 夜雨聆风
夜雨聆风
01
有话题的技术
1、Odyssey 发布世界模型 Starchild-1 与 Agora-1:实现实时音视频联合生成与多智能体并行模拟
Odyssey 推出两款下一代世界模型。Starchild-1 解决了音视频时间频率不一致的挑战,实现首个实时同步的多模态自回归生成;Agora-1 则通过将模拟(状态演变)与渲染(视角生成)解耦,支持最多 4 名智能体在共享生成的 3D 环境(如《黄金眼》)中进行低延迟交互。
Starchild-1:采用因果蒸馏流水线(Causal Distillation Pipeline)将传统的双向音视频基础模型转换为实时自回归模型。通过异步 KV-cache 架构处理音频与视频极高的时间频率差异与信息密度失衡,确保在长时程推演(Long-horizon Rollout)中音视频保持相位同步,且支持流式输入(语音、动作)实时改变模型输出轨迹。
参考链接:https://odyssey.ml/introducing-starchild-1
Agora-1:Agora-1 突破了单智能体世界模型的限制,支持多达 4 个独立视角在同一生成的模拟器中实时行动。由于采用了状态解耦方案,推理成本随玩家增加呈线性而非指数级增长,有效解决了多智能体在互相脱离视线时的世界状态一致性难题。
试玩链接:https://agora.odyssey.ml/
参考链接:https://odyssey.ml/introducing-agora-1
强化学习与 PROWL 框架集成:两款模型均原生支持 PROWL 对抗性强化学习框架。智能体可在生成的模拟世界中进行「想象训练」(Imagined Training),通过探测模型边界产生失效数据,从而递归地提升世界模型的物理真实感与多主体协作的复杂度。
( @odyssey.ml)
2、Runway Characters 开放 Tool Calling 接口:支持实时视频智能体调用双端函数
Runway 宣布为其 Characters 实时视频智能体引入工具调用功能。该更新使模型能够根据实时会话意图,自主决定并触发结构化函数调用,实现查询实时数据、驱动前端 UI 变更或执行后端逻辑,将视频角色从单一的「语音对话」升级为具备业务处理能力的「交互式智能体」。
结构化函数生成 (Structured Function Calling):模型在识别用户需求后,可自动生成包含 name 和 arguments 参数的标准 JSON 指令,用于精准对接外部 API。
双端工具支持方案 (Client & Server Tools):Client tools 在浏览器前端执行,用于触发页面导航、UI 覆盖层显示及元素点击。Server tools 通过标准 HTTP 请求与后端服务器交互,获取私有数据库或实时动态信息。
闭环响应集成 (Response Integration):工具执行结果(Result)会实时回传至模型,由 LLM 将数据整合进自然语言语境,通过视频角色的语音与表情完成最终输出。
多场景组合调用:支持在同一会话中动态组合多种工具,允许智能体在单一通话流中完成「查询实时库存」与「更新前端展示」等复合操作。
https://docs.dev.runwayml.com/characters/tools/
(@runwayml@X)
3、淘宝发布 FashionChameleon:实时 AI 虚拟试衣框架,单卡生成速率达 23.8 FPS
