 夜雨聆风
夜雨聆风上篇聊了LLM应用技术栈的7层结构,感兴趣的可以看看Andrej Karpathy 也认同的 LLM 应用技术栈分层是什么样?其中,第一层是基础大模型。说到大模型,我有时候会想一件很奇怪的事。
你现在打开 Claude 或者 ChatGPT,用一句话跟它聊天,它能用你能看懂的语言回你,能理解你话里的语气,甚至能感觉到你今天心情好不好。
这件事,太震撼了!
震撼的同时,当你真正想清楚这背后经历了什么,你会意识到,我们现在活在一个密度极高的历史时刻里。
这个时刻,是几代人用几十年的时间,踩着无数个错误和沮丧,一点一点堆出来的。
今天,咱们一起回看一下这段历史。
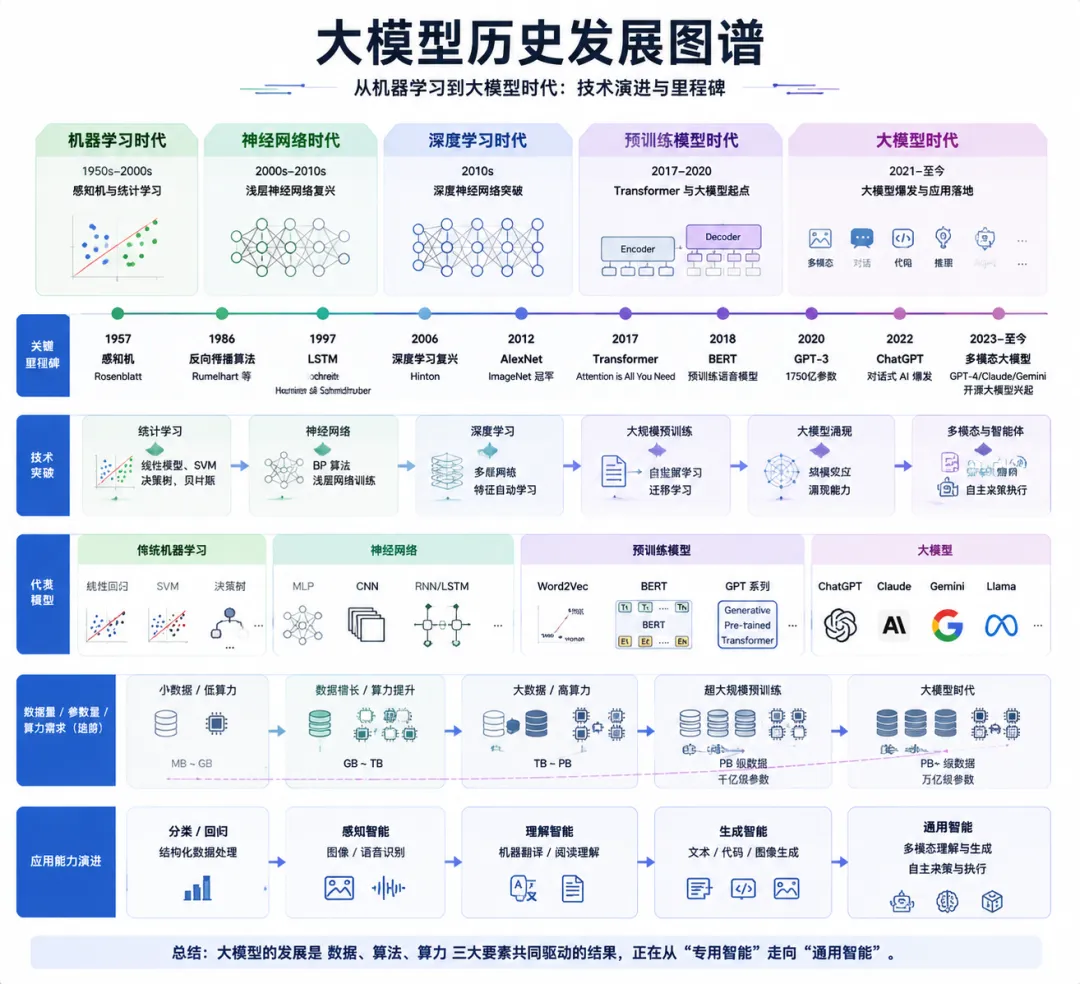
有趣的故事,要从1956年说起。
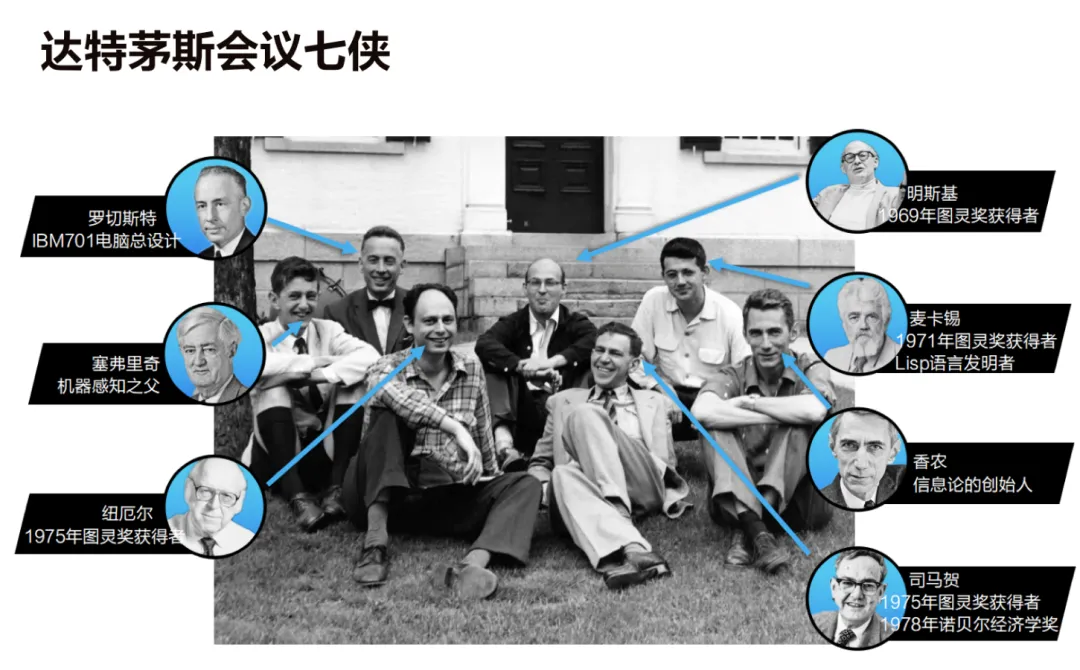
那年夏天,美国达特茅斯学院开了一个研讨会。当时聚集的都是一群对计算机痴迷的年轻人,其中有个叫约翰·麦卡锡的,他提出了一个词,「人工智能」。
就这样,这件事有了名字。
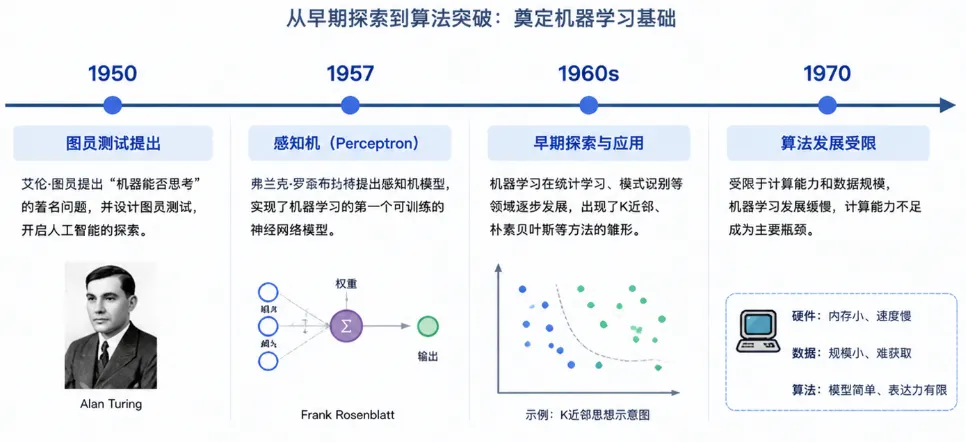
那个年代的人对 AI 的想象,更接近科幻片里的机器人,能下棋,能解数学题,能和你对话。
研究者们在搞一种叫「专家系统」的东西,就是把人类专家的知识硬编码进去,规则写死,让机器按规则走。
效果确实有一些,但问题也很明显,规则永远写不完。
你不可能把世界上所有的逻辑都人工穷举出来。
这条路,走了几十年,基本上就撞墙了。
研究经费被砍,AI的冬天来了,不是一次,是两次。
那段时间研究者们大概是有点绝望的,干着干着发现,这玩意好像没有想象中那么简单。
然而,历史的脚步不会停歇,机器学习出现了!
机器学习这个转变,现在回看,有点像一次哲学层面的革命。
以前的路是,人告诉机器「规则是什么」。
机器学习说,算了,别告诉它规则了,给它数据,让它自己去学。
你给机器看一万张猫的照片,再给它看一万张狗的照片,让它自己找规律,最后它能分辨猫狗。你不需要告诉它「猫有尖耳朵、猫有胡须」,它自己总结出来了。
这个思路在八九十年代逐渐成熟,各种算法冒出来,决策树、支持向量机、随机森林,都是这个时期的产物。
但有一批研究者,对这些不满意。
他们盯着人类的大脑,想,为什么我们学东西那么快,那么灵活?那里面有什么秘密?
