 夜雨聆风
夜雨聆风这是 Mem0 源码解析系列的第三篇。前两篇我们讲了“记忆如何被写入”和“Mem0 如何用提示词管理记忆”。这一篇换个角度:当用户再次提问时,Mem0 到底怎样从一堆历史记忆里,把真正有用的内容找回来?
一、为什么“检索记忆”比看起来更难
人类回忆一件事时,并不是把大脑里的所有经历都扫描一遍。我们通常会先抓住问题里的关键词和语义线索,再联想到相关的人、事、偏好、时间和关系。
AI 的长期记忆系统也类似。
如果用户问:“我喜欢喝什么咖啡?”
系统不能简单地搜索“咖啡”两个字。因为相关记忆可能写成很多不同形式:
• “用户偏好拿铁” • “他每天早上会点一杯 latte” • “张三不喜欢美式,更喜欢奶味重一点的咖啡” • “上次他说星巴克只喝燕麦拿铁”
这些句子不一定共享完全相同的关键词,但语义上都和“喜欢什么咖啡”有关。因此,Mem0 的检索系统要解决的核心问题不是“匹配文字”,而是“找回语义相关的记忆”。
这也是 Mem0 检索链路的主线:先理解问题,再缩小范围,再找相似内容,必要时再重新排序。
二、Mem0 的检索链路
Mem0 的记忆检索可以概括成五步:
1. 接收用户查询 2. 根据用户、Agent、会话等条件构建过滤范围 3. 把查询转换成向量,用向量数据库搜索相似记忆 4. 如果启用了图存储,同时搜索实体和关系 5. 对候选结果进行重排序,返回最相关的记忆
换成更直观的说法:
用户问了一个问题,Mem0 先确认“应该在哪个记忆空间里找”,再把问题变成机器能理解的语义坐标,然后去记忆库中找距离最近的内容。如果还有图谱记忆,它会同时查找人物、偏好、地点、关系等结构化信息。最后,系统会把候选结果再筛一遍,把最可能有用的记忆放在前面。
这条链路看起来简单,但里面有几个关键设计:
• 过滤器负责“别找错地方” • Embedding 负责“理解语义” • 向量搜索负责“快速召回” • 图检索负责“补充关系” • Reranker 负责“精排结果” • 并行检索负责“缩短等待时间”
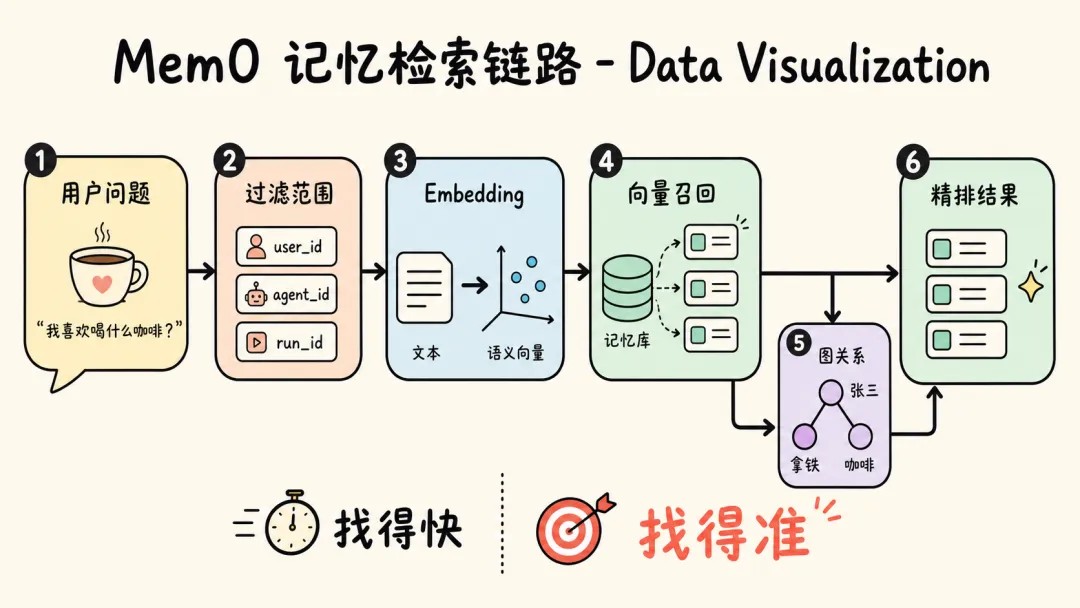
