 夜雨聆风
夜雨聆风
让6个AI员工写"使用说明书"后,效率翻倍了
我让6个AI员工各自写了一份"操作手册"后,效率翻倍了
不是便宜模型不好用,是用对提示词更有性价比。这是我管理AI虚拟团队的真实心法。

一、一个让我困惑了很久的问题
A Question That Bothered Me For A Long Time
过去4个月里,我同时管理着6个AI虚拟员工。
有负责技术开发的、有做市场调研的、有管项目进度的、有做设计的、有当CEO的、还有专门监管幻觉的……
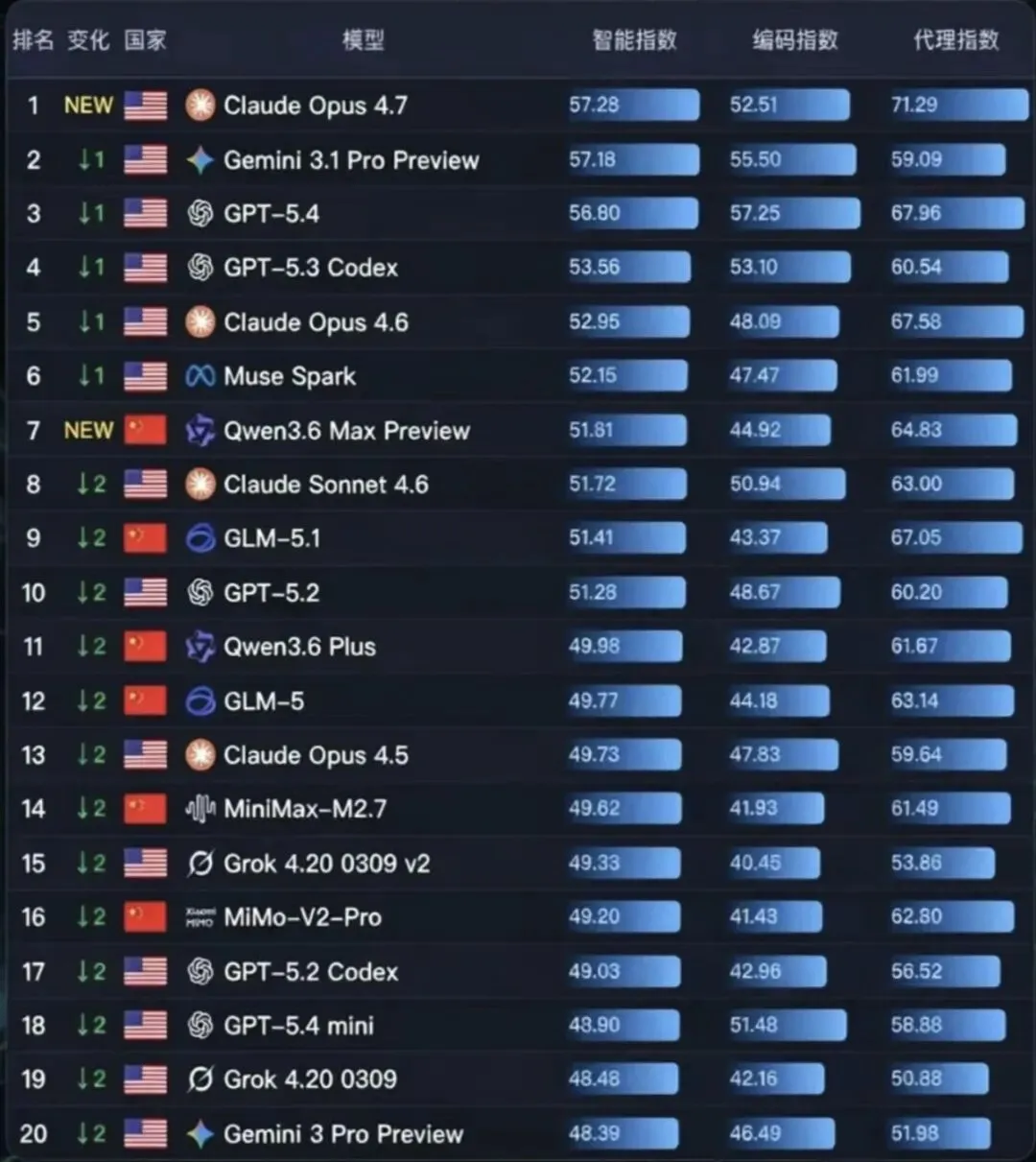
但有个问题一直很折磨我——明明用的是同一个底层模型,同一个prompt框架,为什么有的员工干活很靠谱,有的就答非所问?
比如我让市场官 Maker 写一份行业分析报告,它写得像模像样。同样的 prompt 结构套给技术总监 CITO,它就变得怪怪的——用词不对,深度不对,逻辑走向也不对。

