 夜雨聆风
夜雨聆风如果你以为内容被ChatGPT检索到就万事大吉,那你可能已经输了一半。Ahrefs分析了140万条ChatGPT提示词,发现了一个反直觉的结果:被检索到的页面,最终只有约50%会被真正引用。这意味着什么?
你的内容被AI搜索看到,只是拿到了入场券。能不能进入最终引用列表,才是第二层竞争。
而这第二层竞争,正在重新定义整个内容生态。
被检索≠被引用:AI搜索的双层竞争

第一层:被检索到(入场券)
这是大多数人关注的层面。
你的内容能不能被AI搜索系统找到?能不能进入候选来源池?
传统SEO时代,这对应"能不能被Google抓取和收录"。
AI搜索时代,这对应"能不能被OAI-SearchBot检索到"。
第二层:被引用(真正的战场)
但Ahrefs的数据揭示了一个残酷的事实:
进入候选来源池的页面中,只有约50%最终被引用。
也就是说,差不多一半页面进入了来源池,但没有进入最终引用列表。
这说明了什么?
被收录不等于排名靠前。被检索不等于被引用。
这和传统SEO有点像,但更残酷。
过去你希望自己的页面被Google抓取、收录、排名。今天你可能还要进一步关心:
当ChatGPT、Gemini、Perplexity这类AI搜索系统生成答案时,它会不会把你的页面放进最终引用列表?
这种分层,其实已经体现在OpenAI的爬虫设计里:
OAI-SearchBot 面向搜索可见性 GPTBot 面向训练数据
搜索可见性和训练使用,已经是两件事。
OpenAI自己的web search API文档里,也能看到类似区分:
sources(来源池):模型形成回答时参考过的来源 inline citations(最终引用):最终展示给用户的引用
换成中文,就是:
来源池 ≠ 最终引用。
"模型看过你"和"模型给你署名"之间,还有一层选择。
这层选择,就是AI时代的新战场。
AI搜索的PageRank时刻
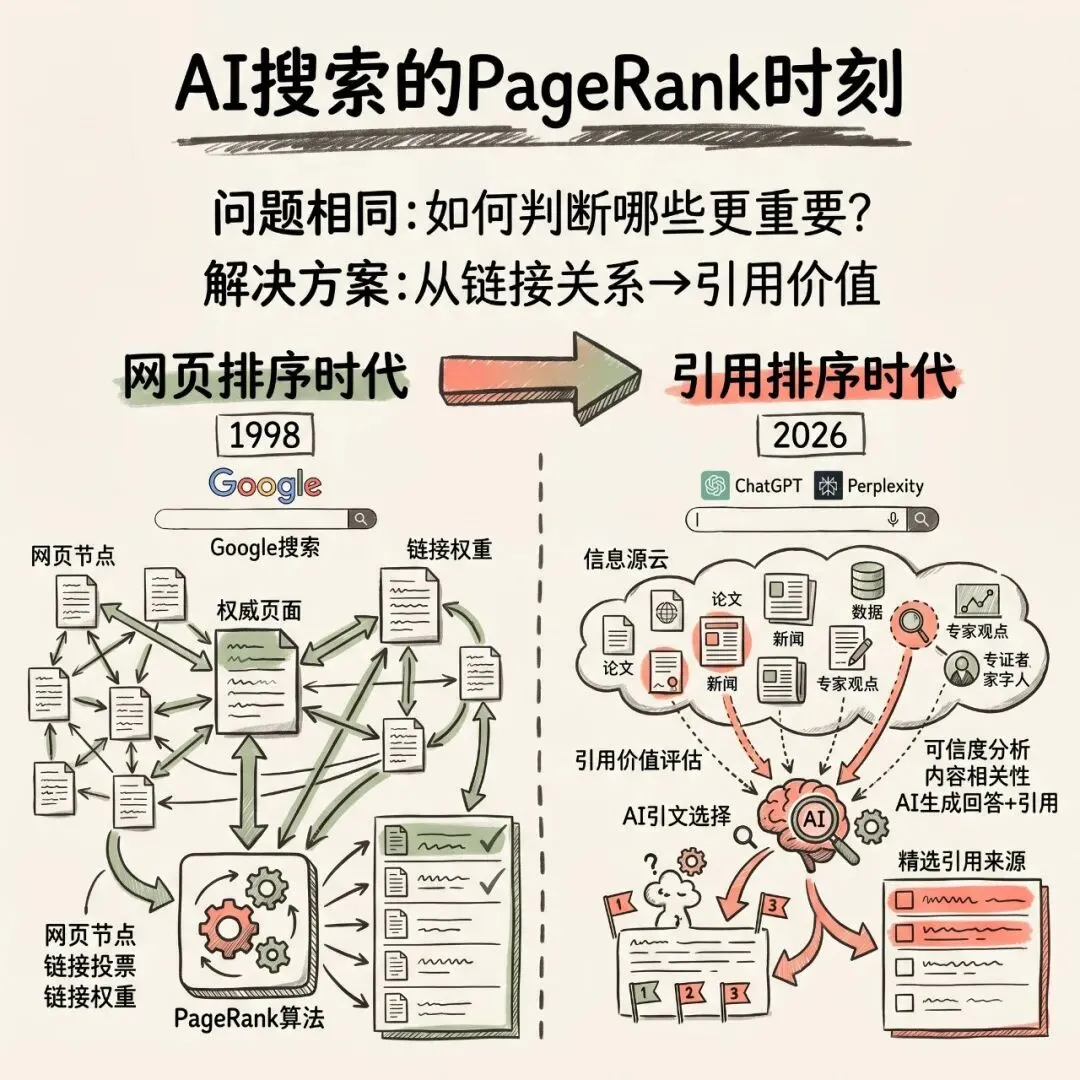
1998年:Google的PageRank
1998年,Larry Page和Sergey Brin还在斯坦福。
他们写了一篇论文,叫《The Anatomy of a Large-Scale Hypertextual Web Search Engine》。这篇论文介绍了一个搜索引擎原型:Google。
Google后来改变了整个互联网。但在最开始,它要解决的问题其实很朴素:
网页太多了,怎么判断哪些页面更重要?
PageRank的核心思路,就是利用网页之间的链接关系,给网页的重要性排序。
2026年:AI搜索的引用排序
二十多年后,类似的问题正在AI搜索里重新出现。
只不过这一次,系统要排序的不只是网页,而是引用来源。
这里的"引用来源",对应英文里的citation。简单说,就是ChatGPT或其他AI搜索回答里,最后展示给用户的那些来源链接。
为什么说这是AI搜索的PageRank时刻?
我不是说ChatGPT用了PageRank算法——我是说它们面对的是同一类问题。
当网页足够多、噪音足够大、内容质量足够参差不齐时,系统就不能只是"找到内容"。
它还必须判断:
哪些内容更相关? 哪些来源更可信? 哪些页面值得被展示? 哪些信息可以进入最终答案?
传统搜索时代,这个问题对应的是网页排序。AI搜索时代,这个问题变成了引用排序。
模型不只是要决定"我看哪些网页",还要决定"我愿意把哪些网页作为引用来源展示给用户"。
这两个动作不是一回事。
这层筛选几乎是必然的
互联网不是一个干净的资料库,而是一个混杂着研究、营销、噪音、过期信息和垃圾内容的巨大候选池。
如果模型把所有检索到的内容都等权处理,答案质量一定会下降。
所以它必须筛选。
这个筛选不一定等同于Google PageRank,但它解决的是同一类问题:
面对大量候选页面,如何判断哪些更相关、更可信、更值得展示?
传统搜索排序会考虑相关性、页面质量、来源权威、新鲜度等多种信号。
AI引用排序也必须在类似维度上做取舍,只是它最终展示的不是"十个蓝色链接",而是答案里的几个引用来源。
Reddit悖论:被AI学到≠被AI署名
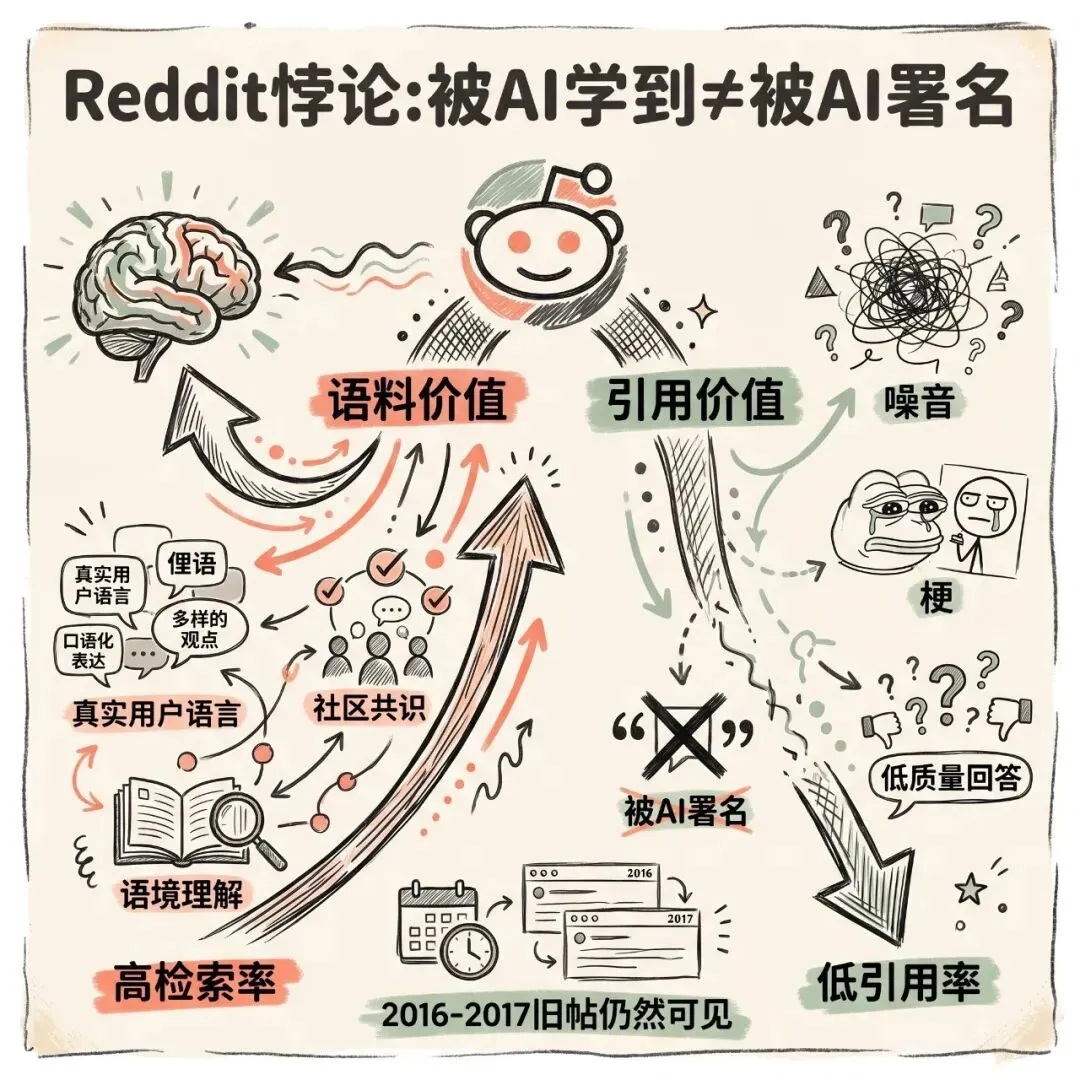
Ahrefs研究里还有一个很值得看的现象:Reddit。
Reddit的数据量很大,但引用率很低。
乍看这像是矛盾的:既然Reddit被大量检索,为什么很少被引用?
但我觉得这反而很好理解。
Reddit很容易进入搜索结果
这里要先分清两件事:Google搜索结果里的Reddit,和大模型答案里的最终引用,不是一回事。
作者在2026年4月26日用两个和《星露谷物语》相关的查询做了截图:
stardew valley profit stardew valley profit calculator
这两张图证明的不是"Reddit会被大模型最终引用",而是一个更前置的现象:
Reddit很容易进入搜索结果,也就更容易进入AI搜索的候选来源池。
截图里还有一个值得吐槽的细节:Reddit结果下面关联的帖子,有些来自2016年、2017年。
所以,高可见度不等于新鲜,高排名不等于高质量,更不等于适合作为最终引用。
Reddit像一个巨大的语料矿山
Reddit里面有大量:
真实用户语言 真实问题 群体共识 一线经验
AI很可能会用它来理解语境、补充背景、观察大众讨论。
但Reddit同时也有大量噪音
玩梗 吐槽 重复问题 低质量回答 情绪化表达 甚至还有不少AI生成内容和营销内容
数据量越大,分母越大;但真正适合拿来署名引用的内容,不可能同步增长。
所以Reddit的问题是什么?
不是"有没有价值",而是**"语料价值"和"引用价值"不是一回事**。
这对内容创作者、SEOer、GEOer、企业官网和SaaS团队都很重要。
你在社交平台上的观点,可能被AI学到,成为它理解某个话题的背景语境。
但如果这些观点没有:
稳定链接 清晰标题 明确结构 可归因结论
它们未必会成为最终引用。
换句话说:
被AI吸收,不等于被AI署名。
这个区别会越来越重要。
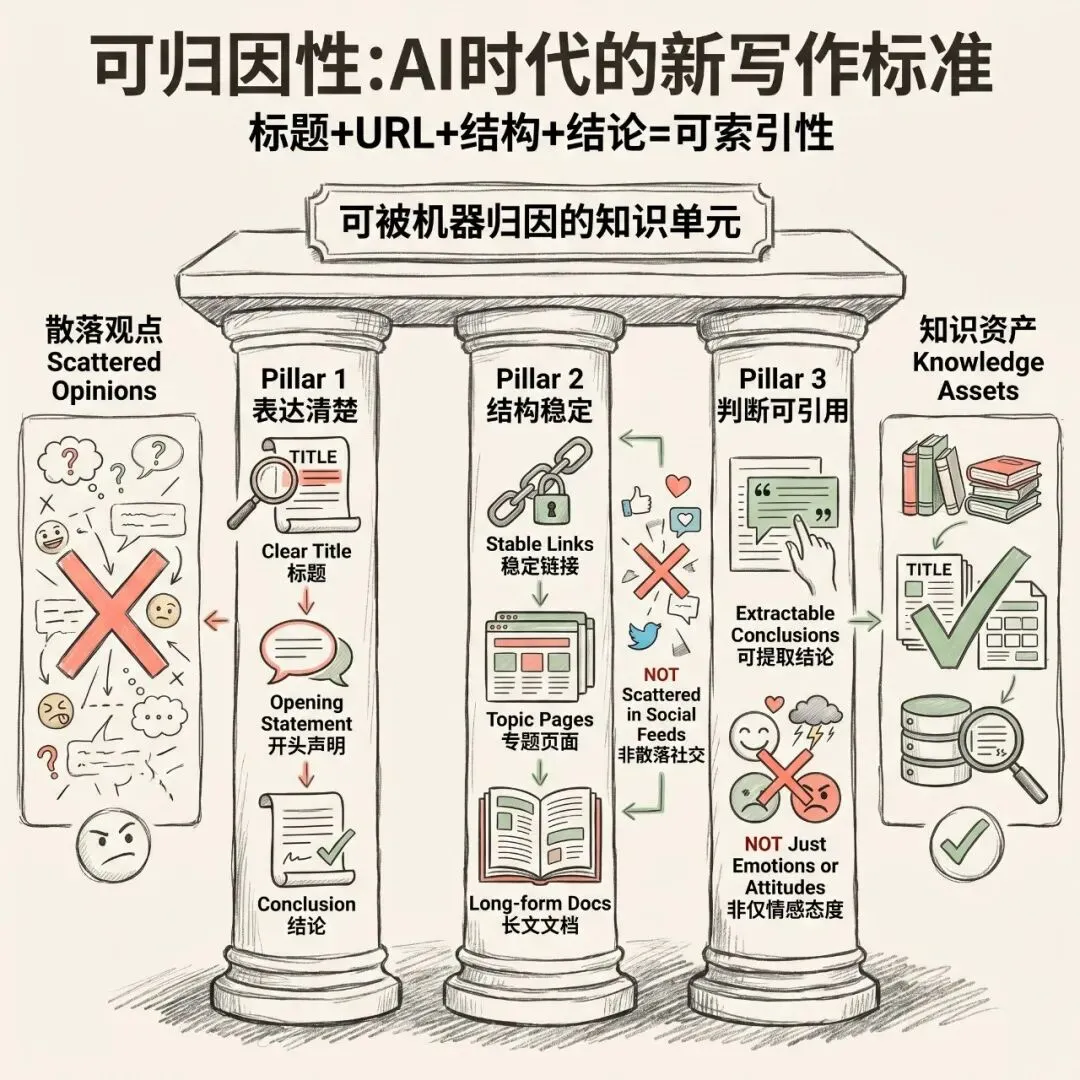
可归因性:AI时代的新写作标准
AI搜索匹配的不只是原始问题
这里还有一个细节:AI搜索匹配的可能不只是用户输入的原始问题。
为了生成一个答案,模型可能会先把问题拆成几个中间问题,再去找能回答这些问题的来源。
比如用户问"为什么ChatGPT会引用某些网页",模型真正需要处理的可能是:
它看过哪些来源 哪些来源更可信 标题和URL是否匹配问题 内容是否足够新 是否适合被引用
所以,内容不是只要覆盖关键词就够了。
它还要让模型判断:这篇文章到底回答了哪个问题。
这件事最后会落到写作本身
标题、URL、结构、结论,过去主要是给人看的。
现在它们也是给机器看的。
如果一篇文章观点很散:
一会儿讲海湾局势 一会儿讲中年危机 一会儿讲AI搜索 一会儿讲个人成长
读者可能还能靠语感理解你在写一种情绪,但机器很难稳定判断:这篇文章到底回答了什么问题?
它不知道该把你放进哪个主题、哪个查询、哪个引用语境。
这不是说文章不能有文学性
也不是说所有内容都要写成说明书。
而是说,如果你希望自己的内容成为AI搜索里的可引用来源,就需要让它具备更清晰的**"可索引性"**。
也就是:
1. 标题能说明问题不要用"今天的思考"、"随笔"这类模糊标题。
2. URL或页面主题能表达语义自然语言URL slug的引用率,高于不透明URL。
3. 开头能提出判断第一段就要让人(和机器)知道你在讨论什么。
4. 正文能围绕判断展开不要跑题,不要散。
5. 结尾能留下可引用结论给一个明确的、可以被摘走的结论。
Ahrefs的数据支持这个方向
它们发现:
被引用页面的title,和用户prompt/fanout query的语义相似度更高 自然语言URL slug的引用率,也高于不透明URL
这不是说标题决定一切。
但标题、URL和结构至少在告诉模型:我这篇内容到底解决什么问题。
新鲜度不是免死金牌
很多人会说,AI搜索喜欢新内容。所以只要更新得快,就更容易被引用。
这句话只对了一半。
新鲜度当然重要
尤其是:
新闻 产品发布 政策变化 价格变化
这类场景。
但新鲜度不是免死金牌
前面《星露谷物语》的截图其实也能说明这一点:
Google搜索结果里关联的Reddit帖子,有些来自2016年、2017年。它们并不新,但依然获得了很高可见度。
Ahrefs的反直觉发现
ChatGPT整体上偏好较新的内容,但在同一个检索集合里,被引用页面并不总是最新的。
很多最终被引用的页面,反而是相对更成熟、更稳定的内容。
这说明什么?
模型不是单纯追新。
它仍然要在相关性、可信度、新鲜度和可归因性之间做权衡。
一个很新的页面,如果没有清楚回答模型的中间问题,也可能被检索到,然后被忽略。
一个稍旧但结构清楚、观点明确、来源可信的页面,反而更容易成为最终引用。
所以内容生产不应该只追热点
真正重要的是:
你能不能把一个判断写成长期可识别、可引用、可复用的知识单元。
未来内容竞争的核心:可被机器归因的知识单元
我的判断是,AI搜索正在奖励一种新的内容形态:
可被机器归因的知识单元。
什么是可被机器归因的知识单元?
如果AI搜索真的在做引用排序,那么内容资产就不能只是"能被读",还要**"能被归因"**。
它不是单纯的短观点,也不是松散的资料堆砌,而是:
能被人读懂、也能被机器识别、索引和引用的内容资产。
这件事不只影响个人创作者
也会影响:
SEOer GEOer 企业官网 SaaS产品页 帮助中心 行业报告 知识库
因为AI搜索不是只在回答"谁写得有趣",它还在判断:
哪个页面能回答这个中间问题? 哪个来源更可信? 哪个结论更适合被引用? 哪个网页能承担最终答案里的署名责任?
这要求内容至少做到三件事
第一,表达清楚
标题、开头和结论要能说明:这篇内容回答了什么问题。
第二,结构稳定
链接、专题页、文档和长文要能长期存在,而不是只散落在社交媒体的信息流里。
第三,判断可引用
不要只给情绪和态度,也要给可以被摘走、被复述、被归因的结论。
对不同角色的启示
对个人创作者:
不能只在社交媒体上输出零散判断。AI可能会吸收你的观点,但未必把信用给你。
对企业和SaaS:
官网、博客、文档和帮助中心不能只是营销页面,而要变成清晰回答用户问题的知识资产。
对SEOer和GEOer:
优化目标也在变化:过去是让页面进入搜索排名,现在还要让页面进入AI答案的引用位置。
为什么要重视长内容和知识库?
这也是作者现在越来越重视素材库、wiki和长文写作的原因。
短内容适合传播观点。
但长内容、专题页、知识库和结构化文档,更适合建立权威。
因为权威不是靠一句话形成的,而是靠持续稳定的判断系统形成的。
三个深度洞察
洞察1:从"排名竞争"到"归因竞争"——内容分发权力的转移
传统SEO时代,内容竞争的核心是"我能不能排在搜索结果前面",这是一个单层竞争。
但AI搜索时代出现了双层竞争:
**第一层:**能不能进入来源池(被检索到) **第二层:**能不能进入最终引用(被署名)
Ahrefs的50%引用率数据揭示了这个双层结构的存在。
更深层的含义是,这不仅是技术变化,而是内容分发权力的转移。
过去Google通过PageRank决定"哪些页面排前面"。
现在ChatGPT、Perplexity这类AI搜索通过引用排序决定"哪些来源配得上署名"。
这个转变类似于:
从"谁能上货架"(传统搜索排名) 到"谁能上推荐位"(AI引用列表)
对内容创作者来说,这意味着优化目标从"提高排名"变成了"提高归因率"——不仅要让AI看到你,还要让AI愿意把信用给你。
这也解释了为什么很多在传统SEO表现优秀的内容,在AI搜索时代可能失去优势,因为游戏规则变了。
洞察2:Reddit悖论揭示"训练价值"与"引用价值"的分离
Reddit的"高检索率、低引用率"现象,揭示了AI时代一个残酷的真相:
你的内容可能被AI大量吸收用于理解语境和训练模型,但这不意味着AI会在生成答案时给你署名。
这类似于学术界的"隐性引用"问题——你的观点被广泛传播和使用,但没人标注来源。
AI在做两种不同的价值判断:
一种是"这个内容对我理解世界有帮助吗"(训练价值) 另一种是"这个内容值得我署名引用吗"(引用价值)
对个人创作者和企业来说,这个洞察非常重要:
如果你只在社交媒体上输出零散观点,AI可能会吸收你的思想但不会把流量和信用给你。
要获得引用,你需要把观点沉淀为:
稳定链接 清晰结构 可归因结论 长期内容资产
这也是为什么作者强调"短内容适合传播观点,但长内容、专题页、知识库和结构化文档更适合建立权威"。
洞察3:"可索引性"定义了AI时代的新写作标准
文章提出的"可索引性"概念,实际上定义了AI时代的新写作标准。
传统写作优化的是"人类阅读体验"——吸引人、有共鸣、能传播。
但AI时代的写作要同时优化"机器理解效率"——让AI能快速判断"这篇文章回答了什么问题、是否可信、能否被引用"。
这不是说要牺牲文学性写成说明书,而是说要在保持人类可读性的同时,增加机器可解析性。
具体来说,这要求内容具备三层结构:
表层(给人看):
标题吸引眼球 开头引人入胜 语言有感染力
中层(给机器看):
标题语义清晰 URL可读 结构化标记 明确结论
深层(给长期价值看):
稳定链接 可持续更新 知识体系化
Ahrefs的数据支持这个判断:"被引用页面的title和用户prompt的语义相似度更高,自然语言URL slug的引用率高于不透明URL"。
这意味着未来优秀的内容创作者,不仅要懂人类心理学(如何吸引读者),还要懂信息架构学(如何让机器理解),甚至要懂知识图谱(如何让内容可被长期索引和引用)。
这是一个更高的写作标准,但也是AI时代内容创作者的护城河所在。
写在最后:一个警告和一个机会
警告:引用归因仍然不可靠
最后要说一个容易被忽视的问题:
AI答案后面挂了引用来源,不等于它就可靠。
CJR/Tow Center的测试显示:200次引用归因里有153次部分或完全错误。
引用排序会越来越重要,但它本身仍然不可靠——这两件事同时成立。
机会:未来内容竞争的核心
未来内容竞争的核心问题,不是"我写得好不好",而是:
"机器能不能把这句话归因到我。"
这是一个新的战场。
而现在,正是建立优势的最好时机。
