 夜雨聆风
夜雨聆风源码剖析
后端相关的代码量是比较多的,思之又想还是将其分解我后端和后端缓冲区来讲解。
后端
ggml_backend 是 GGML 库中用于抽象底层计算硬件的核心接口。
它的核心作用,就是提供一个统一的“硬件抽象层”,让你的模型代码能够“一次编写,随处运行”。
根据上一节的调度器,我们继续往下分解:
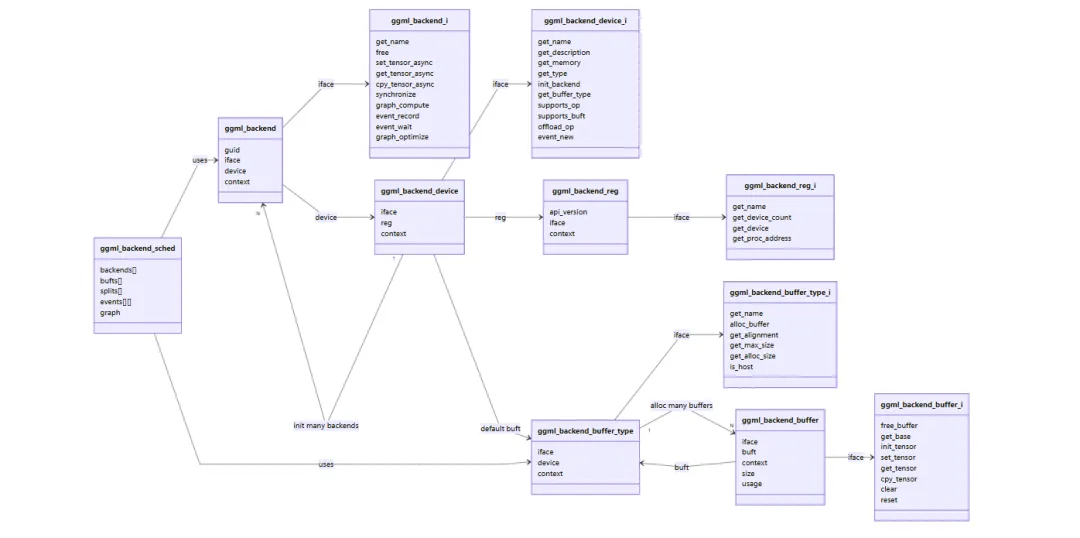
在调度器的调度下,会分割出多个后端数据,这里了解一下后端的数据结构:
ggml-backend-imp.h
// 后端结构包含了后端接口、设备信息、上下文信息等字段,表示一个后端实例。structggml_backend {ggml_guid_t guid; // 唯一标识后端的 GUID,允许区分不同的后端实例structggml_backend_i iface; // 后端接口,包含与后端交互的函数指针,例如计算图执行、事件同步等ggml_backend_dev_t device; // 关联的设备信息,指示该后端实例使用的设备,例如 CPU、GPU 等void* context; // 上下文信息,允许后端存储与其相关的特定于后端的数据或状态,例如资源管理、性能统计等};后端接口
后端接口,包含与后端交互的函数指针,例如计算图执行、事件同步等
ggml-backend-imp.h
// 后端接口定义了与后端交互的函数指针,包括获取后端名称、释放后端资源、异步张量数据访问、计算图执行、事件同步等函数。structggml_backend_i {// 后端名称,表示后端的简短标识符,例如 "CPU" 或 "CUDA",用于区分不同的后端和进行后端选择。constchar * (*get_name)(ggml_backend_t backend);// 释放后端占用的资源,确保正确管理内存和其他相关资源,防止内存泄漏和资源浪费。void (*free)(ggml_backend_t backend);// (optional) asynchronous tensor data access// 异步张量数据访问的函数,允许在不阻塞主线程的情况下设置和获取张量数据,以及在不同后端之间复制张量数据。void (*set_tensor_async)(ggml_backend_t backend, struct ggml_tensor * tensor, constvoid * data, size_t offset, size_t size);void (*get_tensor_async)(ggml_backend_t backend, conststruct ggml_tensor * tensor, void * data, size_t offset, size_t size);bool (*cpy_tensor_async)(ggml_backend_t backend_src, ggml_backend_t backend_dst, conststruct ggml_tensor * src, struct ggml_tensor * dst);// (optional) complete all pending operations (required if the backend supports async operations)// 同步函数,允许等待所有挂起的操作完成,以确保数据一致性和正确的执行顺序。// 这对于支持异步操作的后端非常重要,因为它可以确保在继续执行后续操作之前,所有相关的计算和数据传输都已经完成。void (*synchronize)(ggml_backend_t backend);// (optional) graph plans (not used currently)// compute graph with a plan// 计算图计划的函数,允许创建、更新和计算图计划。图计划是一种优化计算图执行的策略,可以提高性能和效率。ggml_backend_graph_plan_t (*graph_plan_create) (ggml_backend_t backend, conststruct ggml_cgraph * cgraph);// 释放图计划占用的资源,确保正确管理内存和其他相关资源,防止内存泄漏和资源浪费。void (*graph_plan_free) (ggml_backend_t backend, ggml_backend_graph_plan_t plan);// update the plan with a new graph - this should be faster than creating a new plan when the graph has the same topology// 使用新的计算图更新图计划 - 当计算图具有相同的拓扑结构时,这应该比创建一个新的图计划更快。void (*graph_plan_update) (ggml_backend_t backend, ggml_backend_graph_plan_t plan, conststruct ggml_cgraph * cgraph);// compute the graph with the plan// 使用图计划计算图 - 这应该比没有计划的计算更快,尤其是对于大型和复杂的计算图,因为图计划可以优化执行策略和资源管理。enumggml_status(*graph_plan_compute)(ggml_backend_t backend, ggml_backend_graph_plan_t plan);// compute graph (always async if supported by the backend)// 计算图 - 如果后端支持,这将始终是异步的。这允许在不阻塞主线程的情况下执行计算图,提高性能和效率,尤其是在处理大型和复杂的计算图时。enumggml_status(*graph_compute)(ggml_backend_t backend, struct ggml_cgraph * cgraph);// (optional) event synchronization// record an event on this stream// 在当前流上记录一个事件,允许后端跟踪计算图执行的进度和状态。这对于实现事件同步和优化计算图执行非常重要,尤其是在使用多个后端进行计算时。void (*event_record)(ggml_backend_t backend, ggml_backend_event_t event);// wait for an event on on a different stream// 在不同的流上等待一个事件,允许后端实现跨流的事件同步,以确保在继续执行后续操作之前,相关的计算和数据传输已经完成。这对于优化计算图执行和资源管理非常重要,尤其是在处理大型和复杂的计算图时。void (*event_wait) (ggml_backend_t backend, ggml_backend_event_t event);// (optional) sort/optimize the nodes in the graph// 计算图优化的函数,允许对计算图中的节点进行排序和优化,以提高性能和效率。这对于处理大型和复杂的计算图非常重要,因为优化可以减少计算时间和资源使用。void (*graph_optimize) (ggml_backend_t backend, struct ggml_cgraph * cgraph);};下面以 CPU 和 Cuda 为例,看看在其初始化的时候都进行了哪些函数指针的赋值。
ggml-cpu.cpp
ggml_backend_tggml_backend_cpu_init(void){// initialize CPU backend now to avoid slowing the first graph computationggml_cpu_init();structggml_backend_cpu_context * ctx = new ggml_backend_cpu_context;if (ctx == NULL) {returnNULL; } ctx->n_threads = GGML_DEFAULT_N_THREADS; ctx->threadpool = NULL; ctx->work_data = NULL; ctx->work_size = 0; ctx->abort_callback = NULL; ctx->abort_callback_data = NULL; ctx->use_ref = false;ggml_backend_t cpu_backend = new ggml_backend {/* .guid = */ggml_backend_cpu_guid(),/* .iface = */ ggml_backend_cpu_i,/* .device = */ggml_backend_reg_dev_get(ggml_backend_cpu_reg(), 0),/* .context = */ ctx, };if (cpu_backend == NULL) {delete ctx;returnNULL; }return cpu_backend;}...staticconststructggml_backend_i ggml_backend_cpu_i = {/* .get_name = */ ggml_backend_cpu_get_name,/* .free = */ ggml_backend_cpu_free,/* .set_tensor_async = */NULL,/* .get_tensor_async = */NULL,/* .cpy_tensor_async = */NULL,/* .synchronize = */NULL,/* .graph_plan_create = */ ggml_backend_cpu_graph_plan_create,/* .graph_plan_free = */ ggml_backend_cpu_graph_plan_free,/* .graph_plan_update = */NULL,/* .graph_plan_compute = */ ggml_backend_cpu_graph_plan_compute,/* .graph_compute = */ ggml_backend_cpu_graph_compute,/* .event_record = */NULL,/* .event_wait = */NULL,/* .graph_optimize = */NULL,};ggml-cuda.cu
ggml_backend_tggml_backend_cuda_init(int device){if (device < 0 || device >= ggml_backend_cuda_get_device_count()) {GGML_LOG_ERROR("%s: invalid device %d\n", __func__, device);returnnullptr; } ggml_backend_cuda_context * ctx = newggml_backend_cuda_context(device);if (ctx == nullptr) {GGML_LOG_ERROR("%s: failed to allocate context\n", __func__);returnnullptr; }ggml_backend_t cuda_backend = new ggml_backend {/* .guid = */ggml_backend_cuda_guid(),/* .iface = */ ggml_backend_cuda_interface,/* .device = */ggml_backend_reg_dev_get(ggml_backend_cuda_reg(), device),/* .context = */ ctx, };return cuda_backend;}...staticconst ggml_backend_i ggml_backend_cuda_interface = {/* .get_name = */ ggml_backend_cuda_get_name,/* .free = */ ggml_backend_cuda_free,/* .set_tensor_async = */ ggml_backend_cuda_set_tensor_async,/* .get_tensor_async = */ ggml_backend_cuda_get_tensor_async,/* .cpy_tensor_async = */ ggml_backend_cuda_cpy_tensor_async,/* .synchronize = */ ggml_backend_cuda_synchronize,/* .graph_plan_create = */NULL,/* .graph_plan_free = */NULL,/* .graph_plan_update = */NULL,/* .graph_plan_compute = */NULL,/* .graph_compute = */ ggml_backend_cuda_graph_compute,/* .event_record = */ ggml_backend_cuda_event_record,/* .event_wait = */ ggml_backend_cuda_event_wait,/* .graph_optimize = */ ggml_backend_cuda_graph_optimize,};后端设备
ggml-backend-imp.h
