 夜雨聆风
夜雨聆风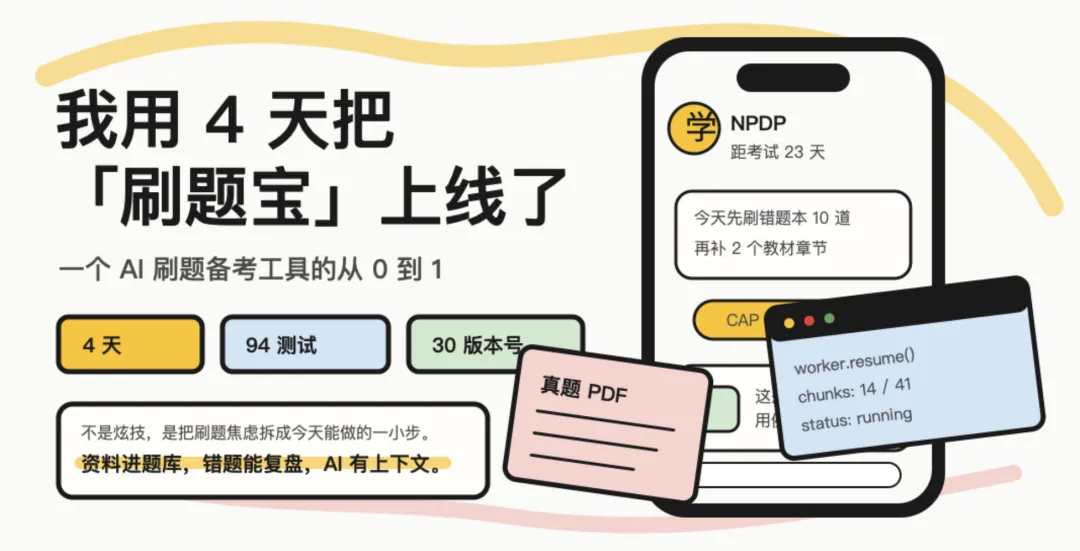

这几天在备考,于是——我的产品【刷题宝】上线了。(没错,除了学习,一切的进度都会很快)
准确说,代码项目代号还叫 learn-or-die-lite,但对外产品名我准备改成 刷题宝。
这个名字更直接,也更符合它现在的核心能力:不讲虚的,先帮你把题刷起来。
你可以把它理解成一个很小的 H5 备考系统:建一个考试档案,把真题、PDF、教材喂进去,然后系统陪你刷题、收错题、复盘,再让 AI 基于真实学习状态给下一步建议。
听起来好像也不复杂。
但这 4 天做下来,我最大的感受是:一个产品从“能跑”到“能被别人用”,中间隔着很多很小、但很真实的坑。
这篇不是产品广告,也不是技术教程。
更像是一个产品经理,趁刚上线还没忘,把这 4 天怎么做、怎么踩坑、怎么一点点把想法压成闭环,认真复盘一下。
01 为什么要做这个?
起因非常朴素:我自己在备考 NPDP。
一个人备考的时候,最难的不是没有资料。恰恰相反,资料太多了:真题 PDF、截图、教材、笔记、别人整理的知识点。
真正麻烦的是三件事。
第一,没人催。
今天刷没刷题,全靠自觉。自觉这东西,早上看很坚定,晚上就很灵活。
第二,看不进。
真题刷完,看一遍答案,感觉懂了。第二天再做,同一道题又错。你甚至能清晰地记得:“这题我昨天好像错过。”然后继续错。
第三,没策略。
错题越积越多,教材越看越厚,距离考试还剩 N 天。你知道自己该学,但不知道今天先做哪一小步。
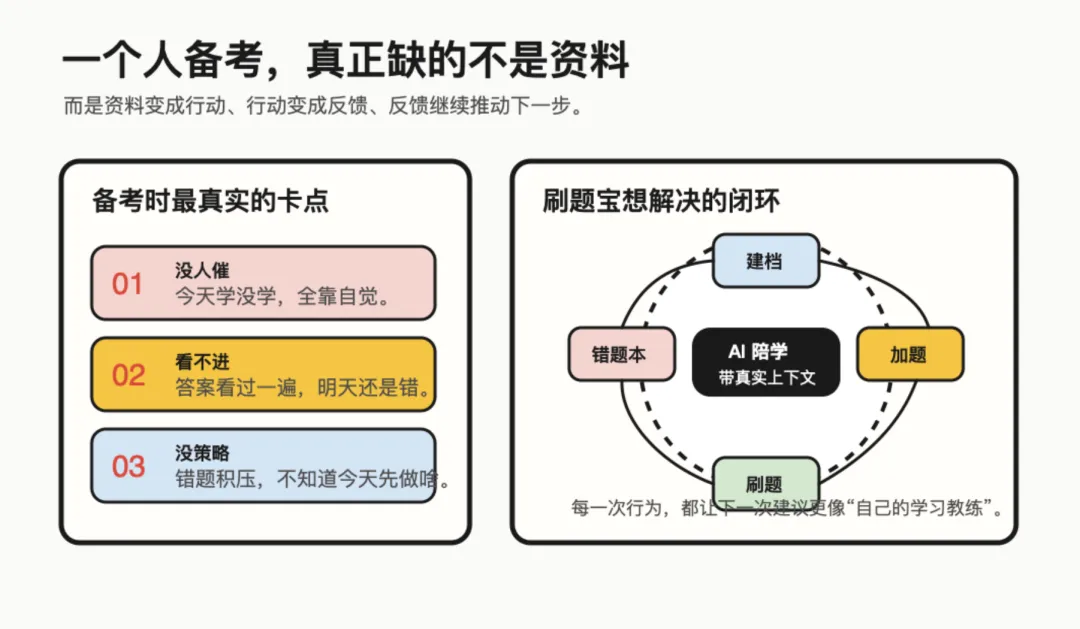
资料很多不等于行动清晰。刷题宝要做的是把资料、刷题、错题和复盘串起来。
所以我想造一个工具,不是帮我“收藏资料”,而是帮我把资料变成行动。
让用户把自己的备考资料喂进系统,系统帮他刷、帮他催、帮他复盘,最后拿结果。
这就是刷题宝的起点。
02 谁该用刷题宝?
今天分享之后,我反而更清楚了一件事:刷题宝不是给所有学习者的。
它更适合那些已经有明确考试目标、手里也有资料,但资料没有变成行动的人。
你只要符合下面任意一个,就很可能是它的早期用户。
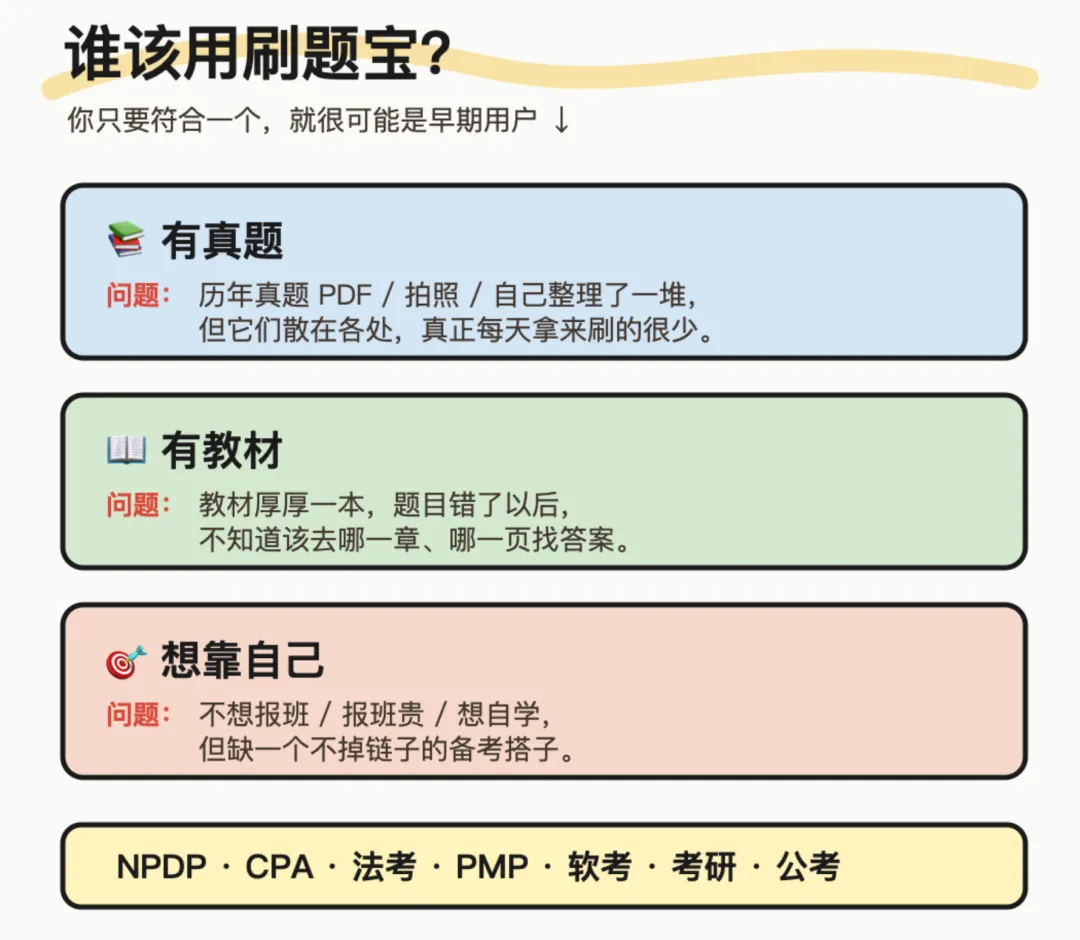
有真题、有教材、想靠自己:这三类人最容易被刷题宝击中。
第一类:有真题,但没用起来。
手里囤了一堆历年真题 PDF、拍照题、别人发来的资料,甚至自己也整理过题目。但它们散在文件夹、微信聊天、相册、网盘里,看起来很多,真正能每天拿来刷的很少。
刷题宝要解决的是:把这些材料变成结构化题库,让它们真的进入你的备考流程。
第二类:有教材,但找答案很痛苦。
很多考试不是没有教材,而是教材太厚。遇到一道题,知道答案可能在某个章节,但不知道是哪一页、哪一段。
刷题宝要解决的是:把教材变成 AI 可引用的上下文。你问问题、看解析、做错题复盘时,不是只听 AI 空口解释,而是尽量回到你上传的教材出处。
第三类:想靠自己,但缺一个不掉链子的搭子。
不想报班,或者觉得报班贵,也可能只是更习惯自学。但自学最大的问题不是没人讲课,而是没人帮你把节奏拎起来。
刷题宝要解决的是:用题库、错题本、距考时间和 AI 陪学,把“今天该做什么”推到你面前。
所以它天然适合选择题为主、真题和教材价值高、复盘链路明确的考试。
比如:NPDP、CPA、法考、PMP、软考、考研、公考。
当然,不是只有这些。只要你的考试高度依赖刷题和错题复盘,刷题宝都可以试。
03 上一代完整版给我的教训
这次我很刻意地加了一个后缀:lite。
因为上一代 v2,给我留下了几个很扎实的教训。
其中最刺激的是:Next 16 + reactCompiler:true,两次把 macOS 拖死,Activity Monitor 里能看到内存吃到 88G。
那一刻我沉默了。
我只是想做个学习工具,不是想让电脑学习如何原地飞升。
