 夜雨聆风
夜雨聆风
上周五下午两点,你正在开一个无聊的例会。镜头里,你的脸旁边多出了另一张脸——一个 AI 的卡通形象,它实时听着发言,偶尔开口补充几句,会后自动整理了会议纪要,顺手把待办事项同步进了你的日历。
今天早上,它出现在 GitHub Trending 第一位。⭐ 13,000,Rust + TypeScript,Early Beta 阶段,今天还在提交 commit。
我把源码翻了一遍。有几个设计让我觉得值得认真拆一下。
一、它想解决什么问题
大多数 AI 助手有一个共同的死穴:每次对话都从零开始。
你打开对话框,先交代背景:"我在用 Next.js 14,公司做 SaaS,最近在搞支付模块……" 解释完 AI 才能帮上忙。几周后再打开,又要重头来一遍。
OpenHuman 的答案是:在第一次同步完成后,就消灭"冷启动"。
连上 Gmail、Notion、GitHub、Slack、Google Calendar——118 个集成,每 20 分钟自动拉一次最新数据,全部压缩进本地 SQLite 的记忆树。你早上第一次开口,Agent 已经知道你昨晚发了什么邮件、今天几个会、上周哪些 PR 合并了。
README 里有一句话很直接:
"Most agents start cold. OpenHuman skips the wait."
二、Memory Tree:一棵每 20 分钟"消化"一次的树
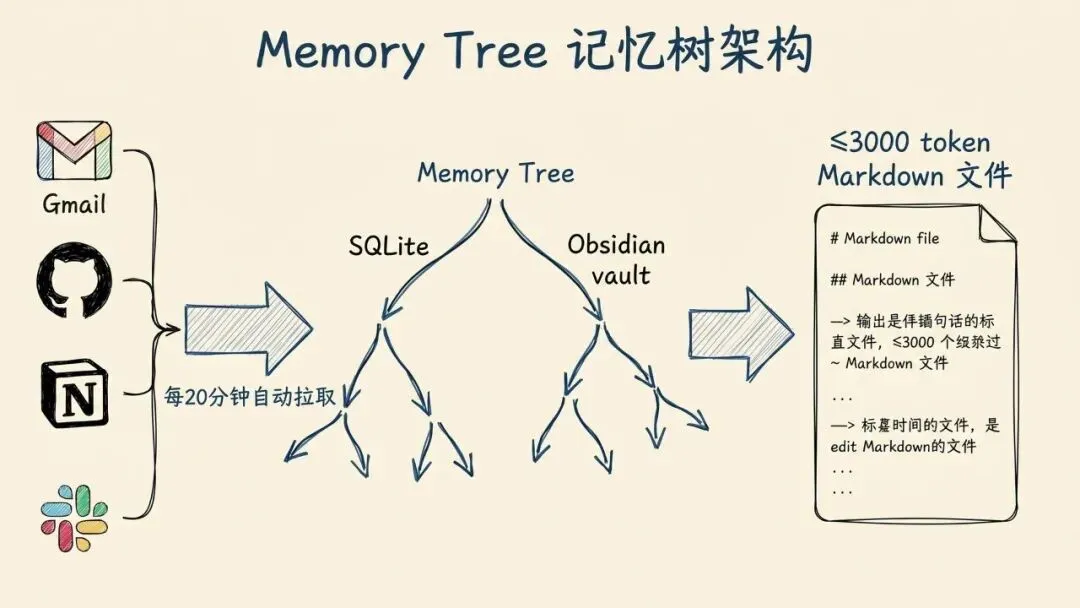
Memory Tree 是核心数据结构。所有接入的数据会被压缩成 ≤3000 token 的 Markdown 块,层叠存成摘要树,同时落两个地方:
- • SQLite:Agent 运行时的主要查询来源
- • Obsidian 兼容 文件:你可以直接用 Obsidian 打开和编辑
切块的逻辑在 memory/chunker.rs 里,用了三级降级策略:
/// 分块策略(三级降级)
/// 1. Heading 边界:先按 #/##/### 切
/// 2. Paragraph 边界:heading section 太大时按空行切
/// 3. Line 边界:paragraph 还是太大时按行切
pub fn chunk_markdown(text: &str, max_tokens: usize) -> Vec<Chunk> {
// 粗估:英文 4字符/token
let max_chars = max_tokens * 4;
let sections = split_on_headings(text);
// ...
}每个 Chunk 携带 heading: Option<Rc<str>>——用 Rc<str> 让同 heading 下的多个 chunk 共享同一个字符串引用,避免重复 alloc。
有意思的地方:切出来的 .md 文件不是只给 AI 看的。你可以直接在 Obsidian 里浏览、手动编辑,甚至覆盖 AI 的摘要。你不是在"用 AI",AI 是在"读你的笔记本"。
对于已经跨多个编程工具(Claude Code、Cursor、Codex)共享 agentmemory 的用户,OpenHuman 提供了一个 memory backend 桥接选项——config.toml 里设 memory.backend = "agentmemory",一套记忆跑所有 Agent。
三、Subconscious Engine:一个有"潜意识"的后台引擎
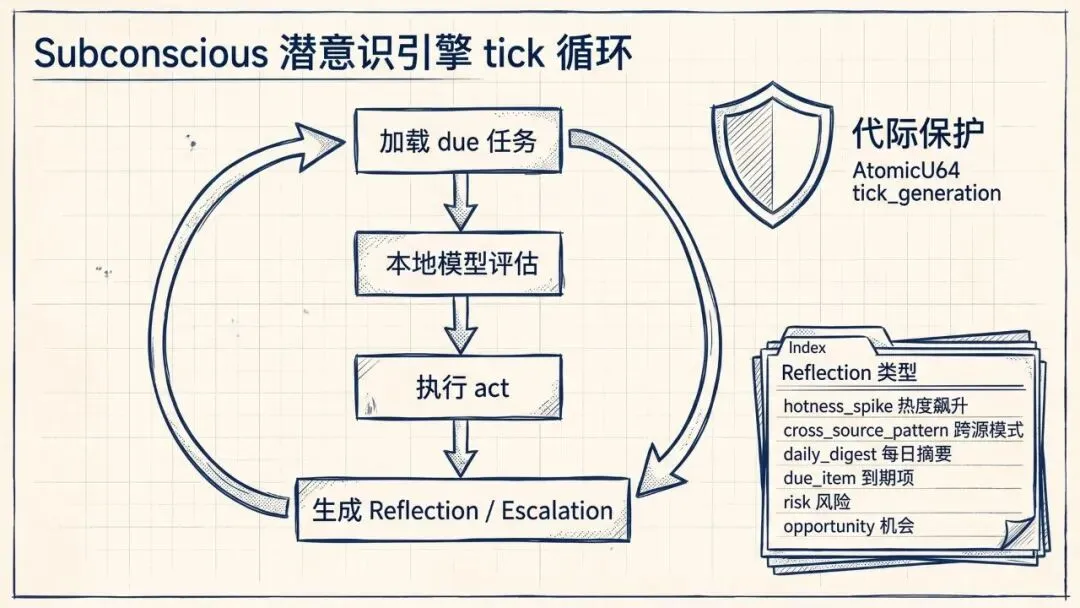
这是整个项目里我翻得最仔细的模块:src/openhuman/subconscious/。
3.1 tick 循环的骨架
engine.rs 里的 run() 方法结构极简:
pub async fn run(&self) -> Result<()> {
if !self.enabled { return Ok(()); }
let interval_secs = u64::from(self.interval_minutes) * 60;
loop {
// 先 sleep,再 tick(不是 interval,防止积压)
tokio::time::sleep(Duration::from_secs(interval_secs)).await;
match self.tick().await {
Ok(result) => info!(
"[subconscious] tick: executed={} escalated={} duration={}ms",
result.executed, result.escalated, result.duration_ms
),
Err(e) => warn!("[subconscious] tick error: {e}"),
}
}
}注意是 sleep 而不是 interval:tick 结束后才开始计时,不会因为单次 tick 超时而让下一个 tick 积压堆叠。
3.2 代际保护:AtomicU64 tick_generation
pub struct SubconsciousEngine {
tick_generation: AtomicU64,
// ...
}
// tick() 开头
let my_generation = self.tick_generation.fetch_add(1, Ordering::SeqCst) + 1;每次新 tick 启动,generation 计数器 +1。tick 执行完之前会检查自己是否还是最新代,如果被抢先了,之前所有 in_progress 的日志条目直接 cancel,结果丢弃。不会撞车,不会重复执行。
3.3 每次 tick 的完整流程
翻完 tick() 方法,五个步骤非常清晰:
1. cancel_stale_in_progress() ← 清理上代残留
2. due_tasks() ← 从 SQLite 加载到期任务
3. build_situation_report() ← 构建"当前状态摘要"(memory-tree 驱动)
4. evaluate_tasks_and_reflections() ← LLM 评估:noop / act / escalate
5. execute() / persist_reflections() ← 执行 or 升级为用户确认其中 build_situation_report 会拉最近 8 条 Reflection 作为防重复上下文——防止同一个信号跨 tick 被重复发出。
3.4 Reflection 的六种类型
reflection.rs 里定义了 Agent 在 tick 时可以生成的观察原语:
pub enum ReflectionKind {
HotnessSpike, // 热度突增
CrossSourcePattern, // 多源交叉信号
DailyDigest, // 每日摘要
DueItem, // 快到期任务
Risk, // 负面信号集中
Opportunity, // 值得关注的机会
}
/// 每次 tick 最多 5 条,超出直接丢弃
pub const MAX_REFLECTIONS_PER_TICK: usize = 5;关键设计:Reflection 不会自动弹进对话框。它只出现在"Intelligence"标签页的卡片上。用户点击"建议操作",才会新开一个对话线程——原有对话完全不被打扰。
注释里的原话很直白:"五条是有用的主动提醒和通知轰炸之间的经验甜点"。
3.5 Prompt 里注入了身份上下文
prompt.rs 还有一个细节:每次 tick 评估,都会先读 SOUL.md / PROFILE.md 作为 identity context 注入 prompt:
pub fn build_evaluation_prompt(
tasks: &[SubconsciousTask],
situation_report: &str,
identity_context: &str, // ← 从 SOUL.md/PROFILE.md 加载
) -> String {
format!(r#"{identity_context}
# Subconscious Loop — Task Evaluation
You are the background awareness layer...
"#)
}还有一条 Self vs Others 的防混淆规则写在 prompt 里:情况报告里包含用户自己的连接账号句柄、邮件地址等"Your Identifiers",LLM 必须用这个列表区分"关于用户自己"和"关于别人"的信号——被标记 (you) 的 hotness 条目才能用第二人称描述,否则是在写别人。
四、TokenJuice:省 80% Token 的 Rust 压缩器
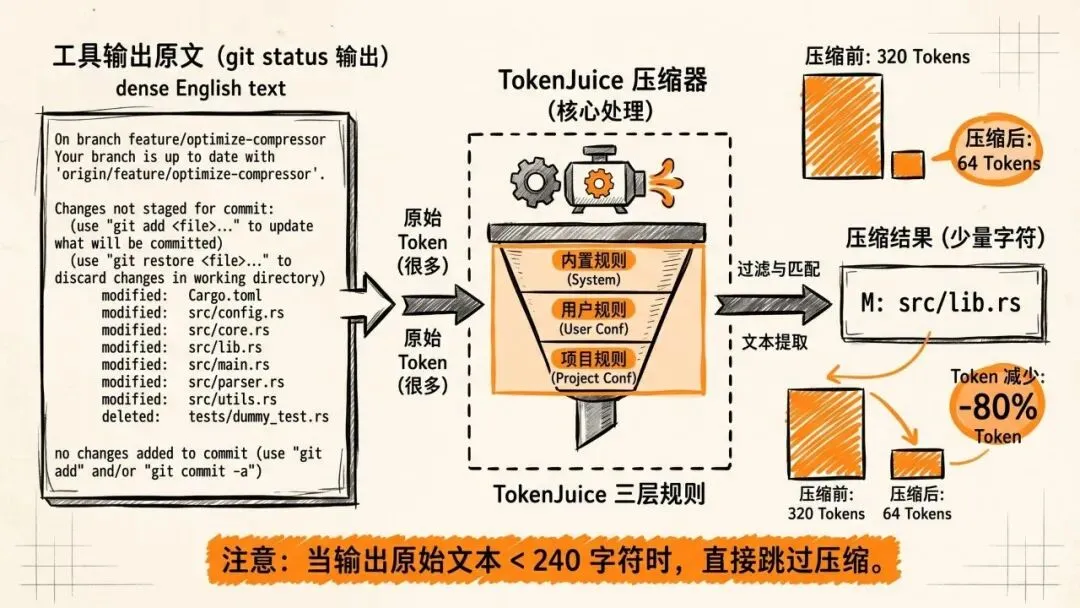
工具输出进 LLM 前,先过一层 TokenJuice 压缩。
这是 vincentkoc/tokenjuice 的 Rust 移植版,三层规则覆盖(内置 → 用户 → 项目),高优先级覆盖低优先级。
reduce.rs 里 git status 的后处理逻辑特别有代表性——把所有 Git 的废话全删了,只留真正有信息量的行:
fn rewrite_git_status_line(line: &str) -> Option<String> {
let trimmed = line.trim();
// 删掉废话:On branch main、use "git add"...、nothing to commit...
if trimmed.starts_with("On branch ") { return None; }
if regex_match(r#"^\(use "git .+"\)$"#, trimmed) { return None; }
if regex_match(r"^nothing added to commit", trimmed) { return None; }
// 压缩标题行
if trimmed == "Changes not staged for commit:" {
return Some("Changes not staged:".to_owned());
}
// ...
}输入:git status 的原始输出(20多行)
输出:Changes not staged: M: src/lib.rs还有一个细节——少于 240 字符的输出直接跳过,原样传给 LLM:
const TINY_OUTPUT_MAX_CHARS: usize = 240;够短就不压,避免压缩引入信息损失。
HTML 那侧也做了同样的工程决策:移除了 html2md 依赖,换成自写的线性扫描器 fast_html_to_text。原因就写在 Cargo.toml 注释里:html2md 遇到 Otter.ai 风格的嵌套表格 HTML 时,递归 walker 会产生 894MB 峰值堆内存。换成线性扫描器后内存降了一个数量级。
五、Meet Agent:STT → LLM → TTS 三段流水线
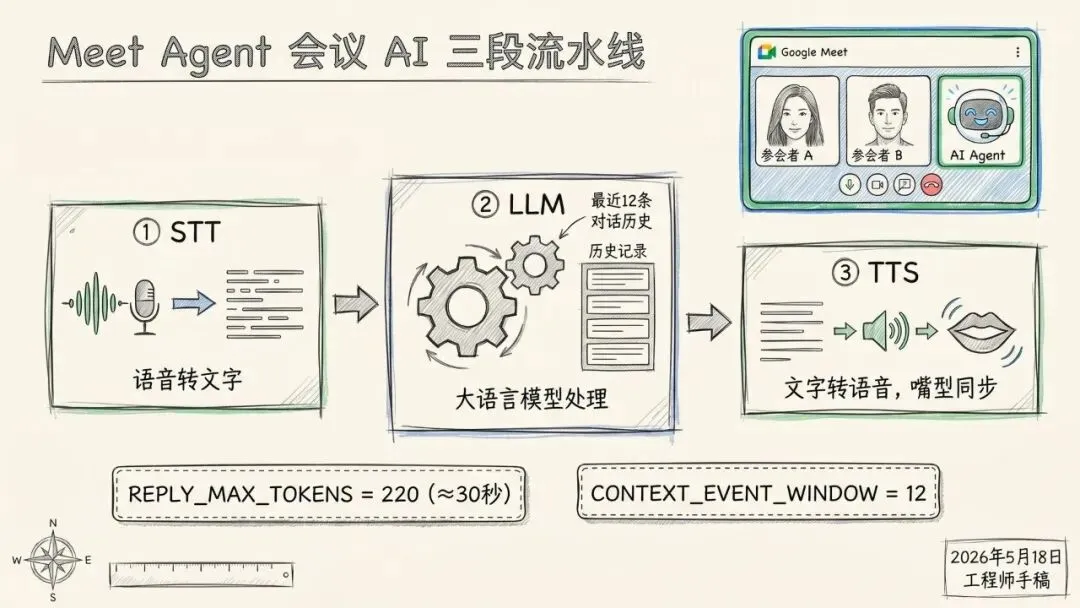
meet_agent/brain.rs 是一个完整的会议 AI 流水线,注释写得清清楚楚:
当 session::Vad 报告 EndOfUtterance:
1. STT — 把 PCM16LE 包成 WAV,发云端转录
2. LLM — 转录文本 + 最近12条对话历史 → 生成回复
3. TTS — ElevenLabs eleven_turbo_v2_5 → PCM → 嘴型同步播出三个硬编码常量决定了 Meet Agent 的行为边界:
/// 最多保留最近 12 条对话记录作为 rolling context
const CONTEXT_EVENT_WINDOW: usize = 12;
/// 回复上限 220 token ≈ 30秒语音
/// 够给真实答案,但不够让 AI 劫持会议
const REPLY_MAX_TOKENS: u32 = 220;
/// ElevenLabs 最佳延迟/质量比
const TTS_MODEL_ID: &str = "eleven_turbo_v2_5";还有一个 fallback 机制:如果后端 session token 不存在(离线、测试环境),系统不崩溃,用确定性的 stub 走完整个流程——让单元测试在没有网络的 CI 环境里也能跑通。
另外,VAD 有一个 250ms 的最小采样过滤:
/// 4000 samples @ 16kHz = 250ms
/// 低于此长度直接跳过 turn,防止咳嗽/点击声触发 AI 发言
const MIN_TURN_SAMPLES: usize = 4_000;六、Screen Intelligence:macOS 的三层感知架构
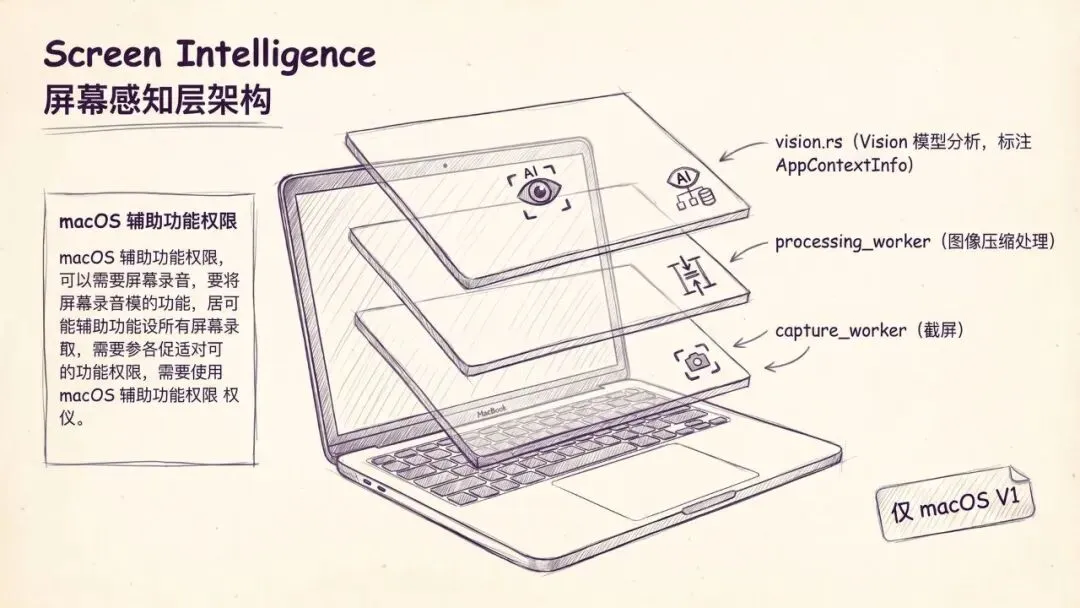
Screen Intelligence 目前是 macOS 专属(V1 注释原话:"screen intelligence is macOS-only in V1"),申请辅助功能权限后做屏幕录制和前台 App 识别。
架构分三层,对应三个 worker:
- •
capture_worker.rs:后台定时截屏,输出CaptureFrame - •
processing_worker.rs:图像压缩处理,输出标准化帧 - •
vision.rs:Vision 模型分析,输出AppContextInfo(前台 App 上下文)
数据结构命名风格像操作系统级感知层,而不是截图工具:AccessibilityEngine、SessionRuntime、PermissionKind。跨平台扩展时,这套架构基本不动,只换底层平台 API。
七、整体数据流
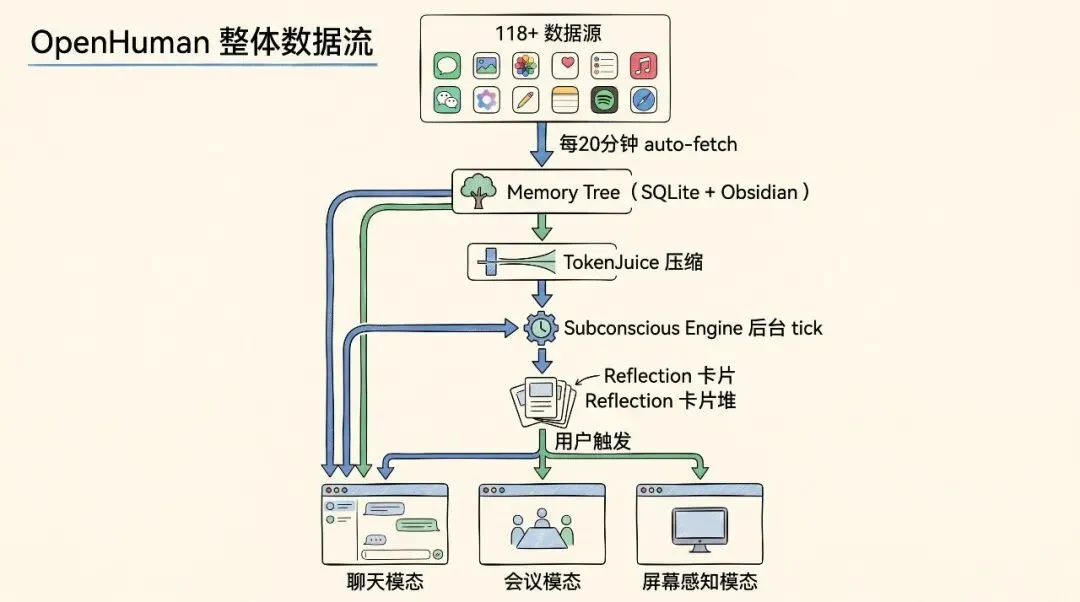
118+ 数据源
↓ 每20分钟 auto-fetch
Memory Tree(SQLite + Obsidian vault)
↓ chunker.rs 三级分块 + TokenJuice 压缩
Subconscious Engine(后台 tick 循环)
↓ situation_report → LLM 评估 → noop / act / escalate
Reflection 卡片(Intelligence 标签页,用户主动触发)
↓
三种 Agent 模态
├── 聊天(文字对话)
├── Meet Agent(Google Meet 实时参会)
└── Screen Intelligence(屏幕感知,macOS)核心设计哲学:把"主动打扰"降到最低。数据在后台安静消化,Reflection 静静堆在卡片上,AI 不会主动弹窗——除非你点。
结尾
OpenHuman 现在是 Early Beta,但代码质量比同类项目扎实——Cargo.toml 的注释里记录了被删依赖的具体堆内存 profile 数据,prompt 里写了防混淆的 Self vs Others 规则,VAD 有 250ms 防误触过滤,tick 有代际保护……这些细节不是做给 README 看的。
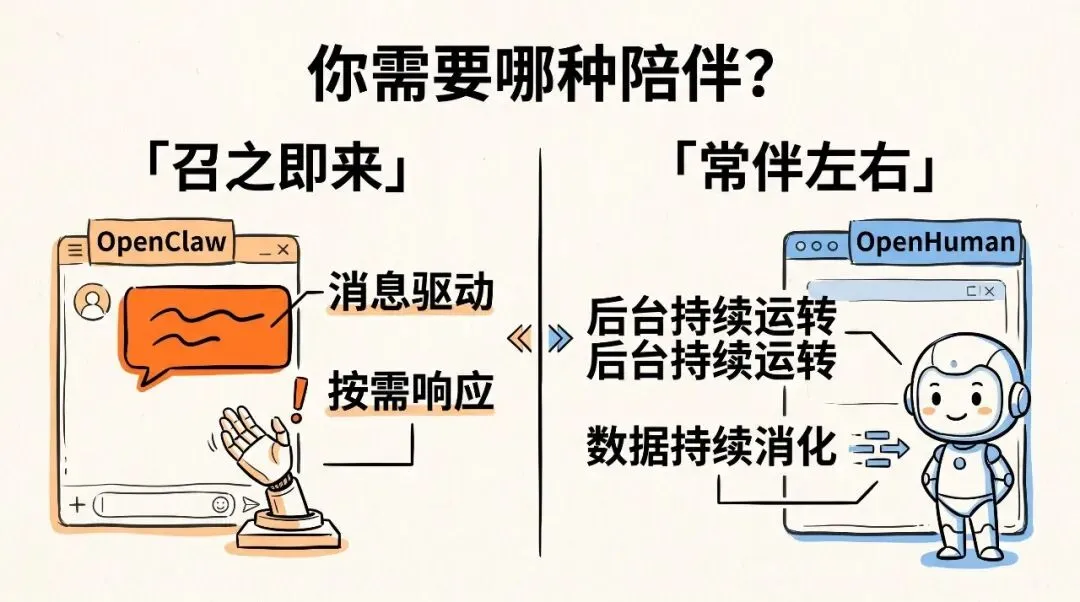
它和 OpenClaw 的定位有根本差异:OpenClaw 是消息驱动的,你发消息它响应;OpenHuman 是持续运转的,它在后台一直消化你的数据,等你需要时已经准备好。
哪种更适合你,取决于你更需要"召之即来"还是"常伴左右"。
⭐ tinyhumansai/openhuman,今天 GitHub Trending 第一,创作者 @senamakel。
本文基于 tinyhumansai/openhuman 主分支源码(2026-05-18 commit),版本 0.53.49
