 夜雨聆风
夜雨聆风声明:本文仅供技术学习与研究交流,严禁用于任何商业目的!请遵守相关法律法规及平台服务条款。
前言
先说结论:我对web端基本算是七窍通了刘窍————一窍不通!
最近在研究某 AI 平台的语音合成功能,想把它的 TTS 能力集成到自己的工作流里做一些自动化实验。官方 API 要收费,而网页版有免费额度,于是萌生了一个想法:能不能用 AI 辅助逆向,把网页版接口搞明白?
实践下来发现,AI 时代的 Web 逆向和以前完全不一样了。以前你得自己一行行读混淆代码、手动断点调试,现在大部分脏活累活都可以交给 AI。整个过程我几乎没怎么手动分析代码,主要精力花在了"怎么问 AI"和"怎么验证结果"上。
下面分享一下完整流程。
整体思路
我的工作流分为 6 步,每一步都尽量让 AI 来干,人只负责"指挥"和"验证":

Step 1:网络抓包,保存为 HAR
打开浏览器 DevTools(F12),切到 Network 面板,操作一遍目标功能(比如点击"生成音频"),然后右键导出为 HAR 文件。
要点:
勾选 "Preserve log" 防止页面跳转丢失请求 WebSocket 请求也会被记录在 HAR 里(包括收发的消息) HAR 本质是 JSON,里面包含了所有请求的 URL、Headers、Body、Response
这一步没什么技术含量,但很关键——HAR 就是后续所有分析的"原材料"。
Step 2:把 HAR 扔给 AI,整理成可测试的接口文档
这一步是整个流程的核心提效点。
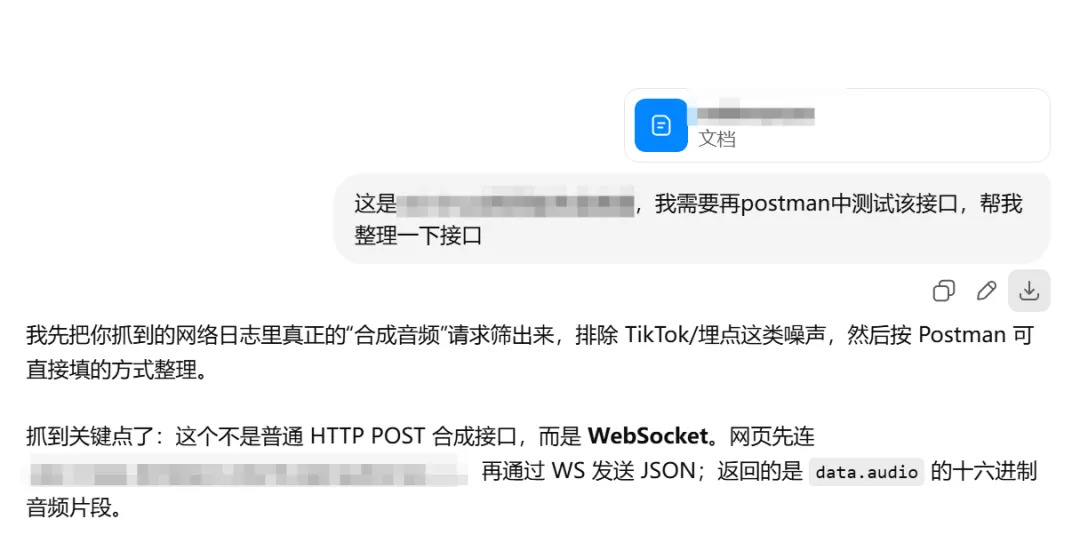
直接把 HAR 文件(或者从中摘出的关键请求)丢给 AI,prompt 大概是:
"帮我分析这个 HAR 文件,整理出所有关键接口,按 Postman 可操作的格式输出,包括 URL、Method、Headers、Body、Response 结构说明。"
AI 会帮你:
区分哪些是核心接口、哪些是辅助接口 识别出 WebSocket 握手和消息格式 整理出请求参数的含义 标注哪些参数是动态的(需要每次计算)
Step 3:外部信息用配置文件分离
AI 整理完接口文档后,会发现有些参数是"你自己的"——比如 token、设备 ID、用户标识等。这些不应该硬编码在脚本里。
让 AI 帮你设计一个 config.json:
{
"credentials":{
"token":"你的登录token",
"uuid":"你的uuid",
"device_id":"你的device_id"
},
"tts":{
"model":"speech-xxx",
"voice_id":"某个音色ID",
"speed":1,
"vol":1,
"pitch":0
},
"output_dir":"./output"
}
这样做的好处:
敏感信息不会意外泄露 换号、换参数只改配置文件 脚本可以直接分享给别人
Step 4:搜索补充缺失参数
整理完接口文档后,你会发现有些参数搞不清楚怎么来的。比如我遇到的情况:请求里有一个 yy 参数,每次都不一样,明显是动态计算的签名。
这时候需要:
在浏览器 DevTools 里全局搜索(Ctrl+Shift+F)关键词 找到相关的 JS 代码片段 把混淆后的代码扔给 AI 分析 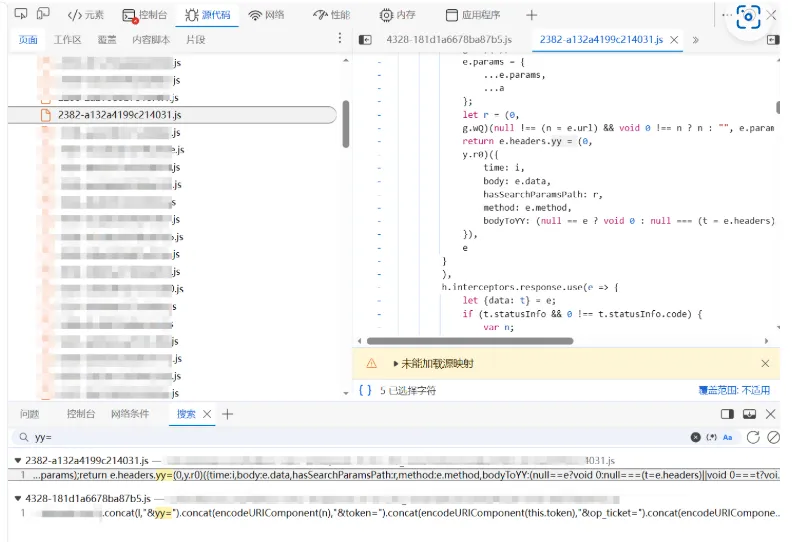
我在 Sources 面板搜索 yy 相关的关键词,定位到了一段 webpack 打包后的代码。虽然变量名全是 e、t、l、n 这种单字母,但把上下文一起扔给 AI,它能帮你理清逻辑。
Step 5:还原加密算法
拿到混淆代码后,让 AI 帮你还原算法。这一步可能需要多轮对话:
先让 AI 解读混淆代码的大致逻辑 确认关键函数的输入输出 让 AI 用 Python 重写
这类平台的签名算法一般都是类似的套路:把请求路径、时间戳、请求体等参数按某种规则拼接,再做一次或多次哈希。具体的拼接顺序、分隔符、盐值各家不同,但思路大同小异。
还原出来后用 Python 实现大概长这样(伪代码,非真实算法):
import hashlib
defgen_sign(path, timestamp, body=None):
"""动态签名计算(伪代码示意)"""
# 1. 组装签名原文:路径 + 分隔符 + 请求体 + 时间相关哈希 + 盐值
raw = encode(path) + separator + serialize(body) + hash(timestamp) + salt
# 2. 对原文做哈希得到最终签名
returnhash(raw)
核心就是:拼接 → 哈希,可能嵌套多层。具体实现因平台而异,需要结合上一步拿到的 JS 代码让 AI 分析。
如果纯靠人肉读混淆代码,可能要花好几个小时。但交给 AI,基本一两轮对话就能搞定。
Step 6:本地复刻测试
所有参数都搞清楚后,让 AI 帮你写一个完整的 Python 脚本:
WebSocket 连接 + 自动签名 发送合成请求 接收流式音频数据 保存为 WAV 文件
# 合成语音
python tts_script.py "你好,这是一段测试语音。"
# 查看可用音色
python tts_script.py --list-voices
跑通的那一刻,成就感拉满。
⚠️ 重要提醒:分散你的 AI 工具!
这里有一个血泪教训要分享:
尽量不要用 ChatGPT 做逆向分析! 我已经被封了一个号了 
ChatGPT 对这类内容比较敏感,容易触发风控。我的经验是:HAR 分析和接口整理交给 DeepSeek(网页版或 API 都行,注意别直接说"逆向",就说"分析接口"就好,但据说DeepSeek是逆向好手,但没怎么用过),它上下文窗口大,吃得下整个 HAR 文件。而还原加密算法、编写最终脚本这些活,我用的是 Kiro——非常配合,啥都能干  甚至还帮我主动搜索了该平台签名函数的相关资料,属实是逆向好帮手。
甚至还帮我主动搜索了该平台签名函数的相关资料,属实是逆向好帮手。
总之一句话:把"危险"的活分散到不同工具上,ChatGPT 留着干正经事。
总结
AI 时代的 Web 逆向,核心能力从"读代码"变成了"问问题":
抓包是基础 — HAR 文件是一切的起点 AI 是放大器 — 混淆代码、协议分析、脚本编写全交给它 人负责决策 — 判断哪些接口重要、验证结果是否正确 配置要分离 — 敏感信息别硬编码 工具要分散 — 别把鸡蛋放一个篮子里(别问我怎么知道的)
整个过程从抓包到跑通,大概花了一小时。如果纯手工逆向,可能要一两天,对于我这种路易十六附体的,肯定需要更长时间!AI 确实把门槛降低了很多,但前提是你得知道"该问什么"和"怎么验证"。
再次声明:本文仅供技术学习与研究,请勿用于商业用途或违反任何平台的服务条款。尊重知识产权,合法合规使用技术。