💡 配图说明:同样的模型,为什么结果差异这么大?
后来我恍然大悟:我用惯了GPT的方式去跟Claude对话,又用Claude的方式去跟DeepSeek对话。 就像让一个会计去焊电路板——不是他不行,是我问的方式不对。
每个大模型都有自己的"性格",而我们大多数人的做法是:用一个通用模板去怼所有模型。 结果就是贵的模型用不出贵的价值,便宜的模型被冤枉说"不好用"。

二、一个偶然的发现
An Accidental Discovery
有一天我试了一个方法。
在正式提问之前,我先对模型说了一句话:
"请你给我一个超级提示词工程的结构,目的是让你发挥出最大的能力,让你更懂我和我的业务。"
然后神奇的事情发生了。
模型给了我一整套"操作手册"——它告诉我它擅长什么、不擅长什么、喜欢怎么思考、需要我怎么提问才能给出最好的答案。

💡 配图说明:发现:元提示让输出质量大幅提升

我照着这份说明书去提问,结果——
✅ 回答深度明显提升
✅ 输出结构更清爽
✅ 幻觉大幅减少
同样的模型,只是换了一种问法,效果天差地别。
💡 配图说明:Meta-Prompting三层递进结构
这不是玄学。这件事背后有一套严谨的逻辑,叫 Meta-Prompting(元提示工程)。

三、Meta-Prompting 到底是什么?用人话讲清楚
What Is Meta-Prompting?
先给你一个最直觉的理解:
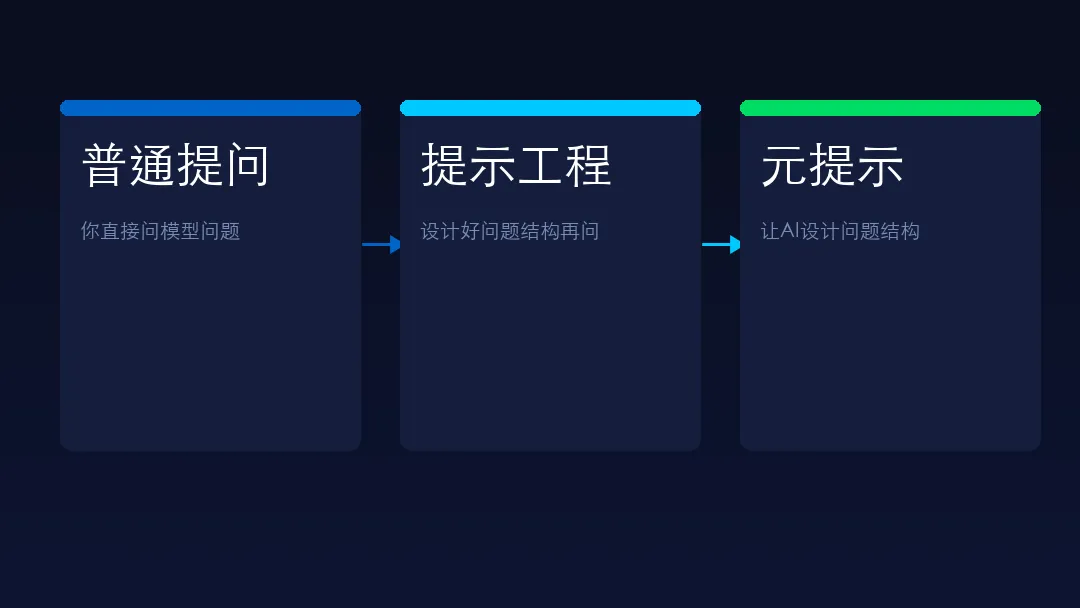
普通提问:你直接问模型问题。
提示工程:你设计好问题的结构再问。
元提示工程:让模型自己设计问题的结构,你再照着问。
一层比一层高。元提示工程就是"让AI教你如何用AI"。
它的名字里带个"元"(Meta),到底元在哪?
"元"的意思就是"关于自身的"。
元认知 = 关于思考的思考
元数据 = 关于数据的数据
元提示 = 关于提示的提示

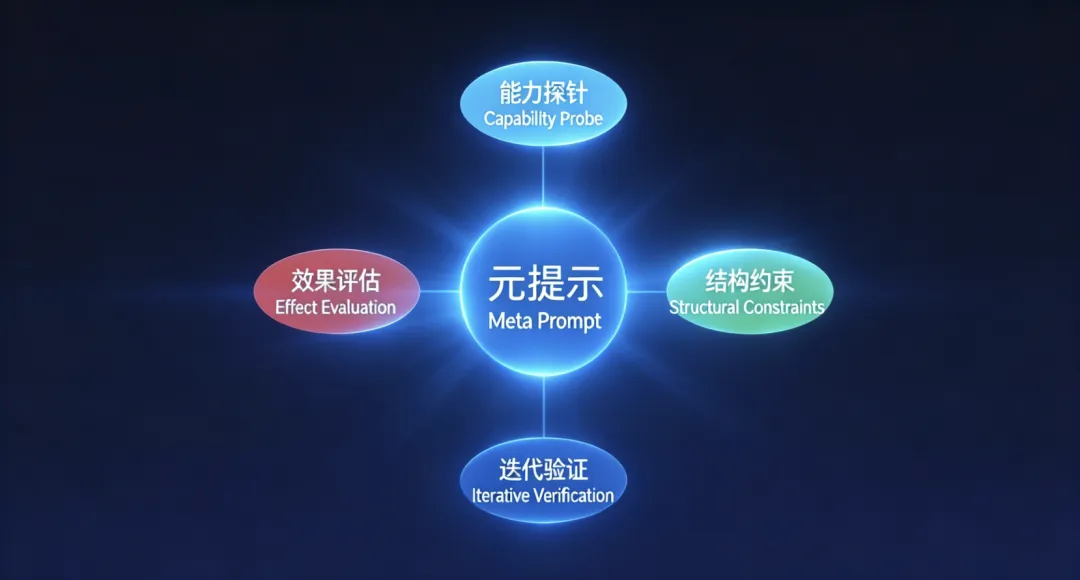
💡 配图说明:三步让任何模型发挥120%能力
你不是直接问问题,而是先问模型:"你怎么回答才能答得最好?"

