 夜雨聆风
夜雨聆风大家好,我是你的AI创业观察者 。
。
最LangChain CEO Harrison Chase(@hwchase17)在 X 上发了一篇干货满满的长帖,系统讲解了顶级团队如何把智能体从「一次炫酷 demo」变成「可重复、安全、生产级」系统的核心实践方法论。
今天我把这篇内容完整改写、扩展并翻译成通俗易懂的简体中文,结合实际落地经验,整理成一篇系统性的技术博文,方便大家分享和学习。
为什么大家都在喊要做智能体,却很难真正落地?
2025-2026 年,AI Agent 异常火爆,几乎人人都在尝试。但真正能稳定、重复、安全交付生产级 Agent 的团队并不多。大多数人做出来的还是"看起来很厉害的一次性 Demo",上线后要么失控、要么成本爆炸、要么效果远不如预期。
顶级团队的秘密在于:他们建立了一套完整的 Agent 开发生命周期,让实验变成可重复、可学习、可持续改进的系统工程。
这个生命周期由四个核心环节组成:
Build(构建) → Test(测试) → Deploy(部署) → Monitor(监控)
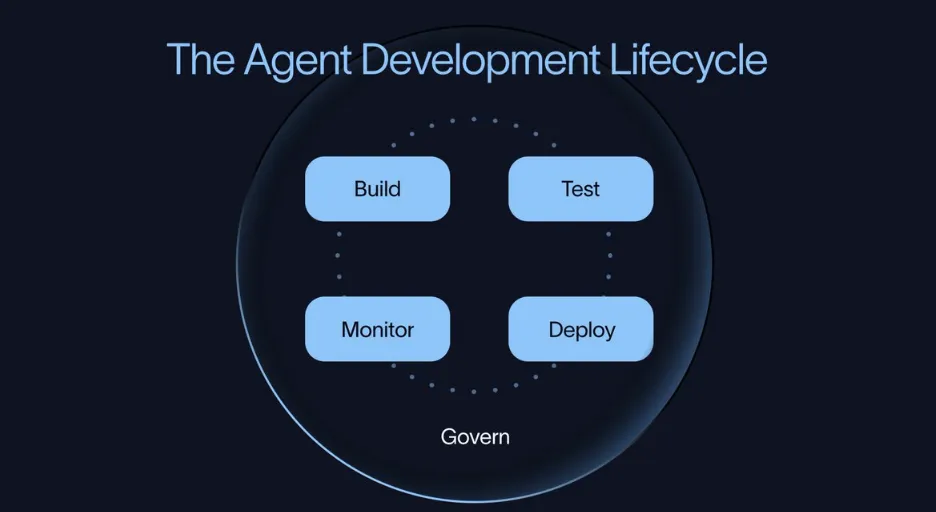
关键原则:测试必须在部署之前就开始,而不是等出问题了再补救。生产环境的数据又会反过来驱动下一次构建,形成持续优化的飞轮。
下面我们逐一拆解每个阶段,并给出实战建议。
1. 构建阶段:先想清楚你要造什么样的智能体
构建阶段的核心不是马上写代码,而是定义智能体的类型和抽象层次。

当前主流工具分层
Agent Framework(框架层):专注于提示词工程、工具调用、结构化输出等抽象。代表:LangChain、LlamaIndex、CrewAI。 Agent Runtime(运行时层):专注于复杂执行能力,如状态管理、控制流、持久化、人机协作。LangGraph 是目前最强的代表之一,能实现分支、循环、暂停、恢复等高级能力。 Agent Harness(装备层):提供完整运行环境,包括提示词管理、技能(Skills)、MCP 服务器、文件系统、中间件等。Claude Agent SDK、Deep Agents 等属于此类。