阿里巴巴开发了名为 FashionChameleon 的实时 AI 虚拟试衣视频生成与定制框架。该框架支持在视频生成过程中进行交互式换装与风格动态切换,在单块 H200 显卡上实现了 23.8 FPS 的实时播放效率,处理速度较现有基线提升 30-180 倍。
高性能推理架构:采用流式蒸馏(Streaming Distillation)与梯度重加权分布匹配蒸馏(Gradient Reweighted DMD)技术,解决了传统扩散模型生成速度慢及长视频退化问题。
实时交互换装:引入无训练的 KV Cache 重调度(Rescheduling)机制,允许用户在视频生成流中实时切换服装素材,实现「边看边换」的交互体验。
小样本学习方案:利用教师模型结合情境学习(In-context Learning),仅需在单件服装视频数据上训练,即可实现复杂的多服装视频外推与合成。
高保真一致性:支持上下装分离替换及整套服装更换,在保持 23.8 FPS 高帧率的同时,确保角色身份(ID)一致性与运动过程中的服装保真度,无明显掉帧或伪影。
项目页:
https://quanjiansong.github.io/projects/FashionChameleon/
GitHub:
https://github.com/quanjiansong/FashionChameleon
( @aigclink@X)
4、曝 OpenAI 正为 Codex 内测实时语音模式,前台连麦与后台写代码分离
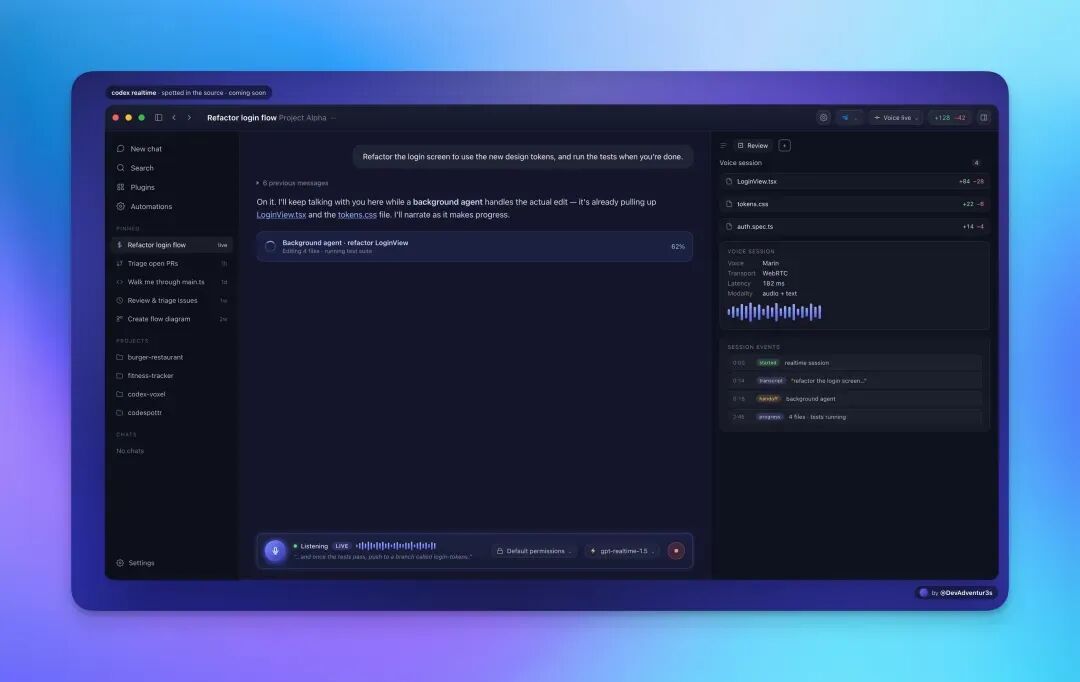
开发者 @DevAdventur3s 近日表示,自己从 OpenAI Codex 代码库中挖出了 1536 行尚未激活的 Rust 代码,显示 Codex 正在测试实时语音模式。
按照其说法,这套方案把交互与执行彻底分开:用户通过语音下达复杂编程任务后,前台会调用代号为 gpt-realtime-1.5 的语音模型,通过 WebRTC 实时与用户沟通进度,而真正的文件修改、代码生成和测试则交由后台另一套更大的模型静默完成。
( @APPSO)
02
有亮点的产品
1、Velo 2.0 发布:一款把「原始语音和屏幕录制一键转成可分享视频与文档」的 AI 视频消息工具。
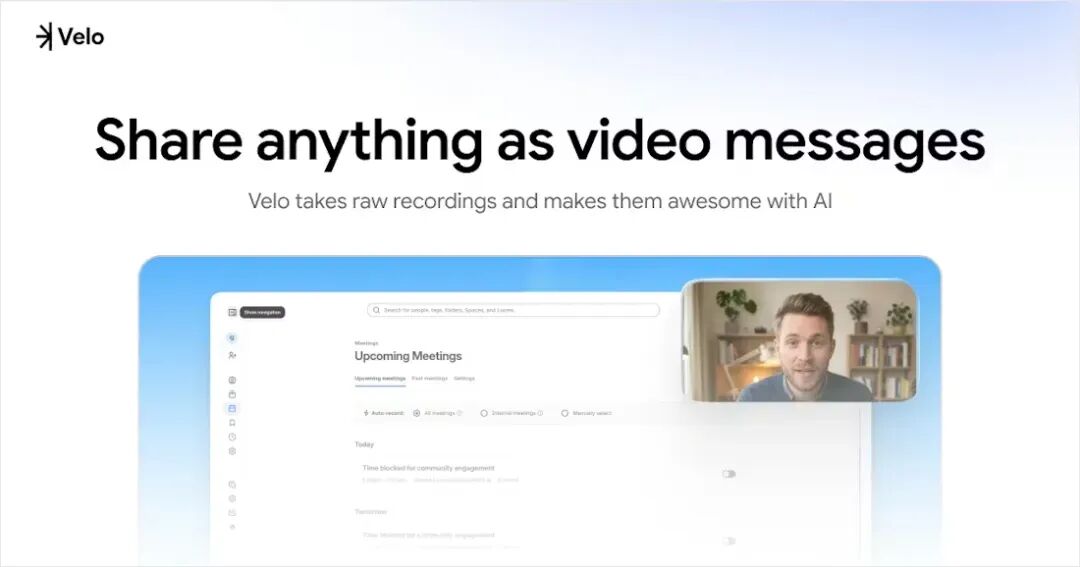
Velo 2.0 定位为「面向对话式工作流的视频消息系统」,核心价值是把「说话 + 屏幕操作」直接结构化成完整的视频和文档。
它适合用来做产品演示、教程、销售提案和内部分享,把原来反复重录、反复剪辑的过程压缩成一次录制、多处输出。
目标用户是销售、产品、客户支持和远程团队;痛点是做视频要么依赖专业剪辑能力,要么只能做简单录屏,很难兼顾专业度、修改便利和品牌一致性。其要解决的是「如何让非视频专业人士也能用自然语言做精细、可靠的视频消息」。
核心功能与差异化优势:
聊天式编辑:通过对话而不是拖时间轴来编辑内容,让非专业用户也能做结构化调整。
实时处理与即时交付:在录制过程中就开始处理,结束即可出视频,减少等待。
语音克隆与语气调整:保留或克隆你的声音,还能随时切换语气,让表达感觉更自然。
智能脚本重写:支持在已经有录音或完全没有音频的情况下,用 AI 补写、重写脚本,让内容逻辑更清晰。
用户体验上,它更像「视频版的对话式工作流」:你录一次,就能自动得到视频和文档,再通过聊天式编辑精细调整,让修改体验接近在写文档而不是在剪辑视频。
( @Z Potentials)
2、谷歌 I/O 2026 开幕倒计时,Android XR 智能眼镜或从概念走向量产

谷歌 I/O 2026 开发者大会将于 5 月 19 日至 20 日在加州山景城举行,北京时间 5 月 20 日凌晨 1 点正式开幕。
5 月 18 日进入最后倒计时阶段,本届大会以 Gemini 3 新版本和 Android XR 智能眼镜为核心看点,预计将展示 Gemini Intelligence 品牌下更多端侧 AI 功能。
综合媒体报道,本届大会大概率不会出现 Gemini 4.0 级别的跨越式迭代,Gemini 3.2/3.5 小幅更新可能性更高,但 Android XR 智能眼镜有望从概念走向量产。
谷歌已提前披露 Android 新特性中涵盖大量 AI 功能,AI 自动化和个性化体验将是核心方向。与此同时,谷歌正准备将 Gemini 深度整合至 Android、Chrome、Search 和 Workspace,这一策略被业界视为谷歌自 Android 发布以来最大的平台级转向,旨在将 AI 变成其生态系统的操作层。
(@极客公园)
03
有态度的观点
1、前 SpaceX 工程师驻扎深圳 8 周后:想做硬件创业,现在就飞过去

前 Tesla 无人驾驶与 SpaceX 猛禽发动机团队工程师 Zac Valles 在 YC Demo Day 结束 72 小时后直飞深圳,驻扎 8 周后携新硬件返回旧金山。
他随后在 X 上发布了一篇长帖,向所有有意从事硬件创业的人发出忠告:不论有没有融资、团队甚至创业想法,都应该立刻去深圳。
只要你对创办一家硬件公司有哪怕一点点想法,就去深圳。融资前、组队前、有想法前、离职前,都不是借口。去就对了。
在切入供应链的路径上,Valles 建议创业者围绕一场大型行业展会安排行程,将其作为接触工厂的跳板。
他还建议在华强北预留 4 到 6 小时实地走访,称其为一座「微型城市」,机器人子组件、电池、底盘、电子元器件均有专属楼栋聚集。
( @APPSO)
加入我们的 Voice Agent 和 Physical AI 社区
RTE 开发者社区持续关注 Voice Agent、Physical AI 等语音对话驱动的下一代人机交互界面。如果你对此也有浓厚兴趣,也期待和更多开发者交流(每个月都有线上/线下 meetup,以及学习笔记分享),欢迎加入我们的社区微信群,一同探索人和 AI 的实时互动新范式。
加入我们:加微信 Creators2022,备注身份和来意(公司/项目+职位+加群),备注完整者优先加群。


更多 Voice Agent 学习笔记:
OpenAI Realtime API 重磅更新:锚定语音模型「深度推理+自主执行」演进路径|Voice Agent 学习笔记
OpenAI 揭秘 Tolan 背后 AI 技术:如何让语音智能体拥有连贯记忆和稳定人格?丨 Voice Agent 学习笔记
如何用 Fun-ASR-Nano 微调一个「听懂行话」的语音模型?丨Voice Agent 学习笔记
如何让你的语音助手有眼力见——Turn Detection 的 5 种解法丨Voice Agent 学习笔记
Pion 创始人聊 WebRTC、AI、SIP 和 QUIC I Voice Agent 学习笔记
2025 年语音 AI 趋势十大洞察丨Voice Agent 学习笔记
硅谷顶级 VC 如何看语音 AI?Greylock 合伙人揭秘 Voice Agent 构建的三层策略
AI 客服还不够聪明,但已超过月薪五千的人类丨RTE Meetup 回顾
引爆 AI 会议工具潮流,Granola 打造 2.5 亿美元估值产品的秘密丨Voice Agent 学习笔记
活动回顾丨主动式语音 AI:全双工加持,让 AI 既会抢答也懂适时沉默丨RTE Meetup
写在最后:

