夜雨聆风
夜雨聆风今日导读
方向 | 篇数 | 关键词 |
|---|---|---|
一、大模型训练数据 | 3 | 数据质量幻觉、数据混合相变、训练数据剪枝 |
二、数据基础设施 | 3 | Parquet 读取重写、10B 向量搜索、PB 级自动驾驶数据湖 |
三、RAG 检索增强 | 3 | 多语言 Embedding、统一多模态检索、知识冲突检测 |
四、数据标注与评估 | 3 | 开源偏好数据集、全模态奖励模型、浅层偏好信号 |
五、多模态数据 | 3 | 100MP 超高清数据集、海洋多模态语料、临床思维链数据集 |
一、大模型训练数据

【The Data-Quality Illusion: Rethinking Classifier-Based Quality Filtering for LLM Pretraining】
【Data Mixing Can Induce Phase Transitions in Knowledge Acquisition】
【Cram Less to Fit More: Training Data Pruning Improves Memorization of Facts】
二、数据基础设施
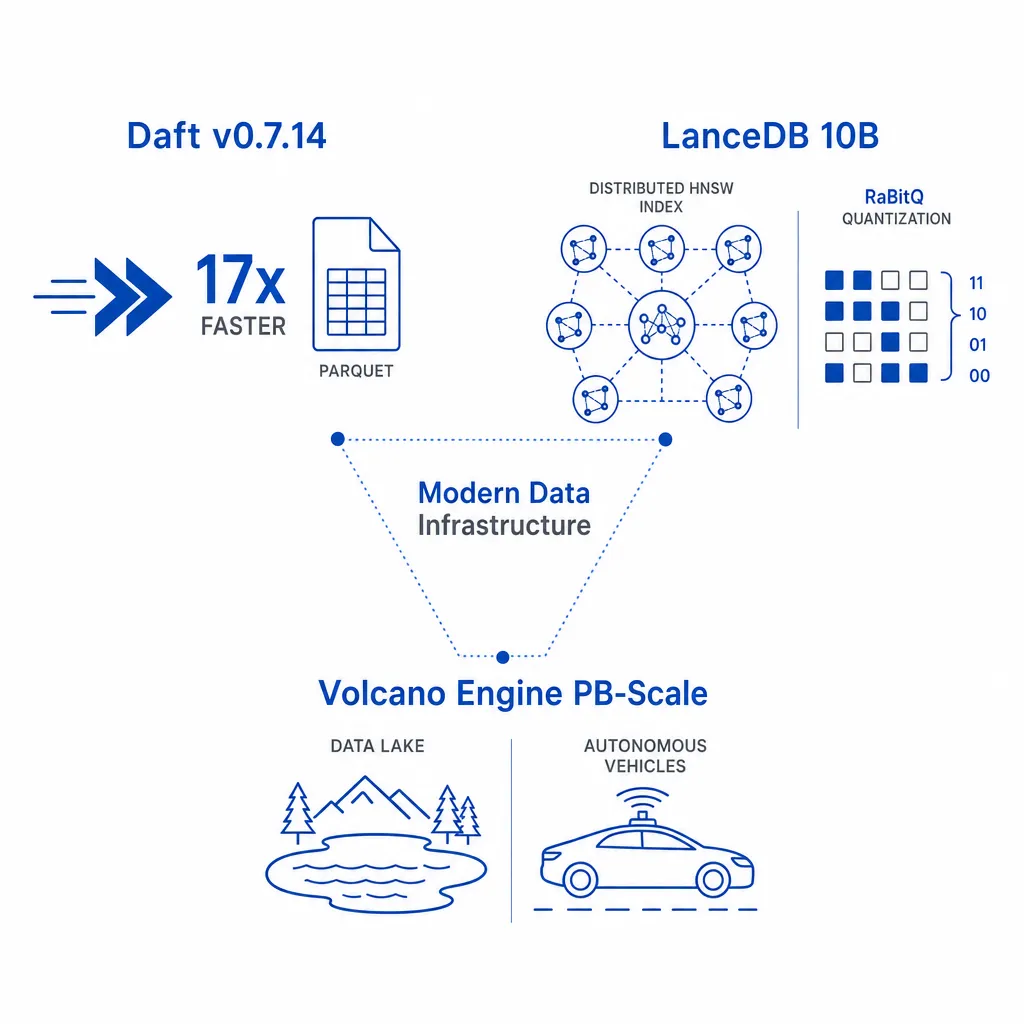
【Daft v0.7.14: Parquet Reader Rewrite, Streaming Distributed Limits, UUIDv7】
【How LanceDB Accelerates Vector Search at 10 Billion Scale】
【Volcano Engine LAS's Lance-Based PB-Scale Autonomous Driving Data Lake Solution】
三、RAG 检索增强
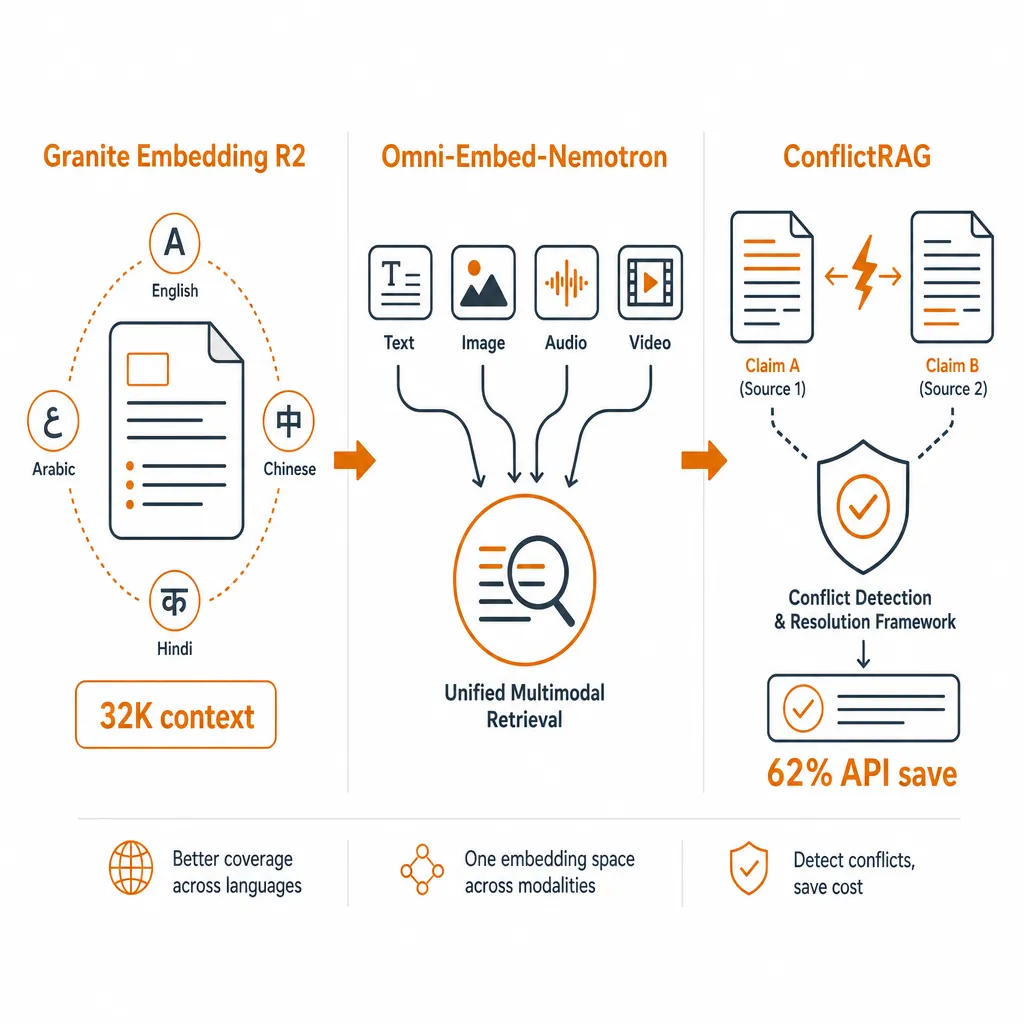
【Granite Embedding Multilingual R2: Best Sub-100M Retrieval Quality with 32K Context】
【Omni-Embed-Nemotron: A Unified Multimodal Retrieval Model for Text, Image, Audio, and Video】
【ConflictRAG: Detecting and Resolving Knowledge Conflicts in Retrieval Augmented Generation】
四、数据标注与评估
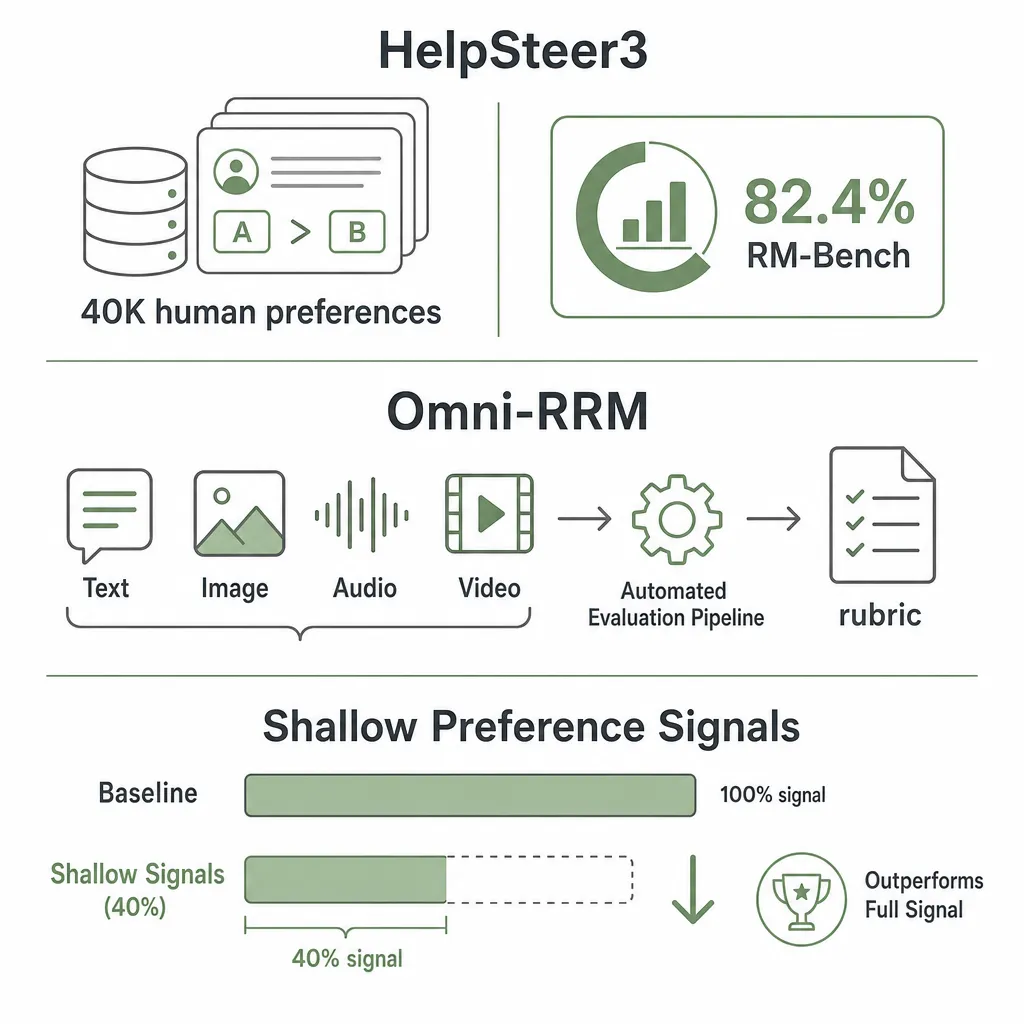
【HelpSteer3-Preference: Open Human-Annotated Preference Data across Diverse Tasks and Languages】
【Omni-RRM: Advancing Omni Reward Modeling via Automatic Rubric-Grounded Preference Synthesis】
【Shallow Preference Signals: LLM Aligns Even Better with Truncated Data?】
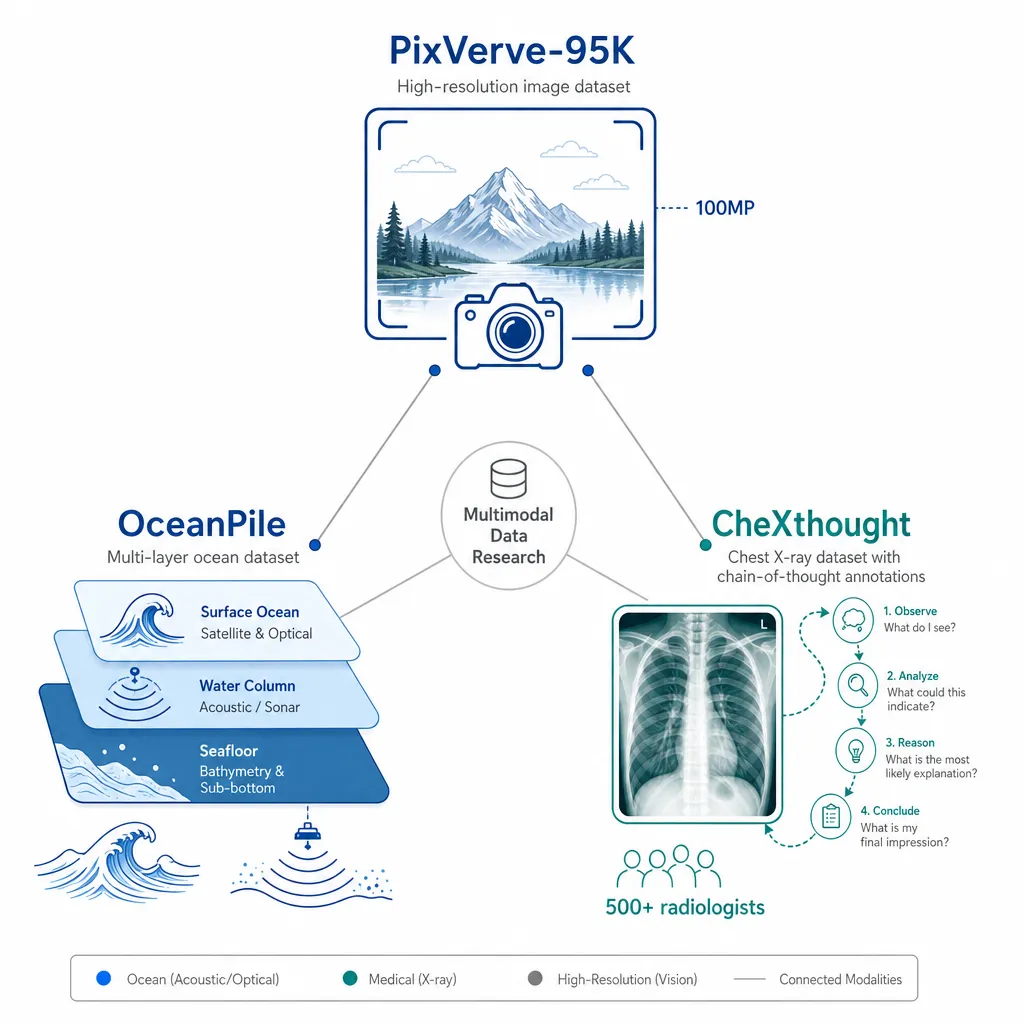
五、多模态数据