实战选择建议
简单任务:用 Framework 快速搭一个 Tool-Calling Loop 即可。 复杂任务:需要 Framework + Runtime + Harness 的组合,涉及持久化上下文、多轮对话、复杂决策流程。
No-Code / Low-Code 的重要性
LangSmith Fleet、Claude Cowork、n8n 等工具让业务专家(非工程师)也能参与 Agent 构建。这非常关键,因为最懂业务流程的人往往不是写代码的人。
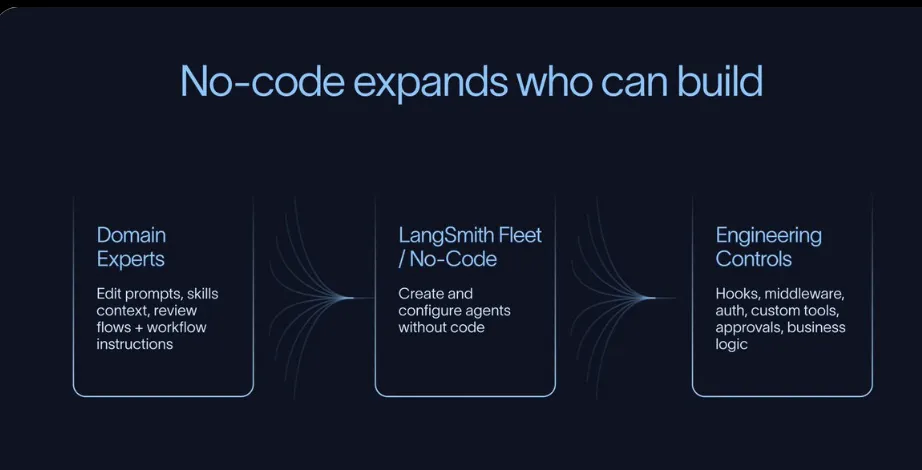
但要注意:No-Code 不等于无治理。优秀的构建体系应该做到"简单的事情极简,复杂的事情可控"。业务人员改提示词和技能,工程师通过 Hooks 和 Middleware 控制权限、审批、安全边界。
核心思考:你的 Agent 是处理简单重复工作,还是需要长期记忆、多轮交互和复杂决策?选对抽象层次,能极大降低后续维护成本。
2. 测试阶段:没有测试,就别急着上线
这是大多数团队最容易忽略、也是代价最高的一环。
好的测试不是追求 100% 覆盖,而是建立足够的安全网,能及早发现明显失败、支持版本对比、避免盲目变更。

核心实践
构建高质量 Datasets:从预期用例、手动测试、用户支持工单、生产日志中积累真实案例。数据集是组织的"记忆库"。 评估指标(Evaluation Metrics): 有标准答案的任务 → 直接测准确率(字段提取、分类、数据库更新等)。 开放性任务 → 用 LLM-as-Judge 评估(是否 grounded、是否符合政策、是否高效、是否主动求澄清)。 实验系统(Experiments):系统对比不同提示词、模型、检索策略、工具组合的效果。 多轮模拟(Simulations):Agent 大多是多轮交互系统,必须模拟真实对话流程、异常处理、用户情绪等场景。
深刻洞见:最好的评估数据往往来自最难、最失败的案例。早期靠团队 dogfooding(自己狂用),后期靠生产真实痕迹。
