 夜雨聆风
夜雨聆风
CSIG文档图像分析与识别专业委员会学术微沙龙(简称:文档图像微沙龙)在线学术报告会第五十期于2026年3月24日成功举行。
本沙龙由中国图象图形学学会主办,文档图像分析与识别专委会发起承办,中国图象图形学报协办。本场活动邀请华中科技大学博士生朱翰绅分享最新成果:基于结构异常量化奖励的视觉文本图像生成增强方法;邀请中国科学院信息工程研究所博士生李庚洛分享最新成果:面向多模态结构理解与推理的文档解析与文本图像机器翻译方法研究。微沙龙活动在B站、蔻享学术、中国图像图形学报视频号进行了同步直播。三个平台共计约4900人次的相关领域的老师同学观看学习。
1
第一场报告活动由西安交通大学硕士生武雪程担任主持人。

报告人为华中科技大学博士生朱翰绅。
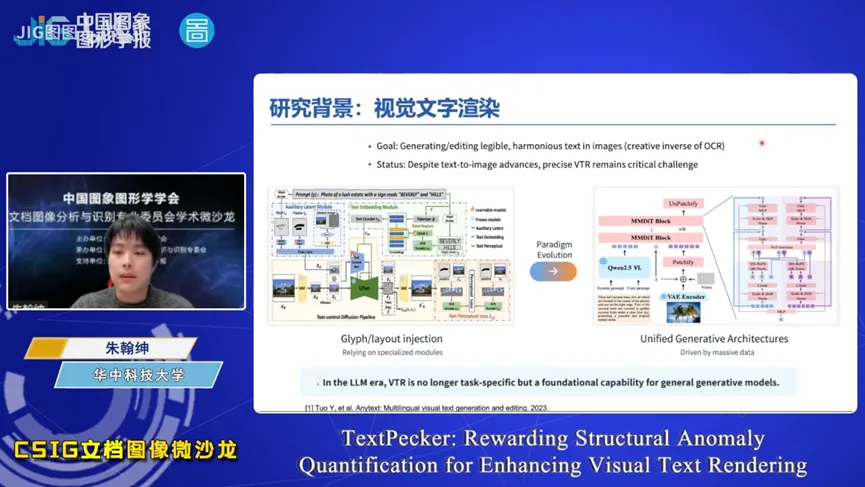
报告以“基于结构异常量化奖励的视觉文本图像生成增强方法”为题,深入探讨了高保真文本渲染的技术瓶颈与强化学习优化方案。报告指出,精准生成结构规范的文字依然是阻碍文生图技术落地的一大痛点。即便如 Nano Banana、Seedream 与 Qwen-Image 等先进生成模型,在处理汉字等复杂字形时,仍频繁出现笔画错位、结构畸变等现象,难以稳定输出结构忠实的文本。为解决上述难题,强化学习已成为主流的后训练优化方案。然而,如何解决现有奖励信号在识别复杂文字结构异常时存在的感知缺陷、评估幻觉以及感知失明等问题,成为了当前的破局关键。为突破视觉文本生成中评估与优化的双重瓶颈,TextPecker 项目从两方面入手。一是构建了涵盖跨模型生成、精细标注及笔画编辑合成的三阶段结构异常数据集,并以此训练出具备专家级文字感知能力的评估模块。二是在此基础上,提出融合结构质量与语义对齐分数的复合奖励机制,将优化目标升级为语义对齐与结构保真的联合优化。广泛的实验证明,该即插即用的强化学习范式在跨模型、跨语言测试中均实现了高度一致的性能跃升,将高保真视觉文本渲染推向了新的水平。报告在结尾指出,可靠的文字渲染能力是多模态 AI 走向真实应用的关键基础设施,无论是 AI Agent 自主生成海报文档,还是多模态大模型输出含文字的视觉内容,都以此为前提。TextPecker 为这一方向提供了基础性的评估工具与优化范式。
参考论文
[1]. Hanshen Zhu, Yuliang Liu, Xuecheng Wu, An-Lan Wang, Hao Feng, Dingkang Yang, Chao Feng, Can Huang, Jingqun Tang, Xiang Bai. TextPecker: Rewarding Structural Anomaly Quantification for Enhancing Visual Text Rendering. CVPR 2026.
2
第二场报告活动由南开大学的刘亿超硕士担任主持人。

