 夜雨聆风
夜雨聆风源码剖析
已经来到了《ggml 源码剖析》的尾声,这是最后一篇了,本以为内容挺多,结果发现都是函数顺势调用,并没有什么需要过多的讲解内容,只需顺序跟随阅读即可...
后端缓冲区
ggml-backend-impl.h
// 后端缓冲区结构包含了后端缓冲区接口、缓冲区类型、上下文信息、大小和使用类型等字段。
structggml_backend_buffer {
structggml_backend_buffer_i iface; // 后端缓冲区接口,包含与后端缓冲区交互的函数指针
ggml_backend_buffer_type_t buft; // 缓冲区类型,指示该缓冲区所属的类型,例如 CPU、CUDA、Metal 等
void* context; // 上下文信息,允许后端缓冲区存储与其相关的特定于后端的数据或状态
size_t size; // 缓冲区大小,以字节为单位,指示该缓冲区的总容量
enumggml_backend_buffer_usage usage; // 使用类型,指示该缓冲区的用途,例如权重、计算等,这有助于后端优化内存管理和数据访问策略
};ggml-backend.h
// 后端缓冲区用途:用于提示后端按不同访问模式优化分配/调度。
enumggml_backend_buffer_usage {
GGML_BACKEND_BUFFER_USAGE_ANY = 0, // 通用用途
GGML_BACKEND_BUFFER_USAGE_WEIGHTS = 1, // 权重(通常偏只读)
GGML_BACKEND_BUFFER_USAGE_COMPUTE = 2, // 计算中间结果
};和 ggml_backend 的设计理念一致,它也是接口驱动的内存管理。
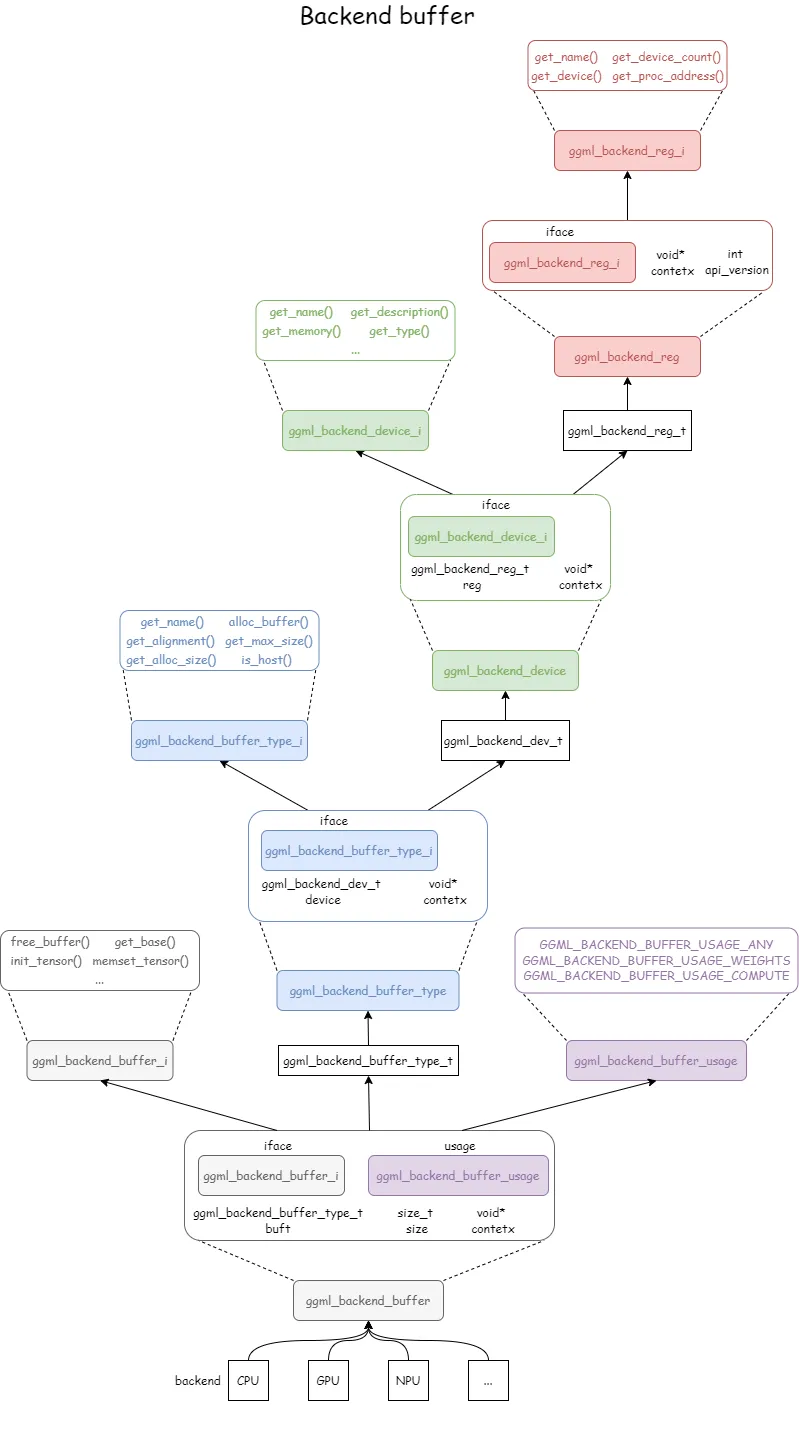
后端缓冲区接口
ggml_backend_buffer 的强大之处在于它和后端一样,也是基于接口设计的。一个 ggml_backend_buffer_t 实际上是一个指针,指向一个包含了一系列函数指针的结构体。
ggml-backend-impl.h
// 后端缓冲区接口定义了与后端缓冲区交互的函数指针,包括分配、访问和管理张量数据的函数。
// 这些函数允许后端实现自定义的缓冲区管理策略,以优化性能和内存使用。
// Backend buffer interface: lifecycle + tensor data access callbacks.
// Different backends (CPU/CUDA/Metal/etc.) provide their own implementations.
structggml_backend_buffer_i {
// (optional) free the buffer
// 释放缓冲区占用的资源,确保正确管理内存和其他相关资源,防止内存泄漏和资源浪费。
// Release buffer and associated backend resources.
void (*free_buffer) (ggml_backend_buffer_t buffer);
// base address of the buffer
// 返回缓冲区的基地址,允许直接访问缓冲区中的数据。这对于高性能计算非常重要,因为它可以避免不必要的数据复制,提高数据访问效率。
// Return base pointer for direct access when supported.
void * (*get_base) (ggml_backend_buffer_t buffer);
// (optional) initialize a tensor in the buffer (eg. add tensor extras)
// 在缓冲区中初始化张量,可能包括设置张量的元数据、分配必要的内存或执行其他与张量相关的初始化操作。
// 这对于确保张量在后端缓冲区中正确配置和准备就绪以供计算使用非常重要。
// Initialize tensor metadata in this buffer (e.g. backend extras).
enumggml_status(*init_tensor)(ggml_backend_buffer_t buffer, struct ggml_tensor * tensor);
// tensor data access
// 访问缓冲区中张量数据的函数,允许设置和获取张量数据,以及在不同缓冲区之间复制张量数据。
// Tensor data read/write on [offset, size] in tensor storage.
void (*memset_tensor)(ggml_backend_buffer_t buffer, struct ggml_tensor * tensor, uint8_t value, size_t offset, size_t size);
void (*set_tensor) (ggml_backend_buffer_t buffer, struct ggml_tensor * tensor, constvoid * data, size_t offset, size_t size);
void (*get_tensor) (ggml_backend_buffer_t buffer, conststruct ggml_tensor * tensor, void * data, size_t offset, size_t size);
// (optional) tensor copy: dst is in the buffer, src may be in any buffer, including buffers from a different backend (return false if not supported)
// 复制张量数据的函数,允许将数据从一个缓冲区复制到另一个缓冲区。这对于在不同后端之间移动数据非常重要,尤其是在使用多个后端进行计算时。
// Copy into destination tensor in this buffer; return false if unsupported.
bool (*cpy_tensor) (ggml_backend_buffer_t buffer, conststruct ggml_tensor * src, struct ggml_tensor * dst);
// clear the entire buffer
// 清除整个缓冲区的函数,允许将缓冲区中的所有数据设置为指定的值。这对于重置缓冲区状态或初始化缓冲区以供后续使用非常有用。
// Fill/clear whole buffer for reset/reuse.
void (*clear) (ggml_backend_buffer_t buffer, uint8_t value);
// (optional) reset any internal state due to tensor initialization, such as tensor extras
// 重置缓冲区的函数,允许重置与张量初始化相关的任何内部状态。
// 这对于确保缓冲区在重新使用之前处于干净状态非常重要,尤其是在处理复杂的张量结构或使用特定于后端的优化时。
// Reset internal state created by init_tensor.
void (*reset) (ggml_backend_buffer_t buffer);
};它定义了一组指针函数(即接口),这些函数是针对缓冲区(buffer)操作的一些基本功能。
这个结构体中的函数指针如下:
• free_buffer:释放缓冲区 • get_base:获取缓冲区的首地址 • init_tensor:在缓冲区中初始化张量 • memset_tensor、set_tensor、get_tensor:用于张量数据的读写 • cpy_tensor:在不同的缓冲区间进行张量数据的复制 • clear:清空整个缓冲区 • reset:重置缓冲区的内部状态
后端缓冲区类型
// 后端缓冲区类型结构包含了后端缓冲区类型接口、设备信息和上下文信息等字段。
structggml_backend_buffer_type {
structggml_backend_buffer_type_i iface; // 后端缓冲区类型接口,包含与后端缓冲区类型交互的函数指针
ggml_backend_dev_t device; // 设备信息,指示缓冲区所属的计算设备
void * context; // 上下文信息,存储与缓冲区相关的额外数据
};
// 后端缓冲区类型接口定义了与后端缓冲区类型交互的函数指针,包括获取名称、分配缓冲区、获取对齐方式和最大大小等函数。
structggml_backend_buffer_type_i {
// 获取后端缓冲区类型的名称,允许识别和区分不同类型的缓冲区。这对于调试、日志记录和选择适当的缓冲区类型非常有用。
constchar * (*get_name) (ggml_backend_buffer_type_t buft);
// allocate a buffer of this type
// 分配一个指定大小的缓冲区,允许后端实现自定义的缓冲区分配策略,以优化性能和内存使用。
ggml_backend_buffer_t (*alloc_buffer) (ggml_backend_buffer_type_t buft, size_t size);
// tensor alignment
// 获取缓冲区的对齐方式,确保分配的缓冲区满足特定的对齐要求。这对于某些计算设备和操作非常重要,因为它可以提高数据访问效率和计算性能。
size_t (*get_alignment) (ggml_backend_buffer_type_t buft);
// (optional) max buffer size that can be allocated (defaults to SIZE_MAX)
// 获取可以分配的最大缓冲区大小,允许后端实现限制缓冲区大小以适应特定的计算设备或内存约束。这对于防止过度分配和确保系统稳定性非常重要。
size_t (*get_max_size) (ggml_backend_buffer_type_t buft);
// (optional) data size needed to allocate the tensor, including padding (defaults to ggml_nbytes)
// 获取分配张量所需的数据大小,包括填充字节,允许后端实现自定义的大小计算策略,以优化内存使用和性能。
// 这对于确保缓冲区能够正确容纳张量数据非常重要,尤其是在处理复杂的张量结构或使用特定于后端的优化时。
size_t (*get_alloc_size)(ggml_backend_buffer_type_t buft, conststruct ggml_tensor * tensor);
// (optional) check if tensor data is in host memory and uses standard ggml tensor layout (defaults to false)
// 检查张量数据是否在主机内存中,并使用标准的 ggml 张量布局,允许后端实现自定义的检查策略,以确定张量数据的位置和布局。
// 这对于优化数据访问和计算性能非常重要,尤其是在使用多个后端进行计算时。
bool (*is_host) (ggml_backend_buffer_type_t buft);
};ggml_backend_buffer_type 结构体用于表示缓冲区的类型,每种缓冲区类型都会实现一组接口(通过结构体 ggml_backend_buffer_type_i 来定义),允许在不同的后端(如 CPU 和 GPU)上创建和管理缓冲区。
ggml_backend_buffer_type_i 其接口函数包括:
• get_name:获取缓冲区类型名 • alloc_buffer:为指定类型分配缓冲区 • get_alignment:获取缓冲区的对齐要求 • get_max_size、get_alloc_size:查询缓冲区的最大大小和分配大小 • is_host:检查缓冲区是否位于主机内存 host 中
ggml_backend_dev_t 是指向 ggml_backend_device 的指针类型,它封装了后端设备的各种具体信息,上节课已经讲过了就不再提交了。
源码
源码相关并不复杂,入口分为 Cpu 和 Cuda 两个来说:
ggml-backend.h
// 默认 Cuda 后端缓存区
GGML_API ggml_backend_buffer_type_tggml_backend_get_default_buffer_type(ggml_backend_t backend);
GGML_API ggml_backend_buffer_tggml_backend_alloc_buffer(ggml_backend_t backend, size_t size);
// Cpu 后端缓冲区
GGML_API ggml_backend_buffer_type_tggml_backend_cpu_buffer_type(void);
GGML_API ggml_backend_buffer_tggml_backend_cpu_buffer_from_ptr(void * ptr, size_t size);先看 CPU 的后端缓冲区
ggml_backend_buffer_tggml_backend_cpu_buffer_from_ptr(void * ptr, size_t size){
GGML_ASSERT((uintptr_t)ptr % TENSOR_ALIGNMENT == 0 && "buffer pointer must be aligned");
returnggml_backend_buffer_init(ggml_backend_cpu_buffer_from_ptr_type(), ggml_backend_cpu_buffer_from_ptr_i, ptr, size);
}
staticggml_backend_buffer_type_tggml_backend_cpu_buffer_from_ptr_type(void){
staticstructggml_backend_buffer_type ggml_backend_cpu_buffer_type = {
/* .iface = */ {
/* .get_name = */ ggml_backend_cpu_buffer_from_ptr_type_get_name,
/* .alloc_buffer = */ ggml_backend_cpu_buffer_type_alloc_buffer,
/* .get_alignment = */ ggml_backend_cpu_buffer_type_get_alignment,
/* .get_max_size = */NULL, // defaults to SIZE_MAX
/* .get_alloc_size = */NULL, // defaults to ggml_nbytes
/* .is_host = */ ggml_backend_cpu_buffer_type_is_host,
},
/* .device = */NULL, // FIXME ggml_backend_reg_dev_get(ggml_backend_cpu_reg(), 0),
/* .context = */NULL,
};
return &ggml_backend_cpu_buffer_type;
}Cuda 的后端缓冲区
ggml_backend_buffer_tggml_backend_alloc_buffer(ggml_backend_t backend, size_t size){
returnggml_backend_buft_alloc_buffer(ggml_backend_get_default_buffer_type(backend), size);
}
ggml_backend_buffer_type_tggml_backend_get_default_buffer_type(ggml_backend_t backend){
GGML_ASSERT(backend);
returnggml_backend_dev_buffer_type(backend->device);
}
ggml_backend_buffer_type_tggml_backend_dev_buffer_type(ggml_backend_dev_t device){
GGML_ASSERT(device);
return device->iface.get_buffer_type(device);
}代码是贴了部分,并没有什么复杂度,依次往下顺便可以了解后端缓存区的内存管理门道。这里就没必要做过多粘代码操作了!
以 set_tensor 设置张量为例:
• 当你的缓冲区是 CPU 缓冲区时, iface.set_tensor指针则会指向一个内部调用memcpy的函数,只是简单的内存复制。• 当你的缓冲区是 CUDA 缓冲区时, iface.set_tensor指针会指向一个内部调用cudaMemcpyHostToDevice的函数,实现从 CPU 到 GPU 的数据传输。
至此《ggml 源码剖析》完结,后续看看继续《llama.cpp 源码剖析》走起!