3. 部署阶段:智能体需要的不只是一个服务器
普通 Web 应用部署可能是"推代码上线"就行,但 Agent 通常需要持久化执行 + 人机协作能力。
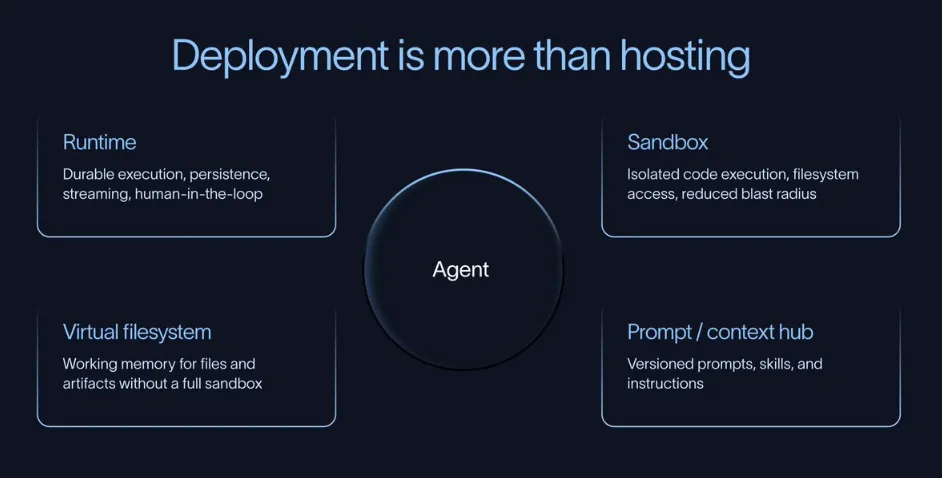
关键基础设施要求
Durable Execution(持久化执行):Agent 能保存状态,失败后从断点恢复,而不是从头开始。 Human-in-the-Loop(人机协作):需要人工审批、提供信息或审查时能优雅暂停等待。 Sandbox(沙箱环境):Agent 需要执行代码、操作文件、调用外部工具时,必须在隔离环境中运行(LangSmith Sandboxes、E2B、Daytona 等)。 Context Hub(上下文中心):提示词、技能、知识库等非代码资产需要独立版本管理,让业务人员也能轻松修改。
部署不是终点,而是让 Agent 拥有完整运行时的开始。
4. 监控阶段:看不见,就管不了
Agent 的监控和传统软件差异极大。
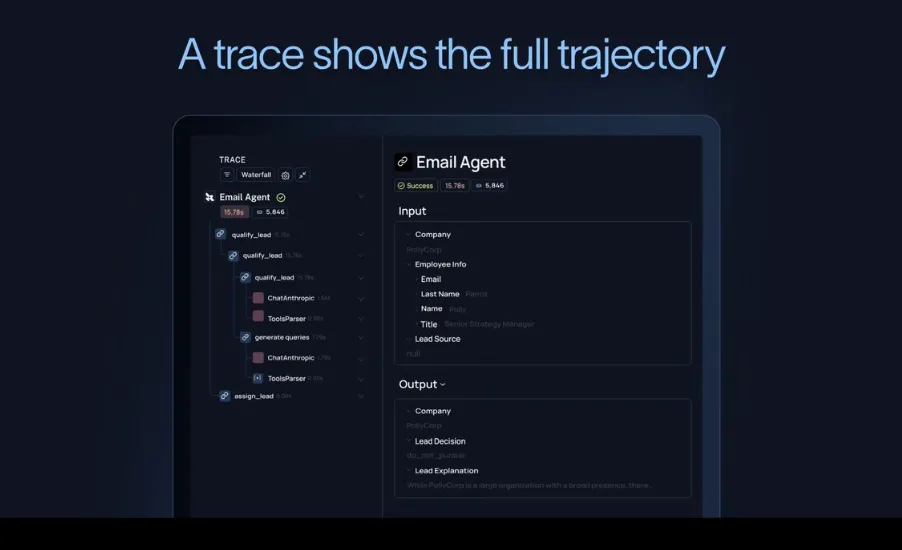
核心监控能力
Trace(完整轨迹):记录 Agent 的每一步思考、模型调用、工具使用、中间输出和最终动作。这是调试和优化的基础。 Signals(信号检测):用 LLM-as-Judge 自动评分,或用规则捕捉异常行为。 Feedback Loop(反馈循环):收集用户反馈、人工评审,并关联到具体执行轨迹。 Dashboards & Alerts:实时监控使用量、成本、成功率、失败模式等,设置关键阈值告警。
最重要的一点:监控数据必须反哺回 Build 和 Test 阶段,形成闭环。
完整迭代飞轮:构建→测试→部署→监控→构建
顶级团队的做法是小步快跑、快速迭代:
快速构建 MVP 版本 用评估体系保障基本安全 小范围部署 严格监控生产表现 把学到的教训变成下一个版本的提升
循环越快、越系统,Agent 就越聪明、越可靠。
治理:规模化时的护城河
当组织内 Agent 从 1 个变成 10 个、100 个时,治理变得至关重要。
