 夜雨聆风
夜雨聆风AI 测试观察|测试思维|质量工程实践
比用例数量更重要的,是测试能不能说清楚:这次我们验证了什么风险,哪些风险还没验证,为什么当前结论可以支撑发布判断
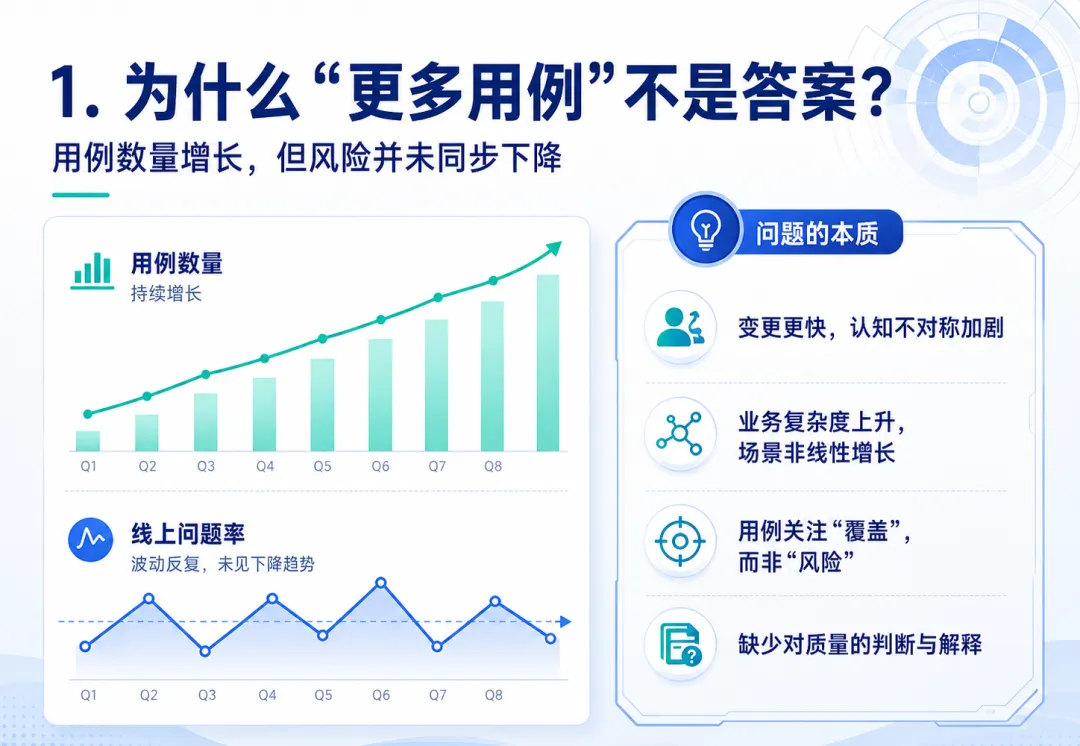
AI coding 让开发交付速度变快,这是事实。但测试真正被放大的压力,不只是“要测的东西变多了”,而是“变更更频繁、影响更隐蔽、判断时间更短”。这时候,测试如果只是继续堆用例,很容易陷入另一种低效:用例越来越多,但团队仍然说不清楚质量风险在哪里
过去我们经常把测试工作拆成几个动作:理解需求、写用例、执行用例、提 Bug、回归验证。这个流程没有问题,但在 AI 参与研发之后,它会暴露出一个明显短板:如果测试只停留在执行层,面对更快的研发节奏,很容易变成被动补位。
所以这篇文章不继续讲“怎么从 Diff 里拆测试点”。上一篇已经把这个方法讲得比较完整了。今天想换一个更靠后的问题:当测试点已经越来越多、自动化脚本也越来越多之后,测试还缺什么?
我的答案是:测试要补上的不是更多用例,而是可解释的质量校验能力
一、为什么“多写用例”解决不了 AI 提速后的测试压力?
很多团队面对研发提速后的第一反应,是增加用例数量。需求多了,就多写几条;接口变了,就多补几条;页面改了,就多加几条自动化脚本。
这个动作本身没有错,但它只能解决一部分问题。因为用例数量增加,并不天然等于质量风险降低。
风险提示
如果测试团队只关注“我补了多少用例”,很容易忽略另一个问题:这些用例到底覆盖了哪些风险?还有哪些风险没有被验证?当前测试结论能不能支撑发布?
AI 生成代码带来的风险,往往不是简单的“功能没实现”,而是更细碎、更隐蔽:
这些问题不是简单多写几条主流程用例就能解决的。它们需要测试工程师把“用例”升级成“风险验证证据”
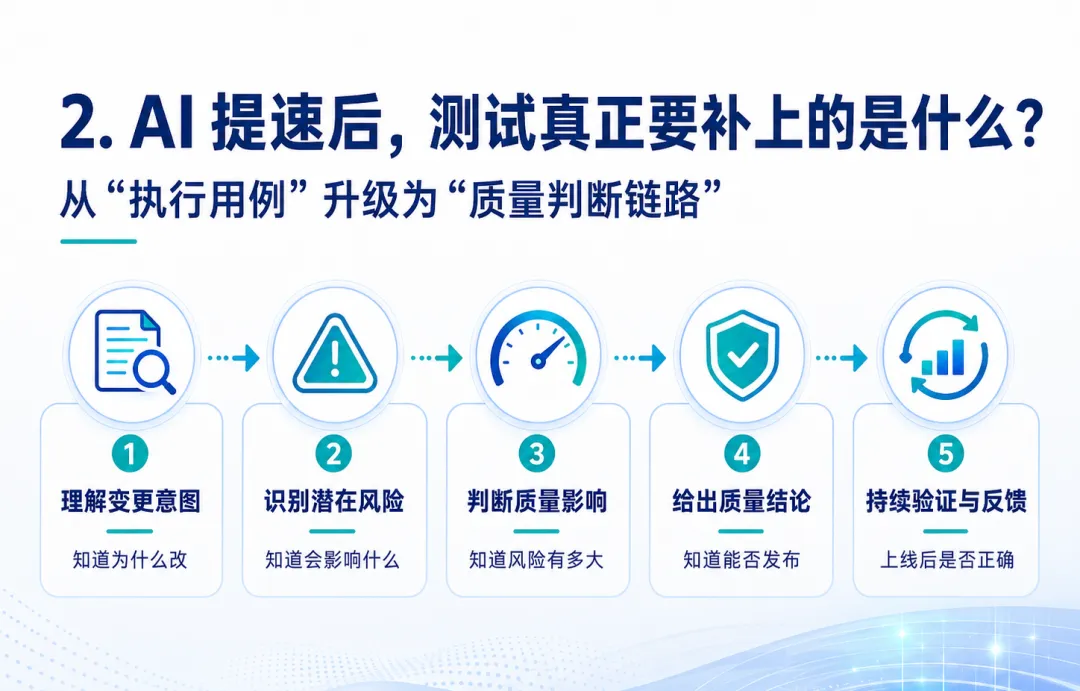
二、测试真正要补的是“质量判断链路”
所谓质量判断链路,不是一个很复杂的平台概念。它可以理解为测试在发布前必须回答清楚的四个问题:
很多测试报告的问题就在这里:它能告诉你执行了多少用例,通过了多少用例,却说不清楚风险是否被覆盖。最后发布会里大家还是要靠经验问一句:“这个影响大不大?”

