 夜雨聆风
夜雨聆风英伟达市值突破3万亿,AMD GPU增速翻倍……AI基础设施的叙事在过去三年几乎被芯片公司垄断。但思科 2026 财年第三财季财报给出了关键信号:面向超大规模云厂商与云构建商的 AI 相关订单达到19 亿美元;同时思科将本财年 AI 订单预期从 50 亿美元大幅上调至90 亿美元。
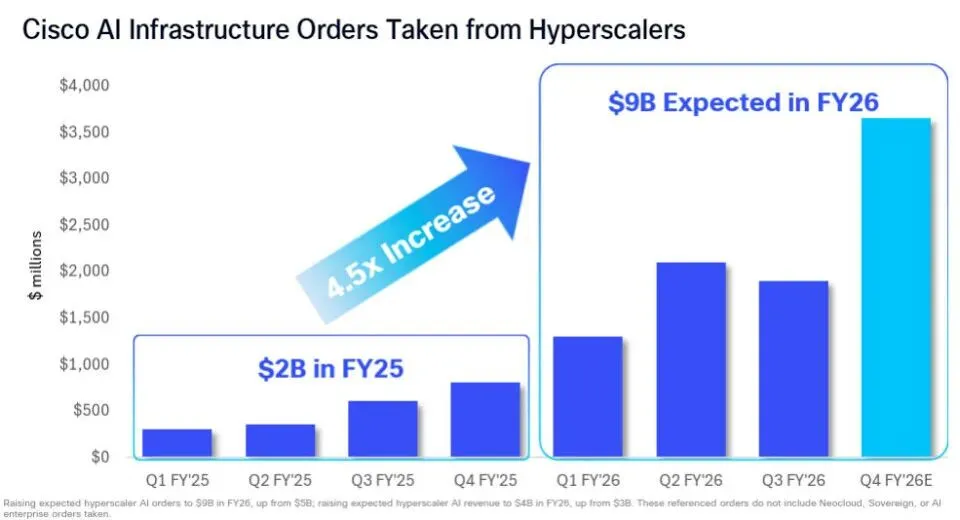
这件事背后真正有意思的地方,不只是思科赚了多少钱。而是AI基础设施这件事,开始慢慢从拼GPU,变成拼整个系统。卡还是最重要的。但光有卡,已经不够了。
先说清一个基本问题。思科的19亿AI订单,卖的到底是什么?主要由三类产品贡献。
Silicon One交换芯片。这是思科自研的芯片家族,当前最新的是G300 系列,102.4Tbps的聚合带宽,512个SerDes电路模块,252MB的统一共享数据包缓冲区,适配大规模 AI 训练集群。思科把它直接卖给云厂商,后者集成到自研设备里。这些公司现在越来越不愿意直接买标准交换机,而是倾向于自己设计网络架构、自定义交换机,再采购核心芯片自己集成。说白了,他们要的是网络CPU,不是整机。这也是Silicon One现在增长很快的原因。
Acacia光模块。思科在2021年收购了Acacia,主打400G/800G 相干光模块、数据中心互联(DCI),用于 AI 集群跨机柜、跨园区高速互联。相干光具备传输距离远、容量大、信号质量好的优势,是 AI 长距互联的核心方案。本财季光业务相关订单已突破 10 亿美元。
高端路由与 AI 集群配套方案。包括面向智算中心的高端路由器、AI POD 整柜交付、集群架构设计与集成,构成端到端 AI 智算网络解决方案。
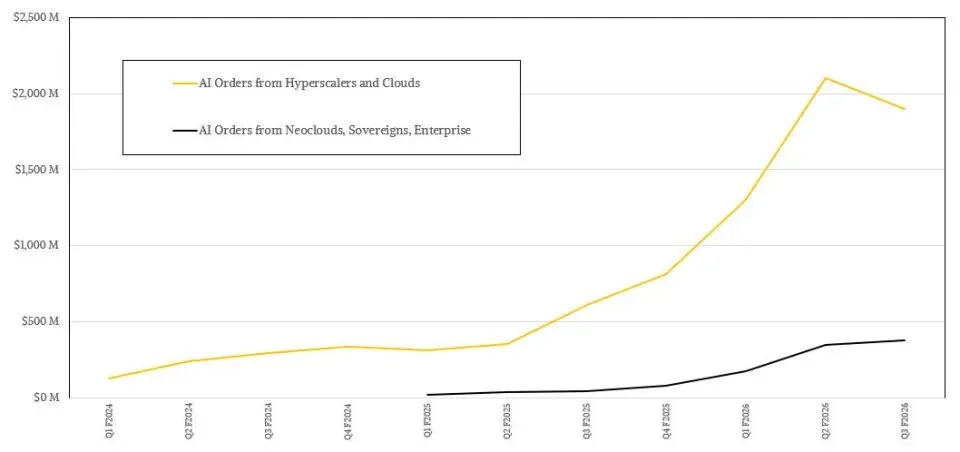
*补充说明:19 亿美元仅统计超大规模云厂商,Q3 企业与新兴云 AI 订单约 3 亿美元单独统计;企业数据中心交换机订单同比增长超 40%,说明 AI 需求正从云厂商向传统企业扩散。
理解思科在AI时代的战略,核心就一句话:同时做组件供应商和系统集成商。
两条路服务的是完全不同的客户。
Google、Microsoft、Amazon、Meta、字节、阿里这些超大规模云厂商有个共同特征:规模够大,自己有能力也有意愿做定制化网络设备。他们不想要思科的整机交换机,想要思科的芯片,然后自己设计、自己组装、自己优化。
这是Silicon One的市场。芯片毛利率远高于整机,轻松超过70%。对云厂商的好处也直接,摆脱对单一设备商的依赖,拥有更多定制空间。
但还有另一批客户。大多数企业级客户需要的是有人帮我搭好、拿来就能用的方案。他们没大厂那么庞大的技术团队,也没那么多工程师从零设计网络架构。Nexus+UCS的存在意义就是这个,提供从架构设计到硬件交付的完整服务。
企业数据中心交换机订单同比涨40%,恰恰印证了这个判断,AI正在从互联网公司的实验室,扩散到各行各业的实际场景中。
两条轨道看起来矛盾,但细想几乎不冲突。组件服务的是自研能力强的顶级云厂商,系统服务的是自研能力弱的传统客户。两个市场的技术诉求差别很大,覆盖的是完全不同的客户层级。
为什么光模块在这里值得单独拎出来说?
因为光模块是AI集群内部GPU到GPU互联的物理层基础。无论你用的是英伟达Blackwell还是AMD MI350X,无论交换芯片是博通的Tomahawk还是思科的Silicon One,只要GPU之间需要通信,就一定需要光模块把电信号转成光信号,通过光纤在服务器之间跑。
光模块的需求量与AI集群规模直接成正比。你部署的GPU越多,需要的光模块就越多,而且这个关系不是线性的,更多GPU意味着更复杂的互联拓扑和更多的长距离光连接。
Acacia 的核心价值在相干光通信。相干光的优势在于单波长速率高、传输距离远、信号质量好,是数据中心长距离连接的首选。Acacia解决的是AI集群里最难的那段连接,跨越机柜和行级的大容量互联。这部分市场技术门槛高,竞争格局相对清晰,Acacia的先发优势也最明显。
800G光模块目前的主流实现方式是将一个800G端口拆分使用,比如QSFP-DD800把800G拆为8×100G。另一种是跟CPO(共封装光学)结合,在交换机芯片附近直接实现光电共封装。前者是Acacia当前的主流量产方案,后者是公认的下一代方向。
思科同时铺了两条线。可插拔市场,Acacia的800G已经在批量出货;CPO领域,思科通过收购Applied Optoelectronics的资产在做下一代布局。
说完了思科,有必要停下来思考一个问题:为什么现在谈智算网络是合适的时机?我们可以注意到,有三个变化正在发生。
1.AI集群的规模正在突破传统网络的物理极限。
就在前几天,OpenAI、微软、博通、AMD、英伟达五方联合发布了MRC协议。目标很直接:把AI集群网络从三层Clos架构压成两层,最大计算节点从65,536扩展到131,072。
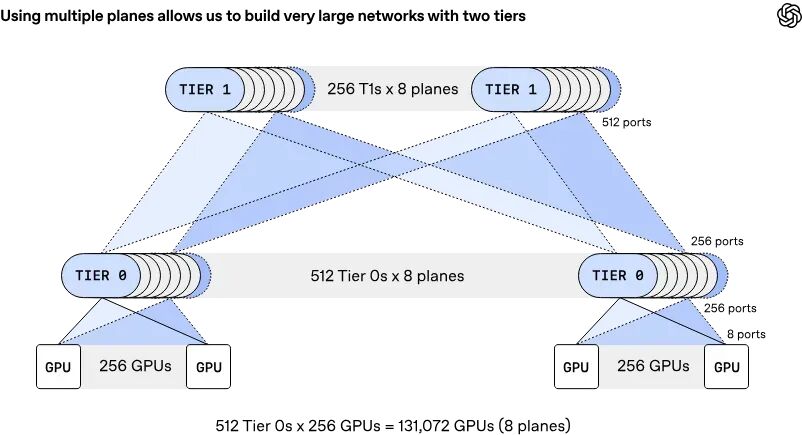
这不是小改动。三层架构面对百万级GPU集群时,扩展性、延迟和成本同时撞墙。131,072节点的上限,是为下一代百万级GPU集群准备的。
思科的AI业务爆发正是这个趋势的反面印证,超大规模客户已经在为下一代集群重新设计网络架构,而重新设计意味着新订单。
2.网络层的瓶颈从隐藏问题变成显性瓶颈。
过去十几年,数据中心网络的性能提升主要靠两个手段:加端口、提速率。从40G到100G再到400G、800G,每次升级都靠交换机芯片代际更新。网络架构本身没有本质变化。
但AI训练的工作负载改写了这个前提。AllReduce这类集合通信操作要求集群中所有GPU在某一时刻保持同步。网络抖动、拥塞、单链路故障,任何一个都可能导致整个训练任务重新开始,GPU空闲等待的每一秒都是纯浪费。
MRC协议把单链路故障只损失12%带宽作为核心设计目标,不是偶然。在传统Clos网络里,单链路故障可能导致拥塞扩散;在MRC架构中,故障被隔离在单个100G子通道内,对整体训练吞吐的影响大幅降低。AI训练对网络可靠性的要求,已经比通用数据中心高了一个数量级。
3.算力可以被量化,网络性能却很难被量化。
这个问题长期被忽视。GPU的算力可以用TFLOPs精确描述,但网络性能呢?用什么指标衡量一个AI集群的网络够不够用?目前行业没有标准答案。延迟、带宽、拥塞率、丢包率……每个指标只反映一个侧面,组合起来又缺乏统一的可比框架。这个测量难题,导致了网络层长期被低估,预算有限时,网络设备往往是第一个被砍的。
但随着AI训练成本公开化,这个认知也在变。一台H100服务器的价格是公开的,一次大规模训练的总电费是可以估算的,GPU空闲成本是可以算出来的。当这些数字摆到台前,网络能不能跟上这个问题的优先级,自然就上去了。
回到思科的财报数字,核心判断很简单:智算网络正在成为一个独立的投资方向,与GPU并列,不是GPU的附庸。
过去三年,AI基础设施的投资叙事几乎被GPU统治。英伟达财报一出,全世界都在分析Blackwell产能、GTC新芯片。这个叙事是合理的,没有GPU就没有模型。但它也是不完整的。
但只盯着GPU,很容易漏掉旁边的变化。光模块增速有多快?交换芯片为什么从通用走向AI定制化?MRC协议发布后意味着什么?
智算网络的逻辑与通用数据中心网络有本质差异。通用网络的核心诉求是够用就行和稳定可靠;智算网络的核心诉求是极致带宽、超低延迟、零故障容忍。目标函数不同,技术路线、产品规格和服务模式跟着也不同。
GPU赚走了聚光灯,网络赚走了钱。这种说法可能过于对立,但方向是对的。
智算网络补上了AI基础设施里那个长期被忽视的短板。GPU决定了一台车的马力,网络决定了马力能不能传到轮子上,这个比喻说烂了,但现实确实如此。
参考:
CISCO REPORTS THIRD QUARTER EARNINGS
Cisco Wins Over AI Customers With Merchant Silicon And Optics
Supercomputer networking to accelerate large scale AI training