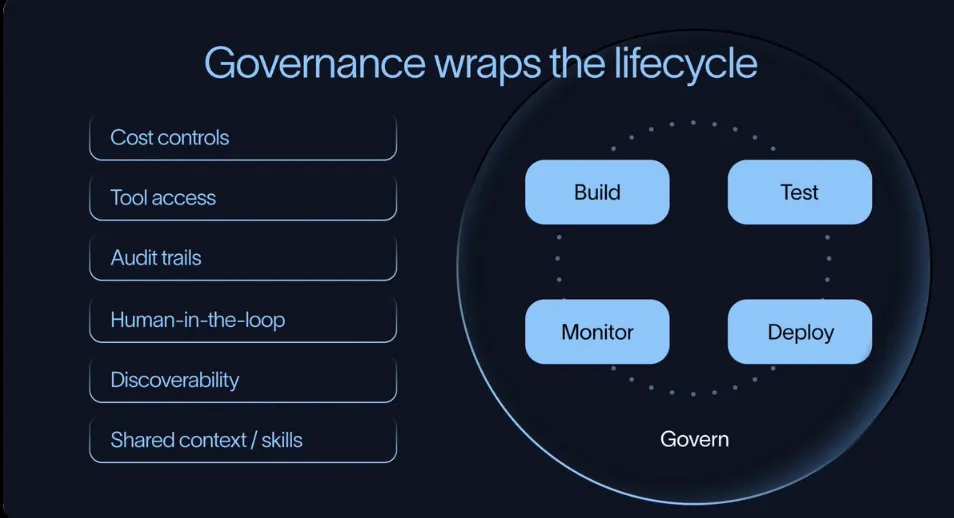
主要治理维度
成本治理:防止多模型调用、长上下文导致费用失控 工具权限控制:明确哪些 Agent 能调用什么工具、需要什么审批 Human-in-the-Loop 机制:涉及资金、敏感数据、生产系统时必须有人工把关 资产复用:提示词、技能、工具、知识库要能被全组织发现和共享,避免重复造轮子
好的治理不是限制创新,而是让创新更安全、更快。
写在最后:智能体时代的制胜之道
Harrison Chase 这篇帖子的核心洞见非常深刻:
智能体和传统软件不一样 —— 它技术上成功了,也可能做错了事。
一个 Agent 可能返回了 200 OK,但用了错误的上下文、跳过了审批、调用了危险工具,或者给出了听起来合理但实际上错误的答案。
只有建立起 Build → Test → Deploy → Monitor 的系统化生命周期,并辅以强有力的治理,你才能把 Agent 从炫技玩具变成真正的生产力武器。
对开发者:多在评估、Traceability 和治理上投入,长期收益远超短期交付速度。对创业者和企业负责人:别只看单个 Agent 多厉害,要问自己——我们是否有能力重复、安全、可规模化地交付 Agent?
未来属于那些把 Agent 开发变成组织核心能力的公司。
如果你正在构建 Agent,欢迎在评论区分享你的经验或踩过的坑,我们一起交流。
点赞 + 转发 + 关注,让更多朋友看到这篇实战指南!
参考资料
本文基于 LangChain CEO Harrison Chase (@hwchase17) 的 X 长帖改写、扩展与系统化整理,结合实际项目经验撰写。https://x.com/hwchase17/status/2053157547985834227
推荐阅读
复杂度棘轮:为什么AI编码时代,90%测试覆盖率从奢侈品变成了底线
五大AI驱动开发开源项目对比:superpowers、gstack、BMAD-METHOD、spec-kit、OpenSpec
