夜雨聆风
夜雨聆风
(本文阅读时间:8分钟)
“医生,我这个片子到底有没有问题?”
这可能是在医院的诊室里经常听到的一句话。面对一张复杂的医学影像,医生不仅要给出“是与否”的答案,更需要向患者解释诊断的依据:这个阴影是什么?为什么怀疑是肿瘤?具体的医学证据在哪里?而在面对疑难杂症或复杂病症时,还需要多个科室的专家联合会诊,才能形成更严谨、准确的诊断结论。
近年来,具备图像理解能力的视觉语言模型(VLM)开始在医疗诊断方面展现潜力。但现有的AI模型多以“黑盒”方式运行,或只给出猜测性的推理,这会不可避免地遭受大模型幻觉的困扰,无法给出事实性依据,更不能像临床医生一样分析影像特征并给出诊断依据。这种“只给答案、不做举证”的模式,无法满足医疗场景对可信性与可解释性的要求,因此很难获得医生与患者的充分信任。此外,单一功能的视觉大模型也难以覆盖内科、外科、影像科等全专科场景,跨科室协同诊断的能力十分薄弱。
针对这些问题,微软亚洲研究院联合多所高校,深入研究临床医生的真实诊断逻辑,设计并推出了两个医疗智能体框架——CARE与MMedAgent-RL。其中,CARE致力于让AI在像素级主动寻找并验证医学证据,提升诊断过程的可解释性与可信性;MMedAgent-RL则模拟真实世界中的多学科会诊(MDT)机制,通过强化学习优化多专家协作决策能力。
这两个框架的提出,不仅推动医疗AI从“给答案”走向“会举证、能协作”,也为更广泛的AI应用探索出一条更加可信、可循证的新路径。
相关论文已被ICLR 2026接收,具体信息整理于文末,欢迎点击相关链接,了解更多技术详情。
在医疗影像诊断中,关键信息往往隐藏在细微的区域,例如肺部CT扫描中一个几毫米的结节,或是皮肤镜图像中一处细微的色素变化。
而通用视觉大模型在处理这类影像时,多采用端到端理解模式,跳过了关键的病灶定位环节。图像被压缩至固定分辨率后,模型极易忽略仅数个像素大小的病灶,进而出现“捷径学习”(即模型依据无关特征而非病理特征做出判断),或是产生“幻觉”(即编造不存在的病灶)等严重问题。
微软亚洲研究院提出的CARE智能体框架(Clinical Accountability in multi-modal medical Reasoning with an Evidence-grounded agentic framework),将黑盒式的预测拆解为类似临床医生可验证的“观察-定位-诊断”循证流程。
CARE不是依赖单一功能的模型,而是设计了一个由“协调员”(coordinator)智能体调度的多步骤流程。首先,系统会根据用户问题,像医生问诊一样,主动识别可能相关的解剖结构或异常实体(entity),例如“左下肺叶”或“磨玻璃结节”;随后,它会调用专家级分割工具,在医学影像中精准定位并放大对应区域(ROI),类似医生在片子上圈出重点病灶;最后,模型再结合原始全景图像与经过验证的关键区域,完成最终诊断推理。
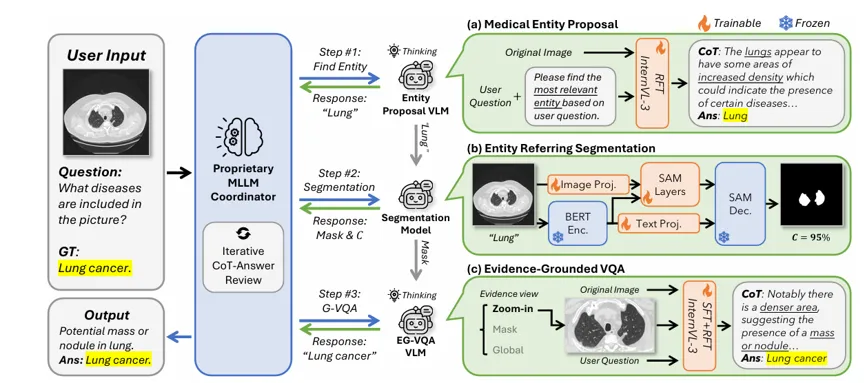
图1:CARE框架概述。CARE智能体框架由一个VLM协调器以及一组任务专用专家模型组成。协调器负责规划工具调用、进行结果审查,并在需要时调用专家模型。专家模型集合包含三类:(1)基于问题条件给出实体建议的VLM,用于识别相关解剖结构与异常病灶;(2)参考分割模型,实现像素级ROI证据定位;(3)循证VQA VLM,依托放大、遮罩或全局标识等视觉证据完成影像推理。
相较于现有方法,CARE不仅在公开评测基准上取得更优性能,还具备更强的可追溯性与可靠性。这一过程为AI诊断构建了一条完整的、可审查的证据链条,有效提升了临床对AI诊断结论的信任度。
如果说CARE解决的是“看得细”的问题,那么MMedAgent-RL则是要攻克“想得全”的挑战。
在真实医疗场景中,疑难杂症的诊断往往不局限于单一科室,需要多学科专家联合会诊。现有的多智能体医疗框架大多采用固定、静态的流程,缺乏应对复杂情况的灵活性。例如,当专家们意见不一致时该如何决断?如果所有专家都出现了误判,又该如何纠正?
