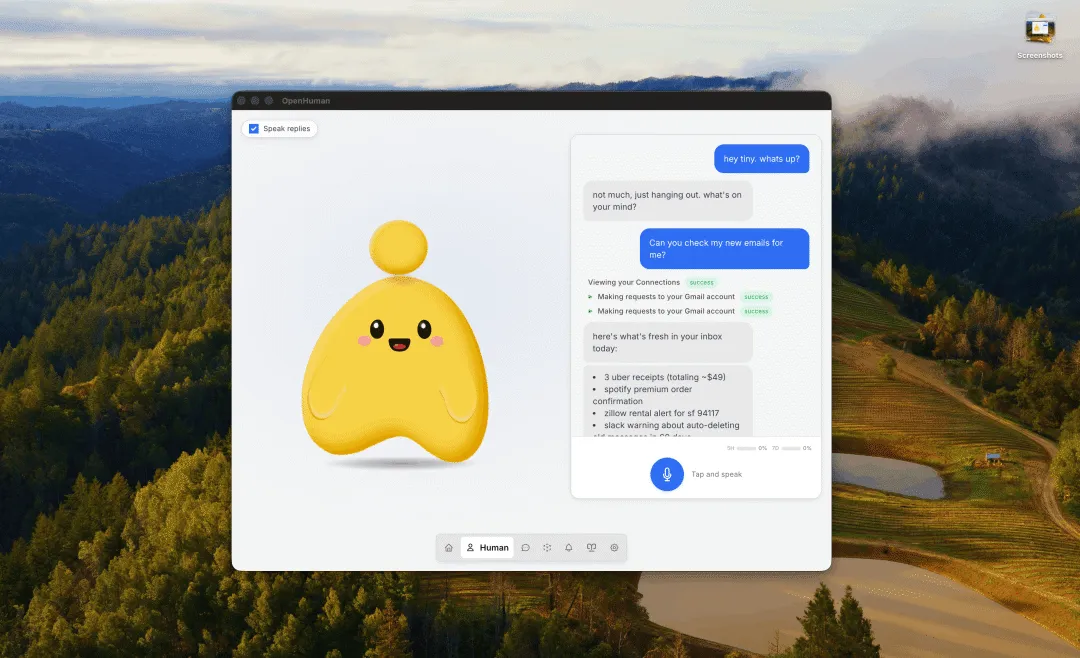
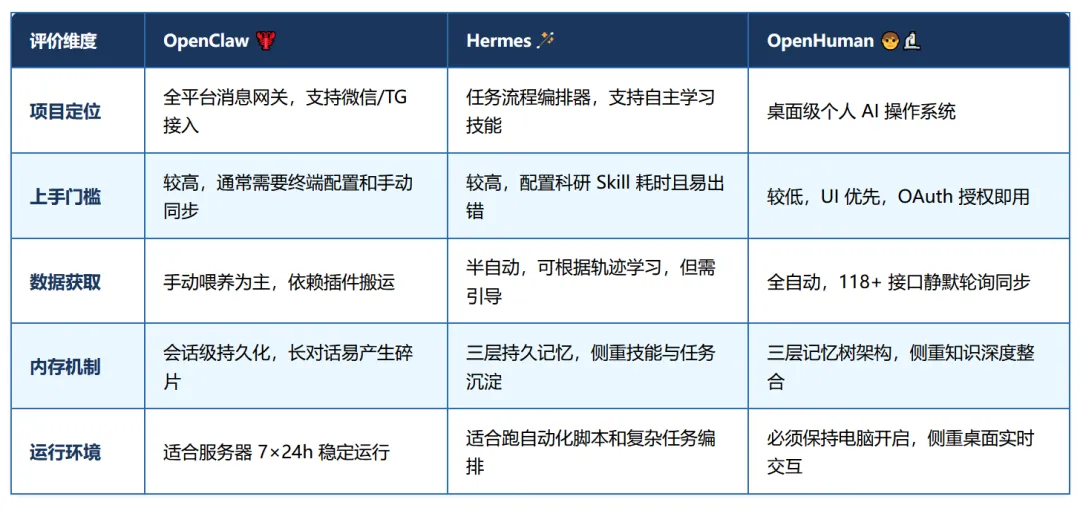
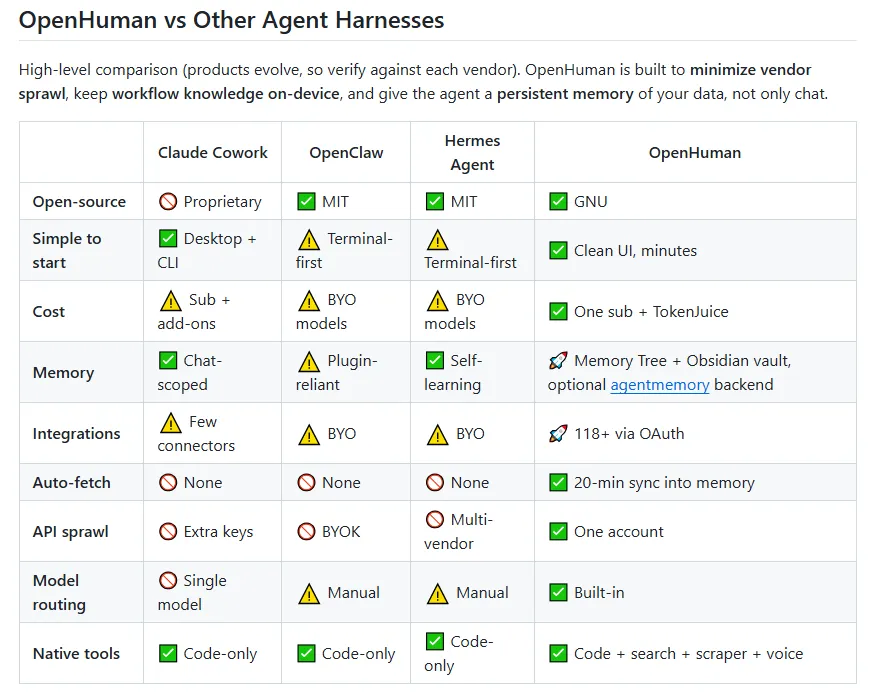
给AI权限还是给科研隐私?OpenHuman横空出世!你的AI研究助手该选谁?按照教程,把AI智能体安装好,但期待的事情并没有发生。安装的智能体就像个未成长的孩子,你每次开启对话,都要一口一口把课题背景,实验进展和导师意见重新喂给它。最近,OpenHuman横空出世,Star迅速攀升。它给AI智能体提供了一种新的思路:让AI从被动接收转向主动了解你的科研工作流。但,也带来了一个问题,为了让AI更好用,我们需要交出多少权限?图源:GitHub目录1. 从频繁喂数据到自动同步2. 跟OpenClaw、Hermes的对比3. 权限开放和隐私保护4. 要装OpenHuman吗PART.01从频繁喂数据到自动同步大多数AI智能体在启动阶段都是空白的。无论是Openclaw还是强调自主学习的Hermes。你要手动配置复杂的插件,或者频繁地提示它们背景资料,它们才能逐渐理解你的研究方向。但,重复的数据搬运本身就会影响效率。OpenHuman的思路相对独特,它用118个以上的OAuth接口(如Gmail,GitHub,Notion,Slack等)实现一键连接。 连接后,它不只是等待你提问,而是通过核心引擎每20分钟自动同步一次你的数据。你可能不用再写长Prompt来解释背景,你坐到电脑前准备改论文时,OpenHuman就通过后台同步,了解了你代码的报错,导师发来的批注和你在日历上标注的实验节点。从被动喂资料到主动观测,也确实带来了一定的便利。图源:GitHubPART.02跟OpenClaw、Hermes的对比要了解一个新出的智能体,快速的方法就是和我们比较熟悉的Openclaw、Hermes进行对比。搞清楚它们各自能做什么不能做什么。三大AI智能体在科研上的对比PART.03权限开放和隐私保护但是OpenHuman是有一个核心的矛盾点在的。你的权限如果给的不够,它就没办法自主做出选择,也会因为信息不足变得平庸。举个例子,你要是不让它有读邮件的权限,它就没办法在你写论文的时候提醒你。可一旦你授权了118+个服务的权限,又容易有暴露的风险。虽说OpenHuman强调Local-first本地优先和本地存储,数据原则上不上云端, 它也并不代表安全。根据新的ADAM攻击研究,攻击者可以通过自适应查询,以较高的成功率从智能体记忆中提取敏感信息。在科研场景下,这意味着你未发表的实验结果,跟导师的私密沟通,甚至是还没来得及提交的专利想法,都有可能因为一次系统性的数字暴露而风险增加。 这就像一个悖论,不给权限,它很难懂你。给了权限,自己的环境又不够安全。图源:GitHubPART.04要装OpenHuman吗面对这样一款刚起步的智能体工具,我们到底要不要安装呢?其实可以再看看,或者在隔离环境下小范围试用,不要交出所有的权限。因为OpenHuman目前仍处在Early Beta(早期测试)阶段,官方也承认可能存在不少Bug。它的TokenJuice技术号称能大幅节省消耗,但在处理逻辑严密的学术公式,专业术语或代码片段的时候,这种压缩会不会造成关键语义的丢失,还没有足够的实测数据支撑。在授权权限前,大家可以利用它Obsidian兼容性,先只授权一些非核心的工具(如公开代码库或日程),定期审计它生成的记忆文件,观察它有没有存在幻觉或者不当的权限调用,再决定要不要拿它作为自己的科研助手。想率先OpenHuman的同学,它的安装过程也很简单,macOS或Linux用户可以通过终端运行一行脚本完成部署:curl -fsSL https://raw.githubusercontent.com/tinyhumansai/openhuman/main/scripts/install.sh | bash;Windows用户则可以使用PowerShell命令:irm https://raw.githubusercontent.com/tinyhumansai/openhuman/main/scripts/install.ps1 | iex。图源:网络项目地址:https://github.com/tinyhumansai/openhumanEND#OpenHuman#AI科研#AI工具#智能体撰稿:学术君责编:科研树懒版权声明:文章分享只为学术交流,如有侵删。
 夜雨聆风
夜雨聆风