召回
用 Embedding 和向量搜索,从大量记忆中找候选。
过滤
用用户、Agent、会话和时间等元数据划边界。
排序
用相似度和 Reranker,把真正有用的记忆放前面。
下面逐个拆开看。
三、第一步:先确定应该去哪片记忆里找
长期记忆系统最怕的一件事,是把别人的记忆拿出来。
比如同一个应用里有很多用户,每个人都可能说过“我喜欢拿铁”。当张三问“我喜欢什么咖啡”时,系统必须只在张三的记忆里找,而不能把李四、王五或者另一个 Agent 的记忆混进来。
所以 Mem0 检索开始时,会先构建过滤条件。最常见的过滤维度包括:
• 用户 ID:区分不同用户 • Agent ID:区分不同智能体 • Run ID:区分不同会话或运行上下文 • Actor ID:区分具体行为主体 • 时间、角色、自定义元数据等额外条件
这一步的意义很大。它不是为了“高级查询”而高级,而是为了给记忆检索划边界。
如果没有这层过滤,向量搜索再准确也可能召回错误对象的记忆。对个人助手、客服 Agent、企业知识助理来说,这一点尤其关键:记忆的准确性首先来自隔离,之后才是相似度。
四、第二步:把问题变成“语义坐标”
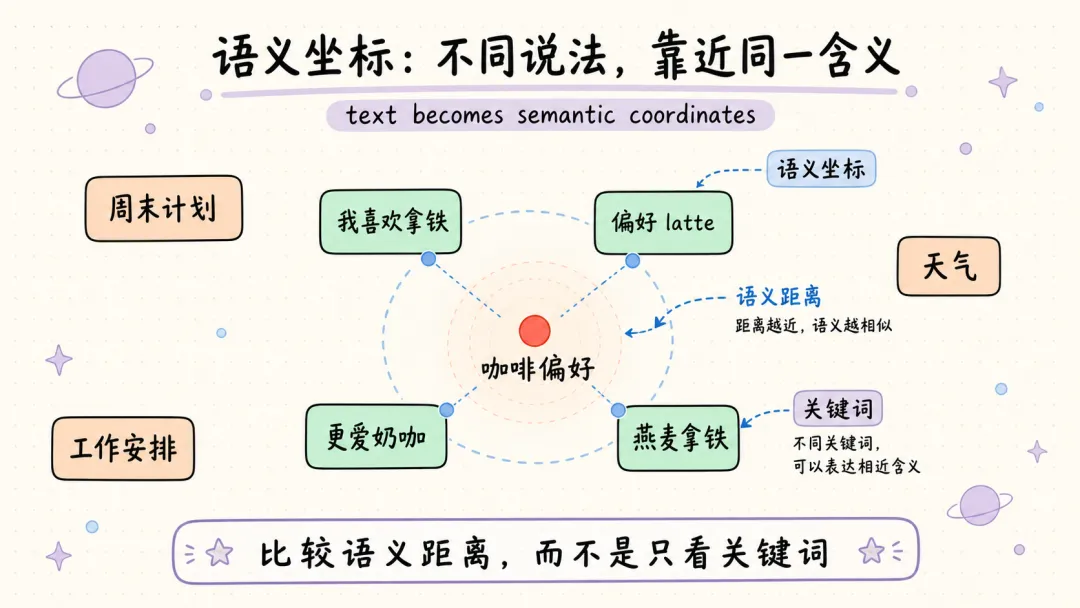
Mem0 检索的核心不是传统关键词搜索,而是向量搜索。
向量搜索背后的关键动作叫 Embedding。简单说,就是把一段文字转换成一组数字。这组数字可以理解成文本在语义空间里的坐标。
比如:
• “我喜欢喝拿铁” • “用户偏好 latte” • “他更爱奶咖”
这三句话字面上差别很大,但语义接近。Embedding 模型会把它们放到向量空间中比较接近的位置。
当用户问“我喜欢喝什么咖啡”时,Mem0 会先把这个问题也转换成向量。随后,系统就不再比较文字本身,而是比较“问题向量”和“记忆向量”之间的距离。
距离越近,说明语义越相似。
这就是为什么 Mem0 能找回那些没有完全命中关键词、但意思相关的记忆。
五、第三步:用向量数据库快速召回候选记忆
当查询已经变成向量,下一步就是去向量数据库里找相似内容。
Mem0 默认支持 Qdrant,也支持 Pinecone、Milvus、Chroma、FAISS、PGVector、Redis、MongoDB、Elasticsearch 等多种后端。不同后端的部署方式和性能特点不同,但在检索链路里的职责是一致的:存放记忆向量,并快速返回最相似的一批结果。
这里有一个很重要的概念:召回。
召回阶段不一定要求一步到位找到最终答案,它更像是先从海量记忆里挑出一批“看起来可能相关”的候选项。
例如用户问:“我喜欢喝什么?”
向量搜索可能先召回:
• 用户喜欢拿铁咖啡 • 用户每天早上喝咖啡 • 用户不喜欢无糖茶 • 用户说过周末会去咖啡店 • 用户喜欢燕麦奶
这些结果相关程度不同,有些很直接,有些只是沾边。向量搜索的任务是快速把候选范围缩小,而不是负责最终裁判。
这也是为什么 Mem0 后面还会引入阈值过滤和 Reranker 重排序。
六、过滤器的作用:让搜索更像“定向回忆”
向量搜索擅长找语义相似的内容,但它不知道业务边界。
业务边界要靠过滤器控制。
比如同样是搜索“最近的偏好”,你可能只想看:
• 某个用户的记忆 • 最近一个月创建的记忆 • 某个 Agent 产生的记忆 • 某个角色说过的话 • 带有某个标签的记忆
Mem0 的过滤器系统支持精确匹配、范围过滤、列表匹配、文本包含、逻辑组合等能力。对于普通使用者来说,不需要记住这些操作符。真正重要的是理解过滤器在检索中的位置:
它发生在“找相似内容”之前或同时发生,用来告诉系统“只在这片范围里找”。
这带来两个好处:
第一,结果更准确。系统不会把其他用户、其他会话或不相关时间段的记忆混进来。
第二,检索更快。范围越明确,向量数据库需要比较的候选越少。
所以,好的记忆检索不只是模型能力问题,也和元数据设计密切相关。写入记忆时保存了哪些字段,检索时就能用哪些字段缩小范围。
七、相似度阈值:不够相关就别返回
向量搜索通常会返回一批“最相似”的结果,但“最相似”不等于“一定相关”。
假设系统必须返回 10 条结果,即使只有 3 条真正相关,它也可能把剩下 7 条勉强相似的内容补上。这会让下游的大模型读到噪声,进而影响回答质量。
因此 Mem0 支持相似度阈值。
阈值的作用很直接:只有相似度达到要求的记忆才会被返回。
如果阈值设得太低,召回更多,但噪声也更多。如果阈值设得太高,结果更干净,但可能漏掉一些有用记忆。
这其实是所有检索系统都要面对的取舍:要更多,还是要更准。
在实际应用里,可以根据场景调整:
• 聊天助手可以适当放宽,避免漏掉背景信息 • 严肃问答可以更严格,减少无关记忆干扰 • 推荐系统可以多召回一些,再交给后续排序处理
八、Reranker:先粗找,再精排
向量搜索很快,但它不是最精细的判断方式。
它更像第一轮筛选:先从大量记忆里找出一批候选。问题是,这批候选内部谁更重要、谁更贴近用户问题,还需要进一步判断。
这就是 Reranker 的作用。
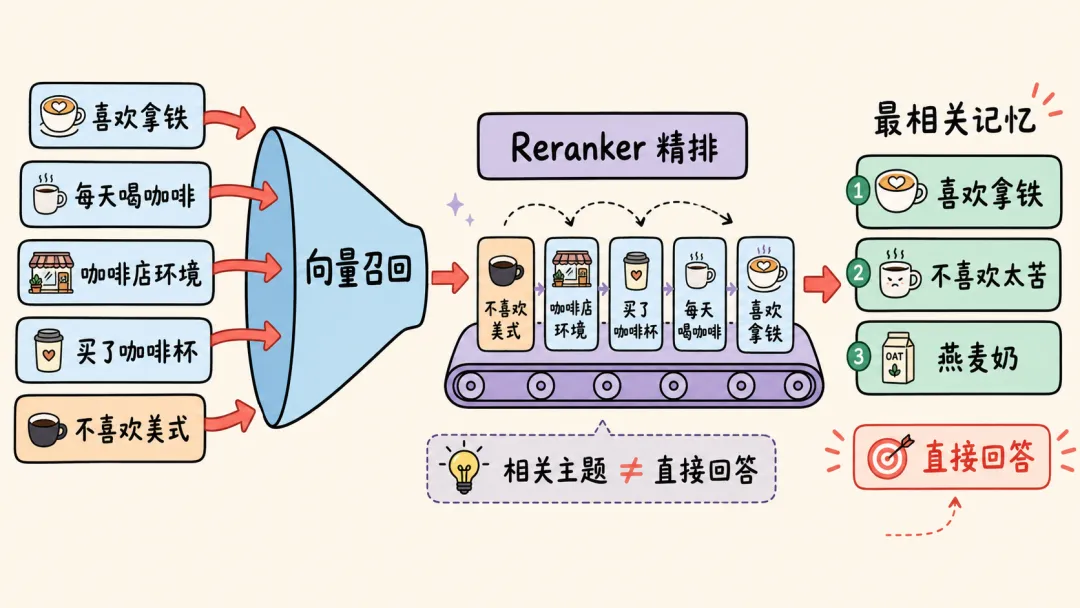
Reranker 可以理解成第二轮面试官。向量搜索先把简历筛出来,Reranker 再逐条看候选记忆和用户问题之间的关系,把真正相关的内容排到前面。
举个例子,用户问:“我喜欢喝什么咖啡?”
向量搜索可能召回:
• 用户喜欢拿铁 • 用户每天早上喝咖啡 • 用户喜欢咖啡店的环境 • 用户不喜欢太苦的美式 • 用户昨天买了咖啡杯
这些都和咖啡有关,但最能回答问题的是“喜欢拿铁”和“不喜欢太苦的美式”。Reranker 的价值就在于进一步区分“相关主题”和“真正回答问题”。
这也是 Mem0 检索质量提升的重要来源:先用向量搜索保证速度,再用 Reranker 提升精准度。
九、图检索:把记忆里的关系也找出来
向量记忆擅长处理语义相似,但有些信息天然更适合用“关系”表达。
比如:
• 张三 喜欢 拿铁 • 张三 就职于 某公司 • 张三 的朋友 是 李四 • 拿铁 属于 咖啡
这些不是简单的文本片段,而是实体之间的关系。
Mem0 如果启用了图存储,会在检索时同时搜索图数据库。它会尝试从查询中找到相关实体,再沿着实体关系查找关联信息。
这能补上向量搜索的短板。
比如用户问:“我之前提到的那个喜欢拿铁的朋友是谁?”
向量搜索可能找回一段聊天记录,图检索则可能直接提供关系:李四 喜欢 拿铁。
两类检索结果结合起来,系统既能获得上下文文本,也能获得结构化关系。
十、并行检索:速度来自同时行动
Mem0 的另一个设计点是并行检索。
如果同时启用了向量存储和图存储,系统不会先查完向量库再查图数据库,而是同时发起两个检索任务。
这很好理解:
• 向量库负责找语义相似的记忆 • 图数据库负责找实体关系 • 两边互不依赖,就可以同时进行
如果向量检索需要 50 毫秒,图检索也需要 50 毫秒,顺序执行大约要 100 毫秒,并行执行则接近 50 毫秒。
对用户来说,这种优化不会体现在某个显眼功能上,但会体现在整体体验里:回答更快,等待更短。
十一、完整例子:一次记忆检索如何发生
假设 Mem0 里已经保存了几条关于张三的记忆:
• 张三喜欢喝拿铁咖啡 • 张三每天早上都会喝咖啡 • 张三不喜欢太苦的美式 • 张三喜欢用燕麦奶
现在张三问:“我喜欢喝什么咖啡?”
Mem0 大致会这样处理:
第一步,确认搜索范围。
系统会把检索限定在张三的记忆里,避免拿到其他用户的信息。
第二步,理解问题语义。
“我喜欢喝什么咖啡”会被转换成向量,表示这个问题的语义位置。
第三步,召回候选记忆。
向量数据库会找出和这个问题语义接近的记忆,比如“喜欢拿铁”“每天喝咖啡”“不喜欢太苦的美式”。
第四步,补充关系信息。
如果启用了图存储,系统可能同时找出“张三 喜欢 拿铁”“拿铁 属于 咖啡”这样的关系。
第五步,重新排序。
Reranker 会把最能回答问题的记忆排到前面。相比“每天早上喝咖啡”,“喜欢拿铁”显然更直接。
最后,Mem0 返回给大模型的就不是全部历史聊天,而是一小组高相关记忆。大模型再基于这些记忆生成回答:
“你喜欢喝拿铁,尤其偏好奶味重一点的咖啡,也提到过喜欢燕麦奶。”
这就是长期记忆真正发挥价值的地方:不是把所有历史都塞给模型,而是在合适的时候找回合适的内容。
十二、这个设计的本质:召回、过滤、排序
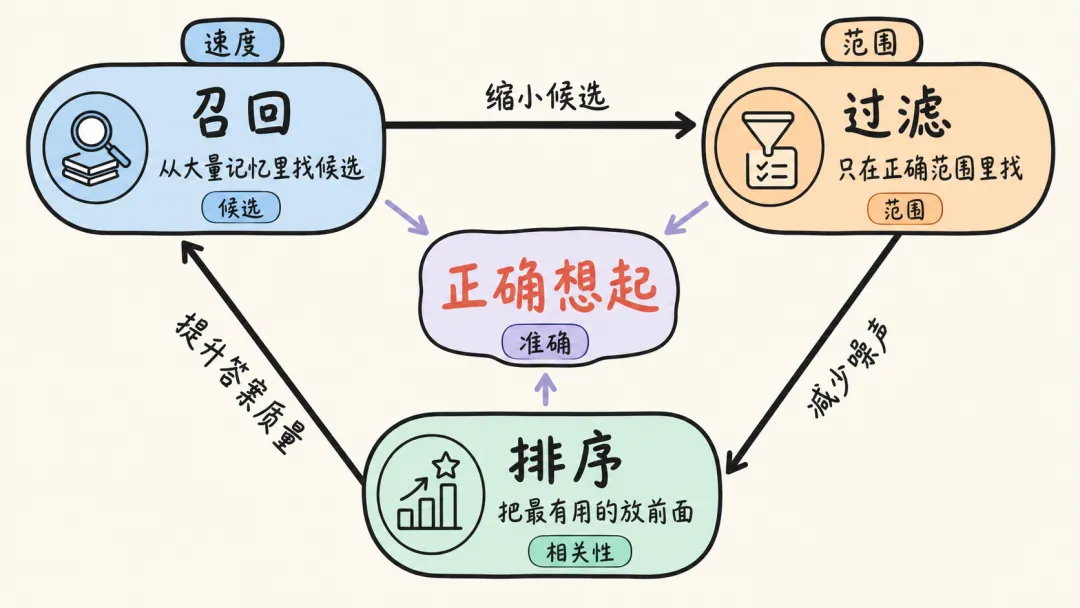
如果把 Mem0 的检索系统再抽象一点,它其实是在做三件事:
第一,召回。
通过 Embedding 和向量搜索,从大量记忆里找到语义相关的候选内容。
第二,过滤。
通过用户、Agent、会话、时间、角色等元数据,确保候选内容来自正确范围。
第三,排序。
通过相似度分数和 Reranker,把最有价值的记忆放到前面。
这三个动作共同决定了记忆检索的质量。
只召回、不过滤,容易串记忆。
只过滤、不做语义搜索,容易找不到换了表达方式的内容。
只召回、不排序,可能把真正有用的信息埋在后面。
