 夜雨聆风
夜雨聆风关注公众号,第一时间获取优质开源项目推荐

你一定经历过这个场景:上次对话里千叮咛万嘱咐"用 jose 做 JWT 认证,不要用 jsonwebtoken",下次开新会话,AI 又问"你用的是 jsonwebtoken 吗?"。CLAUDE.md 和 MEMORY.md 能缓解一点,但 200 行上限、手动维护、内容过时——这些痛点每个重度用户都懂。agentmemory 用一个更根本的方式解决了这个问题:自动捕获、自动压缩、自动注入,开发者什么都不用做。
项目简介
agentmemory 是一个专为 AI 编程助手设计的持久化记忆系统。它作为后台服务运行,通过 Agent 生命周期 Hooks 自动记录每次工具调用的上下文,将原始信息压缩为结构化的记忆(观察、模式、决策、错误修复、偏好),然后在新会话启动时自动注入相关记忆。
核心卖点只有四个字:全自动、零配置。一条 npx 命令启动,从此 AI 助手拥有了跨会话的持久记忆。
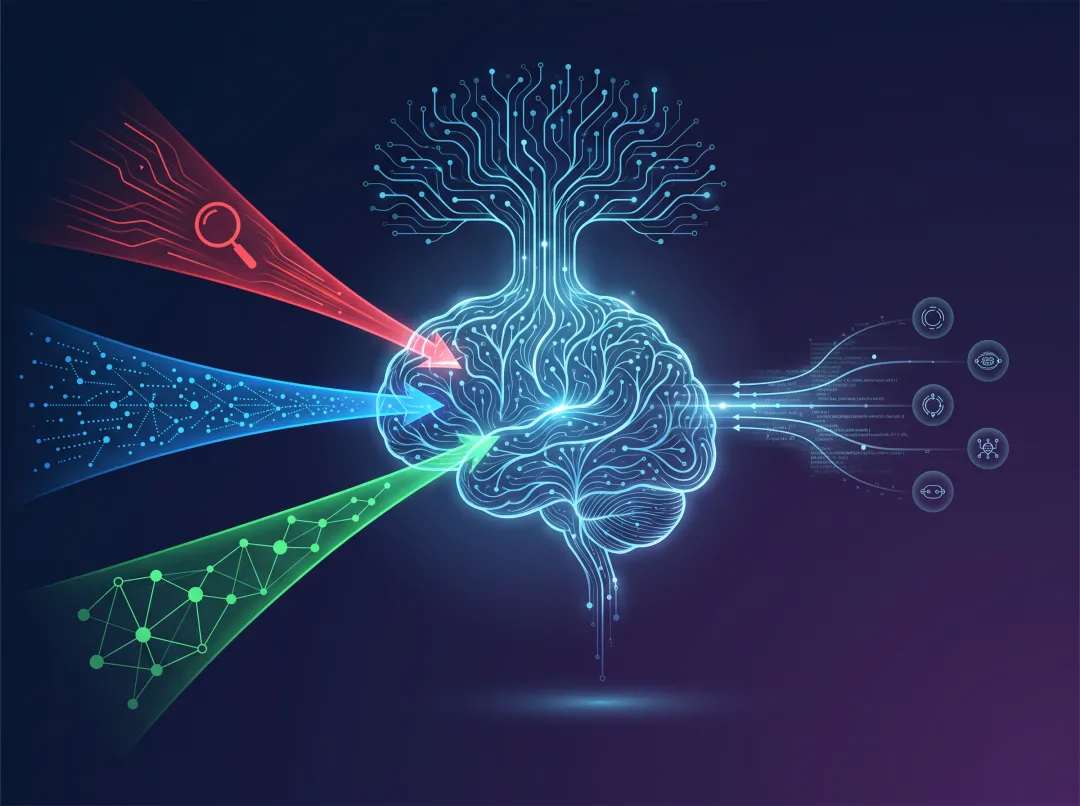
上图展示了 agentmemory 的三路混合检索架构——BM25 关键词搜索、向量语义搜索、知识图谱关系搜索三路并行,共同保障记忆召回的准确性和覆盖度。
项目信息卡片
⭐ Stars: 8.4K 🔧 主要语言: TypeScript + Rust (iii-engine) 📅 创建时间: 2026年2月 📜 协议: MIT 🏠 官网: agent-memory.dev 🔗 GitHub: rohitg00/agentmemory
Star 增长趋势
痛点:为什么现有方案不够好
在 agentmemory 出现之前,AI 编程助手的记忆方案主要有三种:
方案一:手动维护 CLAUDE.md / MEMORY.md
每个项目根目录放一个 Markdown 文件,手写项目约定和偏好。问题是:上限约 200 行就会开始截断;需要手动更新,永远跟不上代码变化;内容很快过时,反而误导 AI。
方案二:mem0 / MemGPT 等通用记忆方案
需要配置向量数据库(Postgres + pgvector)、嵌入模型 API 密钥、多个服务进程。对于只想让 Claude Code 记住"别用 jsonwebtoken"的开发者来说,这太重了。
方案三:寄希望于上下文窗口越来越大
窗口再大,也无法跨会话持久化。今天 200K,明天可能 1M,但关掉终端的那一刻一切归零。

上图对比了两种开发体验——左边是每次新会话都失忆的挫败感,右边是拥有持久记忆后的流畅协作。
核心设计:全自动记忆闭环
agentmemory 的设计哲学是"你不需要做任何事"。整个记忆生命周期完全自动化:
自动捕获
通过 Agent 生命周期 Hooks 自动记录。以 Claude Code 集成为例,agentmemory 注册了 12 个 Hooks,覆盖从工具调用到会话结束的完整生命周期。每次你用 Claude Code 做了一次代码修改、查了一个文件、修了一个 Bug——这些上下文都会被自动记录。
自动压缩
原始的工具调用记录可能很长,agentmemory 会将其压缩为五种结构化记忆:
自动检索与注入
新会话启动时,agentmemory 根据当前上下文自动检索相关记忆并注入。检索不是简单的关键词匹配——它使用三路混合搜索:
- BM25
:关键词精确匹配,适合搜特定库名、函数名 - 向量搜索
:语义相似度匹配,搜"数据库性能优化"能找到"N+1 查询修复"的记忆 - 知识图谱
:实体关系推理,根据项目结构关联相关记忆
语义搜索是关键差异化能力。demo 演示了一个经典案例:搜索"database performance optimization",能召回之前修复 N+1 查询的记忆——纯关键词搜索做不到这一点。
技术架构:iii-engine + 本地优先
agentmemory 底层基于 iii-engine——一个 Rust 编写的通用 Agent 运行时,提供了它需要的所有基础设施:
这意味着 agentmemory 把传统需要 5 个独立服务的架构压缩成了单个进程:
💻 Bash
# 传统方案# Postgres + pgvector + Redis + Socket.io + pm2 + 嵌入 API# → 配置复杂,依赖多个外部服务# agentmemorynpx @agentmemory/agentmemory# → 一个命令,零外部依赖嵌入模型:all-MiniLM-L6-v2
选择 this model 有三个理由:
- 384 维向量
:比常见的 1536 维(OpenAI text-embedding-ada-002)小 4 倍,存储和检索更快 - 22MB 模型体积
:本地运行,不需要 API Key - 3x 推理速度
:比标准 BERT 快 3 倍,P50 检索延迟 < 20ms
存储用 SQLite,同样零外部依赖。整个系统可以运行在任何开发者的笔记本上,不需要云端服务。
三种集成方式
agentmemory 目前对 Claude Code 的集成最完整,提供三种方式:
1. Hooks(12 个生命周期钩子)
自动捕获 Agent 的每一个动作,是记忆系统的基础数据来源。
2. MCP Server
通过 Model Context Protocol 与 AI 助手通信,支持任何 MCP 兼容的客户端。
3. Skills
自定义技能定义,扩展 AI 助手的能力。
对 Cursor 和 Gemini CLI 的集成也在积极开发中。设计上预留了通用 MCP 协议的支持,任何 MCP 兼容的 AI 工具都能接入。
快速上手
💻 Bash
# 一条命令启动记忆服务npx @agentmemory/agentmemory# 验证服务状态curl http://localhost:3111/agentmemory/health# 访问实时记忆面板open http://localhost:3113启动后,记忆服务运行在两个端口:
内置 Demo
💻 Bash
npx @agentmemory/agentmemory demo- 3111
:API 端点,供 AI 助手调用 - 3113
:实时记忆面板,浏览器可视化查看记忆数据变化
Demo 注入 3 个模拟会话:JWT 认证配置、N+1 查询修复、限流方案。你可以直接在面板中搜索"数据库性能"看语义检索召回"N+1 查询修复"记忆的效果。
与同类方案对比
核心差距在于"零摩擦"程度:agentmemory 从安装到产生价值只需要一条命令,而 mem0 需要至少配置数据库、嵌入模型、API 密钥。对于个人开发者来说,本地优先 + 零外部依赖是决定性的优势。
适用人群
总结
- Claude Code 重度用户
:跨会话频繁丢失上下文,希望 AI 记住项目约定和编码偏好 - Cursor / Gemini CLI 用户
:同样的失忆问题,agentmemory 的 MCP 协议支持通用接入 - 团队技术负责人
:希望团队 AI 助手共享架构决策和技术偏好 - 全栈独立开发者
:项目多、上下文切换频繁,AI 助手记住每个项目的约定能大幅减少重复沟通 - Rust / TypeScript 开发者
:对 iii-engine 架构和本地优先设计感兴趣
agentmemory 解决的是 AI 编程助手最让人抓毛的问题——失忆。它的解法不是更大的上下文窗口,也不是手动维护文档,而是全自动的记忆捕获、压缩和注入。三路混合搜索保证召回质量,iii-engine + SQLite + all-MiniLM-L6-v2 实现零外部依赖,一条 npx 命令即可启动。如果你受够了每次新会话都要重新交代项目背景,8K+ Star 证明了你并不孤单。
