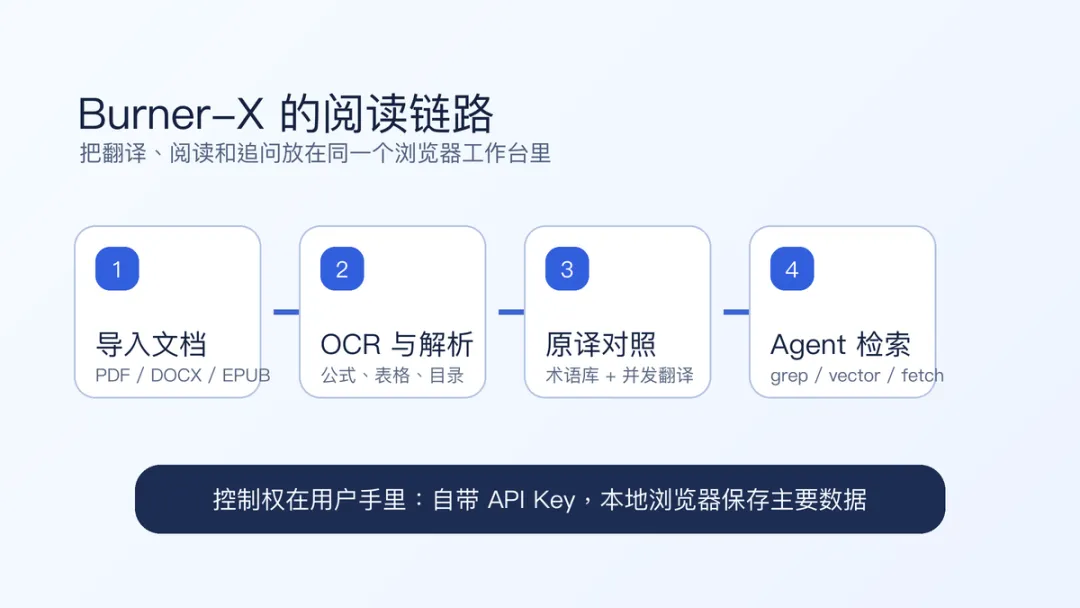
这个项目最值得注意的,不只是“支持很多格式”。README 里写到,它在前端实现了一个 Agentic RAG 系统。项目会给 AI 一份文章结构,再配上grep、vector search、fetch等工具,让 AI 面对长文本时自己判断该怎么找答案。这和普通“把全文塞给模型总结一下”不太一样。论文一长,直接问模型很容易出现两个问题:要么上下文太长,模型只抓到前面一部分;要么回答看起来完整,但你不知道它到底引用了哪一段。如果有目录、段落结构、关键词检索和向量检索,AI 至少可以先定位,再回答。对读论文来说,这比一段漂亮总结更有用。比如你可以先读原译对照,再追问某个概念;也可以让它整理论文贡献、实验设置、局限性,或者生成思维导图、流程图。它更像一个陪读工具,而不是只负责把英文改成中文的翻译接口。
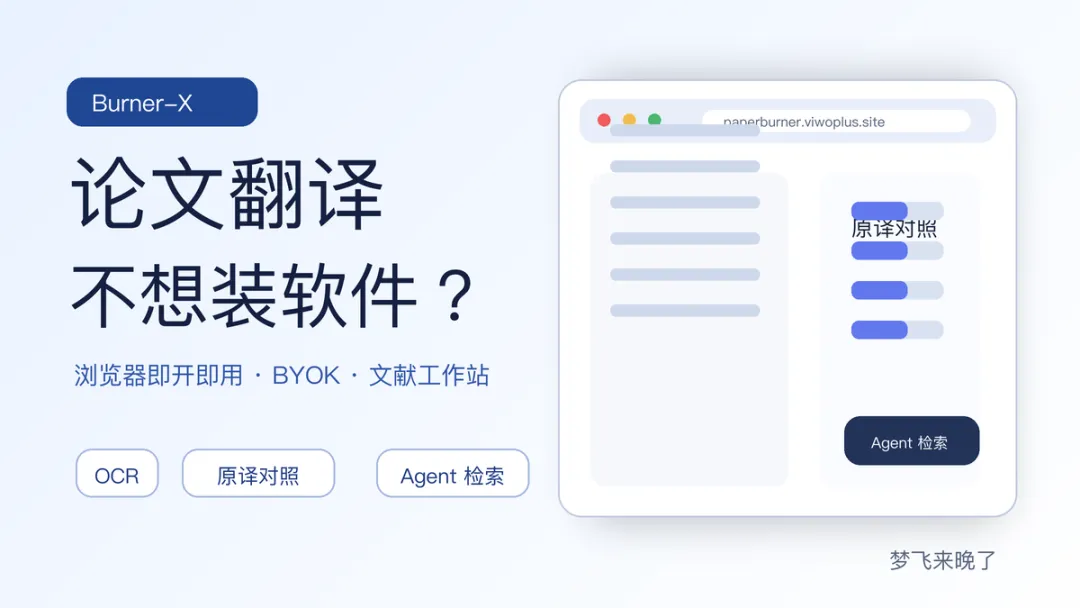
纯前端和 BYOK 是它的现实卖点
Burner-X 现在一个很大的卖点,是纯前端模式。README 写得很清楚:个人使用推荐直接部署到 Vercel,数据存储在浏览器localStorage/IndexedDB中,不会上传到服务器。你需要自己配置 OCR 和模型 API Key,比如 MinerU、Doc2X、Mistral、DeepSeek、Gemini、Claude、通义千问、火山引擎,或者自定义模型端点。这就是典型的 BYOK:Bring Your Own Key。好处是控制权在你手里。你的文档、历史记录和配置主要留在本地浏览器里,模型服务也由你自己选。代价也很明显:它不是完全零门槛工具。你要理解 API Key、OCR 服务、模型端点这些东西,也要自己接受调用成本和服务稳定性。
现在适合怎么用
截至我查看 GitHub API,Feather-2/Burner-X大约是 1.7k stars、658 forks、7 个 open issues,主语言是 JavaScript,许可证是 AGPL-3.0。这个热度说明它确实踩中了需求:很多人不是不想用 AI 读文献,而是不想在 PDF 阅读器、翻译器、OCR、笔记工具和聊天窗口之间来回搬运。不过也要保守一点。README 开头提示“项目分前端版本和后端版本,目前后端版本构建中,请暂时不要拉取 docker 镜像”。所以普通用户现在更适合先试纯前端体验,不要把 Docker 完整部署当成最稳路径。另外,浏览器本地存储不是永久保险箱。清理浏览器数据、换设备、换浏览器,都可能影响历史记录。重要文档和配置,最好还是自己备份。如果你准备二次开发或者做成对外服务,还要认真看 AGPL-3.0 许可证要求。
梦飞的判断
我觉得 Burner-X 值得关注,是因为它抓住了论文阅读里的真实痛点。大多数人不是缺一个“翻译按钮”,而是缺一条完整工作流:导入文档,保留结构,统一术语,原译对照,遇到看不懂的地方能继续追问,最后还能把阅读结果导出去。Burner-X 把这些东西先放进浏览器里,方向是对的。它现在还不像成熟商业工具那样开箱即满分,后端和离线能力也还在迭代。但如果你经常读英文论文、技术报告,或者需要处理一批文档,它已经值得试一下。尤其是你不想把所有文档都交给某个封闭平台,又愿意自己配置模型和 API Key,这个项目会很对胃口。热点来晚了,但瓜更熟。梦飞帮你补错过的全网热事。
话题标签
#AI文献阅读 #论文翻译 #开源工具 #GitHub项目 #科研工具
基本文件流程错误SQL调试
请求信息 : 2026-05-17 06:56:53 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/628094.html
 夜雨聆风
夜雨聆风