对此,多智能体框架MMedAgent-RL模拟真实医院“分诊医生-专科医生-主治医生”的会诊流程,并通过强化学习对这一全链路进行优化,实现了医学智能体间的动态优化协作。
具体而言,系统首先由“分诊”智能体判断病例所属的专业领域;随后,调度对应的“专科医生”智能体(如放射科、皮肤科、病理科AI)给出专业建议;最后,由一位具备全局视野的“主治医生”智能体进行最终“裁决”。
与简单的“少数服从多数”投票机制不同,MMedAgent-RL的核心在于动态权衡。利用强化学习,框架中的“主治医生”能够学会在不同情境下赋予专家意见不同的权重。例如,在处理复杂的软组织病变时,它能够识别出病理学家的意见更具权威性;而在分析骨骼形态时,则会更侧重放射科专家的判断。
更重要的是,面对“真理掌握在少数人手中”甚至“全员误判”的情况,MMedAgent-RL仍具备纠偏能力。为了让框架掌握这种高级协作智能,研究员们引入了课程学习(Curriculum Learning)策略,让AI的训练遵循由易到难的规律:
在训练初期,模型处理的是“专家意见高度一致”的简单案例,建立基础专业认知。
随后进入“专家意见冲突”的中等难度阶段,训练智能体在矛盾中权衡证据的能力。
最后,训练升级到“所有专家均有误”的困难模式,让智能体学会审慎地怀疑与独立纠偏。
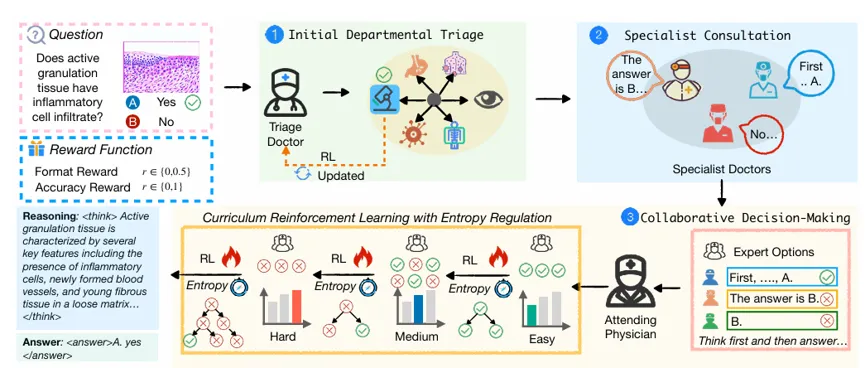
图2:MMedAgent-RL概述。一个专为多模态医学推理设计的基于强化学习的多智能体框架。它模拟了分诊医生—专科医生—主治医生的临床诊断循环流程。首先,框架对分诊医生进行优化以提升分诊准确率;随后,采用高性能的大视觉语言模型(LVLMs)作为各科室的专科医生;最后,结合课程学习与强化学习,逐步训练主治医生,使其能够有效整合专科知识并做出稳健决策。
微软亚洲研究院高级研究员王婧璐介绍道:“这种由易到难的渐进式学习路径,远比直接灌输所有复杂案例数据更为有效。它让AI在习得知识的同时,还具备了可以通过权衡与逻辑推演找到最佳答案的能力,必要时AI甚至可以反驳集体结论,做出独立且正确的判断。”
CARE与MMedAgent-RL的研究,不仅显著提升了AI在医学影像识别上的准确率,更为在广泛行业构建“可靠的AI”探索出了一套全新范式。
通过将临床医生的循证思维、逻辑链条及多科室协作机制进行算法化重构,AI的决策行为得以与人类世界的专业知识体系实现精准对齐。这种从“黑盒预测”向“可验证的透明逻辑”的范式转变,既能有效解决医疗诊断的信任难题,更将为人工智能在更多严苛决策场景中的落地应用提供极具价值的参考基准。
在此基础上,为进一步对齐人类专业知识体系,微软亚洲研究院也在推进医疗领域的AI基准研究。通过构建基于“诊疗指南”(guidelines)的数据集与基准测试,从而确保AI的决策逻辑能够与临床诊疗规范及行业标准严格契合。微软亚洲研究院期望,持续在AI for Health这一最严谨、最严苛领域的技术深耕,可以用健康领域的高标准来反哺与促进AI技术本身的稳健发展。
CARE: Towards Clinical Accountability in Multi-Modal Medical Reasoning with an Evidence-Grounded Agentic Framework(已被 ICLR 2026 接收)
论文链接:
https://openreview.net/forum?id=whRAOJiyHM
MMedAgent-RL: Optimizing Multi-Agent Collaboration for Multimodal Medical Reasoning(已被 ICLR 2026 接收)
论文链接:
https://openreview.net/forum?id=2awntLXwR6
注:本文所述的微软亚洲研究院在医疗健康领域的研究均为科研探索性质,且均在专业医疗和医学研究机构的合作指导下进行,旨在推动科学进步并为人类未来的医疗健康应用提供理论和技术支持。所有研究均严格遵守微软负责任的 AI 流程的指导,并遵循公平、包容、可靠性与安全性、透明、隐私与保障、负责的原则。文中所提及的技术和方法目前均处于研究和开发阶段,尚未形成商业产品或服务,也不构成任何医疗建议或治疗方案。我们鼓励读者在面对健康问题时咨询合格的医疗专业人士。
你也许还想看: