 夜雨聆风
夜雨聆风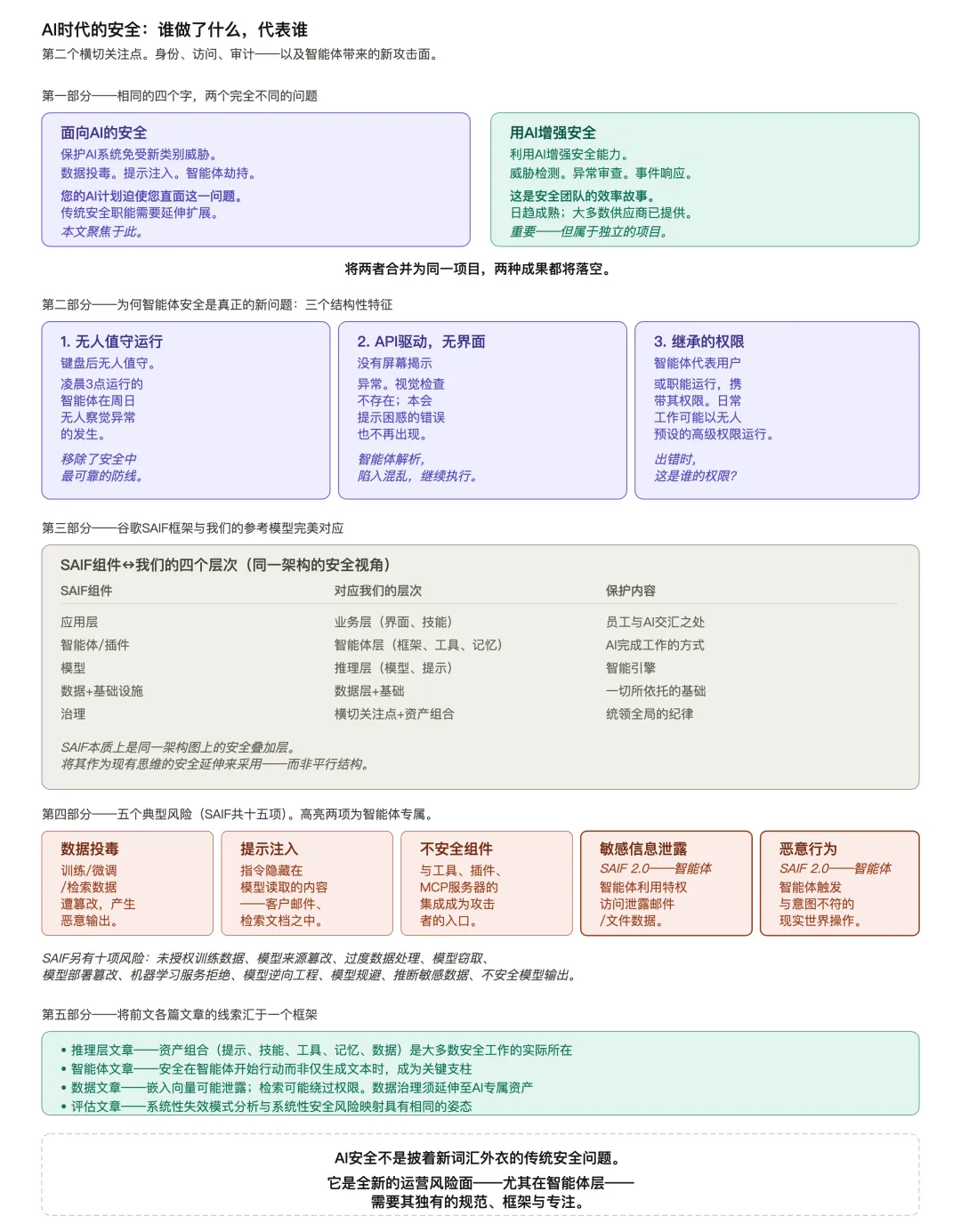
"AI 转型"系列第七篇——也就是最后一篇。这篇讲身份、权限与安全。
前六篇里,我们从上到下走完了四个分层的 AI 栈、引入了贯穿其上的资产组合框架、并讨论了评估——也就是告诉你"这套东西是否在有效工作"的那门纪律。这一篇,讲两个贯穿性关切中的第二个:安全。
谁、以谁的名义、做了什么——以及事后能不能讲清楚。
开始之前,先做一个范围说明。
安全,和负责任 AI(Responsible AI)——公平性、偏见、危害防范、价值对齐、合规——在很多地方相邻,但不是一回事。负责任AI值得专门讨论,我们在后面会回到这个话题。这一篇,我们聚焦在企业 AI一旦开始在真实系统上做出真实动作就必须面对的、技术与运营层面的安全关切。
"AI 安全"这四个字,有两种完全不同的读法——指的是完全不同的两个问题。
大多数高管的对话把这两件事混在一起——这是很多战略混乱和预算混乱的根源。
同样四个字,两件事
"针对AI的安全"(Security for AI)——是保护AI 系统免受AI 引入的新一类威胁的那门纪律。
怎么阻止有人投毒你的训练数据?怎么防止提示词注入?怎么发现一个智能体已经被骗去做了不该做的事?