还有一个问题是 fork 复杂度。我从别的项目骨架里 fork,带进来一堆当时看着“以后可能有用”的东西:微信渠道、通用 skills、sqlite 路径、各种历史包袱。
结果这些“以后可能有用”,很快变成“现在一定会烦你”。
VPS 上也踩过坑。iLink 启动 22 秒后 OOM,4G 内存直接崩。根因到现在都不值得再追,因为这次 lite 的第一条原则就是:
不抄复杂度。
所以这次我从空项目起步,不 fork 任何骨架;不带微信渠道;不开 React Compiler;每加一个依赖,都问一句:现在真的需要它吗?
这不是保守。
这是一个人做产品时必须学会的节制。
04 刷题宝只做三件事
我给 P1 的边界砍得很薄。
不做社交,不做市场,不做付费,不做小程序,不做 UGC 审核,也不做一堆看起来很漂亮但还没有闭环价值的用户画像可视化。
P1 只做三件事。
第一,档案。
每个考试一个档案,填考试日期、每天投入时间、目标。档案是组织单位,题库和教材都挂在档案下面。
第二,题库。
支持手输、拍照识题、PDF 导入、AI 出题四种加题方式。新题入库时做查重,答错自动进入错题本。
第三,AI 陪学。
不是另开一个泛泛聊天窗口,而是知道你的真实状态:题库有多少、错题本堆了多少、距考还有几天、上次刷题是什么时候。
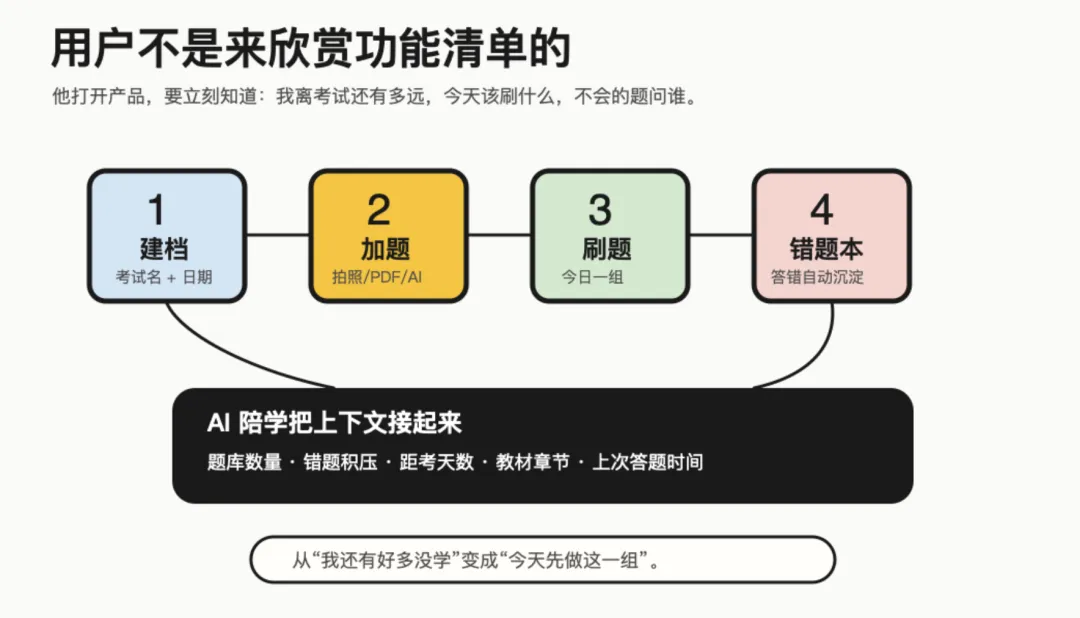
用户打开产品,不是为了看功能列表,而是为了知道今天下一步做什么。
我越来越觉得,一个 MVP 最难的不是“做哪些功能”,而是“忍住不做哪些功能”。
尤其是 AI 产品。
AI 太容易让人产生幻觉:好像什么都能加,什么都能聊,什么都能自动化。最后很容易做出一个功能很丰富、用户却不知道第一步干什么的系统。
所以我反过来问自己:
用户今天打开刷题宝,最想知道什么?

这几个问题能回答,产品就有了第一条命。
05 这 4 天我怎么推进
这次开发,我给自己立了四条铁律。
第一,约束先行。