两种测试思路的差异
三、可解释的质量校验,至少要补五层
如果把测试工作从“执行用例”往前推一层,就会发现真正值得沉淀的不是一堆测试步骤,而是下面五类信息。
每条关键用例最好能说清楚:它在验证什么风险。比如不是“提交订单成功”,而是“验证优惠、库存、支付金额在组合场景下的一致性”
不要只验证页面提示或接口状态码。关键业务要看数据库、缓存、消息、日志、账户流水、状态机是否一致
新数据能跑通不代表老数据安全。测试要特别关注历史状态、空字段、脏数据、重复数据、边界金额、老版本客户端数据
接口返回成功只是开始。异步任务、MQ、定时任务、缓存刷新、第三方回调、补偿逻辑,都可能是质量风险点
测试报告不能只写“通过”。更好的表达是:主要风险已验证,某些风险未覆盖,需要灰度观察哪些指标

四、AI 可以帮测试,但不要让 AI 替你做质量判断
AI 很适合做两类事情:归纳信息和提出盲区。比如把需求、接口文档、历史 Bug、已有用例、执行结果放在一起,让 AI 帮你检查测试方案有没有明显缺口。
但这里要注意一个边界:AI 可以给建议,不能替测试拍板。因为是否能发布,最终取决于业务风险、用户影响、灰度策略、补偿方案和团队对当前风险的接受程度。
Prompt 模板:让 AI 帮你评审测试方案,而不是只生成用例
你是一名资深测试架构师。 请根据下面的需求说明、接口文档、历史线上问题和当前测试方案,评审本次测试设计是否足以支撑发布判断请重点分析: 1. 当前测试方案覆盖了哪些核心业务风险 2. 哪些风险只有步骤覆盖,但缺少有效断言 3. 哪些异常场景、老数据场景、权限场景、灰度场景可能遗漏 4. 哪些用例看起来重复,实际价值较低 5. 哪些地方需要补充日志、数据校验或线上观察指标 6. 当前测试结论是否可以支撑发布,如果不能,还缺少什么证据 输出格式: - 已覆盖风险 - 覆盖不足风险 - 建议补充验证 - 建议删除或合并的低价值用例 - 发布前必须确认的问题 - 灰度观察指标建议 要求: - 不要泛泛而谈 - 不要只增加用例数量 - 重点说明为什么这些风险值得验证 - 输出内容要能直接用于测试评审
这里有一个很实用的转变:
不要总是问 AI:“帮我生成测试用例。”更值得问的是:“请评审我的测试方案还有哪些风险没有解释清楚”
五、测试报告也要从“结果记录”升级为“风险说明”
很多团队的测试报告长这样:执行了多少用例,通过多少,失败多少,遗留多少 Bug。这个报告可以记录结果,但不一定能帮助决策。
更适合 AI 时代的测试报告,应该多补几类信息:
质量报告字段建议
这样做的好处是,测试不再只是“告诉大家我测完了”,而是能告诉团队“为什么当前质量是可接受的,哪些地方还需要继续盯”。
六、从明天开始,可以先改三个小动作
这件事不一定要先做一个很大的平台。对多数测试团队来说,可以先从三个小动作开始
不要只写操作步骤,要写清楚这条用例是为了防什么问题
没测到的地方要写出来,方便产品、开发、测试一起判断是否接受
不是让 AI 直接替你生成一堆用例,而是让它帮你检查有没有遗漏风险、重复用例和无效断言

结尾总结
AI 让研发更快之后,测试当然也需要提升效率。但更重要的是,测试不能只追求“我写了更多用例、跑了更多脚本”
真正能体现测试价值的,是你能不能把风险讲清楚,把验证证据讲清楚,把发布建议讲清楚
用例是测试资产的一部分,但不是全部。AI 时代更需要的测试能力,是可解释的质量校验能力
可直接沉淀的小检查清单
发布前,测试报告里至少回答这 5 个问题:
1. 本次变更最核心的业务风险是什么?2. 这些风险分别用了什么方式验证?3. 哪些风险没有覆盖,原因是什么?4. 当前遗留问题是否影响发布判断?5. 发布后需要重点观察哪些数据或日志?
如果这篇文章对你有帮助,欢迎关注我。
这里会持续分享 AI 测试、测试开发、代码 Diff 风险分析、质量工程和测试人成长 相关内容,尽量写得真实、可落地、能直接用。