他们开始模拟人类的思考,梦想者创造出电子神经元。
神经网络的故事,是这段历史里最让我觉得感慨的部分。
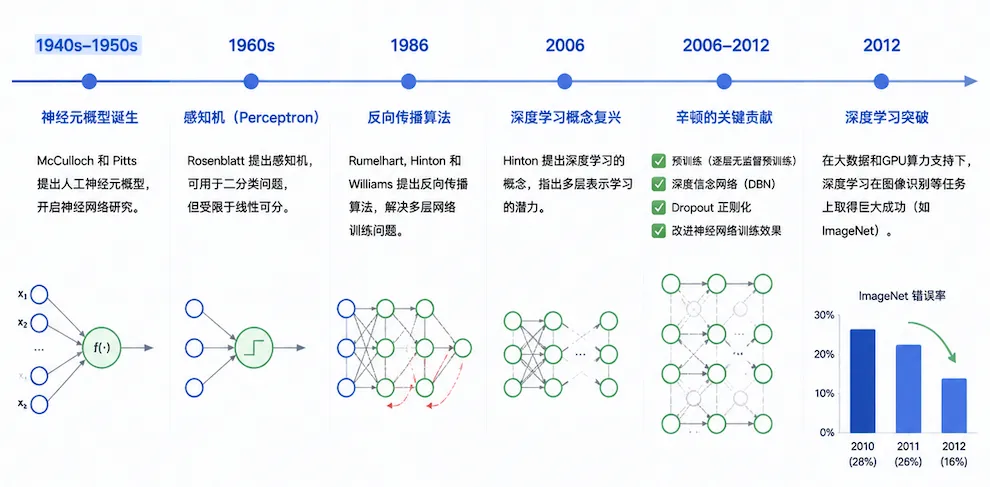
1943年,还没有麦卡锡提出AI这个词的时候,两个人,麦卡洛克和皮茨,就发表了一篇论文,试图用数学来模拟神经元。
这之后几十年,各种人在这个方向上摸索。
到了1980年代,有个东西叫反向传播算法被推广开来,神经网络总算有了一种能让自己变聪明的方法,通过不断试错,调整参数,往正确答案靠近。
但神经网络一直有个死穴,算力不够。
你要训练一个有很多层的网络,计算量是指数级增长的,那时候的计算机根本撑不住。
所以神经网络在很长一段时间里是个「看起来很美但跑不起来」的东西,学术界觉得它太慢太难训练,大家都转去搞其他方法了。
坚持下来的人很少。
辛顿是其中一个!

Geoffrey Hinton这个人,你现在可能知道他,2024 年拿了诺贝尔物理学奖,那会儿很多人说他是「AI教父」。
但在很长一段时间里,他是那种被主流嫌弃的研究者。
他一直相信神经网络是对的路,哪怕整个领域都在往别处走,哪怕开会的时候别人觉得他在搞一个没有前途的东西,他还是在搞。
2006年,他提出了深度信念网络,给深度学习的复活打了第一针。
2012年,他的学生用一个叫AlexNet的深度神经网络,参加了ImageNet的图像识别比赛,把识别错误率从26%降到了16%,比第二名低了将近10个百分点。
这个成绩出来的时候,整个计算机视觉领域愣住了。
那一年,被很多人称为「深度学习元年」。
从那之后,事情开始加速。大家突然意识到,原来这玩意真的行,只是以前算力和数据都不够。
现在GPU可以并行计算,互联网上有海量数据,那,来吧。
深度学习爆发之后,各种任务上的成绩开始被一个接一个地刷新。
图像识别、语音识别、机器翻译,一个一个被干翻。
但自然语言学习,是最难的那个。
自然语言太复杂了。「我没有说他偷了那本书」,这句话如果重音落在不同位置,意思是完全不同的。上下文、语气、常识、文化背景,全都揉在里面。
处理自然语言的早期模型有个痛点:
它们很难处理长距离的依赖关系。
比如一句话说了很长,开头提到的东西,结尾要用,这对早期的循环神经网络是一个很大的挑战。
2017年,谷歌的研究者们发了一篇论文,标题叫「Attention is All You Need」。
就是这篇论文,把一个叫Transformer的结构带进了世界,也把整个自然语言AI的历史,从此劈成了两半。
Transformer的核心思路是注意力机制,我用大白话讲一下。
处理一个句子的时候,不是把它从头到尾顺序过一遍,而是让每个词去「看」句子里所有其他的词,判断哪些词和自己最相关,然后根据这个相关程度来理解自己的含义。
这就是「注意力」。
你在理解一句话里的某个词时,你的注意力会更多地放在那些对理解它有帮助的其他词上。
这个机制让模型能更好地捕捉上下文,而且天然适合并行计算,能把模型做得很大。
接下来发生的事情,就有点像滚雪球了。
2018年,谷歌发布BERT,在一系列语言理解任务上碾压了所有人。
同年,OpenAI发布了第一代GPT。
然后,GPT-2,GPT-3,参数规模从一亿,到十亿,到一千七百五十亿。
GPT-3 的出现是跨时代的!伴随它的 ChatGPT ,让普通人也能和 AI 聊天了!