新项目第一件事不是写代码,而是写 CLAUDE.md。技术栈、目录结构、开发规则、上一代踩过的雷,全部写清楚。
没有规范的工作空间不动手。
第二,可视化原型在前。
我先做 HTML 原型,看页面像不像一个“温柔同伴 · 学习日记”的产品,再写 React。
这是我从 v2 学到的最大教训之一:如果一开始不看页面长什么样,后面很容易把一个错误的产品方向写得非常完整。
第三,按 Superpowers 流程走。
brainstorming → design doc → plan → TDD → code review。听起来像仪式感,其实是防止一个人开发时热血上头。
一个人写产品,最危险的不是手慢,是没人拦你。
第四,红线必先问。
删文件、改 .env、推 Git、动 DB schema,这些都必须停一下。
哪怕 auto-accept 开着,也不能假装自己永远不会犯错。
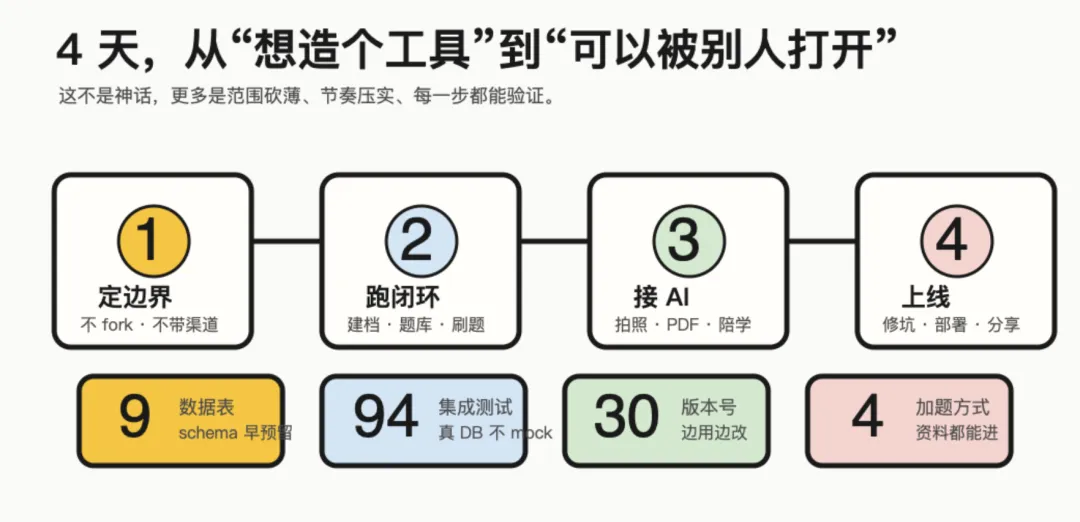
4 天不是“完美产品”,而是把第一条可用闭环跑出来。
当然,这不代表“我 4 天做完了一个完美产品”。
更准确的说法是:我用 4 天把一个能闭环、能真实使用、能继续迭代的第一版跑出来了。
这个差别很重要。
06 技术栈:简单到一个人能维护
这次技术选型非常务实。
前端是 Vite + React 18 + TypeScript + Tailwind + React Router v6 + Zustand。
后端是 Hono + Node 22 + Drizzle ORM + PostgreSQL。
AI 能力走通义千问的 dashscope OpenAI 兼容端点:拍照识题用 Qwen-VL,PDF/AI 出题用 Qwen-Max,陪学聊天用 DeepSeek,查重用 text-embedding-v3。
静态和 PDF 原文件放腾讯云 COS,北京 VPS 上跑后端、前端构建产物和数据库。
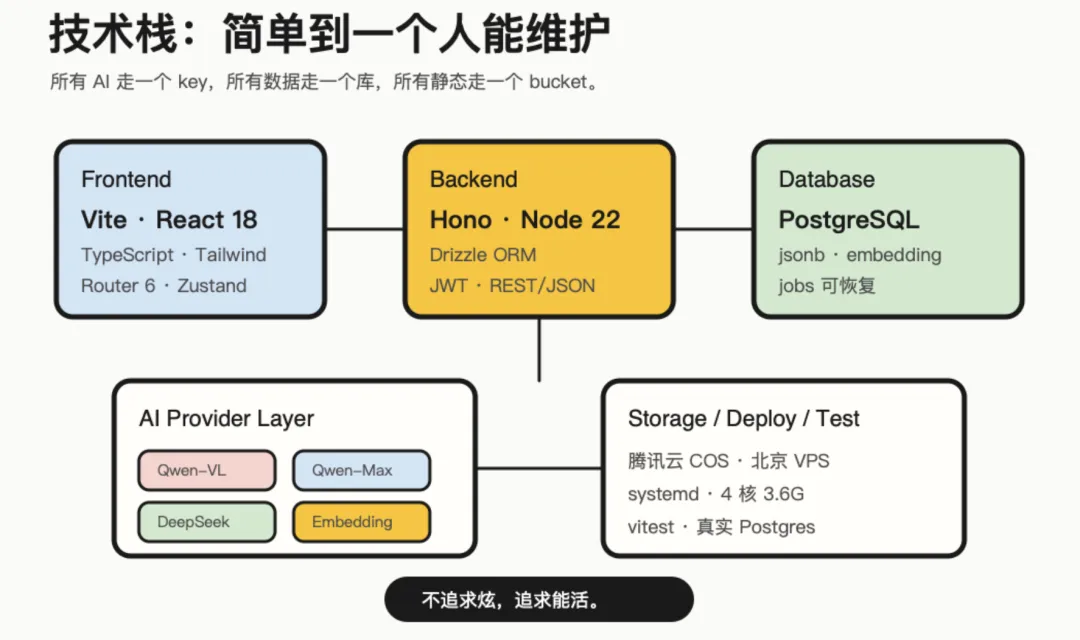
我给这套架构的标准不是先进,而是一个人能维护。
所以它有几个很明确的取舍:
不做微服务。 不上 Redis。 不用 Next.js。 不引入大而全的组件库。 不为了未来十倍流量提前设计现在用不到的复杂链路。
这听起来有点土,但上线产品需要一点土。
尤其是个人产品。
个人产品最怕“架构优雅,人先阵亡”。
07 真正让我长记性的 4 个坑
这 4 天不是一直顺的。
恰恰是踩坑之后,产品才从“能跑”变成“能用”。
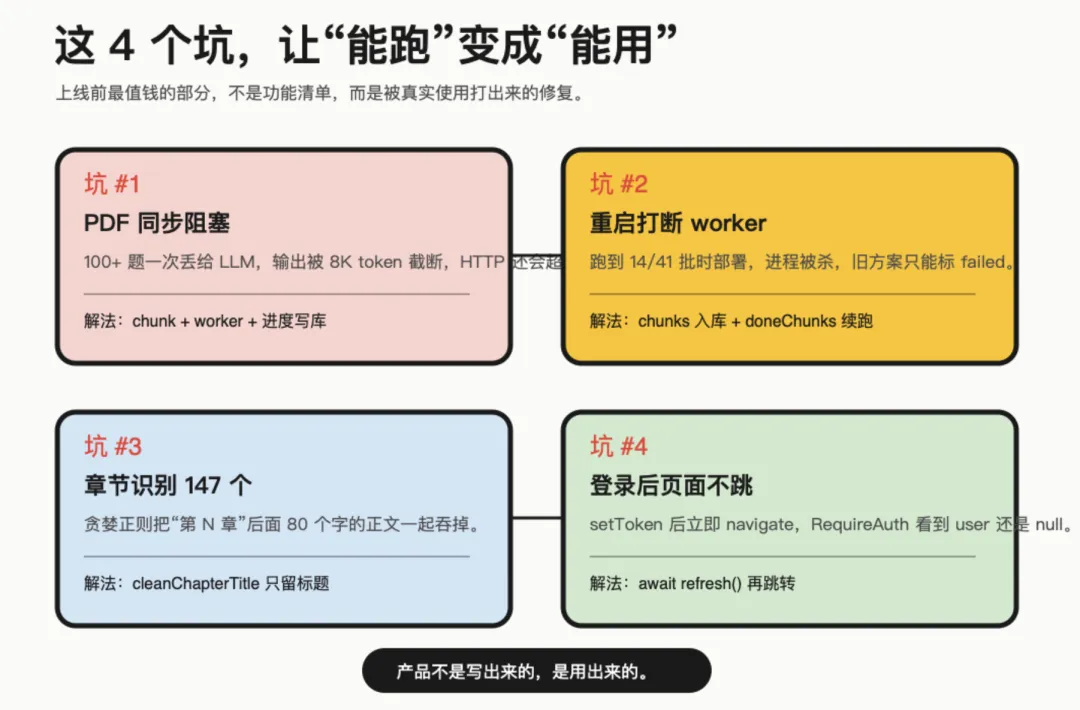
上线前最值钱的部分,不是功能清单,而是被真实使用打出来的修复。
坑一:PDF 同步导入太贪婪
一开始,我把整份 PDF 文本一次性丢给 LLM。
传 100+ 题的真题 PDF 时,问题立刻来了:输出超过 8K token 被截断,HTTP 网关 60 秒超时,用户看着页面卡住,不知道它是在努力、死掉,还是准备给我一个惊喜。
后来改成异步任务模型:
PDF 文本按 chunk 切批 尽量在题号边界对齐 后台 worker 一批一批跑 每个 chunk 做完就写库 前端 1.5 秒轮询进度 失败时保留已识别题目
进度条不是装饰,它是用户信任的一部分。
坑二:服务重启会打断 worker
异步 worker 跑起来后,又遇到第二个真实场景。
用户上传 PDF,任务跑到 14/41 批。我这边部署代码,systemd restart,worker 进程被杀。
旧方案里 chunks 存在内存 Map 里,服务一重启就没了。self-heal 只能把 running job 标成 failed。
这就很尴尬。
后来 v0.0.8.2 改成:chunks 数组写进 DB,candidates 累积写库,worker 从 doneChunks 读起点,服务重启后 setImmediate 续跑。
所有 worker 状态,必须能从数据库单方面恢复。
如果恢复不了,它迟早会在上线时找你算账。
坑三:章节识别 147 个,真实只有 7 个
教材 RAG 也踩了一个很有代表性的坑。
用户上传一本教材,系统识别出 147 个章节。
听起来很努力,但真实只有 7 章。
根因是一个贪婪正则:第 N 章 后面吞了 80 个字正文,每个 chunk 里都匹配出一个“新章节”。
修法很朴素:cleanChapterTitle(raw) 只保留“第 N 章 + 不超过 20 个中文字符”,多余正文不要。
从 147 个回到 7 个。
这类问题很小,但它特别产品。
因为用户不会说“你的正则贪婪了”,用户只会说:“这东西不靠谱。”
坑四:登录后页面不跳转
还有一个经典异步 race。
输入账号密码,点登录,页面不动。手动刷新一下,进去了。
根因是:
setToken → navigate("/") → RequireAuth 看到 user 还是 null → 弹回登录页
token 已经写了,但 AuthContext 的 user 还没 refresh 完。
修复也很简单:
setToken(jwt);await refresh();navigate("/");
状态写了,不等于状态生效。
所有同步跳转前,都要等异步 prerequisite 真的完成。
08 AI 陪学:不是“加油哦”机器
如果只做建档、题库、错题本,刷题宝也能用。
但我真正想做的,是 AI 陪学。
不是那种“你要坚持哦”“学习很重要哦”的泛泛鼓励。
说实话,这种话我自己都不想听。
我想要的是它能看着我的真实学习状态说话:
“你错题本有 28 道积压了。”
“距考还剩 23 天,今天别再加新题了,先清错题。”
“上次刷题是 3 天前,先来 10 道暖暖手。”
“教材第 4 章已经解析好了,你这道题可以回到那个章节看。”
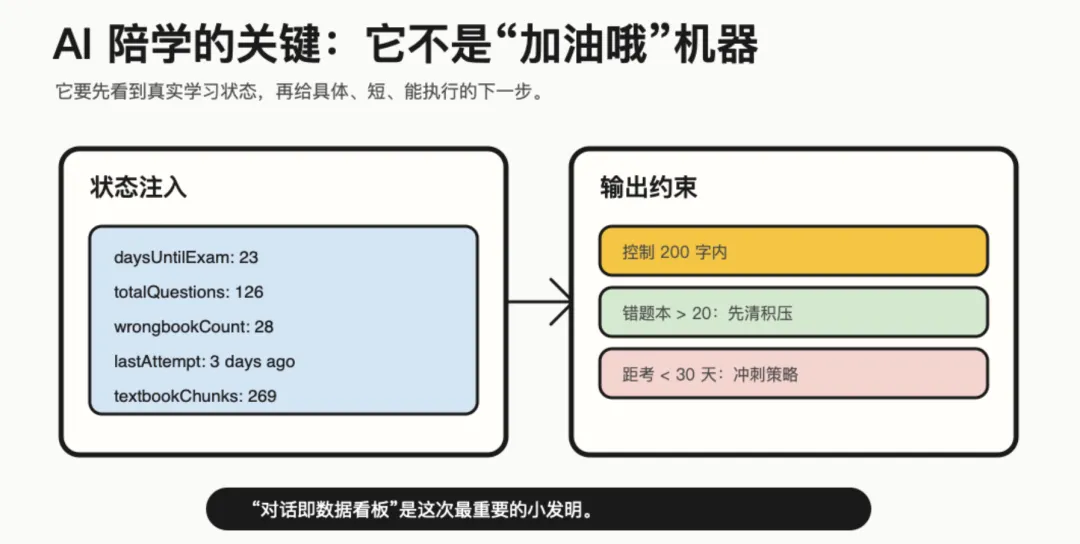
传统数据看板是给人看的,AI 陪学是把看板直接变成行动建议。
这次我给 AI 陪学设计了一个核心 prompt:把 profile 和 stats 注入进去,再给它几条硬约束。
控制 200 字内 给具体可执行建议 错题本超过 20 道,优先清积压 距考小于 30 天,进入冲刺策略 不陪聊离题,不顺着拖延
我把它叫做:
对话即数据看板。
这可能是这次我最喜欢的一个小发明。
09 视觉:让刷题工具不冷
刷题宝的视觉风格,我没有做成冷冰冰的效率工具。
它更像一个学习日记本。
米纸背景、深墨文字、砖红强调、蜜黄高亮、厚黑边、轻微立体阴影,再加一点手写感。
我给它的定位是:
温柔同伴 · 学习日记。
但这里有个边界:温柔不等于软萌。
学习工具如果太软,会像玩具。备考这件事本身有压力,产品可以降低心理负担,但不能把行动骨架拿掉。
所以我保留了 neo-brutalist 的厚黑边和硬阴影:按钮要像按钮,卡片要像卡片,关键数据要站得住。
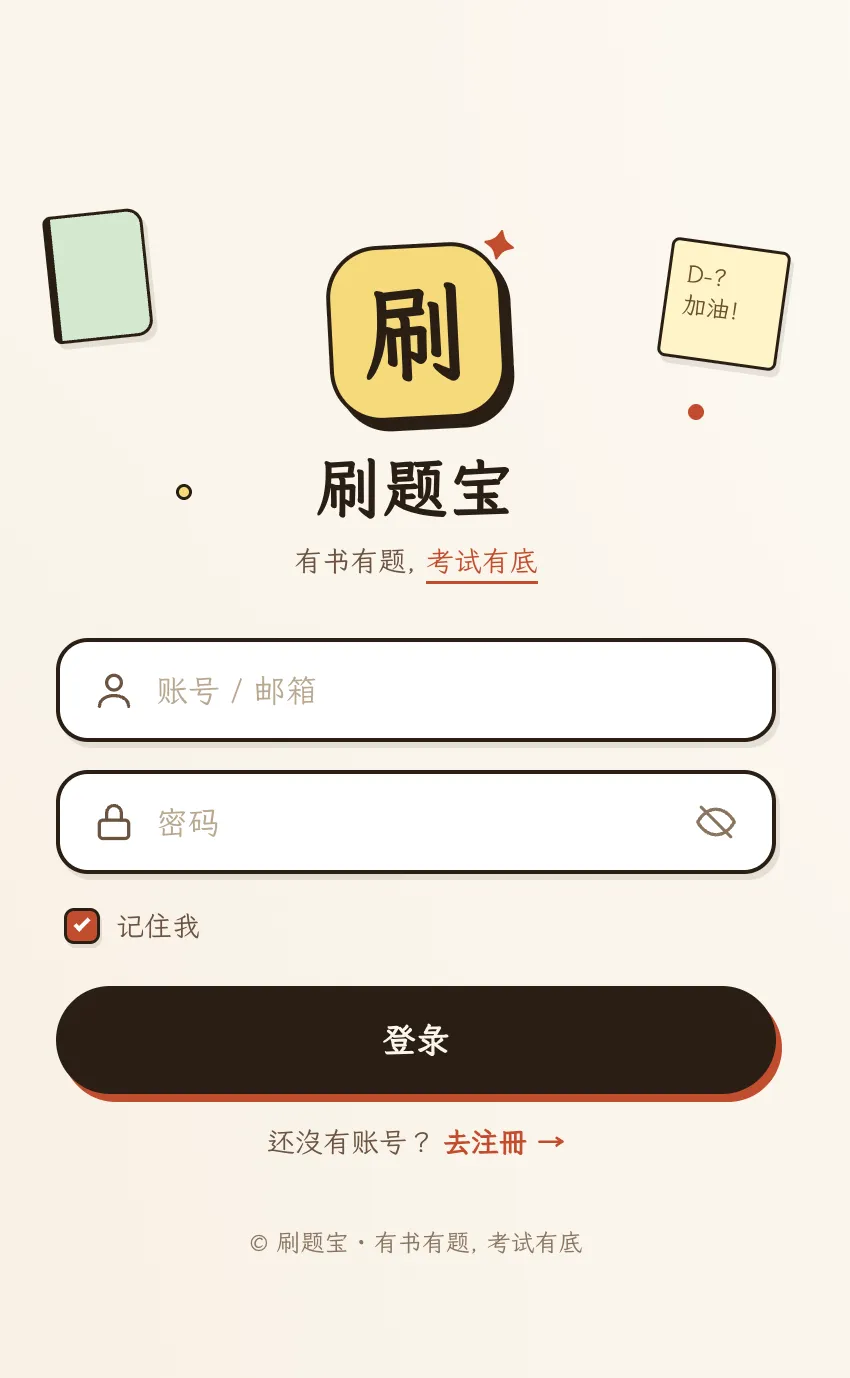
早期高保真视觉稿:米纸、厚边、圆润气泡,以及一点学习日记本的温度。
这个风格不是为了好看而好看。
它想传达的是:你不用被考试压着跑,我们今天先做一小步。
10 现在能拿它干什么?
现在的刷题宝,已经能跑完整个个人备考闭环。
你可以先建一个备考档案,填考试日期和每天投入时间。
然后把资料喂进去。手输一道题可以,拍真题书可以,传 PDF 可以,也可以让 AI 根据知识点出题。
题目进来后,系统会做查重。相似度高的题会提示你新旧对比,答案不一致也会提醒你核对。
刷题时,答错自动进错题本。连续答对 3 次,可以从错题本移除。
如果你上传了教材 PDF,系统会按章节切片、做 embedding。后面问 AI 时,它可以带着教材引用回答,尽量不让概念变成“AI 编得挺像”。
AI 陪学则会根据你的真实状态给建议,而不是开口就“继续加油”。
评论区可以见到产品地址和github开源代码,手机浏览器(非微信自带浏览器哦)和电脑都能打开。
当前还是 HTTP 明文 demo 版,不要上传隐私敏感资料。下一版要先补 HTTPS 和数据备份。
11 我对下一步的计划
刷题宝接下来不会冲“功能大全”。
第一阶段:更稳更深地坚持
补学习进度条、打卡计划、每日任务、阶段提醒。让用户每次回来都知道“今天做什么”。支持更多题型和题源能力。
第二阶段:完成后有结果
做归档通赛、考试成就、上岸记录、复盘报告。备考不是无限苦熬,它应该有一个被看见的终点。
目标就是:把一个人的学习闭环了
也希望大家能多多与我交流,提出宝贵的意见。
写在最后
做完这个版本,我最大的感受不是“AI 开发真快”。
当然,它确实快。
但更准确地说,是 AI 把个人产品开发里很多“原本要靠团队补位的能力”,暂时借给了我。
它帮我写计划,帮我拆任务,帮我跑测试,帮我查 bug,帮我把一些模糊想法压成结构化产物。
但它没有替我做产品判断。
范围要不要砍,坑要不要修,体验是不是可信,数据要不要落库,用户看到这句话会不会焦虑。
这些问题,最后还是人来判断。

刷题宝现在还很早。
它肯定会有 bug,会有不好用的地方,会有很多“这里怎么这么别扭”的瞬间。
但它已经不是一个想法了。
它能被打开,能建档,能加题,能刷题,能复盘,能在你拖延的时候看着数据提醒你。
对我来说,这就够它开始活了。
如果你正在备考,资料很多、错题很多、每天都觉得自己应该学但又不知道从哪下手,可以试试看。
把卡住你的地方告诉我。
你的反馈,就是下一个版本的需求。
关于作者
在瓶,业务型产品经理,为追求好用的产品孜孜不倦的探索。在把 AI 产品从“能聊”推进到“能进入真实业务闭环”。主攻供应链领域产品,也会随时随地的在探索为生活服务的小工具。
本文基于刷题宝 App 2026 年 5 月上线过程整理,保留真实踩坑和取舍。