// GGML 后端设备结构包含了后端设备接口、注册信息和上下文信息等字段,表示一个后端设备实例。structggml_backend_device {structggml_backend_device_i iface; // 后端设备接口,包含与后端设备交互的函数指针,例如获取设备信息、初始化后端、检查操作支持等ggml_backend_reg_t reg; // 注册信息,指示该设备所属的后端注册实例,允许设备与其所属的后端进行关联和管理void* context; // 上下文信息,允许后端设备存储与其相关的特定于后端的数据或状态,例如资源管理、性能统计等};// Note: if additional properties are needed, we should add a struct with all of them// the current functions to obtain the properties can remain, since they are more convenient for often used properties// 后端设备接口定义了与后端设备交互的函数指针,包括获取设备信息、初始化后端、检查操作支持等函数。structggml_backend_device_i {// device name: short identifier for this device, such as "CPU" or "CUDA0"// 设备名称,表示设备的简短标识符,例如 "CPU" 或 "CUDA0",用于区分不同的设备和进行设备选择。constchar * (*get_name)(ggml_backend_dev_t dev);// device description: short informative description of the device, could be the model name// 设备描述,提供设备的简短信息描述,可以是设备的型号名称等,用于了解设备的特性和性能等方面的信息。constchar * (*get_description)(ggml_backend_dev_t dev);// device memory in bytes: 0 bytes to indicate no memory to report// 设备内存,以字节为单位,0 字节表示没有可报告的内存,用于评估设备的内存资源和进行内存管理。void (*get_memory)(ggml_backend_dev_t dev, size_t * free, size_t * total);// device type// 设备类型,表示设备的类型,例如 CPU、GPU、集成 GPU 或加速器设备,用于根据设备类型优化计算和内存管理策略。enumggml_backend_dev_type(*get_type)(ggml_backend_dev_t dev);// device properties// 设备属性,表示设备的功能,例如异步操作、固定主机缓冲区、从主机指针创建缓冲区和事件同步等,用于评估设备的功能和优化计算策略。void (*get_props)(ggml_backend_dev_t dev, struct ggml_backend_dev_props * props);// backend (stream) initialization// 后端初始化函数,允许在设备上创建一个后端实例,以便进行计算和数据管理等操作。ggml_backend_t (*init_backend)(ggml_backend_dev_t dev, constchar * params);// preferred buffer type// 首选缓冲区类型,表示设备首选的缓冲区类型,例如 CPU、CUDA、Metal 等,用于优化性能和内存使用。ggml_backend_buffer_type_t (*get_buffer_type)(ggml_backend_dev_t dev);// (optional) host buffer type (in system memory, typically this is a pinned memory buffer for faster transfers between host and device)// 主机缓冲区类型(在系统内存中,通常是用于加速主机和设备之间传输的固定内存缓冲区),允许设备指定其首选的主机缓冲区类型,以优化数据传输性能。ggml_backend_buffer_type_t (*get_host_buffer_type)(ggml_backend_dev_t dev);// (optional) buffer from pointer: create a buffer from a host pointer (useful for memory mapped models and importing data from other libraries)// 从主机指针创建缓冲区的函数,允许设备从主机指针创建一个缓冲区,这对于内存映射模型和从其他库导入数据非常有用。ggml_backend_buffer_t (*buffer_from_host_ptr)(ggml_backend_dev_t dev, void * ptr, size_t size, size_t max_tensor_size);// check if the backend can compute an operation// 检查后端是否可以计算一个操作,允许设备检查其是否支持计算特定的操作,以便在计算图执行时进行操作分配和优化。bool (*supports_op)(ggml_backend_dev_t dev, conststruct ggml_tensor * op);// check if the backend can use tensors allocated in a buffer type// 检查后端是否可以使用在缓冲区类型中分配的张量,允许设备检查其是否支持使用特定缓冲区类型中分配的张量,以便在计算图执行时进行张量分配和优化。bool (*supports_buft)(ggml_backend_dev_t dev, ggml_backend_buffer_type_t buft);// (optional) check if the backend wants to run an operation, even if the weights are allocated in an incompatible buffer// these should be expensive operations that may benefit from running on this backend instead of the CPU backend// 检查后端是否希望运行一个操作,即使权重分配在不兼容的缓冲区中,这些应该是可能受益于在此后端上运行而不是 CPU 后端的昂贵操作。// 允许设备检查其是否希望运行特定的操作,即使权重分配在不兼容的缓冲区中,这对于那些可能受益于在此后端上运行而不是 CPU 后端的昂贵操作非常有用。bool (*offload_op)(ggml_backend_dev_t dev, conststruct ggml_tensor * op);// (optional) event synchronization// 事件同步函数,允许设备支持事件记录和等待,以便在不同的计算流之间进行同步和协调。ggml_backend_event_t (*event_new) (ggml_backend_dev_t dev);// 事件释放函数,允许设备释放一个事件实例,以便正确管理资源和避免内存泄漏。void (*event_free) (ggml_backend_dev_t dev, ggml_backend_event_t event);// 事件同步函数,允许设备等待一个事件完成,以便在不同的计算流之间进行同步和协调。void (*event_synchronize) (ggml_backend_dev_t dev, ggml_backend_event_t event);};// GGML 后端注册结构包含了后端注册接口和上下文信息等字段,表示一个后端注册实例。structggml_backend_reg {int api_version; // initialize to GGML_BACKEND_API_VERSION // API 版本,表示后端注册的 API 版本,用于确保后端注册与 ggml-backend 库的兼容性。structggml_backend_reg_i iface; // 后端注册接口,包含与后端注册交互的函数指针,例如获取后端名称、枚举可用设备和获取函数地址等void* context; // 上下文信息,允许后端注册存储与其相关的特定于后端的数据或状态,例如资源管理、性能统计等};// 后端注册接口定义了与后端注册交互的函数指针,包括获取后端名称、枚举可用设备和获取函数地址等函数。structggml_backend_reg_i {constchar* (*get_name)(ggml_backend_reg_t reg); // 后端名称,表示后端的名称,用于区分不同的后端实现和进行后端选择。// enumerate available devices// 枚举可用设备的函数,允许后端注册枚举其可用的设备,以便在后续的设备选择和管理中使用。size_t(*get_device_count)(ggml_backend_reg_t reg); // 获取设备数量的函数,允许后端注册返回其可用设备的数量,以便在枚举设备时进行迭代和管理。ggml_backend_dev_t(*get_device)(ggml_backend_reg_t reg, size_t index); // 获取设备的函数,允许后端注册返回其可用设备的实例,以便在设备选择和管理中使用。// (optional) get a pointer to a function in the backend// backends can add custom functions that are not part of the standard ggml-backend interface// 获取函数地址的函数,允许后端注册返回一个指向后端中函数的指针,以便在需要调用后端特定功能时使用。这对于那些不属于标准 ggml-backend 接口的自定义函数非常有用。void * (*get_proc_address)(ggml_backend_reg_t reg, constchar * name);};总结一下各个结构体的相关职责:
• ggml_backend_reg:后端插件入口,负责暴露“有哪些设备”。• ggml_backend_device:描述物理设备能力(类型、内存、是否支持某 op/buffer type)。• ggml_backend:设备上的执行实例(可理解为 stream/command queue 抽象),负责graph_compute、synchronize、异步拷贝等。• ggml_backend_buffer_type:内存分配策略(对齐、最大大小、是否 host memory)。• ggml_backend_buffer:真实内存对象,承载 tensor 的读写/拷贝。• ggml_backend_sched:多 backend 编排器,决定 split、copy、event 同步。
可以看出在 ggml_backend_device 后端设备结构中,用 ggml_backend_buffer 维护了这是内存对象:
• CPU 在内存中 • Cuda 在显存中
这一部分相关后端缓冲区的部分,我们在下一节进行详细讲解。
源码
阅读源码,当我们构建好模型后端和计算图后,会调用 ggml_backend_graph_compute() 函数来执行计算。
ggml-backend.cpp
// 后端计算图的执行函数,提供同步和异步两种接口,允许调用者根据需要选择合适的执行方式enum ggml_status ggml_backend_graph_compute(ggml_backend_t backend, struct ggml_cgraph * cgraph){// 默认实现是调用异步接口并等待完成,这样可以保证兼容所有后端,即使它们没有实现同步接口enumggml_status err = ggml_backend_graph_compute_async(backend, cgraph);// 如果后端没有实现异步接口,或者异步接口返回错误,我们需要同步后端以确保所有操作完成,然后返回错误状态ggml_backend_synchronize(backend);return err;}// 后端计算图的异步执行函数,允许后端在后台执行计算图,同时调用者可以继续执行其他操作,直到需要结果时再同步等待enum ggml_status ggml_backend_graph_compute_async(ggml_backend_t backend, struct ggml_cgraph * cgraph){GGML_ASSERT(backend);// 如果后端没有实现异步接口,我们直接调用同步接口来执行计算图,这样可以保证所有后端都能执行计算图,即使它们没有实现异步接口return backend->iface.graph_compute(backend, cgraph);}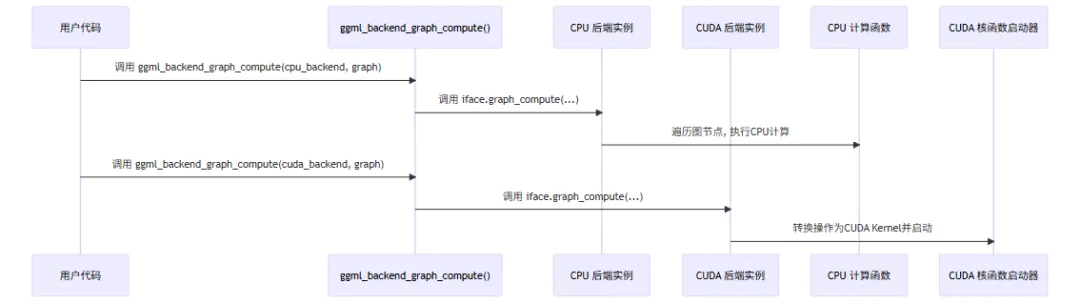
他会调用后端接口的 graph_compute() 函数来执行图计算过程。
从上面的代码可以看出,通过函数指针来实现不同后端的函数调用,来进行计算图的计算:
• Cpu 侧调用 : ggml_backend_cpu_graph_compute()函数• Cuda 侧调用: ggml_backend_cuda_graph_compute()函数
CPU 后端图计算
ggml-cpu.cpp
// 后端 CPU 的计算函数,使用图计划计算图。// 这应该比没有计划的计算更快,尤其是对于大型和复杂的计算图,因为图计划可以优化执行策略和资源管理。staticenum ggml_status ggml_backend_cpu_graph_compute(ggml_backend_t backend, struct ggml_cgraph * cgraph){// 直接使用图计划计算图,而不是每次都创建一个新的图计划,这样可以提高性能,尤其是当计算图具有相同的拓扑结构时。structggml_backend_cpu_context * cpu_ctx = (struct ggml_backend_cpu_context *)backend->context;// 计算图计划包含了计算过程中需要使用的工作缓冲区的大小和数据指针,以及计算过程中使用的线程数量和线程池等信息。structggml_cplan cplan = ggml_graph_plan(cgraph, cpu_ctx->n_threads, cpu_ctx->threadpool);// 如果计算图计划需要使用工作缓冲区,并且当前的工作缓冲区大小不足以满足需求,则重新分配工作缓冲区。if (cpu_ctx->work_size < cplan.work_size) {delete[] cpu_ctx->work_data; cpu_ctx->work_data = newuint8_t[cplan.work_size];if (cpu_ctx->work_data == NULL) { cpu_ctx->work_size = 0;return GGML_STATUS_ALLOC_FAILED; } cpu_ctx->work_size = cplan.work_size; }// 将计算图计划中的工作缓冲区数据指针设置为当前的工作缓冲区数据指针,这样在计算过程中就可以使用这个工作缓冲区了。 cplan.work_data = (uint8_t *)cpu_ctx->work_data;// 将计算图计划中的中止回调函数和数据指针设置为当前的中止回调函数和数据指针,这样在计算过程中就可以使用这个中止回调函数了。 cplan.abort_callback = cpu_ctx->abort_callback; cplan.abort_callback_data = cpu_ctx->abort_callback_data;// 将计算图计划中的是否仅使用参考实现的选项设置为当前的选项,这样在计算过程中就可以根据这个选项来决定是否仅使用参考实现了。 cplan.use_ref = cpu_ctx->use_ref; returnggml_graph_compute(cgraph, &cplan);}ggml-cpu.c
// 计算图执行的主函数enum ggml_status ggml_graph_compute(struct ggml_cgraph * cgraph, struct ggml_cplan * cplan){// CPU 初始化,设置线程优先级和亲和力等ggml_cpu_init();GGML_ASSERT(cplan);GGML_ASSERT(cplan->n_threads > 0);GGML_ASSERT(cplan->work_size == 0 || cplan->work_data != NULL);int n_threads = cplan->n_threads;structggml_threadpool * threadpool = cplan->threadpool;bool disposable_threadpool = false;// 如果没有指定线程池,则创建一个一次性的线程池if (threadpool == NULL) {//GGML_PRINT_DEBUG("Threadpool is not specified. Will create a disposable threadpool : n_threads %d\n", n_threads); disposable_threadpool = true;// 创建一个新的线程池,使用默认参数,并将计算图和计算计划传递给线程池structggml_threadpool_params ttp = ggml_threadpool_params_default(n_threads); threadpool = ggml_threadpool_new_impl(&ttp, cgraph, cplan); } else {// Reset some of the parameters that need resetting// No worker threads should be accessing the parameters below at this stage// 计算图和计算计划可能会在每次调用 ggml_graph_compute 时更新,因此需要重置这些参数 threadpool->cgraph = cgraph; threadpool->cplan = cplan; threadpool->current_chunk = 0; threadpool->abort = -1; threadpool->ec = GGML_STATUS_SUCCESS; }#ifdef GGML_USE_OPENMP // 使用 OpenMP 进行并行计算if (n_threads > 1) {// OpenMP 线程数可能会因为环境变量或系统限制而与请求的线程数不同,因此在并行区域内更新实际线程数#pragma omp parallel num_threads(n_threads) {// 只有一个线程执行这个块,负责更新实际线程数和设置线程优先级和亲和力#pragma omp single {// update the number of threads from the actual number of threads that we got from OpenMP// OpenMP 线程数可能会因为环境变量或系统限制而与请求的线程数不同,因此在并行区域内更新实际线程数 n_threads = omp_get_num_threads();// 将实际线程数存储在原子变量中,以便其他线程可以访问atomic_store_explicit(&threadpool->n_graph, n_threads, memory_order_relaxed); }// Apply thread CPU mask and priority// 每个线程根据线程池的配置设置自己的 CPU 亲和力和优先级int ith = omp_get_thread_num();// 线程的亲和力设置可能会受到 OpenMP 实现的限制,因此这里尝试设置亲和力,但不强制要求成功ggml_thread_apply_priority(threadpool->prio);// 如果线程池为当前线程指定了有效的 CPU 亲和力掩码,则应用该亲和力设置if (ggml_thread_cpumask_is_valid(threadpool->workers[ith].cpumask)) {ggml_thread_apply_affinity(threadpool->workers[ith].cpumask); }// 每个线程执行计算图的计算函数,传递线程池和线程索引作为参数ggml_graph_compute_thread(&threadpool->workers[ith]); } } else {// 如果只有一个线程,则直接执行计算图的计算函数,无需进入并行区域atomic_store_explicit(&threadpool->n_graph, 1, memory_order_relaxed);// 使用主线程执行计算图的计算函数,传递线程池和线程索引 0 作为参数ggml_graph_compute_thread(&threadpool->workers[0]); }#else// 如果没有使用 OpenMP,则使用自定义的线程池实现进行计算if (n_threads > threadpool->n_threads) {GGML_LOG_WARN("cplan requested more threads (%d) than available (%d)\n", n_threads, threadpool->n_threads); n_threads = threadpool->n_threads; }// Kick all threads to start the new graph// 通过调用 ggml_graph_compute_kickoff 函数,通知所有工作线程开始处理新的计算图ggml_graph_compute_kickoff(threadpool, n_threads);// This is a work thread too// 使用主线程执行计算图的计算函数,传递线程池和线程索引 0 作为参数ggml_graph_compute_thread(&threadpool->workers[0]);#endif// don't leave affinity set on the main thread// 计算完成后,清除主线程的 NUMA 亲和力设置,以避免对后续操作产生影响clear_numa_thread_affinity();// 计算完成后,如果使用了一次性的线程池,则释放线程池资源enumggml_status ret = threadpool->ec;// 如果线程池是一次性的,则在计算完成后释放线程池资源if (disposable_threadpool) {ggml_threadpool_free(threadpool); }return ret;}...// 图计算线程函数staticthread_ret_tggml_graph_compute_thread(void * data){structggml_compute_state* state = (struct ggml_compute_state*)data; // 计算状态structggml_threadpool* tp = state->threadpool; // 线程池conststructggml_cgraph* cgraph = tp->cgraph; // 计算图conststructggml_cplan* cplan = tp->cplan; // 计算计划set_numa_thread_affinity(state->ith); // 设置线程亲和性// 设置线程优先级structggml_compute_params params = {/*.ith =*/ state->ith,/*.nth =*/atomic_load_explicit(&tp->n_graph, memory_order_relaxed) & GGML_THREADPOOL_N_THREADS_MASK,/*.wsize =*/ cplan->work_size,/*.wdata =*/ cplan->work_data,/*.threadpool =*/ tp,/*.use_ref =*/ cplan->use_ref, };#ifdef GGML_USE_OPENMPGGML_PRINT_DEBUG("thread #%d compute-start cplan %p\n", state->ith, (constvoid *)cplan);#elseGGML_PRINT_DEBUG("thread #%d compute-start cplan %p last-graph %d\n", state->ith, (constvoid *)cplan, state->last_graph);#endif// 遍历计算图的节点,执行计算for (int node_n = 0; node_n < cgraph->n_nodes && atomic_load_explicit(&tp->abort, memory_order_relaxed) != node_n; node_n++) {// 获取当前节点张量structggml_tensor * node = cgraph->nodes[node_n];if (ggml_op_is_empty(node->op)) {// skip NOPscontinue; }if ((node->flags & GGML_TENSOR_FLAG_COMPUTE) == 0) {continue; }// 执行前向计算ggml_compute_forward(¶ms, node);// 如果是第一个节点,且有中止回调函数,检查是否需要中止计算if (state->ith == 0 && cplan->abort_callback && cplan->abort_callback(cplan->abort_callback_data)) {atomic_store_explicit(&tp->abort, node_n + 1, memory_order_relaxed); tp->ec = GGML_STATUS_ABORTED; }// 如果当前节点不是最后一个节点,且有中止回调函数,等待所有线程到达屏障后继续下一轮计算if (node_n + 1 < cgraph->n_nodes) {// 等待所有线程到达屏障,继续下一轮计算ggml_barrier(state->threadpool); } }#ifdef GGML_USE_OPENMPGGML_PRINT_DEBUG("thread #%d compute-done cplan %p\n", state->ith, (constvoid *)cplan);#elseGGML_PRINT_DEBUG("thread #%d compute-done cplan %p last-graph %d\n", state->ith, (constvoid *)cplan, state->last_graph);#endif// 最后一个节点计算完成后,等待所有线程到达屏障,确保所有线程都完成计算ggml_barrier(state->threadpool);return0;}我将关键代码进行了相关注释,代码并不是很复杂,不做过多讲解了,值得关注的是 ggml_cplan 结构体,它维护了工作缓冲区和线程池等信息。
// ggml 计算规划,ggml_graph_compute() 需要准备这个计划// 包含了计算过程中需要使用的工作缓冲区和线程池等信息structggml_cplan {// 工作缓冲区的大小和数据指针,工作缓冲区是计算过程中需要使用的临时存储空间size_t work_size; // size of work buffer, calculated by `ggml_graph_plan()`uint8_t * work_data; // work buffer, to be allocated by caller before calling to `ggml_graph_compute()`int n_threads; // 计算过程中使用的线程数量,表示在计算过程中可以使用的线程数量,通常根据系统的 CPU 核心数量进行设置structggml_threadpool* threadpool; // 计算过程中使用的线程池,表示在计算过程中可以使用的线程池,线程池可以管理和调度多个线程以提高计算效率// abort ggml_graph_compute when true ggml_abort_callback abort_callback; // 计算过程中用于中止计算的回调函数,表示在计算过程中可以通过调用这个回调函数来中止计算,通常用于处理用户取消操作或超时等情况void* abort_callback_data; // 中止回调函数的数据指针,表示在调用中止回调函数时传递给回调函数的数据指针,可以用于提供额外的信息或上下文// use only reference implementationsbool use_ref; // 是否仅使用参考实现,表示在计算过程中是否仅使用参考实现,参考实现通常是指没有针对特定硬件进行优化的通用实现,启用这个选项可能会降低计算性能,但可以提高计算的兼容性和稳定性};CUDA 后端图计算
ggml-cuda.cu
// 后端 CUDA 计算图执行函数,负责执行计算图中的所有节点,并根据条件使用 CUDA 图进行优化执行。// 该函数首先检查是否启用了 CUDA 图,并根据计算图的结构和节点类型决定是否使用 CUDA 图进行执行。// 如果需要更新 CUDA 图,则在执行前开始捕获 CUDA 图,并在执行后结束捕获并更新 CUDA 图的可执行实例。staticenum ggml_status ggml_backend_cuda_graph_compute(ggml_backend_t backend, ggml_cgraph * cgraph){// 获取 CUDA 后端上下文并设置当前 CUDA 设备 ggml_backend_cuda_context * cuda_ctx = (ggml_backend_cuda_context *) backend->context;// 图执行前需要确保当前线程绑定到正确的 CUDA 设备ggml_cuda_set_device(cuda_ctx->device);bool use_cuda_graph = false; // 是否使用 CUDA 图进行执行bool cuda_graph_update_required = false; // 是否需要更新 CUDA 图的可执行实例constvoid* graph_key = nullptr; // CUDA 图的唯一标识符,用于在 CUDA 上下文中管理不同的 CUDA 图实例// 如果启用了 CUDA 图功能,则获取当前计算图对应的 CUDA 图的唯一标识符,并检查是否启用 CUDA 图进行执行#ifdef USE_CUDA_GRAPH// 获取当前计算图对应的 CUDA 图的唯一标识符 graph_key = ggml_cuda_graph_get_key(cgraph);// 检查是否启用 CUDA 图进行执行 use_cuda_graph = ggml_cuda_graph_set_enabled(cuda_ctx, graph_key);// 如果 CUDA 图已启用,则检查是否需要更新 CUDA 图的可执行实例 ggml_cuda_graph * graph = cuda_ctx->cuda_graph(graph_key);// 检查 CUDA 图是否需要更新可执行实例,主要是根据计算图的结构和节点类型来判断是否需要重新捕获 CUDA 图并更新可执行实例if (graph->is_enabled()) {// 检查 CUDA 图是否需要更新可执行实例 cuda_graph_update_required = ggml_cuda_graph_update_required(cuda_ctx, cgraph);// 检查当前计算图是否兼容 CUDA 图执行,如果不兼容则不使用 CUDA 图进行执行 use_cuda_graph = ggml_cuda_graph_check_compability(cgraph);// 记录当前计算图的结构和节点类型等信息,以便在下一次执行时判断是否需要更新 CUDA 图的可执行实例 graph->record_update(use_cuda_graph, cuda_graph_update_required); }#endif// USE_CUDA_GRAPH// 如果启用了 CUDA 图并且需要更新 CUDA 图的可执行实例,则开始捕获 CUDA 图if (use_cuda_graph && cuda_graph_update_required) {// Start CUDA graph capture {// 使用互斥锁保护 CUDA 图捕获的计数器,确保在多线程环境下正确管理 CUDA 图的捕获状态std::lock_guard<std::mutex> lock(ggml_cuda_lock);// 增加 CUDA 图捕获计数器,表示当前线程正在捕获 CUDA 图 ggml_cuda_lock_counter.fetch_add(1, std::memory_order_relaxed); }// 开始捕获 CUDA 图,使用 relaxed 模式允许在捕获期间进行某些操作(如内存分配等),以提高性能CUDA_CHECK(cudaStreamBeginCapture(cuda_ctx->stream(), cudaStreamCaptureModeRelaxed)); }// 执行计算图中的所有节点,并根据条件使用 CUDA 图进行优化执行ggml_cuda_graph_evaluate_and_capture(cuda_ctx, cgraph, use_cuda_graph, cuda_graph_update_required, graph_key);return GGML_STATUS_SUCCESS;}// 执行 GGML 计算图的评估和 CUDA 图的捕获// 这个函数负责评估 GGML 计算图,并在适当的情况下捕获 CUDA 图以优化后续执行staticvoidggml_cuda_graph_evaluate_and_capture(ggml_backend_cuda_context * cuda_ctx, ggml_cgraph * cgraph, constbool use_cuda_graph, constbool cuda_graph_update_required, constvoid * graph_key){bool graph_evaluated_or_captured = false; // 图是否已经被评估或捕获的标志// flag used to determine whether it is an integrated_gpu// 标记用于确定是否是集成 GPUconstbool integrated = ggml_cuda_info().devices[cuda_ctx->device].integrated;// CUDA 流上下文和并发事件相关的变量 ggml_cuda_stream_context & stream_ctx = cuda_ctx->stream_context();bool is_concurrent_event_active = false; // 当前是否有并发事件正在进行// 当前并发事件的指针 ggml_cuda_concurrent_event * concurrent_event = nullptr;bool should_launch_concurrent_events = false; // 标志用于确定是否应该启动并发事件// Lambda 函数用于尝试启动与给定节点相关的并发事件constauto try_launch_concurrent_event = [&](const ggml_tensor * node) {// 检查当前节点是否与任何并发事件相关联,如果是,则启动该事件并设置适当的 CUDA 流等待关系if (stream_ctx.concurrent_events.find(node) != stream_ctx.concurrent_events.end()) {// 如果当前节点是一个并发事件的起点,则启动该事件并设置适当的 CUDA 流等待关系 concurrent_event = &stream_ctx.concurrent_events[node]; is_concurrent_event_active = true; // 设置当前并发事件为活动状态GGML_LOG_DEBUG("Launching %d streams at %s\n", concurrent_event->n_streams, node->name);// 在主线程中记录一个事件,分支线程将在开始工作前等待该事件 cudaStream_t main_stream = cuda_ctx->stream(); // this should be stream 0GGML_ASSERT(cuda_ctx->curr_stream_no == 0);CUDA_CHECK(cudaEventRecord(concurrent_event->fork_event, main_stream));// 设置分支线程等待主线程的事件,以确保正确的执行顺序for (int i = 1; i <= concurrent_event->n_streams; ++i) { cudaStream_t stream = cuda_ctx->stream(cuda_ctx->device, i);CUDA_CHECK(cudaStreamWaitEvent(stream, concurrent_event->fork_event)); } } };// 循环直到图被评估或捕获while (!graph_evaluated_or_captured) {// Only perform the graph execution if CUDA graphs are not enabled, or we are capturing the graph.// With the use of CUDA graphs, the execution will be performed by the graph launch.// 只有在 CUDA 图未启用或正在捕获图时才执行图的执行。// 使用 CUDA 图时,执行将由图的启动来完成。if (!use_cuda_graph || cuda_graph_update_required) { [[maybe_unused]] int prev_i = 0;// 检查是否有任何并发事件需要启动,并在适当的情况下启动它们if (stream_ctx.concurrent_events.size() > 0) { should_launch_concurrent_events = true;// 循环检查所有并发事件的有效性,以确保它们都可以被启动for (constauto & [tensor, event] : stream_ctx.concurrent_events) { should_launch_concurrent_events = should_launch_concurrent_events && event.is_valid(); } }// 如果应该启动并发事件,则恢复每个并发区域内的原始节点顺序,以启用流内的融合if (should_launch_concurrent_events) {// Restore original node order within each concurrent region to enable fusion within streams// 为每个并发区域恢复原始节点顺序,以启用流内的融合 std::unordered_map<const ggml_tensor *, int> node_to_idx;// 创建一个映射,将每个节点指针映射到其在当前图中的索引,以便快速查找 node_to_idx.reserve(cgraph->n_nodes);for (int i = 0; i < cgraph->n_nodes; ++i) { node_to_idx[cgraph->nodes[i]] = i; }// 循环遍历所有并发事件,并检查每个事件的原始节点顺序是否在当前图中是连续的,如果是,则恢复该顺序for (auto & [fork_node, event] : stream_ctx.concurrent_events) {// Find positions of all nodes from this event in the current graph// 查找当前图中所有来自此事件的节点的位置 std::vector<int> positions; positions.reserve(event.original_order.size());bool all_found = true;// 循环遍历事件的原始节点顺序,并使用之前创建的映射查找每个节点在当前图中的位置,如果找不到任何一个节点,则标记该事件为无效for (const ggml_tensor * orig_node : event.original_order) {auto it = node_to_idx.find(orig_node);if (it != node_to_idx.end()) { positions.push_back(it->second); } else { all_found = false;break; } }// 如果事件的所有节点都在当前图中找到,并且它们的位置数量与事件的原始节点数量相同,则继续检查这些位置是否连续,如果是,则恢复这些位置处的原始顺序if (!all_found || positions.size() != event.original_order.size()) {continue; }// Sort positions to get contiguous range// 对位置进行排序以获得连续范围 std::vector<int> sorted_positions = positions; std::sort(sorted_positions.begin(), sorted_positions.end());bool is_contiguous = true;// 检查排序后的位置是否连续,如果不是,则标记该事件为无效for (size_t i = 1; i < sorted_positions.size(); ++i) {if (sorted_positions[i] != sorted_positions[i-1] + 1) { is_contiguous = false;break; } }if (!is_contiguous) {continue; }// Restore original order at the sorted positions// 在排序后的位置恢复原始顺序int start_pos = sorted_positions[0];for (size_t i = 0; i < event.original_order.size(); ++i) { cgraph->nodes[start_pos + i] = const_cast<ggml_tensor *>(event.original_order[i]); } } } else {// 