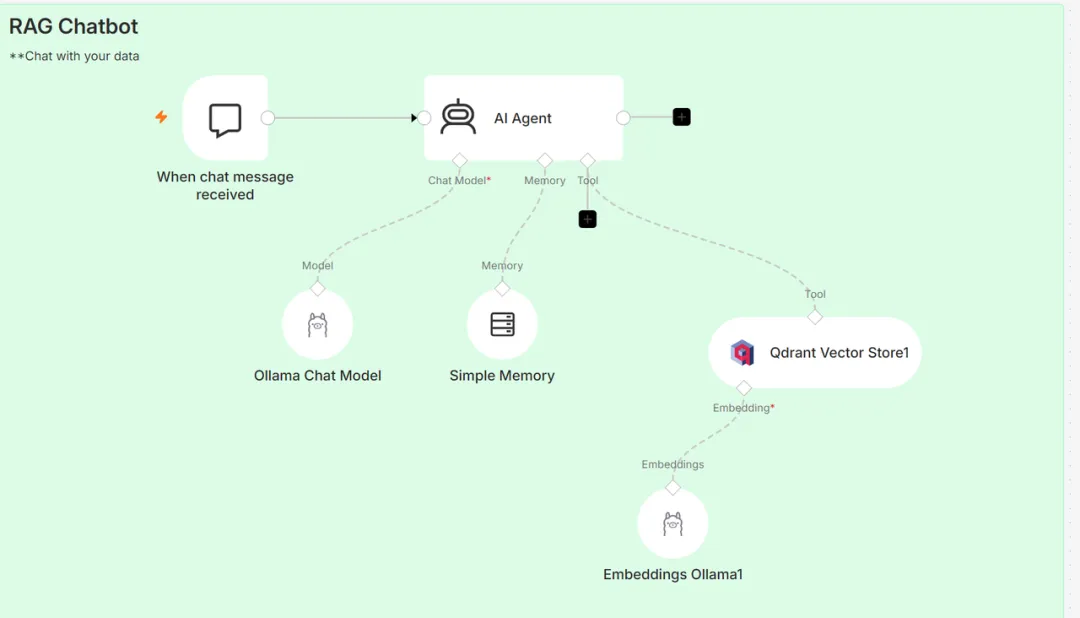
你打开 PDF,Ctrl+F 搜关键词,翻半天,找到几段似是而非的内容; 你丢给在线 AI,又担心文件里有公司资料、客户数据、合同信息; 你想做一个“本地知识库问答机器人”,但一听到向量数据库、Embedding、Agent、RAG,瞬间头大。我们要做的不是一个玩具 Demo,而是一个真正可以本地运行的 PDF 问答机器人:RAG 是 Retrieval-Augmented Generation,中文通常叫“检索增强生成”。先从你的资料库里找相关内容,再让大模型基于这些内容回答。这也是为什么 RAG 比“直接把 PDF 丢给大模型”更适合做企业知识库、个人资料库、合同问答、论文助手。公司文档、客户资料、技术方案、合同条款、财务报告,很多都不能随便上传第三方平台。如果每次问答都走云端 API,文档越多、调用越频繁,成本越高。你不知道模型到底参考了哪些内容,也很难把它接进自己的业务流程里。它的本质不是“又搭了一个聊天机器人”,而是给你的私有资料装了一个大脑。从图里可以看到,整个工作流主要由 5 个部分组成:
- Ollama Chat Model:负责本地大模型回答
- Qdrant Vector Store:负责存储和检索文档向量
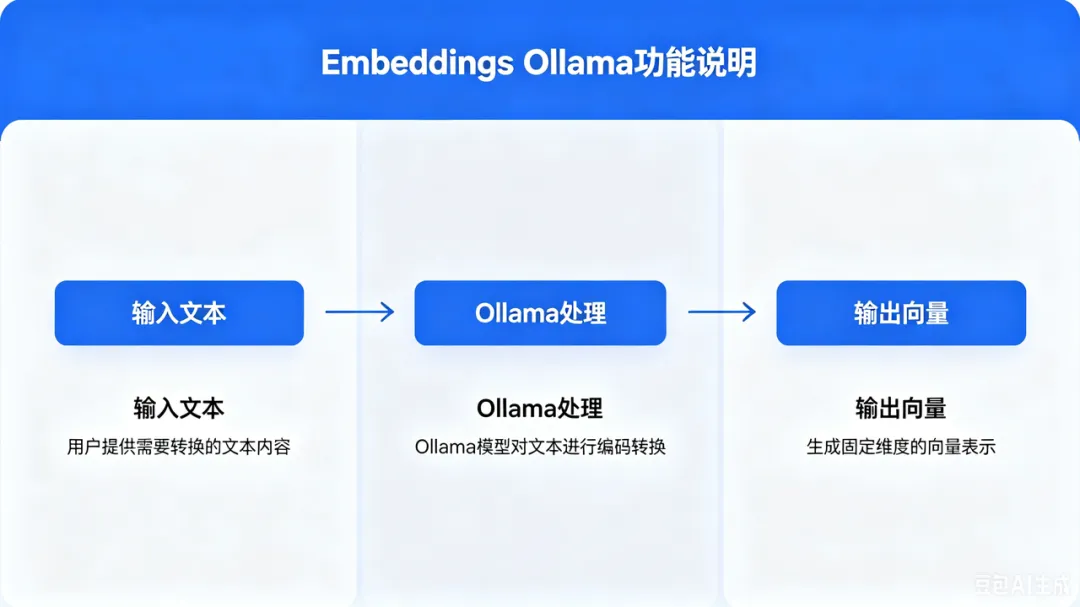
- Embeddings Ollama:负责把文本转成向量
用户提问
↓
n8n 接收消息
↓
AI Agent 判断问题
↓
去 Qdrant 里检索相关 PDF 片段
↓
Ollama 基于检索结果生成答案
↓
返回给用户
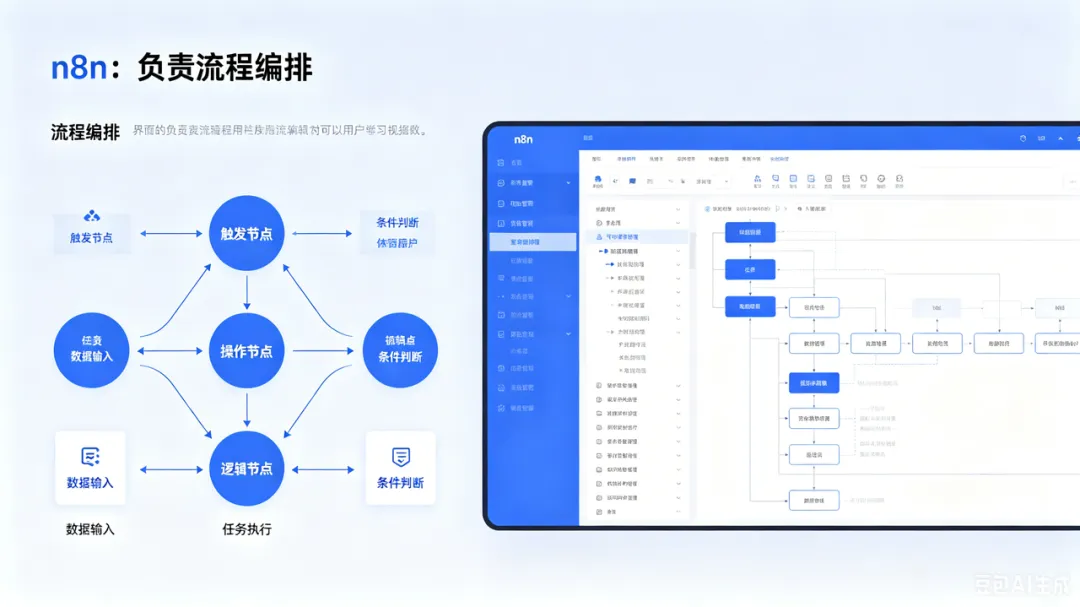
注意,真正的关键点不是“大模型自己知道答案”,而是:很多人一听 AI Agent,就以为要写一堆代码。但 n8n 的好处是:它把复杂流程变成了可视化节点。图中左侧的 When chat message received 就是聊天触发器。中间的 AI Agent 是整个系统的“大脑调度中心”。也就是说,它不只会聊天,还能调用工具、读取记忆、查询知识库。n8n 把 Ollama、Qdrant、Embedding 模型串起来,让它们形成一个完整闭环。没有 n8n,你可能需要自己写后端、写接口、写状态管理。 在自己电脑或服务器上跑一个 ChatGPT 类模型。也就是图里的 Ollama Chat Model。AI Agent 会先从 Qdrant 找资料,然后把资料交给 Ollama,让它组织成自然语言回答。也就是图里的 Embeddings Ollama1。你可以简单理解为:把文字变成一串数字,让机器能判断“语义相似度”。普通关键词搜索可能搜不到,但向量搜索可以找到相关内容。如果说 Ollama 是“大脑”,n8n 是“流程管家”,那 Qdrant 就是“语义图书馆”。它会先把问题转成向量,然后去 Qdrant 里找最相似的内容片段。因为大模型最后回答得好不好,很大程度取决于检索出来的内容准不准。所以,一个 RAG 系统的质量,往往不是只看模型大小,而是看这几个环节:很多人做 RAG 翻车,不是模型不行,而是检索链路没做好。上传 PDF
↓
提取文本
↓
文本清洗
↓
按段落或 token 切块
↓
生成 Embedding
↓
写入 Qdrant
这样后面回答时,既能找到相关内容,也能告诉用户依据来自哪里。用户问题
↓
问题转 Embedding
↓
Qdrant 检索 Top K 相关片段
↓
把片段放进 Prompt
↓
Ollama 生成回答
↓
返回答案和来源
你是一个基于本地知识库回答问题的助手。
请只根据检索到的文档内容回答。
如果文档中没有相关信息,请明确说“资料中没有找到依据”。
不要编造答案。
回答时尽量列出关键依据。
只要你的资料是文本型的,理论上都可以接入 RAG。有些 PDF 是扫描件,里面其实是图片,不是文本。这种情况下需要先做 OCR,否则系统根本读不到内容。RAG 的检索单位是“文本块”,文本块质量决定检索质量。如果你的资料主要是中文,就尽量选中文效果好的 Embedding 模型。如果你不明确要求“基于资料回答”,模型就可能凭自己的知识补充。尤其是合同、医疗、财务、法律类场景,一定要限制幻觉。九、为什么 n8n + Ollama + Qdrant 是普通人最容易上手的组合?你不用一上来就写复杂后端,可以用节点把流程搭起来。不用申请 API,不用每次请求云端,可以直接在本机或内网服务器运行。它专门为向量搜索设计,比你自己拿数据库硬凑要稳定得多。这三者组合起来,刚好形成一个本地 AI 应用闭环:n8n:负责连接一切
Ollama:负责理解和生成
Qdrant:负责存储和检索知识
如果你只是想体验 AI 应用开发,这套方案足够轻量。 如果你想做企业内部知识库,这套方案也有继续扩展的空间。让系统支持多个 PDF、多个知识库、多个业务分类。依据来源:
《项目报告.pdf》第 12 页
《成本分析.pdf》第 6 页
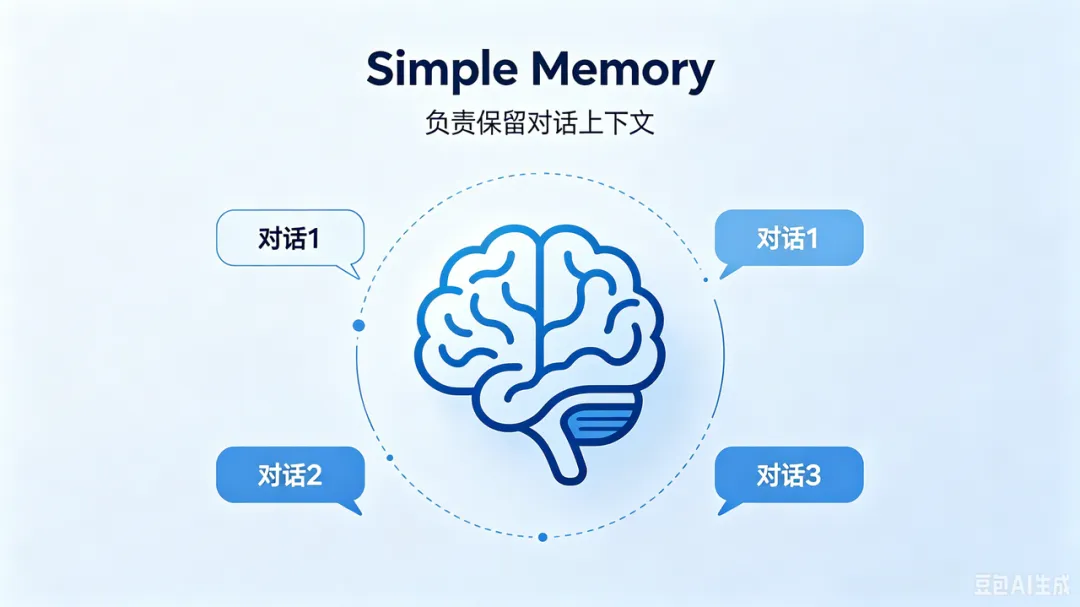
图里的 Simple Memory 就是做这个的。如果没有 Memory,系统可能不知道“第二点”指什么。本地 RAG 真正进入企业场景时,权限是绕不开的。只要有新的 PDF 放进去,就自动解析、切块、向量化、入库。以后你管理知识,是靠语义检索、上下文理解、智能问答。而 RAG,就是这条路上最现实、最落地的方案之一。AI 应用真正的分水岭,已经不是“会不会调用大模型”。n8n + Ollama + Qdrant 这套本地 RAG 方案,最大的价值就在于:它让普通人也能拥有一个私有、安全、可控的知识库机器人。如果你只是把 AI 当聊天工具,它可能只是一个玩具。 但如果你把它接进 PDF、文档、知识库、业务流程,它就会变成生产力系统。 夜雨聆风
夜雨聆风