2025 年,多模态能力大幅提升,不止能读懂语言,还能看懂图!甚至,Deepseek 抛出了重炮炸弹 Deepseek-v3 开源模型!当时,全国,不全世界都疯狂了!技术平权要来了!
到了 2026 年,大模型的能力好像用在了自我进化上,疯狂地往前狂奔!Claude opus 4.7刚发布,GPT 5.5 紧接推出,国内的Deepseek-v4 也再次展现开源模型的强大!
我有时候觉得,大模型这件事,不只是技术的胜利,它背后有一个深刻的赌注被证明是对的,
那就是,规模,是有意义的。
这个赌注在早期是充满争议的。更大的模型,更多的数据,更多的算力,真的会让模型更智能吗?还是说到某个点会遇到天花板?
事实证明,这个赌注是对的,而且还没看到清晰的天花板。
这很难用传统的工程思维解释,感觉更像是,量变引起了质变。
你越用大模型,它学习的越多,全世界都帮助它们疯狂成长!
好,说到这里,我想停一下,聊点我自己的感受。
做了十多年软件架构,我见过太多技术浪潮了。SOA、微服务、容器化、Serverless,每一波出来的时候都有人说「这次真的不一样」,然后你跟着评估,跟着落地,跟着踩坑,最后发现,它确实有用,但也没那么神,世界缓慢地变了一点点,然后又平静下来。
所以我不是那种容易被一项技术搞得很激动的人。
但这段历史看完,我有个感觉,跟以前不一样。
以前的每一次技术革命,改变的是系统的「结构」。
微服务让系统拆得更细,容器让部署更灵活,云计算让资源按需取用。
这些变化,工程师需要重新学,但那个「我在设计一个系统」的感觉没变,还是你在画架构图,你在决定数据怎么流,你在定接口协议。
大模型改变的是另一层,它把「意图」和「实现」之间的距离,压缩了。
一个十年前的架构,从需求到设计到编码到测试,每一步都需要人把「想要什么」翻译成「机器能理解的语言」。这个翻译过程,就是我们这些工程师存在的核心价值。
现在有点不一样了。你用自然语言描述需求,它能给你出一个可以跑的原型。你不满意,你继续说,它继续改。这个过程里,「翻译」这件事,它开始能参与了。
我不是说这会让架构师消失,我是说,这一次动的是更底层的东西,是「人和机器之间的接口」本身。
这对我来说,比任何一次我见过的技术变革,都更难预测它的边界在哪里。
那,了解这段历史,对我们来说意味着什么?
我想抛几个问题,大家一起来想一想。
第一个,我们正在经历的这一刻,在技术史的坐标上,大概在什么位置?
你可以类比1990年代初的互联网,当时浏览器刚出现,大多数人不知道互联网能干什么,但有一批人,开始模糊地感觉到,这个东西会改变很多事。
那些人,后来都去做了什么?
第二个,技术的进步,从来不是线性的,也从来不是顺滑的。
神经网络被抛弃过,AI有过两个冬天,辛顿坚持了几十年才被认可。那些看似「走进死路」的阶段,往往只是当时算力和数据跟不上,而不是方向本身是错的。
那今天,你觉得,哪些「现在看起来没用」的方向,可能只是在等待它的时机?
第三个,也是最让我个人着迷的,
这段历史里,真正推动事情往前走的,从来不是「大多数人觉得对的方向」。麦卡锡他们当年推的专家系统,是主流,后来被机器学习颠覆。深度学习在2000年代是边缘研究,2012年之后突然成了一切。
什么时候应该相信主流,什么时候应该赌一个「现在是少数派但我觉得是对的」的方向?
这个问题,我没有答案。但我觉得,你知道这段历史之后,再来想这个问题,会想得更扎实一些。
你用的 AI,其实已经等了你七十年。
从达特茅斯那个夏天,到2012年的AlexNet,到2017年的Transformer,到现在你打开手机跟它说话,每一步都有人在某个地方,咬着牙,做别人觉得没意思的事情。
这一段,我觉得值得记住。
不是因为要感恩,而是因为,咱们接下来要做的任何一件事,也是这段历史的延续。
大时代啊,朋友们。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。