这些问题,是你的传统安全职能十年前没有遇到过的——因为能被这样攻击的系统当时还不存在。
"针对AI的安全",是把你的安全姿态扩展到一个新的攻击面。
"用AI做安全"(AI for Security)——方向相反。
这是用AI来增强你的安全能力:AI 驱动的威胁检测、自动化的事件响应、对人类团队根本看不过来的海量日志做异常检测。
"用AI做安全",对安全组织本身,是一个生产力的故事——而且已经相当成熟。很多企业已经在用AI增强SOC的运营,大多数安全厂商都有AI驱动的产品。
两个话题都重要。两个都值得投入。
但它们需要不同的团队、不同的预算、不同的厂商评估、不同的成功度量。
一家把这两件事当成一个项目来推的企业,产出的战略文档谁都不会满意,资助的动议哪个结果都拿不到。
这篇文章,聚焦的是前者——"针对AI的安全"——因为这是你的 AI 项目逼你必须面对的那一个,无论你是否选择同时去做后者。
智能体安全,为什么不一样
过去十二个月里,AI安全最重要的变化,是从聊天机器人到智能体的迁移。
一个聊天机器人给错建议,有点尴尬。
一个智能体做错动作,可以动钱、发货、招人、把你公司绑进一份合约。
这里风险的性质完全发生了变化。智能体系统有三个性质,让它们的安全和传统安全职能过去面对的任何东西,都根本不同。
1。 智能体在无人值守的状态下运行(headless)。
传统应用,前面坐着一个用户。用户是最后一道防线——他们注意到事情不对劲,他们在确认按钮前犹豫一下,他们在行为反常时给 IT 打电话。
一个在周日凌晨三点行动的智能体,这些防线一个都没有。
等早上团队登录系统时,它可能已经处理了上百个决定——每一个单看都合理,没有一个有人去检查。
无人值守不是技术细节。它去掉了传统企业安全里最可靠的一道防线——键盘前面坐着一个人。
2。 智能体通过 API 端点行动,不是通过人机界面。
当一个客服代表盯着屏幕看时,屏幕是被设计来暴露异常的——字体、布局、品牌、错误信息,都在用视觉信号告诉他"哪里不对"。
智能体永远看不到屏幕。它读结构化的 API 响应,写结构化的 API 请求。人机界面里那些视觉检查全都不存在。
那些会让一个困惑的人打电话给安全部门的错误——对智能体根本不存在。它要么解析了响应继续往下走,要么解析了响应、被搞糊涂了、还是继续往下走——基于一个没人有能力发现的误解去采取动作。
3。 智能体继承"被指派的角色和权限"。
这是三件事里最深的一件。
当一个智能体代表用户行动时,它继承了用户的一部分权限。
当一个智能体代表一个职能——账务智能体、研究智能体、客户入职智能体——行动时,它带着那个职能的权限。
一个设计糟糕的智能体权限模型,其结果往往是:日常工作被用高管级权限来完成——或者权限是从多个用户那里组合出来的,而那个组合,过去从来没有任何一个人应该拥有过。
更糟的是,当事情出错时,"这个智能体是以谁的名义在行动"——这件事变成有争议:
是开始这次对话的用户?
是最初配置这个智能体的用户?
还是这个智能体的技术所有者?