报告人来自中国科学院信息工程研究所的李庚洛博士。
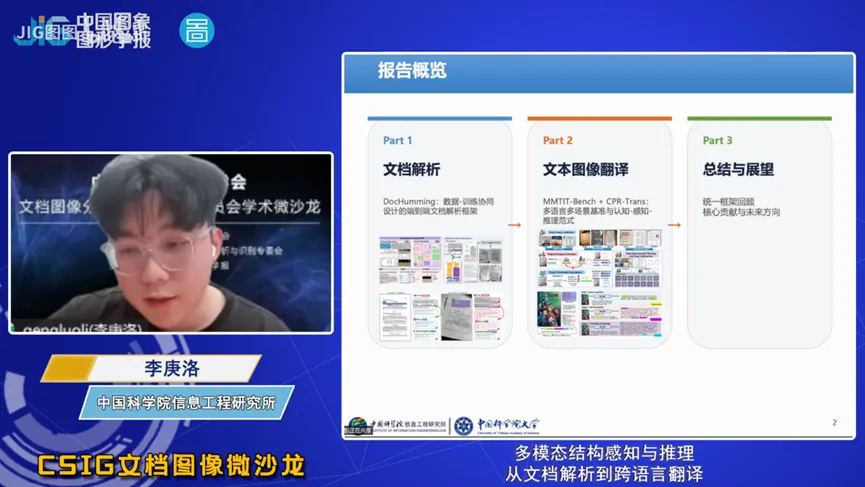
报告以“面向多模态结构理解与推理的文档解析与文本图像机器翻译方法研究”为题,深入探讨了大模型时代的智能文档解析与翻译技术。报告首先强调了该技术的应用价值与研究意义:随着多模态大语言模型的快速发展,其在视觉语言融合场景中的结构理解与跨模态推理能力成为当前研究的重要方向。现实应用中,大量信息以文档与图像形式存在,其中既包含复杂的版面结构,也包含跨语言的文本内容。因此,如何实现从视觉输入到结构化理解,再到跨语言语义表达的统一建模,成为多模态智能的重要挑战。 为应对这些挑战,团队面向文档解析与文档翻译进行了深入探究。在文档解析方面,团队提出基于数据—训练协同设计的端到端建模方法,通过真实场景合成数据构建与结构感知训练策略,有效提升模型在复杂文档与真实拍摄条件下的解析能力,并构建了面向真实场景的评测基准,以系统评估模型的鲁棒性 。在文本图像机器翻译方面,团队构建多语言多场景评测基准MMTIT-Bench,并提出融合“认知—感知—推理”的统一推理范式CPR-Trans,将视觉理解、文本解析与翻译过程有机整合,从而显著提升多模态翻译的准确性与可解释性。
参考论文
[1]. Gengluo Li, Pengyuan Lyu, Chengquan Zhang, Huawen Shen, Liang Wu, Xingyu Wan, Gangyan Zeng, Han Hu, Can Ma, Yu ZHOU. Towards Real-World Document Parsing via Realistic Scene Synthesis and Document-Aware Training. CVPR 2026.
[2]. Gengluo Li, Chengquan Zhang, Yupu Liang, Huawen Shen, Yaping Zhang, Pengyuan Lyu, Weinong Wang, Xingyu Wan, Gangyan Zeng, Han Hu, Can Ma, Yu ZHOU. MMTIT-Bench: A Multilingual and Multi-Scenario Benchmark with Cognition–Perception–Reasoning Guided Text-Image Machine Translation. CVPR 2026.
报告回放
B站视频链接:
https://www.bilibili.com/video/BV1hMRsBxEzk/
或扫描二维码观看:

END
加入学会:
关注我们:
