夜雨聆风
夜雨聆风链接:https://pan.baidu.com/s/15r0rLWkJlcecUvBPKZo_MQ?pwd=mnsj提取码:mnsj
https://www.mizhushare.com/docs/
在做数据分析时,我们经常会遇到一个核心问题:两组数据的差异,到底是真实存在的“因果必然”,还是运气不好的“随机波动”?
t检验正是回答这一问题最基础、最经典的统计工具之一。它能帮助我们从概率的角度,判断差异是否具有统计学上的显著性。

t检验本质上是一种假设检验,其工作流程大致如下所示:
①、建立假设:零假设H0(通常假设两组数据无差异)、备择假设H1(两组数据确实存在差异)。
②、设定显著性水平α:通常设为0.05(对应 95% 置信区间)。这意味着在做出“存在差异”的结论时,我们愿意承担不超过5%的误判风险。 ③、计算检验统计量:也就是t值。计算公式为:t =(样本均值差异)÷(差异的标准误)。通过公式可以看出分子越大(差异越明显)、分母越小(数据越稳定),t值就越大,差异越可能具有统计学意义。 ④、得出p值并做出推断:p值是在零假设(H0)成立的前提下,观察到当前或更极端数据的概率。通常情况下若p < 0.05,拒绝零假设,认为观察到的差异具有统计学意义。
需要注意的是,t检验要求数据为计量资料(连续变量,如身高、体重、分数等),且应服从或近似服从正态分布。不过,t检验对轻微的偏态偏离具有较强的稳健性,无需过分苛求完美正态。

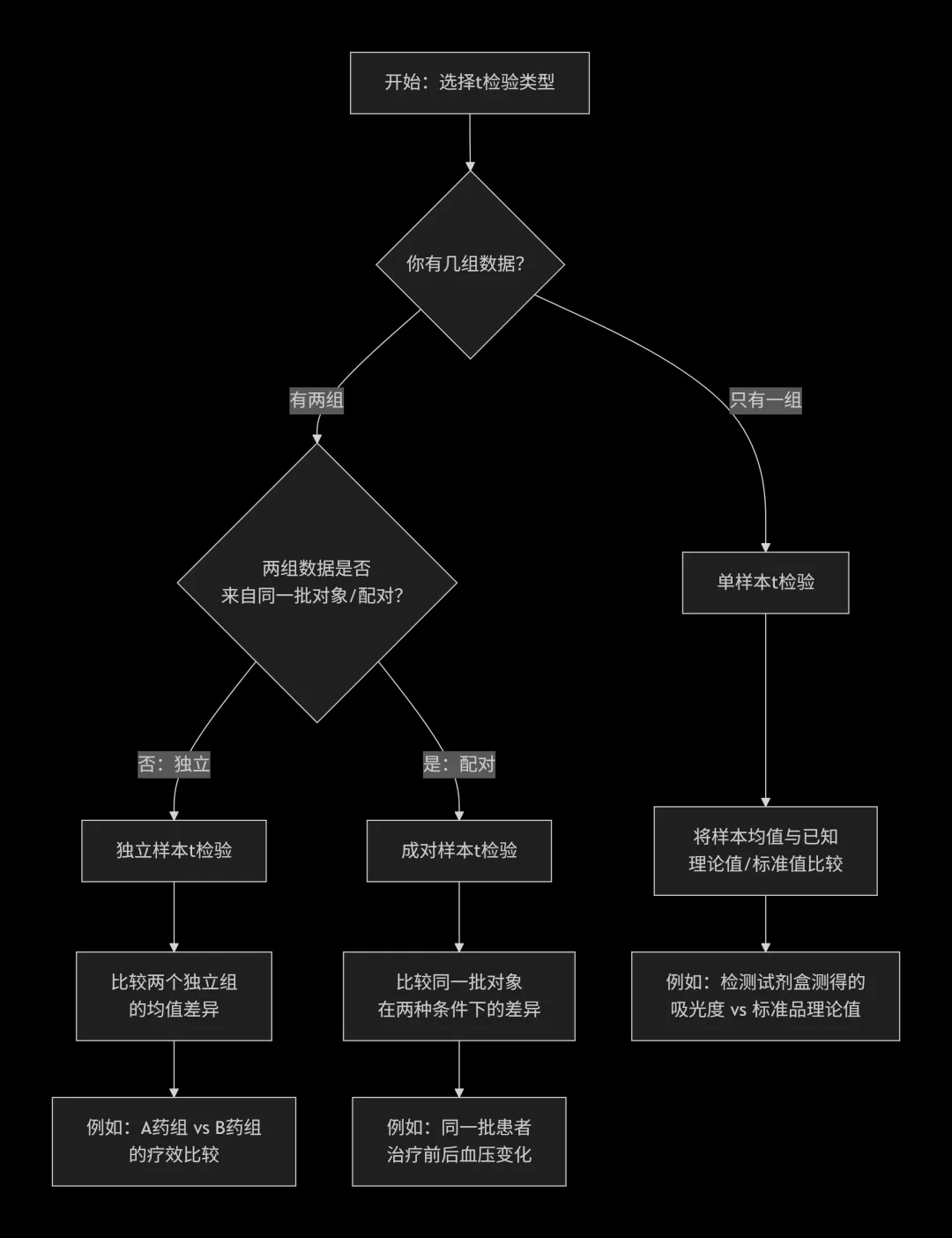
一、单样本t检验:和“标准答案”比高低
核心用途:
经典场景:
某班级的平均考试成绩是否与年级平均分存在显著差异;
验证实验室测定的某种元素含量是否等于国家标品认证值等。
二、独立样本t检验:两组人马,一较高下
核心用途:
比较两个完全独立、互不相关的组别在某个定量指标上的均值差异。它的特点是两个组的成员互不重叠,你测你的、我测我的,两组样本之间没有关联。比如男生组和女生组、实验组和对照组、A药组和B药组。
经典场景:
三、成对样本t检验:自己和自己比,最公平
核心用途:
比较同一批研究对象在两种不同条件或两个不同时间点下的均值差异。它的核心在于“配对”——每一个“处理前”的数据都对应一个“处理后”的数据,两组样本之间存在一一对应的配对关系。数据必须成对出现,且样本量相等。本质上,它是先计算每一对的差值,然后将这些差值作为一个新的变量,检验其均值是否显著偏离0,因此可以理解为转化为单样本t检验来处理。
经典场景:
t检验是统计分析中最基础但极其重要的工具,选择合适的t检验方法的关键在于理解“数据之间的关系”: