 夜雨聆风
夜雨聆风一、安全是设计出来的,不是堵出来的
在整个 Claude Code 源码解析系列的最后一篇,我们来聊聊安全系统。
在前四篇文章中,我们已经看到了 Claude Code 在架构、Agent 循环、工具系统、记忆系统等多个层面的设计。安全系统并不是其中最"显眼"的一层,但它是所有其他层面的共同基础——没有安全保障,再强大的 Agent 也会成为潜在的风险源。
核心观点:Claude Code 的安全设计不是"事后打补丁",而是从一开始就融入架构的每一个环节。这就是业界常说的"Security by Design"。
二、纵深防御:六层安全体系
Claude Code 的安全体系不是一条防线,而是多层防线纵深布置。单一防线被突破不等于整个系统被攻破。
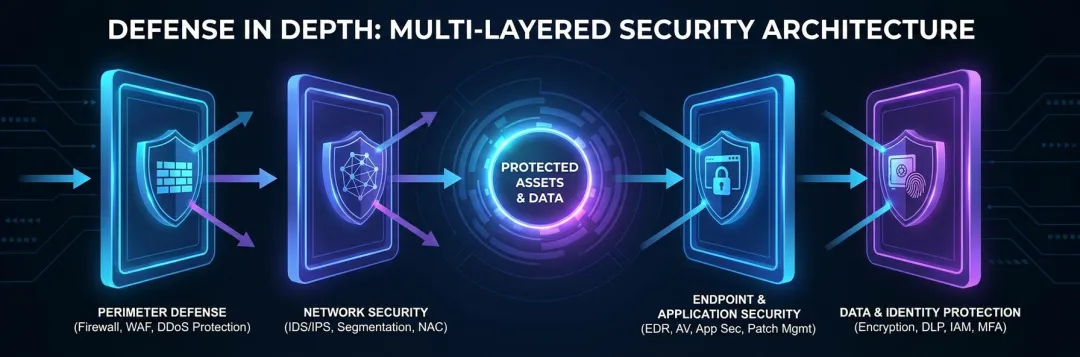
▲ 纵深防御体系:CLI 层 → Agent 推理层 → 工具路由层 → 执行层 → 结果审查层 → 记录审计层,每层都有独立的安全机制
具体来说,Claude Code 的安全防线分为六层:
🛡️ Claude Code 六层安全防线
- ① CLI 层
— 输入解析,过滤恶意指令格式 - ② Agent 推理层
— System Prompt 内置安全边界 - ③ 工具路由层
— 工具调用权限校验 - ④ 执行层
— 高危操作二次确认 - ⑤ 结果审查层
— 影子 AI 分类判断 - ⑥ 记录审计层
— 完整操作日志
三、YOLO Classifier:影子 AI 安全审查
Claude Code 内部有一个被称为 YOLO Classifier 的模块,运行在工具执行之前,对每个操作进行安全分类。

▲ YOLO Classifier 工作原理:每个工具调用请求经过分类器,判断为安全/危险/高危,拒绝危险操作,拦截高危操作上报
YOLO 的工作逻辑非常简洁:
- Safe(安全)
— 直接放行,执行工具 - Risky(危险)
— 记录日志,执行工具,但向用户发送警告 - Dangerous(高危)
— 拦截操作,向上报系统,请求用户明确授权
为什么叫"影子 AI"? 因为 YOLO Classifier 本身也是一个 AI 模型(独立于主 Agent LLM),它在背后静默运行,像影子一样监控每一次工具调用。如果主 Agent LLM 生成了一个危险的操作建议,影子 AI 有机会将其拦截。
四、Bash 命令安全检查
在所有工具中,BashTool(shell 命令执行)是最敏感的一个——它几乎可以执行任何系统命令。
Claude Code 对所有 Bash 命令执行前,都经过安全检查,包括:
🔍 Bash 命令安全检查项
- 路径检查
— 是否包含危险路径(如 /etc、/system) - 模式检查
— 是否匹配已知危险命令模式(如递归删除、管道到 eval) - 权限检查
— 命令是否涉及超权操作 - 并发限制
— 禁止同时执行多个高危 Bash 命令 - 输出过滤
— 返回结果中的敏感信息(密钥、Token)自动过滤
五、权限分级机制
Claude Code 的权限系统,将操作分为四个级别,每个级别对应不同的授权要求:
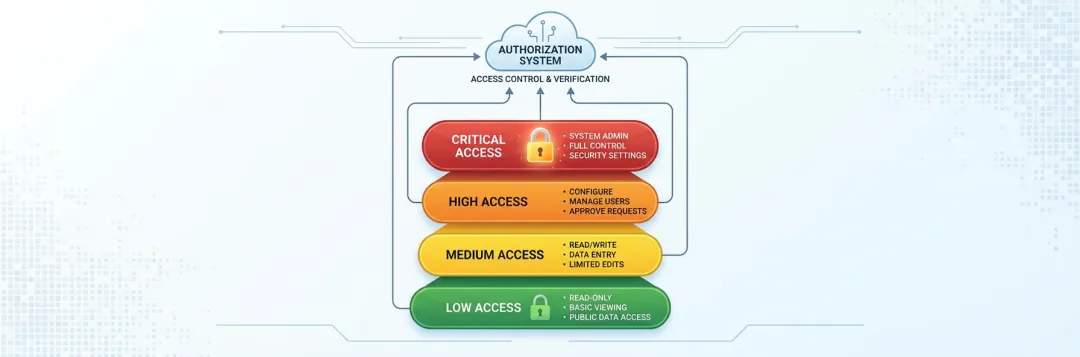
▲ 权限分级机制:低 → 中 → 高 → 极高四级,每级有明确授权要求
🔐 四级权限体系
- 低危读取操作
— 读文件、搜索、查看状态 → 自动放行 - 中危写入操作
— 写文件、创建目录 → 日志记录后执行 - 高危系统修改
— 修改配置、安装依赖、删除文件 → 用户明确确认 - 极高危危险操作
— 危险命令、网络访问Credential → 拒绝执行 + 上报
六、安全设计的工程哲学
① 最小权限原则Claude Code 默认以最小权限运行,需要时才申请更多权限。这与云原生安全最佳实践完全一致。
② 信任但要验证即使 Agent 已经决定执行某个操作,系统仍会在执行前再次检查,不完全信任 Agent 的判断。
③ 白名单优于黑名单Claude Code 的安全策略以白名单为主——默认拒绝,只放行明确安全的行为。这比黑名单(默认放行,只拒绝明确危险的行为)更安全。
七、AI Agent 安全:一个行业命题
Claude Code 的安全设计,折射出一个更大的行业命题:当 AI Agent 拥有执行能力时,如何确保它的行为是安全的、可控的?

▲ AI Agent 安全是行业共同命题:能力越大,责任越大
Claude Code 的做法,提供了几个值得借鉴的思路:
- 能力边界
— Agent 只能通过工具做事,工具本身可以设计安全边界 - 影子 AI
— 用一个 AI 监控另一个 AI,形成制衡 - 可审计
— 所有操作有记录,出了问题可追溯 - 透明
— 用户始终知道 Agent 在做什么,有最终否决权
八、全系列收官
五篇文章,我们从整体架构出发,逐步深入 Agent 循环引擎、工具系统、记忆系统、安全权限系统。Claude Code 的 50 万行代码背后,藏着一条清晰的工程主线:
让模型做擅长的事(推理),让工程系统做擅长的事(执行、安全、记忆)。 模型不是万能的,架构设计才是让"不万能的模型"变得"真正有用"的关键。
Claude Code 不是一个"封装了 API 的 CLI 工具",而是一套完整的终端 Agent 运行时。它的每一个设计选择——分层解耦、工具边界、记忆分层、安全纵深——都在回答一个共同的问题:如何在保证安全可控的前提下,让 AI Agent 真正替人类做事?
这个问题,值得所有 AI 应用开发者持续思考。
Claude Code 源码解析系列 · 完 第1篇:整体架构 第2篇:Agent 循环引擎 第3篇:工具系统 第4篇:记忆系统 第5篇:安全与权限系统