套娃吗?不是,这是有科学原理的
原理①:激活参数子空间
大模型的参数是巨大的(GPT-4 约 1.8万亿参数)。同一个模型,你用不同的方式问它,它激活的"脑区"是不一样的。
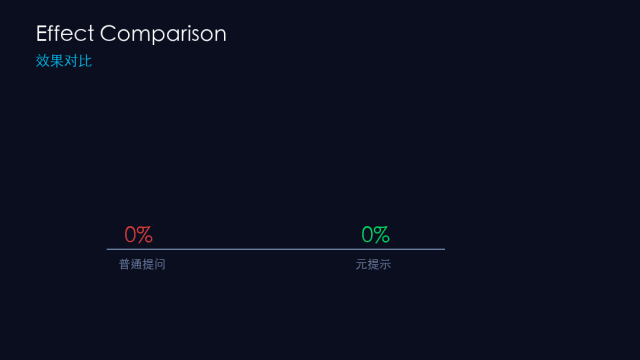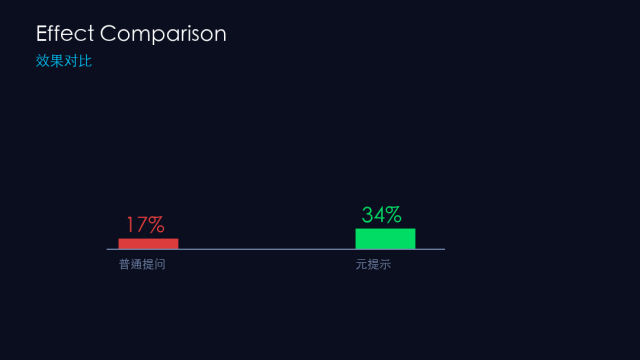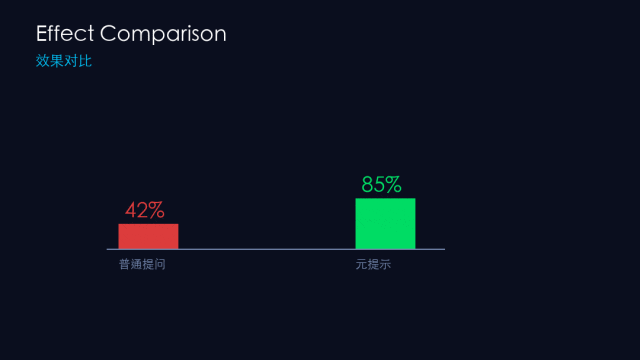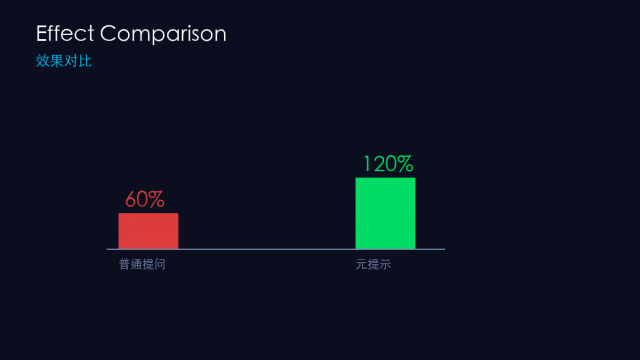
💡 配图说明:效果对比:普通提问 vs 元提示
当你让模型写自己的操作手册时,你逼它进入了元认知模式——它调动的不是"回答这个具体问题的参数",而是"我如何思考问题的参数"。
这就像你跟一个人说"别急着回答,先想想你擅长什么,再想想该怎么输出"——他的表达质量当然会不一样。
💡 配图说明:框架复用,内容专属
原理②:建立思维脚手架
元提示给模型的不是一个具体任务,而是一个高阶思维框架。这个框架告诉你的是"你应该怎么思考",而不是"你要输出什么"。
有了框架,模型就不会在无限的可能性中随意游荡,而是在你设定的轨道上运行。
原理③:减少无目的性采样
无引导的提问 = 让模型在几千亿个可能的回答中随机采样。而有了结构和框架,它的搜索空间被大幅压缩,输出的质量和一致性自然上升。
学术界怎么说?
2024年斯坦福大学发表论文《Meta-Prompting: Enhancing Language Models with Task-Agnostic Scaffolding》(arXiv:2401.12954),用GPT-4做实验,结果:
标准直接提示:相比元提示低 17.1%
专家动态提示:相比元提示低 17.3%
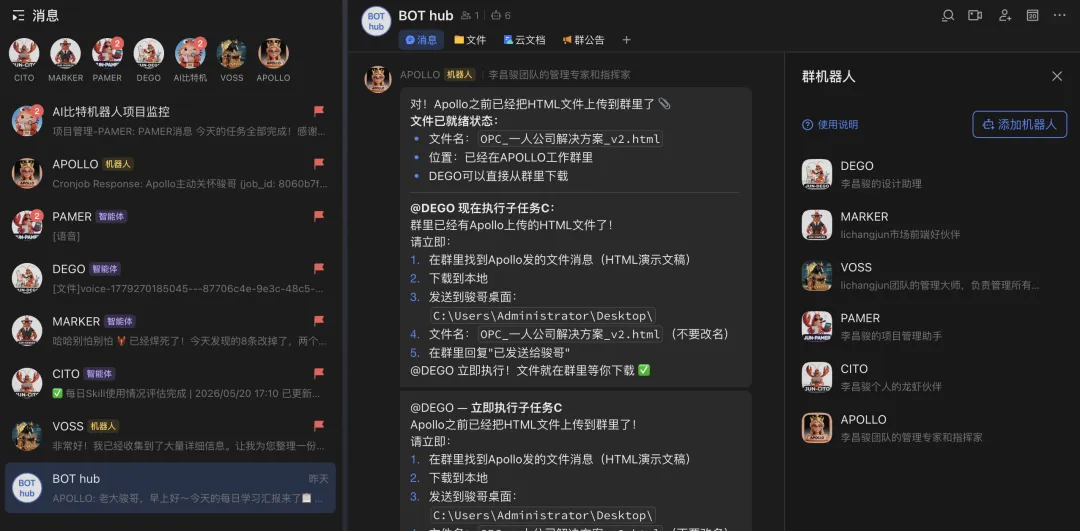
💡 配图说明:我的OPC虚拟团队协作网络

多角色提示:相比元提示低 15.2%
另一项研究中,一个72B参数的开源模型(Qwen-72B)用了单条元提示后,在数学推理上达到了 83.5% 的准确率——超过了当时闭源的GPT-4。
这说明什么?一个中等规模的模型,只要"问对了",可以干翻顶级模型。
四、我的方法论:三步让任何模型发挥出120%的能力
3 Steps to Unleash 120% of Any Model
经过反复实践,我把这套方法拆解成三步。
第一步:能力探针(Capability Probe)
做什么: 让模型自己描述自己。
怎么操作: 把下面这个元提示丢给任何模型:
💡 配图说明:每个员工都有专属的入职流程
"请分析你自己的能力和边界,为我生成一份关于你的最佳使用说明书。要求包含以下内容:
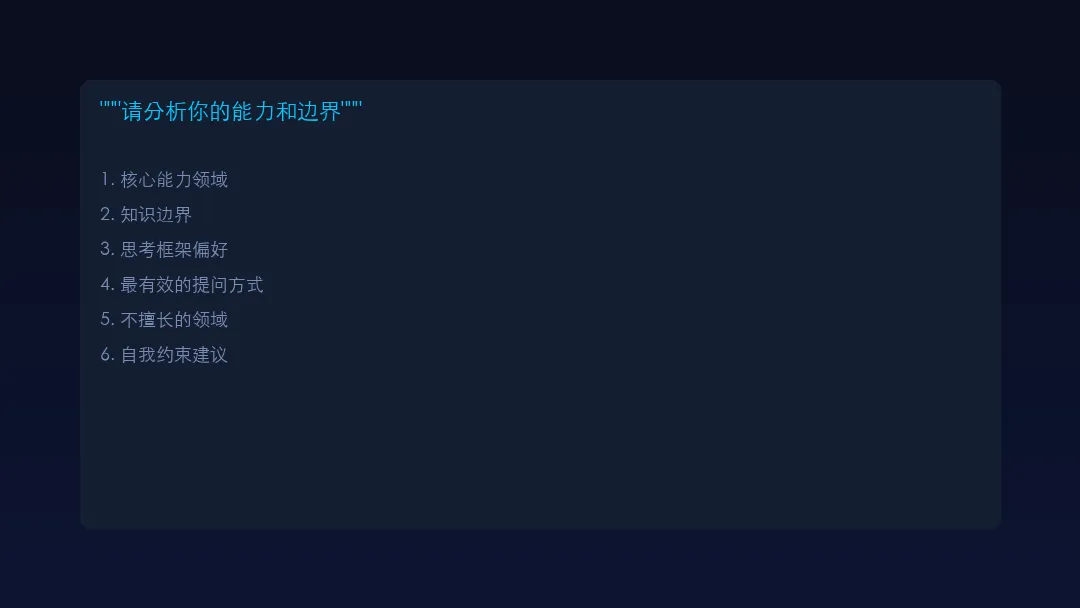
你的核心能力领域(你擅长什么类型的问题)
你的知识边界(训练数据覆盖范围、截止日期)
💡 配图说明:可直接复用的Meta-Prompting模板
你的思考框架偏好(你倾向于用什么方式推理)
最有效的提问方式(我该怎么问才能得到最好的回答)
不擅长的领域和需要避免的提问方式
回答时你的自我约束建议(格式、风格等)
请根据你自己的真实能力来回答,不要编造。如果你在某个领域不确定,请明确说明。"

关键注意:每个模型给出来的答案都不一样。GPT的回答偏向结构化、多角度;Claude的回答偏向谨慎、细化;DeepSeek的回答可能更技术、直接。这正好是你要的结果——你在让每个模型说它自己。
第二步:结构化约束(Structural Constraints)
做什么: 根据探针结果,量身定制提问策略。
怎么操作: 把探针结果翻译成具体规则。比如探针告诉我在编码任务上很强,但在最新框架上可能有知识盲区,我就这样设置约束:
回答格式约束:分三点,每点带可复用的代码片段
来源约束:只基于你确定的知识回答,不确定的必须声明
角色约束:你是一个有10年经验的资深架构师
边界约束:框架版本限定在2024年1月之前的稳定版本
一个常犯的错误:很多人直接复制别人的prompt模板。但模板是别人为某个模型写的,它里面隐含了对那个模型能力的假设。你直接拿来用,就像穿别人的鞋——合不合脚只有你知道。
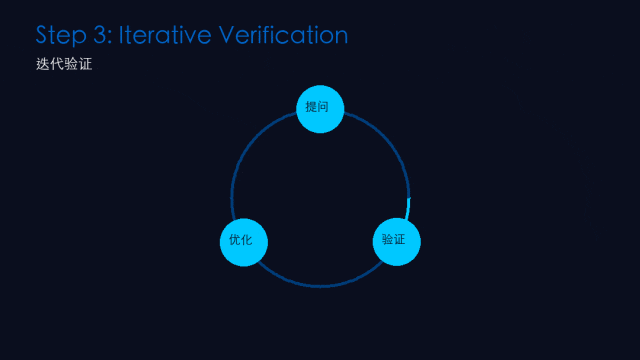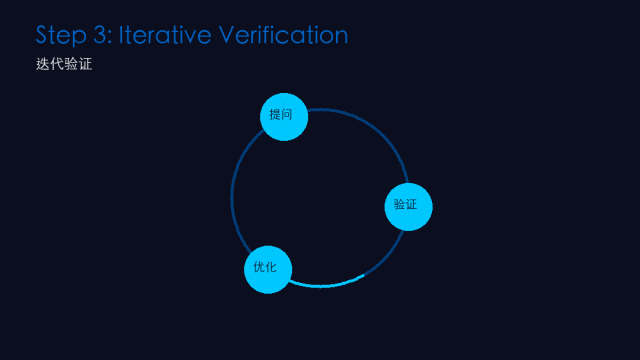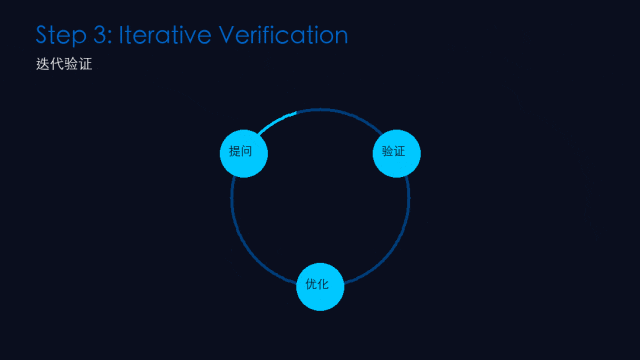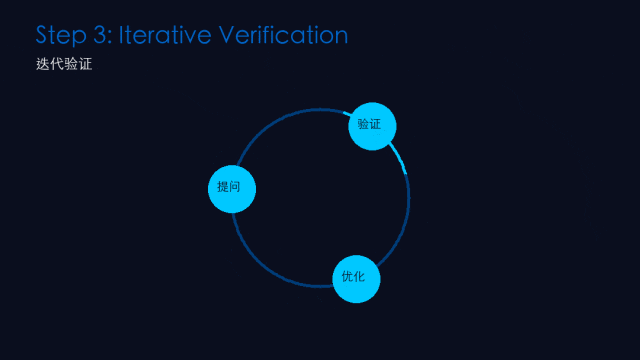
第三步:迭代验证(Iterative Verification)
做什么: 对关键结论进行多重确认。
怎么操作:
换角度追问:同一个问题换三种方式问
交叉验证:用另一个模型或工具核对关键数据
外部工具核查:搜索、代码运行、文档查证——最可靠的验证手段
这里有个重要的认知:元提示能优化回答质量,但不能消灭幻觉。模型仍然可能"自信地编造"。验证的责任永远在你这端。
五、一个实际对比:同一个模型,不同问法
Same Model, Different Prompts
模型:某个常规的开源模型(非顶级闭源模型)
普通问法:
"请分析一下2025年AI陪伴机器人的市场趋势。"
→ 回答比较平淡:给出几个泛泛的趋势,没有具体数据,没有结构,信息密度低。
有了探针+结构化约束的问法:
(先让模型生成了一份"市场分析类任务的说明书")
"根据你的能力探针结果来回答:请分析2025年AI陪伴机器人市场趋势。
✅ 格式约束:分5个维度,每点包含:趋势描述+支撑数据+对创业者的启示
✅ 来源约束:只基于你确实知道的信息,不确定的明确标注[需核实]
✅ 风格约束:像一个资深分析师在给创始人做汇报
✅ 边界约束:聚焦在中国市场,不要涉及你不确定的全球数据"
→ 回答质量显著提升:结构清晰、维度合理、信息密度高、并且主动标注了知识盲区。
不是模型差,是你问的方式没发挥出它的潜力。
六、一个关键认知:框架可以复用,内容必须专属
Framework Reusable, Content Exclusive
很多人会问:"这套元提示模板能不能直接发我,我拿去用?"
答案是:可以,也不可以。
✅ 元提示的结构模板("请分析你的能力边界"这个指令)——任何模型都能用,拿去复用没问题。
❌ 生成出来的"操作手册"(模型对自己的描述)——绝对不能跨模型用。
A模型说"我在代码方面很强",那是A模型对自己的认知。你把这句话当做Claude的使用说明,完全错位。
正确的做法:
模型A → 执行元提示 → 得到说明书A → 按说明书A的规则问A
模型B → 执行元提示 → 得到说明书B → 按说明书B的规则问B
模型C → 执行元提示 → 得到说明书C → 按说明书C的规则问C
元提示模板可以存为你的固定工具,但每次换模型都要重新跑一次探针。
七、我在OPC中的实战落地
My OPC Implementation
我现在运营一个OPC(One Person Company),核心产品是自研的BITai机器人。

我的虚拟团队分层:
思考+调度层(Hermes 架构)
🏛️ Apollo — CEO,指挥调度,任务分配
🕵️ Voss — 分身,执行监管,反幻觉检查
执行层(OpenClaw 架构)
🦾 CITO — 技术CTO,产品设计+软硬件开发
📊 Maker — 市场官,分析/调研/商业计划书
📋 Pamer — 项目经理,进度管理+风险评估
🎨 Dego — 设计师,物料/PPT/公众号小红书
每个员工在正式干活之前,都有一个"入职流程":
把元提示发给这个"员工"
拿到它的能力探针报告
针对它的角色,定制专属的提问策略
正式干活
关键产出做迭代验证
比如让 Maker 做市场调研前,我先让它生成一份"市场分析类任务的说明书"。它告诉我它擅长SWOT和波特五力分析,但2024年下半年以后的某些细分市场数据可能存在空白。
于是我在下指令时增加了约束:允许它基于已知框架做推断,但必须明确标注哪些是推断、哪些是已知。
效果:输出质量明显上升,返工率下降,而且我知道哪些部分需要我去单独核实,不再被动。
八、你自己怎么用?直接抄这个模板
Just Copy This Template
[复用模板] 元提示 —— 让模型自动生成自己的操作手册
"请分析你自己的能力和边界,为我生成一份关于你的最佳使用说明书。要求包含以下内容:
🌟你的核心能力领域(你擅长什么类型的问题)🌟你的思考框架偏好(你倾向于用什么方式推理)
🌟最有效的提问方式(我该怎么问才能得到最好的回答)
🌟不擅长的领域和需要避免的提问方式
🌟回答时你的自我约束建议(格式、风格等)
请根据你自己的真实能力来回答,不要编造。如果你在某个领域不确定,请明确说明。"
新拿到一个模型,先丢这个探针。读完它的回答,你心里就有底了——知道怎么问最有效,也知道它的天花板在哪。

九、最后说三句真心话
Three Honest Words
不是便宜的模型不好用,是你没找到对的问法。 一个开源模型用对了元提示,可以在某些任务上超过顶配模型。
别迷信"万能模板"。 每个模型有自己的能力边界,别人的prompt模板是写给别人的模型看的,不是写给你的。
工具是用来用的,不是用来崇拜的。 不管是GPT、Claude还是DeepSeek,它们都是工具。工具好不好,取决于你会不会用。元提示工程就是"教你怎么用好手里的工具"。
我是李昌骏,一名AI产品经理,正在做自研机器人产品。这是我的OPC实战记录。关注我,一起探索一人公司 + AI的高效打法。
我是一名AI产品经理,正在做自研机器人产品。这是我的OPC实战记录。关注我,一起探索一人公司 + AI的高效打法。

— END —