如果不应该启动任何并发事件,则清除所有并发事件,以避免在后续迭代中错误地启动它们 stream_ctx.concurrent_events.clear(); }// 循环遍历计算图中的所有节点,并执行每个节点的计算,同时检查是否有任何并发事件需要启动,并在适当的情况下启动它们for (int i = 0; i < cgraph->n_nodes; i++) { ggml_tensor* node = cgraph->nodes[i]; // 获取当前节点的指针// 检查当前节点是否与任何并发事件相关联,如果是,则启动该事件并设置适当的 CUDA 流等待关系if (is_concurrent_event_active) {GGML_ASSERT(concurrent_event);// 如果当前节点是一个并发事件的终点,则在主线程中等待所有分支线程完成,并将当前流设置回主线程流if (node == concurrent_event->join_node) { cuda_ctx->curr_stream_no = 0; // 将当前流设置回主线程流// 循环等待分支线程的 join 事件,以确保主线程在继续执行之前等待所有分支线程完成for (int i = 1; i <= concurrent_event->n_streams; ++i) {// Wait on join events of forked streams in the main stream// 在主流中等待分叉流的 join 事件CUDA_CHECK(cudaEventRecord(concurrent_event->join_events[i - 1], cuda_ctx->stream(cuda_ctx->device, i)));CUDA_CHECK(cudaStreamWaitEvent(cuda_ctx->stream(), concurrent_event->join_events[i - 1])); } is_concurrent_event_active = false; // 将当前并发事件标记为非活动状态 concurrent_event = nullptr; // 重置当前并发事件的指针 } else {// 如果当前节点是一个并发事件的内部节点,则将当前流设置为该节点在并发事件中的映射流,以确保该节点在正确的流上执行GGML_ASSERT (concurrent_event->stream_mapping.find(node) != concurrent_event->stream_mapping.end()); cuda_ctx->curr_stream_no = concurrent_event->stream_mapping[node];GGML_LOG_DEBUG("Setting stream no to %d for node %s\n", cuda_ctx->curr_stream_no, node->name); } }// 如果当前节点与上一个节点之间的距离大于 1,则检查当前节点是否与任何并发事件相关联,如果是,则启动该事件并设置适当的 CUDA 流等待关系elseif (i - prev_i > 1) { //the previous node was fusedconst ggml_tensor* prev_node = cgraph->nodes[i - 1]; // 获取上一个节点的指针try_launch_concurrent_event(prev_node); // 尝试启动与上一个节点相关的并发事件// 如果当前节点没有与任何并发事件相关联,则继续检查当前节点是否与任何并发事件相关联,如果是,则启动该事件并设置适当的 CUDA 流等待关系if (is_concurrent_event_active) { cuda_ctx->curr_stream_no = concurrent_event->stream_mapping[node];GGML_LOG_DEBUG("Setting stream no to %d for node %s\n", cuda_ctx->curr_stream_no, node->name); } }#ifdef GGML_CUDA_DEBUGconstint nodes_fused = i - prev_i - 1;if (nodes_fused > 0) {GGML_LOG_INFO("nodes_fused: %d\n", nodes_fused); }#endif prev_i = i; // 更新上一个节点的索引为当前节点的索引,以便在下一次迭代中检查节点之间的距离// 如果当前节点是一个计算节点,并且它的操作不是重塑、转置、视图、置换或无操作,并且它具有计算标志,则继续检查是否可以将其与后续节点融合,以优化执行if (ggml_is_empty(node) || node->op == GGML_OP_RESHAPE || node->op == GGML_OP_TRANSPOSE || node->op == GGML_OP_VIEW || node->op == GGML_OP_PERMUTE || node->op == GGML_OP_NONE) {continue; }// 如果当前节点没有计算标志,则跳过该节点,因为它不执行任何计算,不需要优化if ((node->flags & GGML_TENSOR_FLAG_COMPUTE) == 0) {continue; }// start of fusion operations// 融合操作的开始staticbool disable_fusion = (getenv("GGML_CUDA_DISABLE_FUSION") != nullptr); // 如果环境变量 "GGML_CUDA_DISABLE_FUSION" 被设置,则禁用融合操作,以便在调试或测试时更容易观察每个节点的行为if (!disable_fusion) {// 定义一个结构体变量,用于存储与 top-k MoE 融合相关的参数,这些参数将用于检查是否可以将当前节点与后续节点融合,以及在执行融合操作时提供必要的信息 ggml_cuda_topk_moe_args args; // 如果当前节点的操作是 UNARY、SOFT_MAX 或 ARGSORT,则继续检查是否可以将其与后续节点融合为一个 top-k MoE 操作,以优化执行if (cgraph->nodes[i]->op == GGML_OP_UNARY || cgraph->nodes[i]->op == GGML_OP_SOFT_MAX || cgraph->nodes[i]->op == GGML_OP_ARGSORT) {// 检查当前节点是否可以与后续节点融合为一个 top-k MoE 操作,如果可以,则执行融合操作,并跳过已经融合的节点,以避免重复执行constbool can_fuse = ggml_cuda_topk_moe_fusion(cgraph, i, args);// 定义一个向量变量,用于存储与 top-k MoE 融合相关的操作序列,这些操作将用于检查是否可以将当前节点与后续节点融合,以及在执行融合操作时提供必要的信息 std::vector<ggml_op> ops;// 如果可以融合,则根据融合参数构建操作序列,并检查当前节点与后续节点是否匹配该操作序列,如果匹配,则执行融合操作,并跳过已经融合的节点,以避免重复执行if (can_fuse) {const ggml_tensor * logits = node->src[0]; ggml_tensor * weights = nullptr; ggml_tensor * ids = nullptr;const ggml_tensor * bias = nullptr;const ggml_tensor * clamp = nullptr;const ggml_tensor * scale = nullptr;// 如果没有延迟的 softmax,则构建一个包含 gating_op、RESHAPE、ADD(如果有概率偏置)、ARGSORT、VIEW 和 GET_ROWS(如果没有概率偏置)的操作序列,以检查是否可以将当前节点与后续节点融合为一个 top-k MoE 操作if (!args.delayed_softmax) { ggml_op gating_op = args.sigmoid ? GGML_OP_UNARY : GGML_OP_SOFT_MAX;int out_nodes[2]; // nodes which can't be elided// 如果有概率偏置,则在操作序列中添加一个 ADD 操作,并将 bias 设置为该 ADD 操作的第二个输入,否则直接将 bias 设置为 nullptrif (args.prob_bias) { bias = cgraph->nodes[i + 2]->src[1]; ops.insert(ops.end(), { gating_op, GGML_OP_RESHAPE, GGML_OP_ADD, GGML_OP_ARGSORT, GGML_OP_VIEW, GGML_OP_GET_ROWS }); out_nodes[0] = i + 4; ids = cgraph->nodes[i + 4]; } else { ops.insert(ops.end(), { gating_op, GGML_OP_RESHAPE, GGML_OP_ARGSORT, GGML_OP_VIEW, GGML_OP_GET_ROWS }); out_nodes[0] = i + 3; ids = cgraph->nodes[i + 3]; }// 如果有规范化,则在操作序列中添加一个 RESHAPE、SUM_ROWS、CLAMP、DIV 和 RESHAPE 操作,并将 clamp 设置为该 CLAMP 操作的输出,否则直接将 clamp 设置为 nullptrif (args.norm) { ops.insert(ops.end(), { GGML_OP_RESHAPE, GGML_OP_SUM_ROWS, GGML_OP_CLAMP, GGML_OP_DIV, GGML_OP_RESHAPE }); clamp = cgraph->nodes[i + ops.size() - 3]; }// 如果有缩放,则在操作序列中添加一个 SCALE 操作,并将 scale 设置为该 SCALE 操作的输出,否则直接将 scale 设置为 nullptrif (args.scale) { ops.insert(ops.end(), { GGML_OP_SCALE }); scale = cgraph->nodes[i + ops.size() - 1]; } weights = cgraph->nodes[i + ops.size() - 1]; out_nodes[1] = i + ops.size() - 1;// 检查当前节点与后续节点是否匹配构建的操作序列,并且检查是否应该使用 top-k MoE 融合,如果是,则执行融合操作,并跳过已经融合的节点,以避免重复执行if (ggml_can_fuse_subgraph(cgraph, i, ops.size(), ops.data(), out_nodes, 2) &&ggml_cuda_should_use_topk_moe(node, logits, weights, ids)) {ggml_cuda_op_topk_moe(*cuda_ctx, logits, weights, ids, clamp, scale, bias, args); i += ops.size() - 1;continue; } }// 如果有延迟的 softmax,但没有规范化和概率偏置,则构建一个包含 ARGSORT、VIEW、GET_ROWS、RESHAPE、SOFT_MAX 和 RESHAPE 的操作序列,以检查是否可以将当前节点与后续节点融合为一个 top-k MoE 操作elseif (!args.norm && !args.prob_bias) {//special case gpt-oss, no norm, no bias. ops.insert(ops.end(), { GGML_OP_ARGSORT, GGML_OP_VIEW, GGML_OP_GET_ROWS, GGML_OP_RESHAPE, GGML_OP_SOFT_MAX, GGML_OP_RESHAPE }); weights = cgraph->nodes[i + 5]; ids = cgraph->nodes[i + 1];const ggml_tensor * softmax = cgraph->nodes[i + 4];int out_nodes[2] = { i + 1, i + 5 };if (ggml_can_fuse_subgraph(cgraph, i, ops.size(), ops.data(), out_nodes, 2) &&ggml_cuda_should_use_topk_moe(softmax, logits, weights, ids)) {ggml_cuda_op_topk_moe(*cuda_ctx, logits, weights, ids, clamp, scale, bias, args); i += ops.size() - 1;continue; } } } }// 如果当前节点的操作不是 top-k MoE 融合操作,并且它的操作是 ROPE,则继续检查是否可以将其与后续节点融合为一个 ROPE + SET_ROWS 操作,以优化执行if (ggml_cuda_can_fuse(cgraph, i, { GGML_OP_ROPE, GGML_OP_VIEW, GGML_OP_SET_ROWS }, {})) { ggml_tensor * rope = cgraph->nodes[i]; ggml_tensor * set_rows = cgraph->nodes[i + 2];ggml_cuda_op_rope_fused(*cuda_ctx, rope, set_rows); i += 2;continue; }// 如果当前节点的操作不是 top-k MoE 融合操作,也不是 ROPE + SET_ROWS 融合操作,并且它的操作是 ADD,则继续检查是否可以将其与后续节点融合为一个融合多个 ADD 操作的节点,以优化执行if (node->op == GGML_OP_ADD) {int n_fuse = 0; ggml_op ops[8]; std::fill(ops, ops + 