传统访问控制模型——围绕"有名字的人类主体"建起来的——对这些问题没有给出干净的答案。
而你企业最终落实的那个答案,将会塑造你接下来几年的审计姿态。
这三个性质合起来,产生了一个新的攻击面和一个新的运营风险面。
智能体安全,不是传统应用安全的小扩展。它是一门真正新的纪律。
早认识到这一点的企业,会给自己省下大量后续修补的钱。
SAIF:一个能干净地映射到我们栈上的框架
过去两年里,数个AI安全框架陆续出现——NIST 的 AI 风险管理框架、OWASP 针对 LLM 应用的 Top 10、MITRE ATLAS、以及各厂商自家的指南。
它们之间高度重叠——用哪一个都比不用强。
但在高管对话里,我最喜欢用的,是Google的Secure AI Framework(SAIF)——让我花一点篇幅讲为什么。
SAIF把 AI 安全映射到一组组件上,这组组件看起来和我们这个系列里的分层惊人地相似。
SAIF谈的是数据(Data)、基础设施(Infrastructure)、模型(Model)、应用(Application)、智能体/插件(Agent/Plugin)、治理(Governance)——作为 AI风险被引入、被暴露、被缓解的地方。
把这个和我们的业务层、智能体层、推理层、数据层——加上我们一直在发展的几个贯穿性关切——对比,你会发现:
SAIF 本质上,是把同一张架构图,叠加上了一层安全视角。
词汇不完全一样,但描述的是同一片领土。
这种兼容性,在实践中很重要。
一家已经参考我们的模型思考过AI的企业,可以把 SAIF 当成该模型的"安全扩展"——而不是另起一套并行结构。
这省下了在大企业里跑两套相互竞争心智模型的政治成本和运营成本——而那种摩擦,正是大企业里消磨AI安全项目的典型力量。
SAIF识别了十五个具体的风险,分布在它的各个组件上。每个风险都被追踪到"在哪里被引入、在哪里被暴露、在哪里被缓解"。
完整清单请直接参考 Google 的网站(它公开发布并定期更新)。这篇文章里,我挑五个有代表性的风险走一遍,让你感受一下其核心内容。
数据投毒(Data Poisoning)——训练数据、微调数据、或检索数据被污染,导致 AI 产出恶意输出或异常行为。
数据流到的任何地方都可能被引入;模型行为异常时被暴露;通过数据消毒、完整性检查、访问控制来缓解。
这是传统安全团队凭直觉就能理解的风险——因为有清晰的类比:它本质上就是"供应链攻击"思路应用到数据层。
提示词注入(Prompt Injection)——AI 模型本身存在的固有风险:它没法可靠地区分"指令"和"输入数据"。
攻击者可以把指令藏在模型读到的内容里——一封客户邮件、一份被检索到的文档、一个被总结的网页——而模型可能就把那些指令当作合法用户的指示去执行。
这种风险在传统安全里没有干净的类比。唯一的缓解手段,是输入/输出过滤,加上模型层面的鲁棒训练——两者都不完全可靠。
敏感数据泄露(Sensitive Data Disclosure)——AI意外暴露了不该暴露的信息。
在聊天机器人场景下,这可能是模型不小心引用了一份机密文档。在智能体场景下——SAIF 2.0 专门把这件事扩展进了框架——这件事严重得多:智能体可以利用它的特权访问和连接到的工具,把用户邮件、文件、或其他连接系统里的敏感信息泄露出去——有时是给第三方,有时甚至用户自己都不知情。
缓解需要在多个层面布控:对智能体所能调用的工具的权限控制、智能体输出的安全渲染、以及在可能泄露敏感信息的动作之前,显式让用户确认。
不安全的集成组件(Insecure Integrated Components)——AI 系统和其他系统的连接处——智能体使用的工具、暴露给模型的插件、给它喂数据的 MCP 服务器——变成可被利用的攻击面。
一个安全做得很差的工具集成,就能成为攻击者劫持一个其他方面保护得很好的 AI 系统的入口。
缓解的方式是:对每一个集成都执行严格的权限控制,把"集成面"作为一等公民的安全关切来对待——不是当成开发者的便利。
流氓动作(Rogue Actions)——这是 SAIF 2.0 在 2024 年专门为智能体加进来的风险,也是最值得高管关注的一个。
"流氓动作"是指:智能体触发了一个和用户意图不匹配的真实世界动作——或者因为它的推理核心和用户意图不一致,或者因为它的编排环节里(用到的工具、检索到的记忆、处理过的提示词)已经被投毒。
这种风险独特的地方是——和传统安全攻陷不同——它不需要对基础设施发起一次成功的攻击。智能体本身,通过它自己合法的权限,被错误地使用,就成了攻击载体。
缓解需要分层防御:在输入到达模型之前过滤;在系统指令里给工具定义边界;对推理核心和模型做对抗训练以识别提示词注入;在编排层用可观测性、策略引擎、和带凭证的工具访问来治理智能体的能力;在动作渲染时做规范化和清洗;以及在带业务风险的动作上提供面向用户的提示和保护。
这是五个,共十五个里的。其余十个——未授权训练数据、模型源码篡改、过度数据处理、模型外泄、模型部署篡改、ML 服务拒绝、模型逆向工程、模型规避、推断的敏感数据、不安全的模型输出——没有哪一个不重要;只是从让高管理解的角度,新颖度低一些。
贯穿这十五个风险的一致模式是:一个熟悉的安全关切——盗窃、篡改、未授权访问、拒绝服务——在 AI 上下文里换了一种形态,需要新的缓解手段,而你的现有安全职能需要理解这些风险并且去实施相应的防御措施。
回到前几篇文章
这个系列里,我们在几个地方已经触及过安全。这里把那些线索拉到一起,看看它们怎么在同一个框架下连起来。
在推理层那篇,我们引入了资产组合的框架——提示词、技能、工具、记忆、数据作为一个有意管理、有治理纪律的整体组合。
SAIF 的多数风险,都可以重读为这个组合的安全含义:每一类资产都需要访问控制、版本管理、审计轨迹、以及对事件响应的就绪状态。
资产组合框架和 SAIF 框架是相互加强的——把组合管好,本身就完成了大部分安全工作。
在智能体层那篇,我们说过:一旦智能体开始采取动作而不只是生成文字,智能体的安全就变成承重墙。
这篇文章把这个观点说得更尖锐——通过"三个性质"的分析,把"智能体的安全为什么不一样"讲透。
在数据层那篇,我们标出了两个具体的风险——嵌入向量可能泄露信息,检索可能绕过源系统权限。
这两个都是 SAIF 风险(都是敏感数据泄露和过度数据处理的变体),也都说明了为什么数据治理必须显式地扩展到我们在那篇文章里引入的 AI 特定数据资产。
在评估那篇,我们说过:对失败模式做系统分析,是把"被管理的系统"和"被运营的系统"区分开。
安全有类似的性质:系统性地把自己的 AI 安全姿态对照一个像 SAIF 这样的框架来检查的企业,是在管理它的风险;寄希望于"不出事"的企业,其实还没有在那种纪律下开展运营。
做这些回连的目的不是重复材料。
而是让你看到:我们这一路在搭建的,是一张内部一致的图——栈、资产、治理纪律、评估制度、安全姿态——是同一个企业 AI 项目的几个方面。
把它们当成几条独立工作流,是最常见的错误。
把它们当成一个项目里的相互关联的内容——才是正确的方向。
对你的企业,这意味着什么
这篇如果只能带走一句话,我希望是:
AI 安全,不是"换了套术语的传统安全问题"。它是一个新的运营风险面——尤其在智能体那一层——需要它自己的纪律、它自己的框架、它自己的专门注意力。
三个实际含义。
第一,采用一个框架——并且显式地采用它。
我推荐 SAIF,因为它干净地映射到这个系列一直在建的架构思考上——但具体选哪个,远不如"明确做出一个选择"重要。
没有显式框架的企业,会最后隐式地、不一致地、不完整地,自己捏一套出来。
第二,在预算和团队结构上,把"针对AI的安全"和"用AI做安全"区分开。
两个都在你路线图上。两个不在同一份项目计划里。技能不同、厂商不同、度量不同、时间表也不同。
第三,把"智能体安全"作为AI安全里它自己的一门纪律。
无人值守、API 驱动、权限继承——这三个性质让智能体和聊天机器人、个人助手相比较,是完全不同的生物。
负责智能体治理的团队需要:显式的训练、显式的授权、显式地拥有约束智能体能力的权威——不是把"过去管应用安全那个人"随手扩展一下就完事。
这篇文章,标志着系列主线的完成。
我们走完了四个分层、引入了资产组合、讨论了两个贯穿性关切。
基本模型已经到位。
下面,要去回答的,是"如何真正把一个企业 AI 项目跑好"这种更难的问题。