Mem0 的检索链路,就是把这三件事组合起来。
核心模型
召回决定能不能想起来,过滤决定是不是想错人,排序决定最重要的信息能不能排在前面。
十三、对开发者的启发
从 Mem0 的实现里,可以看到几个对长期记忆系统很重要的经验。
第一,记忆不是越多越好,能被正确找回才有价值。
长期记忆系统很容易陷入“先存下来再说”的思路,但真正困难的是后续检索。如果写入时没有保存用户、时间、来源、角色等元数据,后面就很难精准过滤。
第二,向量搜索适合召回,不适合独自承担最终判断。
向量相似度能解决“语义接近”的问题,但不能完全解决“是否回答了这个问题”的问题。Reranker、阈值和业务规则仍然很重要。
第三,结构化关系和非结构化文本应该互补。
文本记忆保留上下文,图记忆保留关系。两者结合,系统既能理解一段话,也能回答“谁和谁有什么关系”。
第四,检索性能来自链路设计,而不是某一个模型。
并行检索、索引、过滤器、召回数量、重排序策略,都会影响最终速度。一个好的记忆系统,通常不是靠单点技术取胜,而是靠整条链路配合。
十四、总结
Mem0 的记忆检索并不是简单地从数据库里查几条记录。它更像一次“定向回忆”:
先确定是谁的记忆,再理解问题的语义,然后从向量库里快速召回候选内容;如果有图存储,就同时补充实体关系;最后再通过阈值和重排序,把最相关的记忆交给大模型。
这套机制让 Mem0 能做到两件事:
• 找得快:通过向量数据库、索引和并行检索提升速度 • 找得准:通过过滤器、阈值、图关系和 Reranker 提升相关性
对 AI Agent 来说,长期记忆的关键不只是“记住”,更是“在需要的时候想起来”。
Mem0 的检索系统,解决的正是这个问题。
相关源码位置
• mem0/memory/main.py:记忆检索主流程• mem0/embeddings/:Embedding 生成• mem0/vector_stores/:向量存储适配• mem0/reranker/:重排序逻辑• mem0/memory/graph_memory.py:图记忆检索
系列完结
到这里,Mem0 源码解析系列就正式完结了。
从第一篇的“记忆如何被添加”,到第二篇的“提示词工程如何驱动记忆管理”,再到这一篇的“记忆如何被检索”,我们基本走完了 Mem0 长期记忆系统最核心的闭环:写入、管理、检索。
如果把 AI Agent 看成一个会持续行动的系统,那么长期记忆不是锦上添花的功能,而是它从“一次性问答工具”走向“长期协作伙伴”的关键基础设施。Mem0 给出的启发也很直接:真正可用的记忆系统,不只是把信息存下来,而是要能在合适的时机、合适的范围里,把合适的内容找回来。