8, GGML_OP_ADD);// 检查当前节点与后续节点是否可以融合为一个融合多个 ADD 操作的节点,如果可以,则执行融合操作,并跳过已经融合的节点,以避免重复执行for (; n_fuse <= 6; ++n_fuse){if (!ggml_can_fuse(cgraph, i + n_fuse, ops + n_fuse, 2)) {break; }if (cgraph->nodes[i + n_fuse] != cgraph->nodes[i + n_fuse + 1]->src[0]) {break; }if (!ggml_are_same_layout(cgraph->nodes[i + n_fuse]->src[1], cgraph->nodes[i + n_fuse + 1]->src[1])) {break; } } n_fuse++;// 如果可以融合的 ADD 操作数量大于 1,则执行融合操作,并跳过已经融合的节点,以避免重复执行if (n_fuse > 1) { ggml_tensor fused_add_node;memcpy(&fused_add_node, node, sizeof(ggml_tensor));for (int j = 0; j < n_fuse - 1; ++j) { fused_add_node.src[j + 2] = cgraph->nodes[i + j + 1]->src[1]; } fused_add_node.data = cgraph->nodes[i + n_fuse - 1]->data;ggml_cuda_op_fused_add(*cuda_ctx, &fused_add_node, n_fuse); i += n_fuse - 1;continue; } }// 如果当前节点的操作不是 top-k MoE 融合操作,也不是 ROPE + SET_ROWS 融合操作,也不是多个 ADD 操作的融合,并且它的操作是 MUL_MAT 或 MUL_MAT_ID,则继续检查是否可以将其与后续节点融合为一个融合了矩阵乘法、偏置和 GLU 的节点,以优化执行bool fused_mul_mat_vec = false; int fused_node_count = 0;// 检查当前节点与后续节点是否可以融合为一个融合了矩阵乘法、偏置和 GLU 的节点,如果可以,则执行融合操作,并跳过已经融合的节点,以避免重复执行for (ggml_op op : { GGML_OP_MUL_MAT, GGML_OP_MUL_MAT_ID }) {const ggml_op bias_op = op == GGML_OP_MUL_MAT ? GGML_OP_ADD : GGML_OP_ADD_ID;// 检查当前节点与后续节点是否匹配一个包含矩阵乘法、偏置和 GLU 的操作序列,如果匹配,则执行融合操作,并跳过已经融合的节点,以避免重复执行if (ggml_cuda_can_fuse(cgraph, i, { op, bias_op, op, bias_op, GGML_OP_GLU }, {})) {/* 在大模型(尤其是 Transformer 的 MLP / FFN)里,glu、gate、up 通常指这三类投影: • up:把隐藏维度升高的线性层(例如从 d_model->d_ff)。 • gate:门控分支的线性层,经过激活函数(如 SiLU)后用于“控制”信息通过多少。 • glu:Gated Linear Unit(门控线性单元)这一类结构的统称,常见形式是 output = activation(gate(x)) * up(x),再接一个 down 投影回原维度。 */ ggml_tensor* glu = cgraph->nodes[i + 4]; // 获取 GLU 节点的指针,该节点应该是当前节点和后续节点融合后的结果 ggml_tensor* gate_bias_n = glu->src[0]; // 获取 gate 偏置节点的指针,该节点应该是 GLU 节点的第一个源节点 ggml_tensor* up_bias_n = glu->src[1]; // 获取 up 偏置节点的指针,该节点应该是 GLU 节点的第二个源节点//we don't assume the order for {gate, up}. Instead infer it from the bias tensor// gate 和 up 的顺序不确定,而是从偏置张量中推断出来的。// 根据 gate_bias_n 的源节点来确定 gate_n 和 up_n 的位置,如果 gate_bias_n 的源节点之一是当前节点或当前节点 + 2,则将其作为 gate_n,并将另一个节点作为 up_n;如果都不是,则继续检查下一个操作序列 ggml_tensor * gate_n = nullptr; ggml_tensor * up_n = nullptr;if (gate_bias_n->src[0] == cgraph->nodes[i] || gate_bias_n->src[1] == cgraph->nodes[i]) { gate_n = cgraph->nodes[i]; up_n = cgraph->nodes[i + 2]; } elseif (gate_bias_n->src[0] == cgraph->nodes[i + 2] || gate_bias_n->src[1] == cgraph->nodes[i + 2]) { gate_n = cgraph->nodes[i + 2]; up_n = cgraph->nodes[i]; } else {continue; }// Lambda 函数用于从偏置节点中获取与矩阵乘法节点相关的偏置张量,如果偏置节点的操作是 ADD,则检查两个源节点中哪个是矩阵乘法节点,并返回另一个源节点作为偏置张量;如果偏置节点的操作是 ADD_ID,则直接返回第二个源节点作为偏置张量auto get_bias_tensor = [](const ggml_tensor * bias_node, const ggml_tensor * mul_node, ggml_op op_bias) {if (op_bias == GGML_OP_ADD) {if (bias_node->src[0] == mul_node) {return bias_node->src[1]; }if (bias_node->src[1] == mul_node) {return bias_node->src[0]; }return (ggml_tensor *) nullptr; }GGML_ASSERT(op_bias == GGML_OP_ADD_ID);GGML_ASSERT(bias_node->src[0] == mul_node);return bias_node->src[1]; };// gate 和 up 的偏置节点应该是 GLU 的源节点,如果它们的操作分别是 ADD 或 ADD_ID,则从中获取与矩阵乘法节点相关的偏置张量,以便在执行融合操作时使用 ggml_tensor * up_bias_tensor = get_bias_tensor(up_bias_n, up_n, bias_op); ggml_tensor * gate_bias_tensor = get_bias_tensor(gate_bias_n, gate_n, bias_op);if (!up_bias_tensor || !gate_bias_tensor) {continue; }// we don't support repeating adds// 我们不支持重复的加法if (bias_op == GGML_OP_ADD && (!ggml_are_same_shape(gate_bias_n->src[0], gate_bias_n->src[1]) || !ggml_are_same_shape(up_bias_n->src[0], up_bias_n->src[1]))) {continue; }const ggml_tensor * src0 = up_n->src[0];const ggml_tensor * src1 = up_n->src[1];const ggml_tensor * ids = up_n->src[2];// 根据 up_n 的源节点来确定 src0、src1 和 ids 的位置,如果 up_n 的源节点的第一个源节点是当前节点或当前节点 + 2,则将其作为 src0,并将另一个源节点作为 src1;如果 up_n 的源节点的第二个源节点是当前节点或当前节点 + 2,则将其作为 src1,并将另一个源节点作为 src0;如果都不是,则继续检查下一个操作序列if (ggml_cuda_should_fuse_mul_mat_vec_f(up_n)) { ggml_cuda_mm_fusion_args_host fusion_data{}; fusion_data.gate = gate_n->src[0]; fusion_data.x_bias = up_bias_tensor; fusion_data.gate_bias = gate_bias_tensor; fusion_data.glu_op = ggml_get_glu_op(glu);ggml_cuda_mul_mat_vec_f(*cuda_ctx, src0, src1, ids, glu, &fusion_data); fused_mul_mat_vec = true; fused_node_count = 5;break; }// 如果 up_n 的源节点与当前节点或当前节点 + 2 匹配,并且 up_n 满足融合矩阵乘法、偏置和 GLU 的条件,则执行融合操作,并跳过已经融合的节点,以避免重复执行if (ggml_cuda_should_fuse_mul_mat_vec_q(up_n)) { ggml_cuda_mm_fusion_args_host fusion_data{}; fusion_data.gate = gate_n->src[0]; fusion_data.x_bias = up_bias_tensor; fusion_data.gate_bias = gate_bias_tensor; fusion_data.glu_op = ggml_get_glu_op(glu);ggml_cuda_mul_mat_vec_q(*cuda_ctx, src0, src1, ids, glu, &fusion_data); fused_mul_mat_vec = true; fused_node_count = 5;break; } }// 如果当前节点与后续节点匹配一个包含矩阵乘法、偏置和 GLU 的操作序列,但不满足融合矩阵乘法、偏置和 GLU 的条件,则继续检查下一个操作序列elseif (ggml_cuda_can_fuse(cgraph, i, { op, op, GGML_OP_GLU }, {})) {// 在大模型(尤其是 Transformer 的 MLP / FFN)里,glu、gate、up 通常指这三类投影: ggml_tensor * glu = cgraph->nodes[i + 2]; ggml_tensor * gate = glu->src[0]; ggml_tensor * up = glu->src[1];bool ok = (gate == cgraph->nodes[i] && up == cgraph->nodes[i + 1]) || (gate == cgraph->nodes[i + 1] && up == cgraph->nodes[i]);if (!ok) continue;// 根据 up 的源节点来确定 src0、src1 和 ids 的位置,如果 up 的源节点的第一个源节点是当前节点或当前节点 + 1,则将其作为 src0,并将另一个源节点作为 src1;如果 up 的源节点的第二个源节点是当前节点或当前节点 + 1,则将其作为 src1,并将另一个源节点作为 src0;如果都不是,则继续检查下一个操作序列const ggml_tensor * src0 = up->src[0];const ggml_tensor * src1 = up->src[1];const ggml_tensor * ids = up->src[2];// 如果 up 的源节点与当前节点或当前节点 + 1 匹配,并且 up 满足融合矩阵乘法、偏置和 GLU 的条件,则执行融合操作,并跳过已经融合的节点,以避免重复执行if (ggml_cuda_should_fuse_mul_mat_vec_f(up)) { ggml_cuda_mm_fusion_args_host fusion_data{}; fusion_data.gate = gate->src[0]; fusion_data.glu_op = ggml_get_glu_op(glu);ggml_cuda_mul_mat_vec_f(*cuda_ctx, src0, src1, ids, glu, &fusion_data); fused_mul_mat_vec = true; fused_node_count = 3;break; }// 如果 up 的源节点与当前节点或当前节点 + 1 匹配,并且 up 满足融合矩阵乘法、偏置和 GLU 的条件,则执行融合操作,并跳过已经融合的节点,以避免重复执行if (ggml_cuda_should_fuse_mul_mat_vec_q(up)) { ggml_cuda_mm_fusion_args_host fusion_data{}; fusion_data.gate = gate->src[0]; fusion_data.glu_op = ggml_get_glu_op(glu);ggml_cuda_mul_mat_vec_q(*cuda_ctx, src0, src1, ids, glu, &fusion_data); fused_mul_mat_vec = true; fused_node_count = 3;break; } } }// 如果当前节点的操作不是 top-k MoE 融合操作,也不是 ROPE + SET_ROWS 融合操作,也不是多个 ADD 操作的融合,并且它的操作是 MUL_MAT 或 MUL_MAT_ID,并且满足融合矩阵乘法、偏置和 GLU 的条件,则执行融合操作,并跳过已经融合的节点,以避免重复执行if (fused_mul_mat_vec) { i += fused_node_count - 1;continue; } fused_mul_mat_vec = false; // 重置融合标志和计数器,以便在下一次检查融合条件时使用 fused_node_count = 0; // 检查当前节点与后续节点是否匹配一个包含矩阵乘法、偏置和 GLU 的操作序列,如果匹配,但不满足融合矩阵乘法、偏置和 GLU 的条件,则继续检查下一个操作序列for (ggml_op op : { GGML_OP_MUL_MAT, GGML_OP_MUL_MAT_ID }) {const ggml_op bias_op = op == GGML_OP_MUL_MAT ? GGML_OP_ADD : GGML_OP_ADD_ID;if (!ggml_can_fuse(cgraph, i, { op, bias_op })) {continue; }// 如果当前节点与后续节点匹配一个包含矩阵乘法和偏置的操作序列,但不满足融合矩阵乘法、偏置和 GLU 的条件,则继续检查下一个操作序列 ggml_tensor* mm_node = cgraph->nodes[i]; // 获取矩阵乘法节点的指针,该节点应该是当前节点 ggml_tensor* bias_node = cgraph->nodes[i + 1]; // 获取偏置节点的指针,该节点应该是当前节点的下一个节点 ggml_tensor * bias_tensor = nullptr;// 根据偏置节点的操作来确定与矩阵乘法节点相关的偏置张量,如果偏置节点的操作是 ADD,则检查两个源节点中哪个是矩阵乘法节点,并返回另一个源节点作为偏置张量;如果偏置节点的操作是 ADD_ID,则直接返回第二个源节点作为偏置张量;如果都不是,则继续检查下一个操作序列if (bias_op == GGML_OP_ADD) {if (bias_node->src[0] == mm_node) { bias_tensor = bias_node->src[1]; } elseif (bias_node->src[1] == mm_node) { bias_tensor = bias_node->src[0]; } else {continue; } } else {if (bias_node->src[0] != mm_node) {continue; } bias_tensor = bias_node->src[1]; }// 根据矩阵乘法节点的源节点来确定 src0、src1 和 ids 的位置,如果矩阵乘法节点的源节点的第一个源节点是当前节点或当前节点 + 1,则将其作为 src0,并将另一个源节点作为 src1;如果矩阵乘法节点的源节点的第二个源节点是当前节点或当前节点 + 1,则将其作为 src1,并将另一个源节点作为 src0;如果都不是,则继续检查下一个操作序列const ggml_tensor * src0 = mm_node->src[0];const ggml_tensor * src1 = mm_node->src[1];const ggml_tensor * ids = mm_node->src[2];// 如果矩阵乘法节点的源节点与当前节点或当前节点 + 1 匹配,并且偏置节点满足融合矩阵乘法、偏置和 GLU 的条件,则执行融合操作,并跳过已经融合的节点,以避免重复执行if (bias_op == GGML_OP_ADD_ID && bias_node->src[2] != ids) {continue; }// 如果偏置节点的操作是 ADD,并且两个源节点的形状不相同,则继续检查下一个操作序列,因为我们不支持重复的加法if (bias_op == GGML_OP_ADD && !ggml_are_same_shape(bias_node->src[0], bias_node->src[1])) {continue; }// 如果矩阵乘法节点的源节点与当前节点或当前节点 + 1 匹配,并且偏置节点满足融合矩阵乘法、偏置和 GLU 的条件,则执行融合操作,并跳过已经融合的节点,以避免重复执行 ggml_cuda_mm_fusion_args_host fusion_data{}; fusion_data.x_bias = bias_tensor;// 根据矩阵乘法节点的源节点来确定 gate_n 的位置,如果 gate_bias_tensor 的源节点之一是当前节点或当前节点 + 1,则将其作为 gate_n 的源节点,并将另一个源节点作为 gate_n;如果都不是,则继续检查下一个操作序列if (ggml_cuda_should_fuse_mul_mat_vec_f(mm_node)) {ggml_cuda_mul_mat_vec_f(*cuda_ctx, src0, src1, ids, bias_node, &fusion_data); fused_mul_mat_vec = true; fused_node_count = 2;break; }// 如果矩阵乘法节点的源节点与当前节点或当前节点 + 1 匹配,并且偏置节点满足融合矩阵乘法、偏置和 GLU 的条件,则执行融合操作,并跳过已经融合的节点,以避免重复执行if (ggml_cuda_should_fuse_mul_mat_vec_q(mm_node)) {ggml_cuda_mul_mat_vec_q(*cuda_ctx, src0, src1, ids, bias_node, &fusion_data); fused_mul_mat_vec = true; fused_node_count = 2;break; } }// 如果当前节点的操作不是 top-k MoE 融合操作,也不是 ROPE + SET_ROWS 融合操作,也不是多个 ADD 操作的融合,并且它的操作是 MUL_MAT 或 MUL_MAT_ID,并且满足融合矩阵乘法、偏置和 GLU 的条件,则执行融合操作,并跳过已经融合的节点,以避免重复执行if (fused_mul_mat_vec) { i += fused_node_count - 1;continue; }// 如果当前节点的操作不是 top-k MoE 融合操作,也不是 ROPE + SET_ROWS 融合操作,也不是多个 ADD 操作的融合,也不是融合矩阵乘法、偏置和 GLU 的操作,并且它的操作是 RMS_NORM,则继续检查是否可以将其与后续节点融合为一个融合了 RMS_NORM、乘法和加法的节点,以优化执行if (ggml_cuda_can_fuse(cgraph, i, { GGML_OP_RMS_NORM, GGML_OP_MUL, GGML_OP_ADD}, {})) {ggml_cuda_op_rms_norm_fused_add(*cuda_ctx, node, cgraph->nodes[i+1], cgraph->nodes[i+2]); i += 2;continue; }// 如果当前节点的操作不是 top-k MoE 融合操作,也不是 ROPE + SET_ROWS 融合操作,也不是多个 ADD 操作的融合,也不是融合矩阵乘法、偏置和 GLU 的操作,并且它的操作是 RMS_NORM,则继续检查是否可以将其与后续节点融合为一个融合了 RMS_NORM 和乘法的节点,以优化执行if (ggml_cuda_can_fuse(cgraph, i, { GGML_OP_RMS_NORM, GGML_OP_MUL}, {})) {ggml_cuda_op_rms_norm_fused(*cuda_ctx, node, cgraph->nodes[i+1]); i++;continue; }// 如果当前节点的操作不是 top-k MoE 融合操作,也不是 ROPE + SET_ROWS 融合操作,也不是多个 ADD 操作的融合,也不是融合矩阵乘法、偏置和 GLU 的操作,也不是融合 RMS_NORM、乘法和加法 的操作,并且它的操作是 TANH,则继续检查是否可以将其与后续节点融合为一个融合了 TANH 和乘法的节点,以优化执行if (ggml_cuda_can_fuse(cgraph, i, { GGML_OP_SCALE, GGML_OP_UNARY, GGML_OP_SCALE }, { GGML_UNARY_OP_TANH })) { i += 2;ggml_cuda_op_softcap(*cuda_ctx, cgraph->nodes[i], node);continue; } }#ifndef NDEBUGassert(node->buffer->buft == ggml_backend_cuda_buffer_type(cuda_ctx->device));for (int j = 0; j < GGML_MAX_SRC; j++) {if (node->src[j] != nullptr) {assert(node->src[j]->buffer);assert(node->src[j]->buffer->buft == ggml_backend_cuda_buffer_type(cuda_ctx->device) ||ggml_backend_buft_is_cuda_split(node->src[j]->buffer->buft) || (integrated && ggml_backend_buft_is_cuda_host(node->src[j]->buffer->buft))); } }#elseGGML_UNUSED(integrated);#endif// NDEBUG// 对当前节点执行 CUDA 计算,如果执行失败,则记录错误日志并断言失败,以便在开发和调试阶段及时发现和修复问题bool ok = ggml_cuda_compute_forward(*cuda_ctx, node);if (!ok) {GGML_LOG_ERROR("%s: op not supported %s (%s)\n", __func__, node->name, ggml_op_name(node->op)); }GGML_ASSERT(ok);// 尝试启动并发事件if (!is_concurrent_event_active) {try_launch_concurrent_event(node); } } }// 如果启用了 CUDA 图并且需要更新 CUDA 图的可执行实例,则结束 CUDA 图捕获,并根据捕获的 CUDA 图创建或更新 CUDA 图的可执行实例,然后启动 CUDA 图进行执行;如果没有启用 CUDA 图,则直接执行计算图中的节点#ifdef USE_CUDA_GRAPH// 获取当前计算图对应的 CUDA 图实例,如果需要更新 CUDA 图的可执行实例,则结束 CUDA 图捕获,并根据捕获的 CUDA 图创建或更新 CUDA 图的可执行实例,然后启动 CUDA 图进行执行;如果没有启用 CUDA 图,则直接执行计算图中的节点 ggml_cuda_graph * graph = cuda_ctx->cuda_graph(graph_key);if (use_cuda_graph && cuda_graph_update_required) { // End CUDA graph capture// 如果 CUDA 图已经存在,则销毁它,以便在结束捕获后创建一个新的 CUDA 图实例if (graph->graph != nullptr) {CUDA_CHECK(cudaGraphDestroy(graph->graph)); graph->graph = nullptr; }CUDA_CHECK(cudaStreamEndCapture(cuda_ctx->stream(), &graph->graph));// 标记 CUDA 图已经被捕获,以便在后续执行时使用捕获的 CUDA 图进行优化执行 graph_evaluated_or_captured = true; // CUDA graph has been captured// 使用互斥锁保护 CUDA 图捕获的计数器,确保在多线程环境下正确管理 CUDA 图的捕获状态,如果当前线程是最后一个正在捕获 CUDA 图的线程,则通知所有等待 CUDA 图捕获完成的线程,以便它们可以继续执行std::lock_guard<std::mutex> lock(ggml_cuda_lock);if (ggml_cuda_lock_counter.fetch_sub(1, std::memory_order_relaxed) == 1) { ggml_cuda_lock_cv.notify_all(); } } else {// 如果没有启用 CUDA 图或者不需要更新 CUDA 图的可执行实例,则直接执行计算图中的节点,并标记计算图已经被评估或捕获,以便在后续执行时使用评估或捕获的结果进行优化执行 graph_evaluated_or_captured = true; // ggml graph has been directly evaluated } }// 如果启用了 CUDA 图并且需要更新 CUDA 图的可执行实例,则结束 CUDA 图捕获,并根据捕获的 CUDA 图创建或更新 CUDA 图的可执行实例,然后启动 CUDA 图进行执行;如果没有启用 CUDA 图,则直接执行计算图中的节点if (use_cuda_graph) { ggml_cuda_graph * graph = cuda_ctx->cuda_graph(graph_key);if (graph->instance == nullptr) { // Create executable graph from captured graph.CUDA_CHECK(cudaGraphInstantiate(&graph->instance, graph->graph, NULL, NULL, 0)); }if (cuda_graph_update_required) { // Update graph executableggml_cuda_graph_update_executable(cuda_ctx, graph_key); }// Launch graphCUDA_CHECK(cudaGraphLaunch(graph->instance, cuda_ctx->stream()));#else// 如果没有启用 CUDA 图或者不需要更新 CUDA 图的可执行实例,则直接执行计算图中的节点,并标记计算图已经被评估或捕获,以便在后续执行时使用评估或捕获的结果进行优化执行GGML_UNUSED(graph_key); graph_evaluated_or_captured = true;#endif// USE_CUDA_GRAPH }}相对 Cpu 而言,Cuda 部分的代码就复杂多了!
这里涉及一个 CUDA Graph 一个概念,我也不确定 CUDA Graph 算不算一个概念,还是一个具体的、可编程的 CUDA 特性。它不是一个停留在理论层面的抽象概念,而是有完整 API 支持的实用工具。
在下面我会着重讲解 CUDA Graph,现在要的是对 Transformer / LLM 常见模块有所了解:
• Attention (注意力机制)缩放点积注意力:多头注意力:其中每个头为:在自回归生成时,Query 是当前新 Token,Key 和 Value 是包含所有历史 Token 的缓存(KV Cache)。 模块 算子 操作 对应关系解读 Attention ROPE旋转位置编码 (RoPE) 完全对应。这是一个为 Q、K 施加旋转变换的专用融合算子。 VIEW/RESHAPEConcat(..., head_i)及 QKV 投影 对 Tensor 进行形状重排,零计算开销,只改变元数据。是多头注意力拼接和拆分的必经步骤。 SET_ROWSKV Cache 更新 这就是我们在聊 Graph 实现要点时强调的“原地更新”KV Cache 的操作,将新 K、V 写入预分配张量的指定行。 • FFN / MLP (前馈网络 / 多层感知机)标准 FFN(两层 MLP):常见激活函数 :ReLU, GELU 等。SwiGLU 变体(常用于 LLaMA 等模型):其中 , 为逐元素乘法。 模块 算子 操作 对应关系解读 FFN / MLP MUL_MAT(线性层) XW_1, XW_2等矩阵乘法完全对应。这就是最核心的矩阵乘法。 ADD(bias) + b_1, + b_2等偏置加法完全对应。通常与矩阵乘融合或在后面跟随一个单独加法 kernel。 GLUSwiGLU 变体中的 Swish(xW_1) ⊙ (xW_2)包含逐元素乘法和激活函数的融合操作。是高阶门控路径的具体实现。 mul_mat + bias + glu),这是大头计算路径。• MoE (混合专家模型)带 Top-K 稀疏门控的 MoE 层输出: 模块 算子 操作 对应关系解读 MoE SOFT_MAX/ UNARYG =softmax(xWg) SOFT_MAX是核心, UNARY(一元操作)可以指激活函数、类型转换等。ARGSORTTop-K 选择的前序或实现步骤 通过排序来获取 token 分数排序,是确定 token 路由去向的核心逻辑。 GET_ROWS数据分发 (Router) 根据 ARGSORT产生的索引,从输入张量中提取 token 给不同专家。TOPKTop-K 门控 直接选出分数最高的 K 个专家,是门控路由的关键。 走
topk_moe融合路径,减少路由阶段开销。• :门控网络,仅保留概率最大的 K 个专家,其余置零(或 −∞)。 • :被选中的专家索引集合 • :第 个专家网络 • Norm (归一化层)LayerNorm:其中 μ、σ2 为 x 在最后一个维度上的均值和方差,γ,β 为可学习的缩放和偏移参数。RMSNorm:通常不带偏移 β,d 为特征维度。 模块 算子 操作 对应关系解读 Norm RMS_NORM我们专门介绍的高效归一化算子 将规约(求平方均值)、逐元素运算(除均方根)和仿射(乘 γ)融合成一个算子。MUL/ADD仿射变换 * γ或+ β当未完全融合时,它们作为独立的逐元素操作存
当然 Transformer / LLM 常见模块不止这些,但这里只对代码中相关的模块做了一下讲解。
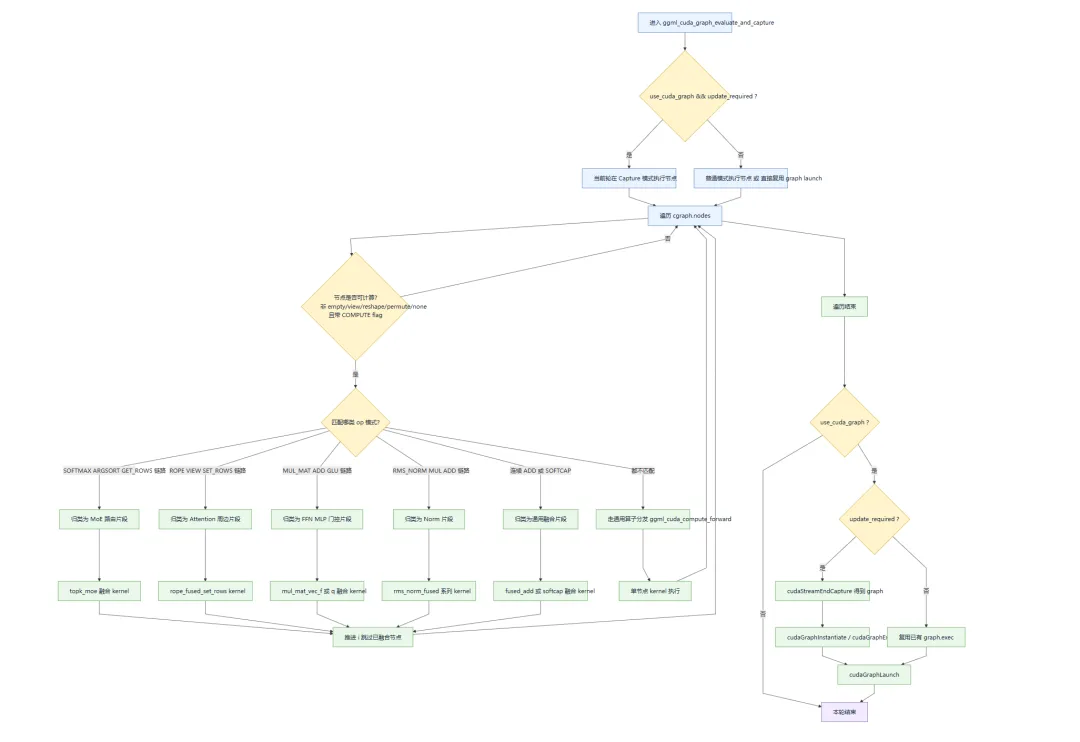
ggml_cuda_graph_evaluate_and_capture(...) 这个函数并不会直接识别 “这是 Attention 层/FFN 层/MoE 层” 的高层语义,而是通过 op 序列模式匹配 来推断可归类的计算片段,并执行对应融合。
因此导致该函数比较羞涩难懂,这里梳理决策关系图,便于更好的理解代码:
CUDA Graph 概述
课后小课堂,这里聊一聊 Cuda Graph。
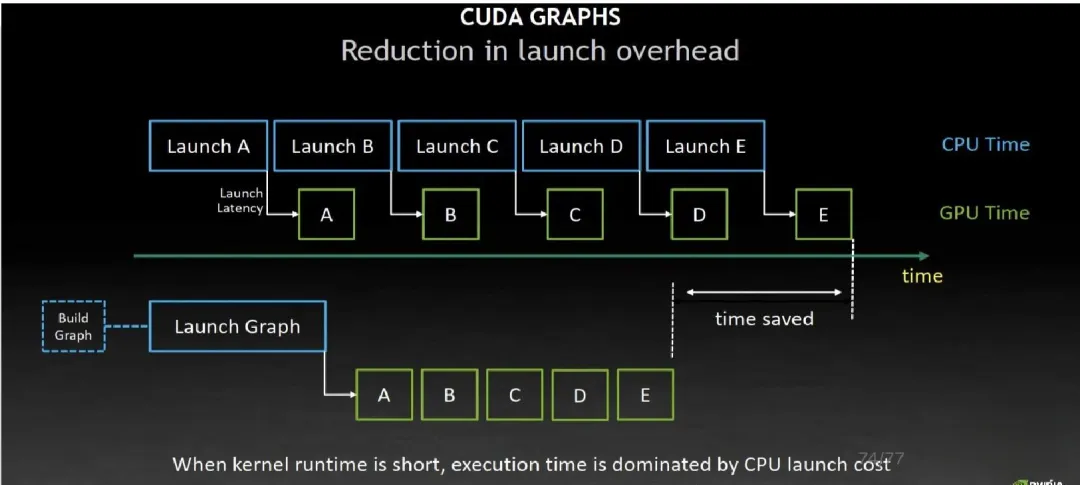
CUDA Graph 是 NVIDIA 从 CUDA 10 开始引入的一套 API,旨在用一次提交、批量执行的方式取代传统“一个一个 kernel 发射”的流式提交,从而大幅降低 CPU 端的调度开销。
它的核心思想可以概括为:将一系列 GPU 操作“录制”成一个静态执行图,之后只需“回放”这个图,就能让 GPU 一气呵成地完成所有工作。
Cuda Graph 核心工作流程
• 定义/录制:通过显式 API 逐个添加节点,或通过流捕获模式(Stream Capture)录制一整个 CUDA Stream 上的操作序列,形成一张有向无环图 (DAG)。 • 实例化:对图进行验证、优化,并生成一个可执行的“实例”,这个过程类似于编译,会产生针对当前设备的优化代码。 • 回放:只需一个调用( cudaGraphLaunch),即可将整个图提交到 GPU,后续所有操作按照图中定义的依赖顺序自动执行。• 更新:图实例支持部分参数(如指针)的原地更新,无需重新创建整个图。
使用 C++ API 实现 CUDA Graph 主要有两种路径:
• 一种是侧重于精细控制的显式 API (Explicit API) • 另一种是更简单直观的流捕获 API (Stream Capture API)
下面我们将通过完整的代码示例,来展示这两种方法,以及关键的编程技巧。
显式 API (Explicit API) 实现
这个方法赋予你对图的完全控制权,你可以一步步地创建图、添加节点、设定依赖。
以下是一个完整的示例,演示了如何通过显式 API 将两个内核(向量加法和减法)捕获到一个图中并执行。
#include<cuda_runtime.h>#include<iostream>#include<cassert>// 1. 定义CUDA核函数__global__ voidvecAdd(float *a, float *b, float *c, int n){int i = blockIdx.x * blockDim.x + threadIdx.x;if (i < n) c[i] = a[i] + b[i];}__global__ voidvecSub(float *a, float *b, float *c, int n){int i = blockIdx.x * blockDim.x + threadIdx.x;if (i < n) c[i] = a[i] - b[i];}// 2. 封装错误检查宏,便于调试#define CUDA_CHECK(call) \ do { \ cudaError_t err = call; \if (err != cudaSuccess) { \ std::cerr << "CUDA Error at " << __FILE__ << ":" << __LINE__ << " - " \ << cudaGetErrorString(err) << std::endl; \ exit(EXIT_FAILURE); \ } \ } while(0)intmain(){constint N = 1024;constsize_t bytes = N * sizeof(float);// 3. 分配和初始化设备内存float *d_a, *d_b, *d_c;CUDA_CHECK(cudaMalloc(&d_a, bytes));CUDA_CHECK(cudaMalloc(&d_b, bytes));CUDA_CHECK(cudaMalloc(&d_c, bytes));// 初始化数据 (此处省略,假设数据已通过cudaMemcpy拷贝到设备)// 4. 创建 CUDA Graph cudaGraph_t graph;CUDA_CHECK(cudaGraphCreate(&graph, 0));// 5. 定义节点参数 cudaKernelNodeParams addNodeParams = {0}; addNodeParams.func = (void*)vecAdd; addNodeParams.gridDim = dim3((N + 255) / 256); addNodeParams.blockDim = dim3(256); addNodeParams.sharedMemBytes = 0;void *addArgs[] = { &d_a, &d_b, &d_c, (void*)&N }; addNodeParams.kernelParams = addArgs; cudaKernelNodeParams subNodeParams = {0}; subNodeParams.func = (void*)vecSub; subNodeParams.gridDim = dim3((N + 255) / 256); subNodeParams.blockDim = dim3(256); subNodeParams.sharedMemBytes = 0;void *subArgs[] = { &d_a, &d_b, &d_c, (void*)&N }; subNodeParams.kernelParams = subArgs;// 6. 向图中添加节点,并建立依赖关系 cudaGraphNode_t addNode, subNode;CUDA_CHECK(cudaGraphAddKernelNode(&addNode, graph, nullptr, 0, &addNodeParams));// subNode 依赖于 addNode,确保执行顺序CUDA_CHECK(cudaGraphAddKernelNode(&subNode, graph, &addNode, 1, &subNodeParams));// 7. 实例化图 cudaGraphExec_t graphExec;CUDA_CHECK(cudaGraphInstantiate(&graphExec, graph, NULL, NULL, 0));// 8. 在CUDA流中启动图 cudaStream_t stream;CUDA_CHECK(cudaStreamCreate(&stream));CUDA_CHECK(cudaGraphLaunch(graphExec, stream));CUDA_CHECK(cudaStreamSynchronize(stream));// 9. 清理资源CUDA_CHECK(cudaGraphExecDestroy(graphExec));CUDA_CHECK(cudaGraphDestroy(graph));CUDA_CHECK(cudaStreamDestroy(stream));CUDA_CHECK(cudaFree(d_a));CUDA_CHECK(cudaFree(d_b));CUDA_CHECK(cudaFree(d_c)); std::cout << "CUDA Graph executed successfully!" << std::endl;return0;}参数传递的坑点在显式 API 中设置 kernelParams 时,必须传递指向GPU内存指针的指针。对于临时对象,应创建局部变量来存储地址,否则可能导致段错误。
流捕获 API (Stream Capture API) 实现
流捕获方法更为简洁,允许你像写常规CUDA代码一样操作,然后“录制”成图。
#include<cuda_runtime.h>#include<iostream>__global__ voidmyKernel(float *data, int n){int i = blockIdx.x * blockDim.x + threadIdx.x;if (i < n) data[i] *= 2.0f;}intmain(){constint N = 1024;constsize_t bytes = N * sizeof(float);float *d_data;cudaMalloc(&d_data, bytes); cudaStream_t stream;cudaStreamCreate(&stream); cudaGraph_t graph; cudaGraphExec_t instance;// 1. 开始流捕获cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);// 2. 在此之后的所有流操作都会被捕获// 这里可以像编写普通 CUDA 代码一样 myKernel<<<(N+255)/256, 256, 0, stream>>>(d_data, N);// 可以添加更多kernel、memcpy等操作...// 3. 结束捕获,生成图cudaStreamEndCapture(stream, &graph);// 4. 实例化图并启动cudaGraphInstantiate(&instance, graph, NULL, NULL, 0);cudaGraphLaunch(instance, stream);cudaStreamSynchronize(stream);// 5. 清理cudaGraphExecDestroy(instance);cudaGraphDestroy(graph);cudaStreamDestroy(stream);cudaFree(d_data);return0;}| 控制力 | 高 | 低 |
| 易用性 | 低 | 高 |
| 复杂性 | ||
| 适用场景 |
通常,对于多数应用场景,推荐从简单的流捕获 API 开始,当它无法满足你的定制需求时,再转向更灵活的显式 API。
图的动态更新:如果你的图只是部分参数(如输入数据指针)需要改变,无需重新录制整个图。可以使用 cudaGraphExecUpdate 来更新已实例化的图,这比重新创建和实例化图的性能开销更低。
总结一下 Cuda Graph 核心的 API:
cudaGraphCreate | |
cudaGraphAddKernelNode | |
cudaGraphAddMemcpyNode | |
cudaStreamBeginCapture | |
cudaStreamEndCapture | |
cudaGraphInstantiate | |
cudaGraphLaunch | |
cudaGraphExecUpdate | |
cudaGraphExecDestroy | |
cudaGraphDestroy |
至此使用示例讲述了 Cuda Graph 的简单使用,哦对了,根据代码可以看出 ggml-cuda.cu 中使用的是流捕获方式。收工~
